
In the light of the ongoing climate crisis, let’s talk about the carbon footprint of artificial intelligence.
The everyday internet user might find it hard to fathom the fact that using ChatGPT or watching YouTube-recommended videos might generate greenhouse emissions. And, understandably, they could be least concerned about “Green AI” or “Environmental AI” when using these technologies. But for researchers and data scientists, the carbon footprint created as a result of the machines, computers, and digital devices being powered by machine learning (ML) – is a growing concern, especially as global climatic change continues to escalate.
Algorithms powered by machine learning generate a great deal of greenhouse gas emissions. Fossil fuels are burned for electricity which power up some highly sophisticated and powerful data servers dealing with millions to billions of queries a day. And, let’s not forget all the interconnected machines and computers, or the network and internet infrastructure supporting them – most notably, data centres – which stock data and applications, drawing almost unimaginable levels of power worldwide.
Plus, with transfer learning being the ’next big thing in the world of machine learning’, businesses and organisations of all scales and across all sectors will really need to think about clever ways to reduce their machine learning carbon footprint.
On a quick side note, Google’s BERT model is a good example of transfer learning in ML – we’ll be shedding some light on that too later in the article, so grab your cuppa, and enjoy the in-depth read.
Before we discuss some ways and ideas to reduce our machine learning carbon footprint, it’s only fair that we briefly understand the environmental impact machine learning and data science can have in general.
Every piece of software – from the apps we run on our smartphones to the data science pipelines operating in the cloud – consume power. As long as we do not produce that power from renewable sources alone, we will leave behind a carbon footprint. Hence, machine learning models leave behind a carbon footprint too.
Throughout the article, we may refer to this carbon footprint as “the amount of CO₂e emissions”, where the ’e’ stands for equivalents. Other gases like nitrous oxide, methane or even water vapour have a warming effect, therefore, a standardised measure to describe how much warming a certain amount of gas will have is typically donated through CO₂e emissions for simplification purposes.
As far as we understand it, no reports currently detail the total amount of CO₂e emissions in the field of machine learning, specifically. However, several attempts have been made to estimate the total power consumption of the global data centre industry.
If we narrow this down to the organisational level in terms of environmental AI, Google claims that 15% of its total energy consumption was towards the machine learning involved in the use of computers for research, development, and production. The graphic card giant, NVIDIA, estimates that 80-90% of the ML workload is due to inference processing. Additionally, Amazon Web Services reported that 90% of their ML demand in the cloud is dedicated toward inference.
These estimates are actually much higher than the ones reported by an unknown but major cloud computing provider in an OECD report. The provider estimates that approximately between 7% and 10% of enterprise customers’ total compute infrastructure spend is dedicated towards AI applications – where 4.5% is spent on inference and 3-4.5% on training ML models.
All in all, it can be quite difficult to paint an accurate picture of the carbon footprint of ML as a field and what specific measures companies should be taking to achieve a more “green AI” footprint. After all, there’s a lack of data, although it’s understood by the vast majority of companies that certain machine learning models, especially language models, can leave behind some very large carbon footprints. This correlates with what some organisations are doing as they spend a significantly large amount of their total power usage on ML-related activities.
Now then, what can we personally do to reduce our machine learning carbon footprint as much as possible and work with a more of a ‘green’ AI footprint instead?
Before we start discussing the ways of reducing our machine learning carbon footprint, we need to make sure that from a terminology standpoint, we’re both onboard:
Throughout this section, we may distinguishing between two different kinds of carbon footprints – the one produced as a result of training an ML model and the one from using a ML model. So, we’ll refer to the former as model training or model development and the latter as operations; as in, the operational phase of the ML model’s lifecycle where it is used for inference.
Naturally, our first recommendation is fairly simply and has nothing to do with reducing a single model’s footprint, but rather, reducing your work’s footprint in general.
So, we need to estimate the carbon footprint of our models. In doing so, you can factor in this information during model selection.
Let’s say you’re in a situation where your best model obtains an MAE (Mean Absolute Error) which is 13% lower than your second-best model – however, all the while, your best model registers a carbon footprint which is approximately 9,000% larger. Do you go for a reduction in model error while bypassing the major increase in carbon footprint?
