How we explain how a neural network can recognise an image?
Sometimes as data scientists we will encounter cases where we need to build a machine learning model that should not be a black box, but which should make transparent decisions that humans and businesses can understand. This can go against our instincts as scientists and engineers, as we would like to build the most accurate model possible.
In my previous post about face recognition technology I compared some older hand-designed technologies which are easily understandable for humans, such as facial feature points, to the state of the art face recognisers which are harder to understand. This is an example of the trade-off between performance and interpretability, or explainability.
Imagine that you have applied for a loan and the bank’s algorithm rejects you without explanation. Or an insurance company gives you an unusually high quote when the time comes to renew. A medical algorithm may recommend a further invasive test, against the best instincts of the doctor using the program.
Or maybe the manager of the company you are building the model for doesn’t trust anything he or she doesn’t understand, and has demanded an explanation of why you predicted certain values for certain customers.
All of the above are real examples where a data scientist may have to trade some performance for explainability. In some cases the choice comes from legislation. For example some interpretations of GDPR give an individual a ‘right to explanation’ of any algorithmic decision that affects them.
One approach is to avoid highly opaque models such as Random Forest, or Deep Neural Networks, in favour of more linear models. By simplifying architecture you may end up with a less powerful model, however the loss in accuracy may be negligible. Sometimes by reducing parameters you can end up with a model that is more robust and less prone to overfitting. You may be able to train a complex model and use it to identify feature importance, or clever preprocessing steps you could take in order to keep your model linear.
An example would be if you have a model to predict sales volume based on product price, day, time, season and other factors. If your manager or customer wanted an explainable model, you might convert weekdays, hours and months into a one-hot encoding, and use these as inputs to a linear regression model.
The best models for image recognition and classification are currently Convolutional Neural Networks (CNNs). But they present a problem from a human comprehension point of view: if you want to make the 10 million numbers inside a CNN understandable for a human, how would you proceed? If you’d like a brief introduction to CNNs please check out my previous post on face recognition.
You can make a start by breaking the problem up and looking at what the different layers are doing. We already know that the first layer in a CNN typically recognise edges, later layers are activated by corners, and then gradually more and more complex shapes.
You can take a series of images of different classes and looking at the activations at different points. For example if you pass a series of dog images through a CNN:
Fast Data Science - London

Dog image to be passed through an explainable CNN. Image credit: Zeiler & Fergus (2014) [1]
…by the 4th layer you can see patterns like this, where the neural network is clearly starting to pick up on some kind of ‘dogginess’.
 models can be explainable. Image credit: Zeiler & Fergus (2014)](https://fastdatascience.com/images/dog_activations.jpg)
The activations of a neural network by the 4th layer, explaining how the neural network has detected some ‘dogginess’. Image credit: Zeiler & Fergus (2014) [1]
Taking this one step further, we can tamper with different parts of the image and see how this affects the activation of the neural network at different stages. By greying out different parts of this Pomeranian we can see the effect on Layer 5 of the neural network, and then work out which parts of the original image scream ‘Pomeranian’ most loudly to the neural network.
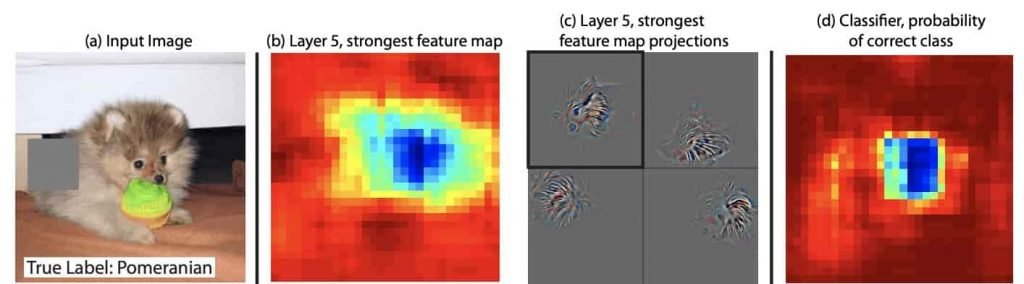
If you grey out different segments of an input image you can see what part of the neural network as affected by layer 5. This is starting to make the model more explainable. Image credit: Zeiler & Fergus (2014) [1]
Using these techniques, if your neural network face recogniser backfires and lets an intruder into your house, if you have the input images it would be possible to unpick the CNN to work out where it went wrong. Unfortunately going deep into a neural network like this would take a lot of time, so a lot of work remains to be done on making neural networks more explainable.
