
Many applications of machine learning in business are complex, but we can achieve a lot by scoring risk on an additive scale from 0 to 10. This is a middle way between using complex black box models such as neural networks, and traditional human intuition.
Imagine that you have the task of predicting a high school student’s chance of graduating. Which would you trust more: the prediction of that student’s class teacher, or a scoring recipe like the one below?

Hypothetical scoring algorithm for a high school student, to predict the risk of not graduating.
In 1954, the psychologist Paul Meehl wrote a groundbreaking book called Clinical Versus Statistical Prediction: A Theoretical Analysis and a Review of the Evidence, where he compared the accuracy of clinical predictions made by healthcare professionals to statistical predictions made by scores and algorithms, and found that the numerical scoring methods outperformed human professionals.
In the years since Meehl’s publication, algorithms have become widespread for many problems where professional intuition does bring value, but there is also a high degree of uncertainty and unpredictability.
Algorithms have been shown to outperform expert intuition for tasks such as predicting the length of hospital stays, diagnosis of cardiac disease, risk of criminal recidivism, and susceptibility of babies to sudden infant death syndrome, among other problems.
In fact, checklists, scores and algorithms could well outperform human intuition in about 60% of cases (see the excellent book Thinking Fast and Slow by Daniel Kahneman, who won the Nobel Memorial Prize for Economics in 2002 for his work in applying psychological insights to economic theory. There is an interesting chapter called Algorithms vs Intuition).
A university contacted us with a need to understand the dropout levels of their students. I asked the student welfare officer of the university what they understood to be the main factors that cause students to drop out, and they told me that household income, single parent families, and student grades were the main factors.
We were provided with an anonymised database of the student roster over a period of several years, together with information about student grades, application dates, and data on the students’ socioeconomic backgrounds. The organisation had a system whereby students who were identified as being at risk of dropping out from their studies would be contacted by a student advisor, who offered support and attempted to get them back on track. It was not possible to give every student a one-on-one intervention, so these interventions had to be targeted.
Also important to the education provider was the fact that government funding is allocated on the basis of total student enrolment by a particular cut-off date, so the objectives of the study were to understand the drivers of student attrition, and to reduce student attrition both overall and at a set of key dates.
We tried building a number of different predictive machine learning models, including a complete black box approach such as Microsoft Azure machine learning (a drag-and-drop machine learning interface), random forest, and a simple linear regression model.
The linear regression model gave this following scoring recipe:

This linear scoring model is an effective business application of machine learning.
This score gives a minimum value of 0 and a maximum value of 100.
Surprisingly, this score, which can be worked out with pen and paper or Excel by administrators, outperformed the more sophisticated machine learning models. It also proved to be more accurate than the institution’s current system of targeting interventions according to the teachers’ intuition.
What’s also nice is that the score can be fed into a sigmoid function formula and converted to a probability of the student completing their course (between 0 and 1).
You can experiment with some values in the spreadsheet below. Can you simulate a student who is very likely to complete, or very likely to drop out of the course?
| Attribute | Weight (B) | Input for this student (C) | Score (D) | Formula for column D |
|---|---|---|---|---|
| start at score | 40 | 1 | 40 | =B2*C2 |
| good grades | 5 | 5 | =B3*C3 | |
| low household income | -10 | 0 | =B4*C4 | |
| single parent family | -10 | 0 | =B5*C5 | |
| age above 18 at start of course | 5 | 20 | =B6*C6 | |
| student applied early | 35 | 35 | =B7*C7 | |
| student applied late | -10 | 0 | =B8*C8 | |
| student had poor attendance | -10 | 0 | =B9*C9 | |
| TOTAL SCORE | =SUM(D2:D9) | =SUM(D2:D9) | ||
| probability of dropping out of course | =1/(1+EXP(D10*0.04-0.3)) | =1/(1+EXP(D10*0.04-0.3)) |
By creating a student with good grades, high household income, etc, you should be able to create a student with score 100. Likewise, if you set all values to 0 except those with negative weights (low household income, single parent family, student applied late, student had poor attendance), you can output a score of zero, representing a high-risk student.
We calculated that if the lowest scoring 15% of students were given a targeted intervention, the institution could improve retention rates significantly.
I imagine a similar model could be designed for employee turnover prediction.
A vital part of lead management for business is a lead scoring model. B2B businesses in particular need to be able to evaluate and rank incoming leads based on how likely they are to become a customer, and how much revenue they are likely to generate if they do convert.
I took a dataset of incoming sales enquiries which Fast Data Science received, and was able to train the following logistic regression model:

Scoring model for incoming sales leads received. This generates a score between 0 and 100.
I found that this simple scoring method could classify leads with 75% accuracy and AUC 82%, which is as good as a text-based classifier on the same data, but far more understandable for the user.
It’s easy to see at a glance from looking at the scoring algorithm that messages containing links, or originating from Hotmail accounts rather than corporate accounts, are most heavily penalised (as we would expect).
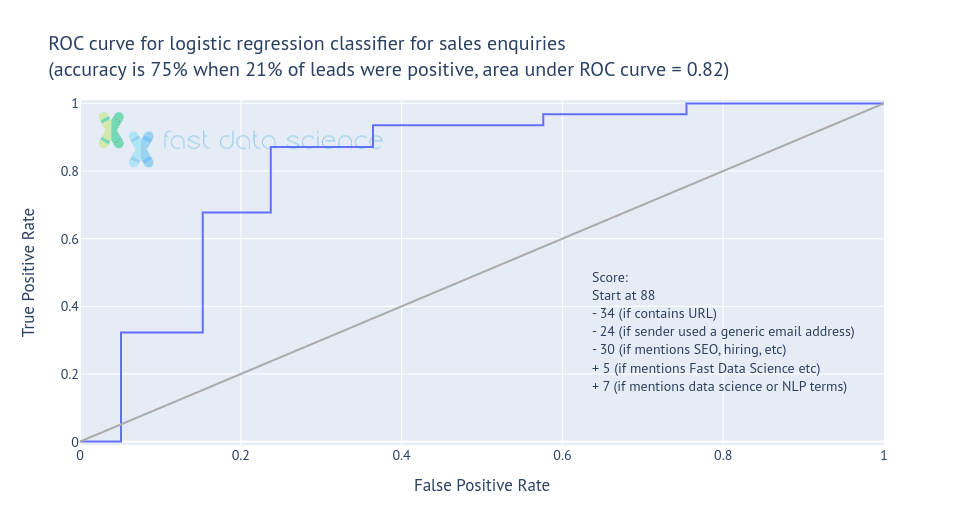
Machine learning for business: the scoring model was able to predict lead value 75% of the time.
You can test out this lead scoring model if you try filling out the contact form below. Try writing out a message with a lot of hyperlinks to see how it affects the score!
Name:| start at score | 88 |
| message text contains URL | 0 |
| sender used generic email | 0 |
| message text contained negative keywords | 0 |
| message text mentions [Fast Data Science](/fast-data-science-company) or relevant people by name | 0 |
| message text contains industry-relevant keywords | 0 |
| TOTAL SCORE | 88 |
| probability of lead | 33.3% |
(How it works: I wrote a few regular expressions in Javascript to scan the message content for any keywords that affect the score.)
A scoring recipe like this is hugely helpful to organisations because the model is explainable. The weights assigned to the risk factors allow a transparent view into what is driving risk.
In particular, it was not immediately obvious that a student’s course application date could be a risk factor, although intuitively we can understand that a student applying to a course late in the year may not have thoroughly thought through their study options, or may have applied to that institution as their second choice after being rejected elsewhere, which could be correlated with risk.
Besides transparency and explainability, the other clear advantages are that you don’t need to deploy a machine learning model in order to calculate risk, and it can be done on paper.
If you choose a simple linear scoring model like the student risk model or B2B lead scoring model above, there are a few pitfalls to look out for:
if the relationship between the data is not linear, the model will not be able to handle it.
if there are huge outliers (for example, an employee who earns 10 times as much as everybody else), linear regression cannot cope with these cases.
any complexity of interaction between features is lost. For example, grades may be of no consequence for higher-income students but make a large difference for lower-income students.
Linear regression does not work as well when some of the inputs to the model are correlated with one another, or influence one another.
Due to its simplicity, a lot of care must be taken in choosing the features that you use in a model like this. The easiest features to work with are often binary values.
By now it is no surprise that formulae and machine learning have outperformed expert intuition in many fields. Kahneman and Meehl both suggest that the problem could be that human decision-makers are prone to to information overload: they overestimate the influence of insignificant factors on the outcome.
For example, the educational institution mentioned above considered students who had been in foster care homes as high risk, whereas the linear regression model shows that once previous grades, application date, and social deprivation level of their home address were known, information about foster care history added no more value to the prediction.
So, when should an expert listen to their gut feeling and allow their intuition to override an algorithm’s prediction?
Paul Meehl asserted that clinicians should rarely deviate from algorithmic conclusions. An example he gave is the famous “broken leg” scenario: an algorithm predicts that a professor is 90% likely to attend the cinema. But we have an additional piece of information: the individual recently broke his leg. This is objective evidence which should override the 90% prediction of the algorithm. However, Meehl argued that clinicians rarely have access to this kind of information, and can therefore rarely afford to disregard algorithmic predictions completely.