That is very context dependent. Ultimately, it comes down to your individual business, and based on data supplied by your ML engineer or data scientist.
However, there’s a formula you can use to estimate the carbon footprint of an ML model: E*C.
The ‘E’ here is the total number of electricity units consumed during a computational process (kilowatt per hour or kWh) while the C is the volume or quantity of CO₂e emitted per kWh of electricity, which is sometimes referred to as the carbon intensity of electricity. This carbon intensity may vary from geographical region to region, as energy sources vary between different regions across the world.
Some regions of the world may have an abundant supply of renewable energy sources, for example, while others may have less.
There are tools available to estimate the carbon footprint of machine learning models, which generally fall under one of the two categories:
Those which estimate the carbon footprint from estimates of energy consumption (E)
And, those which estimate the carbon footprint from measurements of energy consumption (E)
You may find other off-the-shelf tools as well although it’s best to consult a data science expert who can build the software on a bespoke basis, taking into account your specific use cases, region, and business needs.
You might have heard of the term ‘page weight budget’ in web development. It specifies how much a website should ideally weigh in kilobytes, as far as all the various files are concerned – i.e. text, images, icons, graphics, etc.
More specifically, it is the size of the files which are transferred from the main source to the end user when the webpage is loaded. Web developers specify the page weight budget before the actual development begins, as it acts as a guiding star in the entire process, from design through to implementation.
Well, you could certainly cultivate a similar concept in data science. For example, you could set a limit on how much carbon you can allow your machine learning model to emit throughout its lifetime. So, more specifically, the metric to target would be ‘carbon footprint per inference’.
This one is relatively easy in practice, yet data scientists often get so caught up in the mix that they forget to remind themselves of one very important and cardinal rule: a more complex solution isn’t always the best one.
Every time you kickstart a new project, begin by computing a cheap, practical, and reasonable baseline. So, for time series forecasting, for example, you can come up with a basic and ‘cheap’ baseline to use the value at t-n as the predicted value for t – ’n’ could be 24, for instance, if the data refers to an hourly resolution and shows daily seasonality.
In natural language processing or NLP, heuristics implemented as regex is what you’d call a “reasonable baseline”. In regression, a good baseline may be as simple as using the mean of the target variable, which is potentially grouped by another variable.
Once you have established a reasonable baseline, you can compare it against the above just to see if more complex solutions are, in fact, even worth the extra work and especially carbon emissions. If a skateboard can get you there, ditch the sports car!
What we can do for you
Chances are you’re using a cloud provider like Azure, AWS or Google Cloud. If that is the case, then you can select which region to run your computational procedure.
Research shows that emissions can be cut down by up to 30 times simply by conducting experiments in regions which utilise more renewable sources of energy. Clearly, electricity’s carbon intensity varies from region to region and often by a wide margin, so choose accordingly.
Contrary to popular belief, electricity tends to be ‘cleaner’ around noon than at night. Furthermore, the carbon intensity of electricity may vary on a daily and even hourly basis.
This means that you can cut down your work’s carbon footprint by scheduling heavy model training during periods when the energy is cleaner. However, if you’re in a hurry to train a new model at the earliest possible opportunity, then you may want to begin the training at a time when the carbon intensity in your specific cloud region is under a certain threshold. Simply put your training on hold when the carbon intensity goes above the threshold.
If you’re familiar with the Torch library, then you would have likely used the machine learning framework based on that library, PyTorch, which lets you conveniently save and load your model. Simply hardcode the hours or manually feed in the hours during which your cloud region has clean energy. Alternatively, you may obtain this data from a paid service such as Electricity Map which offers real time access to data and forecasts on carbon intensity across various regions.
When you distil large machine learning models, you can reduce your model’s carbon footprint during the production phase. You might see model distillation as the process of moving knowledge from a significantly larger ML model to a smaller one. At times, this can be accomplished by training a smaller model to replicate the larger model’s behaviour which has already been trained.