 explainability by masking parts of a dog image](https://fastdatascience.com/images/Convolutional-neural-network-explainability-by-masking-parts-of-a-dog-image-min-2-1024x464.jpg)
Convolutional neural network explainability by masking parts of a dog image
Imagine you have trained a price elasticity model that uses 3rd order polynomial regression. But your client requires something easier to understand. They want to know for each additional penny reduced from the price of the product, what will be the increase in sales? Or for each additional year of age of a vehicle what is the price depreciation?
You can try a few tricks to make this more understandable. For example you can convert your polynomial model to a series of joined linear regression models. This should give almost the same power but could be more interpretable.
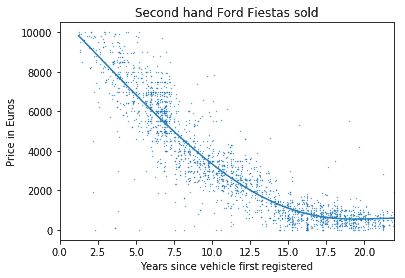
Traditional polynomial regression fitting a curve, showing car price depreciation by age of vehicle
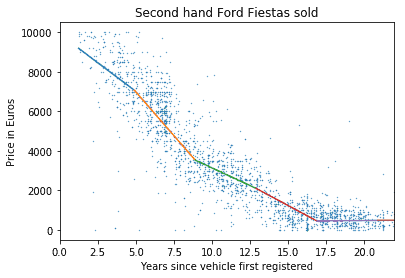
Splitting up the data into segments and applying a linear regression to each segment. This is useful because it shows a ballpark rate of depreciation at different stages, which salespeople might find useful for quick calculations.
Recommendation systems such as Netflix’s movie recommendations are notoriously hard to get right and users are often mystified by what they see as strange recommendations. The recommendations were usually calculated directly or indirectly because of previous shows that the user has watched. So the simplest way of explaining a recommendation system is to display a message such as ‘we’re recommending you The Wire because you watched Breaking Bad’ - which is Netflix’s approach.
There have been some efforts to arrive at a technique that can demystify and explain a machine learning model of any type, no matter how complex.
The technique that I described for investigating a convolutional neural network can be broadly extended to any kind of model. You can try perturbing the input to a machine learning model and monitoring its response to perturbations in the input. For example if you have a text classification model, you can change or remove different words in the document and watch what happens.
One implementation of this technique is called LIME, or Local Interpretable Model-Agnostic Explanations[2]. LIME works by taking an input and creating thousands of duplicates with small noise added, and passing these duplicate inputs to the ML model and comparing the output probabilities. This way it’s possible to investigate a model that would otherwise be a black box.
I tried out LIME on my author identification model. I gave the model an excerpt of one of JK Rowling’s non-Harry Potter novels, where it correctly identified the author, and asked LIME for an explanation of the decision. So LIME tried changing words in the text and checked which changes increase or decrease the probability that JK Rowling wrote it.

LIME explanation for an extract of The Cuckoo’s Calling by JK Rowling, for predictions made by a stylometry model trained on some of her earlier Harry Potter novels
LIME’s explanation of the stylometry model is interesting as it shows how the model has recognised the author by subsequences of function words such as ‘and I don’t…’ (highlighted in green) rather than strong content words such as ‘police’.
However the insight provided by LIME is limited because under the hood, LIME is perturbing words individually, whereas a neural network based text classifier looks at patterns in the document on a larger scale.
I think that for more sophisticated text classification models there is still some work to be done on LIME so that it can explain more succinctly what subsequences of words are the most informative, rather than individual words.
With images, LIME gives some more exciting results. You can get it to highlight the pixels in an image which led to a certain decision.

