
One challenge that large organisations face today is the problem of understanding and predicting which employees are going to leave the business, called employee turnover prediction or workforce attrition prediction.
Employees do not always participate in offboarding processes, may not be truly forthcoming in the HR exit interview, and by the time the exit interview comes around it’s too late to address the issues which caused the employee to leave in the first place.
Furthermore, if you have a large workforce, then you may want to be able to predict which employees are at risk of leaving at any given time, how long they are expected to stay, and get a hint of which interventions may have a chance of reducing attrition.
Fortunately most organisations today will have some form of employee database. This can be a gold mine for data scientists who want to analyse, explain or predict employee turnover, and one of the most exciting applications of AI in business.
We’ve undertaken a number of projects in the area of employee turnover analysis, from predicting employee attrition for the UK’s National Health Service through to predicting student attrition (dropping out) for higher education institutions and the Scottish governmental body Skills Development Scotland. In both cases we analysed the causes of attrition and developed a churn prediction model which could be used to mitigate the problem.
This problem of employee turnover analysis is a little trickier than predicting customer spend. Any employee database is going to have a hi ghly sensitive information. If you are in the UK or EU, the GDPR limits the type of analysis you can do on an employee database, the actions you are allowed to take based on employee data, and even the technology you can use. You may not be able to use external data storage and processors such as cloud services, and if you do you will be restricted to European servers.
Typically around your organisation you will have a disparate set of databases such as salary databases, employee address databases, onboarding and recruitment records, etc. They are probably maintained by different departments.
The first step would be to find a way to unify the datasets so that for every current and past employee you can easily access all data about them. You want to know when someone joined the organisation, when they advanced pay grades, and when they left.
Here a point about data strategies which you can adopt as an organisation to make employee turnover analysis easier:
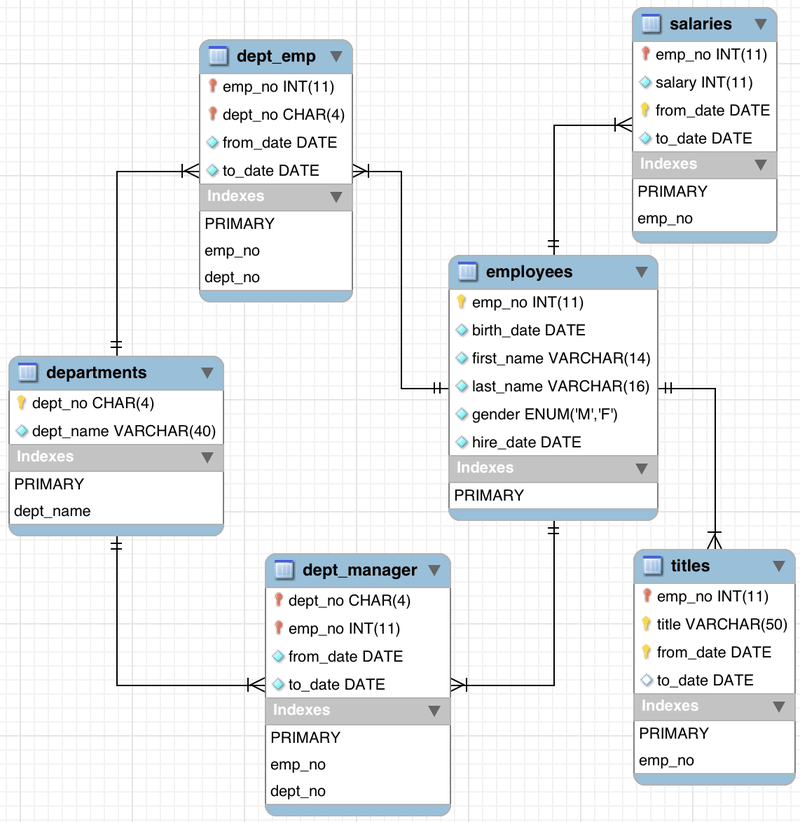
An employee database consists of several tables joined together by IDs. In practice in a company there would be data on employees scattered across different systems such as payroll, timesheets, recruitment, HR, accounting etc so there is a considerable amount of work needed to connect them in order to develop a model for predicting employee turnover. Image source: MySQL at dev.mysql.com.
Once you have found out how to join together each employee’s record, the next step for employee turnover analysis is to try to transform a dataset into a single flat table, which is the easiest format to feed into a machine learning algorithm.
Employee turnover analysis
There are many ways of transforming your employee data into a single table but here is one of the simplest:
You create a single table representing every employee present in the organisation on 1 January 2019, with columns for values such as the time they have spent in the organisation, and a final column set to TRUE or FALSE (a Boolean value), indicating whether they left the organisation by 31 January or not. This can be your training data.
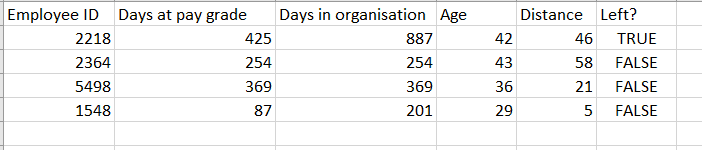
An example employee table. The final column is a Boolean value which is what we want to predict. Note that Age will be age on 1 Jan 2019, not the employee’s current age. Each employee has its own row, so this table can be input directly into a model for aalysing and predicting employee turnover.