DistilBERT is a good example of a distilled pre-trained language model. If you compare it with the “undistilled” version (BERT), it is at least 40% more compact in terms of the total number of parameters and a good 60% faster in inference. Perfect for transfer learning and it does all this will maintaining 97% of its language understanding.
Model distillation has been successfully applied to image recognition as well and we imagine it can also be used in other domains, such as in time series forecasting involving neural networks.
It would appear that model distillation can be highly effective in producing a model that’s more computationally efficient, and where you don’t end up sacrificing accuracy. However, if you’re applying model distillation purely to reduce your model’s carbon footprint, then it’s worth noting that the additional carbon emissions resulting from the distillation process will not overrule or outweigh the emissions savings you will have during the model’s time in the production phase.
Some data scientists blindly tend to throw more compute at their problem, hoping to obtain a better outcome. Unsurprisingly, most of us instinctively think that reducing the executing time of certain procedures would automatically reduce their carbon footprint.
Well, this can only be achieved if you speed up your code quite simply by writing better code to begin with, so that it executes faster. Now, this is where most researchers and data scientists fall short: attempting to speed up their programs by heaving more compute power at them, which may potentially make them ‘greener’ but only up to a certain degree.
In this study, researchers measured the processing time and carbon footprint of executing a particle physics simulation using a CPU which had a varying number of cores. If you take a brief look at the study, you will find that the green line indicates the running time – i.e. the total time it took to run or execute the simulation – while the orange line indicates the carbon footprint emission as a result of running that simulation. Now, it’s worth observing that when the number of CPU cores used to run the simulation doubled from 30 to 60, the execution time did not decrease by much, while the carbon footprint actually increased from approximately 300 gCO₂e to over 450 gCO₂e.
From these findings, the authors of the study concluded that, generally speaking, if the reduction in the simulation’s running time is lower than the relative increase in the total number of cores, then distributing the computations across more cores will lead to an increased carbon footprint. And, for any parallelised computation, there will likely be a specific optimal number of cores to target, so as to minimise GHG emissions.
Did you know that cloud data centres can be 1.4 times to twice as more energy-efficient than the typical data centres? Furthermore, ML-specific hardware can be up to 5 times more efficient than ‘off the shelf’ systems.
Google’s custom TPU v2 processor, for example, uses 1.2 times less energy for training large language models compared to NVIDIA’s Tesla P100 processor.
By using highly efficient data centres, you can effectively reduce your machine learning carbon footprint during both the development and operations phase.
A relatively easy way to cut down your ML carbon footprint is by reducing the total number of model training procedural runs.
It’s always better to experiment with small data subsets before actually kicking off the entire training procedure. This way, you can also find bugs more quickly and cut down your total power consumption during the model development phase.
This is another no-brainer. In our quest to work with green AI and reduce the impact of environmental AI, we should avoid training large language models from scratch – well, that is, unless we absolutely must from a business standpoint.
A better way to approach things and reduce our machine learning carbon footprint would be to fine-tune the existing or pre-trained language models at our disposal. Huggingface is one way to tweak the existing language models you have. Would this be a direct competitor?
Did you know that the energy a cloud instance consumes on which a large language model is operating, is very high even when that model isn’t processing any requests actively? The thing you should consider is whether you service will actually be utilised on a 24/7/365 basis or you can afford to shut it down at times.
For example, you are using a machine learning-based service for internal use within your business – in some instances, you may reasonably expect no one to be using that service, let’s say, at night, right?
So, the compute resource on which your service is running can safely be shut down during certain hours of the night and then brought back to life the next morning. Your business won’t take a hit and you’ll effectively reduce your machine learning carbon footprint. That’s one more point for green AI!
As you are likely aware, neural networks require a fair amount of compute to train. However, sparsely or partially activated networks can give you the same performance but while consuming noticeably less energy. A sparse or partially activated network is one where only a certain percentage of all the possible connections exist.
If you can get the job done with 65% of your neural network, then there’s not need to activate the full 100%, is there? And, that’s another point for green/environmental AI!
Traditional deployments involve running a server that’s always on. There is also the option of function as a service, which means that you write your code as an executable function rather than a server which maintains a state and exists in memory.