LIME highlighting in pink the parts of face images that “look like” certain people. Image credit: Ribeiro, Singh, Guestrin (2016) [2]
There is a huge variety of machine learning models being used and deployed for diverse purposes, and their complexity is increasing. Unfortunately many of them are still used as black boxes, which can pose a problem when it comes to accountability, industry regulation, and user confidence in entrusting important decisions to algorithms as a whole.
The simplest solution is sometimes to make compromises, such as trading performance for interpretability. Simplifying machine learning models for the sake of human understanding can have the advantage of making models more robust.
Thankfully there have been some efforts to build explainability platforms to make black box machine learning more transparent. I have experimented with LIME in this article which aims to be model-agnostic, but there are other alternatives available.
Hopefully in time regulation will catch up with the pace of technology, and we will see better ways of producing interpretable models which do not reduce performance.
References
Dive into the world of Natural Language Processing! Explore cutting-edge NLP roles that match your skills and passions.
Explore NLP Jobs
Fast Data Science Ltd’s flagship AI platform, the Clinical Trial Risk Tool, has been accepted as a supplier on the UK Government’s G-Cloud 15 framework.

We are pleased to announce that Thomas Wood, director of Fast Data Science, will be appearing as a panelist at the Bond Solon Expert Witness Conference on 6 November 2026 at Church House, Westminster in London. This follows Thomas’s recent appearance at the Ireland’s Expert Witness Conference on 20 May 2026.
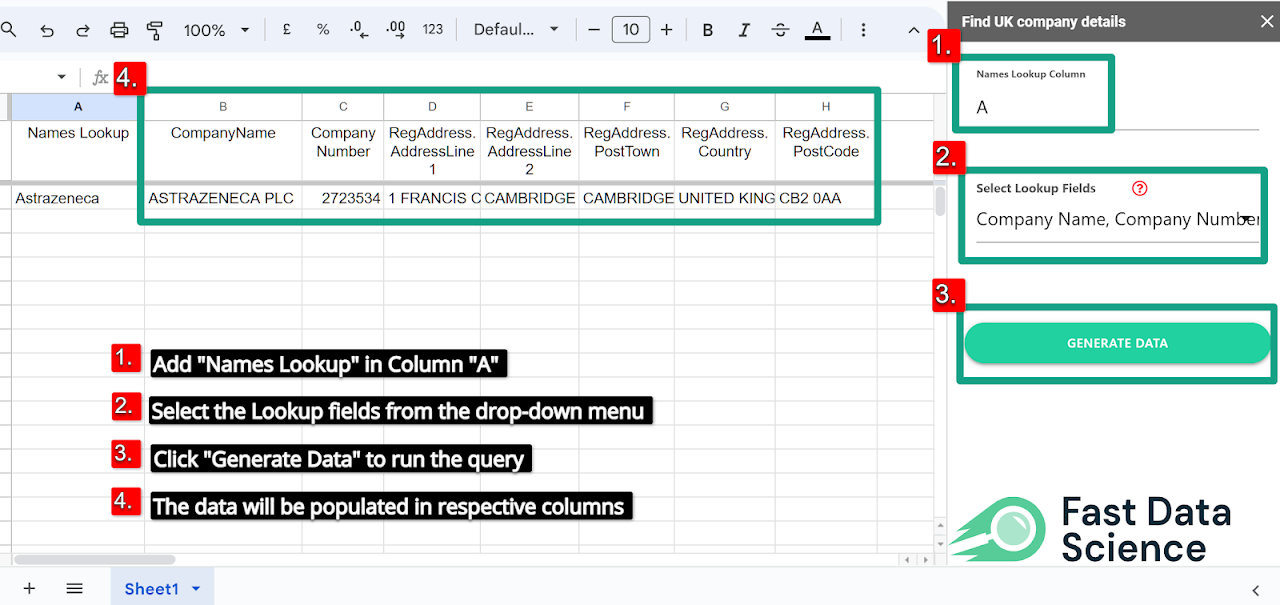
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.
What we can do for you
{kind=link}