Data is not always available to train a formula using linear regression as in the two examples I gave above, but additive scoring models can also be derived from human intuition, and backed up with data afterwards if necessary.
We are working on a similar project where clinical trials are scored for risk, and the client has helped us to come up with a recipe to score clinical trials between 0 and 100, where 0 corresponds to high risk and 100 would be low risk. Since quantitative risk data wasn’t available, we had to use our intuition and a voting system among subject matter experts in order to determine the weights assigned to the inputs. However, the structure of the final model is identical to that of the regression models described in my case studies above.
A clinical trial which contains a statistical analysis plan, or which has used simulation to determine sample size, is a well planned clinical trial and would score highly on the scale, whereas clinical trials which plan to recruit a small or inadequate number of participants would get a low score. You can read more about the factors contributing to the risk of a clinical trial ending uninformatively on the project website.

Historically, obstetricians and midwives always knew that infants who did not start breathing immediately after birth were at high risk of adverse outcomes such as brain damage or death. Normally, they use their clinical judgement and expert experience to determine whether baby was at risk or not.
In 1953, the anaesthesiologist Virginia Apgar was asked by a medical resident how she would make a systematic assessment of a newborn baby. She was able to come up with five variables off the top of her head, which were: heart rate, respiration, reflex, muscle tone, and colour, which could each be scored low, medium or high. She turned this into a regression formula now known as the APGAR score:
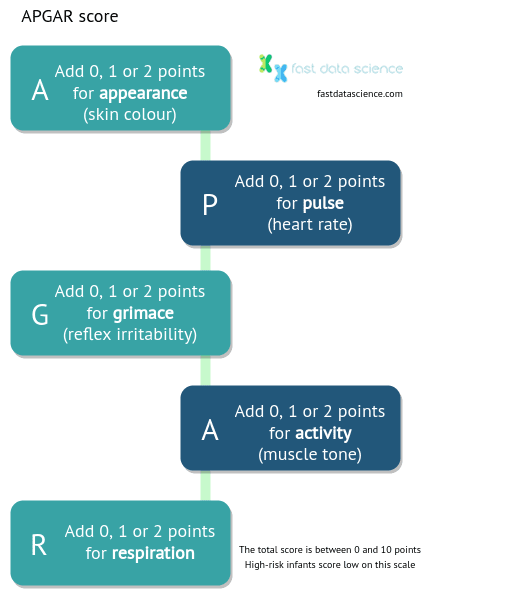
The APGAR score was one of the pioneering checklists to be widely used in the medical field. It expresses a newborn’s risk on a scale from 0 to 10.
In 1955, Dr Apgar analysed the APGAR scores of 15348 infants and was able to establish an association between low APGAR scores and asphyxia.
The APGAR score is now credited with saving the lives of thousands of infants worldwide, although it has now been superseded by other scoring methods due to advances in medicine.
Although the APGAR model is itself simple, the genius of its design lies in the selection of features.
Another linear scoring model I found is in the game of chess. Players often calculate the strength of their pieces on the board using the following scoring model:
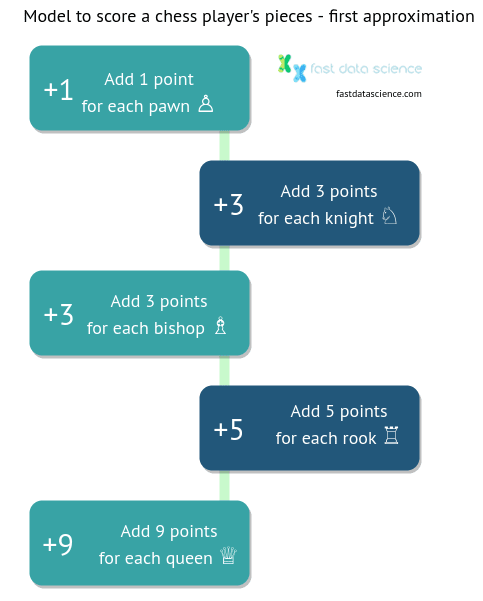
Although the score is not part of the rules and has no direct effect on gameplay, it helps learners to quickly understand the relative values of a chess piece and assess the value of captures and exchanges.
As a first approximation, the linear scoring model is very useful and so it features in most introductions to the game.
The above scoring model has been used since the 18th century. It has been adapted for computer algorithms such as Stockfish, which scores board configurations in “centipawns”, where a knight is worth approximately 300 centipawns, and so on.
In chess scoring models like Stockfish, the values of pieces vary according to the board configuration and stage of the game. Pieces with a long range such as rooks, queens and bishops become more powerful towards the end of a chess game, as the board becomes less cluttered, and values are also affected by what other pieces a player and the opponent possess.
At Fast Data Science we have adapted the risk and complexity model approach used in the pharmaceutical industry for data science (NLP) projects. In the Resources section of our website, you can find a risk checklist for identifying high-risk NLP projects, as well as an Excel cost modelling tool for NLP projects. The parameters of these tools were derived by running a regression model on some of our past projects to identify key factors contributing to cost, complexity, and risk.
A simple model such as linear regression has very few parameters, being an additive process whereby inputs are added with different weightings. Provided that sensible inputs are used, there is not much that can go wrong.
I really like the transparency that comes from a simple score on a scale from 0 to 10, or 0 to 100. Humans find probabilities hard to interpret. We have been dealing with concepts such as probabilities on a very short evolutionary timescale, and I don’t think the human brain handles them intuitively.