The three major cloud providers offer their own serverless solutions: Azure Functions, AWS Lambda, and Google Cloud Functions.
We’ve found that even large ML solutions can be deployed just fine on serverless. There is a small compromise in terms of a “cold start” - a wait of a few seconds when you first use a model. But overall, serverless is kind on both your wallet and the environment.
Simple models such as Naive Bayes are ideal for serverless deployments and have additional advantages that they are cheap and easy to train, quick to use, explainable, and easy to adjust manually with feature engineering.
Well, this isn’t exactly related to machine learning models, but it is a good way, nevertheless, to cut down your entire application’s carbon footprint. For a fact, some data storage solutions simply consume less energy or are generally more energy-efficient than others.
AWS Glacier offers a great data archiving solution, which we’ve found to be more energy-efficient than others. It may take you a while to retrieve your data, but you’ll certainly appreciate a storage solution that’s more energy efficient, as opposed to just being faster and leaving behind a larger carbon footprint.
Naturally, it makes sense to talk about the environmental AI impact of training LLMs like GPT-3 while we’re on the subject of reducing machine learning carbon footprint.
LLMs must be trained computationally. They are built on transformer architectures which consume huge amounts of text. Language training for GPT-3 means that 175 billion parameters will require semi-random adjustment – that is, they must be “adjusted” or “tuned” so that the output texts are exactly what people expect when they throw a query at it.
This is done only once – well, in theory. What actually happens is that during testing and development, the “once” may occur over and over again until it is tuned. End users can also fine tune the language models which means yet more computation to adjust all the parameters.
After multiple rounds of training, you get a transformer neural network which has billions of optimised or ’tuned’ parameter values that can not only “autocomplete” texts, but also write entire paragraphs coherently, provide instructions, respond to detailed questions, and more.
Interestingly, both ChatGPT and GPT-3 are not the largest LLMs even though they certainly are the most popular. PaLM from Google research and the Open Source BLOOM are respectively 500 billion parameters and 176 billion parameters each.
The bottom line is this: training an LLM is very, very carbon-intensive.
The data sets’ size is massive and the number of parameters always range in the billions. This is something that requires thousands of hours of compute. And, this is why the machine learning carbon footprint of an LLM like GPT-3 is such a hot topic at the moment. The compute occurs at large cloud data cloud centres which are distributed throughout the world. It’s certainly made life convenient but at what cost to the environment?
Studies have been published to help reduce the carbon footprint associated with training LLMs, but that may not be enough because the environmental AI impact of it all continues to increase day by day.
Now, let’s put this into perspective and study its impact in terms of green AI and sustainability:
Google’s T5 pretrained language model consumes 86 megawatts of energy and produces 47 metric tonnes of CO₂ emissions.
Google’s routing algorithm, Switch Transformer, consumes 176 megawatts of energy while producing 56 metric tonnes of emissions.
GPT-3, OpenAI’s highly sophisticated natural language model, no doubt the most popular of them all, consumes a whopping 1,287 megawatts (that’s 1.3 gigawatt) of energy while producing 552 metric tonnes of CO₂ emissions. Let’s think about that for a moment – that’s the equivalent of covering a distance of 1.3 million miles across the UK in a petrol-driven car in one hour! -Source
The average person in the US emits around 15 tonnes of CO₂ each year, while the average person elsewhere in the world emits about 4 to 5 tonnes of CO₂ each year. The most carbon-intensive numbers ever recorded for training GPT-3 is approximately 200,000 kg of CO₂. That translates to 12 people from the US emitting 200 tonnes of CO₂ for a year and 50 non-US people emitting the same during a year.
The least carbon intensive numbers recorded for training GPT-3 is around 4,000 kg of CO2. So, if you train it with a clean grid (more energy-efficient systems and higher abundance of renewable energy), that’s 25% of an American person’s emissions in a year.
Now, a petrol-driven car typically emits 5 tonnes of CO2 if you drive it throughout the year. So, training GPT-3 on a clean grid just once is the equivalent of driving that one car for a year. Training on a dirty grid, on the other hand – that is, a region where the systems are energy-hungry and there is a lack of renewable energy source – is the equivalent of driving 40 cars for a year, each one emitting 5 tonnes.
It’s fair to say that we still have quite a way to go in terms of green AI or taking the appropriate steps towards incorporating more positive environmental AI practices.
However, in this day and age, it is still very challenging to accurately gauge the environmental impact of machine learning as a field.
Specific off-the-shelf tools may help practitioners to estimate their machine learning carbon footprint, although the ideas we have presented above should send you off to a good start. We’ll admit, some of these ideas are definitely low-hanging fruits which you can implement easily, while others require more nuance, trial-and-error, and expertise.
At Fast Data Science, we really care about environmental AI and do everything possible to reduce machine learning carbon footprint as much as we can. If you are facing specific business challenges that require a bespoke AI/ML solution, we can provide a very cost-effective and green AI/ML solution to help you address those challenges head on.
Ready to take the next step in your NLP journey? Connect with top employers seeking talent in natural language processing. Discover your dream job!
Find Your Dream Job
Fast Data Science Ltd’s flagship AI platform, the Clinical Trial Risk Tool, has been accepted as a supplier on the UK Government’s G-Cloud 15 framework.

We are pleased to announce that Thomas Wood, director of Fast Data Science, will be appearing as a panelist at the Bond Solon Expert Witness Conference on 6 November 2026 at Church House, Westminster in London. This follows Thomas’s recent appearance at the Ireland’s Expert Witness Conference on 20 May 2026.
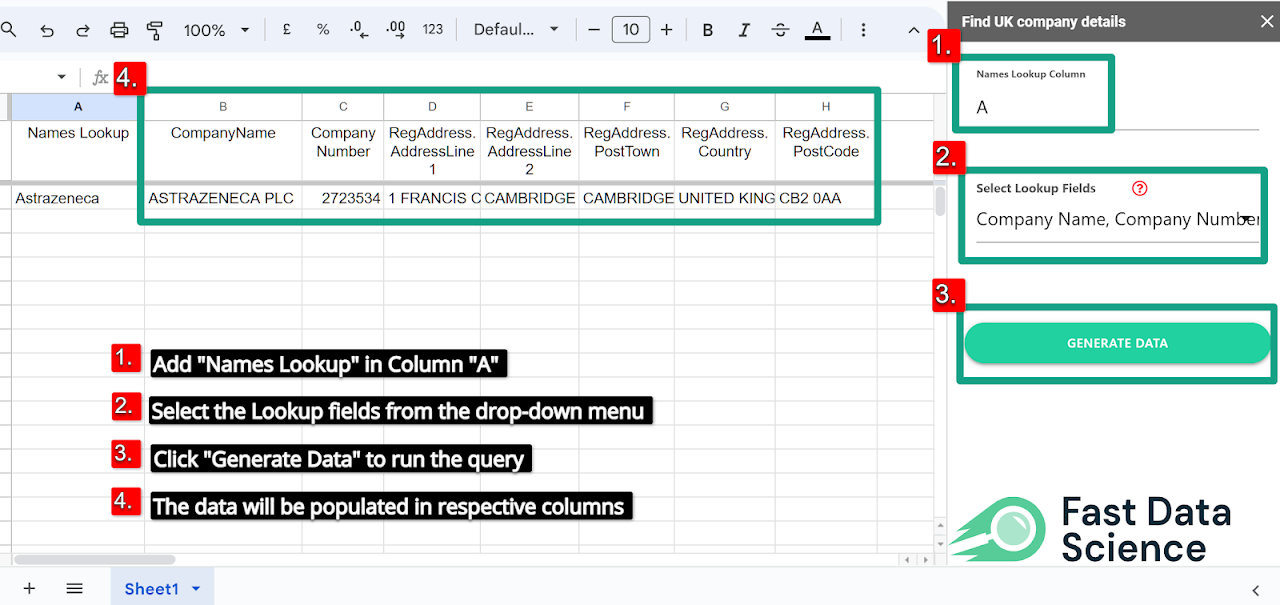
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.
What we can do for you