Daniel Kahneman conducted a number of behavioural experiments offering wagers (monetary bets) to volunteers, where he was able to show that the participants consistently overestimate small probabilities such as a 1% chance of winning $100, and underestimate large probabilities such as 99%, leading them to irrationally accept or reject bets with these kinds of odds.
A scoring model sidesteps our probability blindness and can be understood by stakeholders. However, as I showed above in the example of the student attrition risk model and the lead classifier model, a score on a scale from 0 to 100 can still be converted to a probability (or something resembling one) using the Sigmoid function or an alternative, and therefore provides the best of both worlds.
Sometimes data is available to train a scoring model using logistic regression or a similar statistical algorithm, but even if human intuition is used to build one from scratch, as in the case of the APGAR score, there is still value in having a checklist to score.
It’s important to note that although these scoring models are useful for making predictions, they do not tell us anything about cause and effect. For example, if we know that a student who sent in a late application for studies is more likely to drop out, this allows us to identify high-risk students, but it does not mean that a late application caused a student to drop out of their course. It is quite possible that a further, unknown, factor (home life, motivation, etc) caused the student to apply late and also affected their academic performance.
If you are interested in identifying the causes of a particular outcome there are other tools available. The simplest option is the intervention used in the early stages of drug development in the pharmaceutical industry: the randomised controlled trial (RCT), where participants are divided at random into two groups and one group receives an intervention while the other serves as a control.
When interventions are not an option either due to practical or ethical constraints, economists and statisticians sometimes use pseudo-experiments, such as instrumental variables estimation. I have written a blog post about causal machine learning, where I attempted to explore causality from a machine learning perspective.
We can deliver a lot of value to organisations and businesses with simple machine learning models, provided the features are selected with care. For example, the lead classifier model above depends on a smart choice of keywords, and I chose the keywords after generating word clouds from the data. Likewise, Dr Apgar was able to choose which criteria to feature in the APGAR score because of her clinical experience.
Because regression models are so simple, it is very easy for users to understand how different factors influence an outcome and see at a glance which factor dominates.
Although regression models are not always the most accurate, their simplicity may mark them as the most appropriate model for implementation in a business setting.
Professionals in a variety of fields, from medicine to engineering to law, are overwhelmed by the amount of information and training that they must remember, and checklists and scores help us to keep track of which factors are important and which are insignificant.
Atul Gawante, The Checklist Manifesto: How to Get Things Right (2011)
Daniel Kahneman, Thinking Fast and Slow (2011)
Paul Meehl, Causes and Effects of my Disturbing Little Book (1986)
Paul Meehl, Clinical Versus Statistical Prediction: A Theoretical Analysis and a Review of the Evidence (1954)
Robyn M. Dawes, The Robust Beauty of Improper Linear Models in Decision Making (1979)
Virginia Apgar, A Proposal for a New Method of Evaluation of the Newborn Infant, Current Researches in Anesthesia and Analgesia (1953)
Ready to take the next step in your NLP journey? Connect with top employers seeking talent in natural language processing. Discover your dream job!
Find Your Dream Job
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.

This is an article based on my presentation on “The Role of Artificial Intelligence in Expert Investigations and the Preparation of reports” which I gave at the Expert Witness Conference on 20 May 2026.

Many companies and organisations have large datasets that are stored in a very unstructured format. For example, you could work for a US based healthcare provider or insurer and have patient records stored in a free text format such as HL7 files or PDFs. A building regulator, land registry, or mortgage provider may have texts and accompanying diagrams from thousands of building inspections or land title deeds. A patent attorney’s office may have records of patent applications in PDF format.
What we can do for you