Then create the same snapshot table for 1 January 2020, which can be your test data.
You can be creative with your columns. For example if you have the employees’ home address on the snapshot date then you can calculate their distance to the office, travel time, etc. The important thing is that all values in your table should be the values at the date of the snapshot, so the distance in the training table should be the distance from the office on 1 Jan 2019 to their home on 1 Jan 2019, and likewise the age should be the employee’s age on that date.
This latter point is quite tricky to get right, and if you are doing the joining operation in SQL you will need to use window functions.
Now you have both tables, you can feed them into a machine learning algorithm of your choice. You tell the algorithm these two things:
I know the employee’s age, distance to the office, time at pay grade, time in the organisation
I want to predict the employee’s turnover over the following month
If you like Python I recommend to try a Random Forest or Gradient Boosted Tree, or you can also use a cloud based auto ML tool such as Microsoft Azure or Google Cloud Platform. There are a plethora of tutorials available to get started.
Make sure to exclude the Employee ID from the analysis, since otherwise you run the risk of your model just memorising which employees have left!
You can train your model on the 2019 data and evaluate on the 2020 data. If it performs well then you know your model is robust enough to learn patterns and apply them on a cohort of employees a year in the future.
It means that you can analyse the current cohort of employees and produce a ranking of those who are most at risk of dropping out, allowing your human resources department to target retention measures effectively.
(In practice I would not just make a snapshot on a single date but rather take various snapshots throughout the year, trying to keep even amounts of data from every month to eliminate bias from seasonal effects. There is no reason to limit the monitored period to 1 month either - you can always train it to predict attrition in the next year or decade if you have enough data.)
Of course your model will not have foreseen the Covid-19 pandemic. This will always be a limitation of machine learning, which involves learning patterns from the past to apply to the future. However you can design any system using your model to allow for a manual ‘adjustment factor’, for example to let you adjust attrition for all employees by a user defined constant during an economic downturn.
Most machine learning models will allow you to look inside and analyse how they are making the decisions that they return. This is called model explainability, or feature importances: (read more about explainable AI, or XAI)
 model in [Scikit-Learn](https://scikit-learn.org/stable) Python library.](https://fastdatascience.com/images/Feature-importances.png)
Example of the feature importances output of the Random Forest model in Scikit-Learn Python library.
If you find that distance from home to office is a major factor in attrition then you can adjust recruitment policy to prioritise candidates who live close by, or include a relocation package, or put on a company bus or car pooling scheme. Of course you can’t use this information to discriminate on age.
The benefits of applying an employee turnover prediction model like this extend beyond its pure prediction capabilities towards insights that can modify the operations of the organisation as a whole. The employee turnover analysis cost savings to the organisation are two-fold as HR professionals can use the model’s explanations to develop retention policies across the business and also target high risk individuals with retention initiatives.
Other than the classification model described above, I can think of two other ways I can think of that you could try to model employee turnover.
Firstly - instead of classification, why not try a regression model to predict the total time that an employee will stay in the business from a given date?
In fact, I would not recommend using regression for the following reasons: for the employees on 1 January 2019, we know how much longer everybody stayed in the company up to today, 29 April 2020, i.e. 484 days. For anybody who is still in the business at day 484, we know that their total stay is greater than or equal to 484 but we can’t define it. You would have to think of a workaround for the model for these undefined values. If you set the stay to 484, or any arbitrary large value, then you are introducing a bias which a regression model will not handle correctly. If you simply exclude these people you will introduce another bias. Statisticians would say that our data is right-censored.
If you wanted to use machine learning to predict the total remaining time someone will stay in the business, then I would suggest to train a separate classification model to predict attrition within 1 month, 2 months, etc, and combine them when you want to make a prediction.
As another alternative to the classification model, one possible alternative tool we could use from statistics might be survival analysis.
This is used for example in clinical studies on diseases with high fatality rates (mainly cancer, heart attack and stroke patients), to analyse the proportion of a starting cohort or patients who have not died by various points in time.
The survivals can be plotted on a curve called a Kaplan-Meier curve:

Kaplan-Meier survival curve for patients with Acute Myeloid Leukaemia, divided into two groups, one receiving treatment and the other not.
You can also calculate a number called the Kaplan-Meier estimator which is an approximation of the survival rate at any point in time.
Survival analysis is robust to right-censoring and so could be used to analyse employee attrition on a longer time scale than the machine learning model. However, survival analysis becomes more complex to use when we are predicting from lots of independent variables (commute length, age, pay grade etc).
I am not aware of any businesses using survival analysis to predict employee attrition but I would be interested to hear if anyone is doing it.
Ready to take the next step in your NLP journey? Connect with top employers seeking talent in natural language processing. Discover your dream job!
Find Your Dream Job
This is an article based on my presentation on “The Role of Artificial Intelligence in Expert Investigations and the Preparation of reports” which I gave at the Expert Witness Conference on 20 May 2026.

Many companies and organisations have large datasets that are stored in a very unstructured format. For example, you could work for a US based healthcare provider or insurer and have patient records stored in a free text format such as HL7 files or PDFs. A building regulator, land registry, or mortgage provider may have texts and accompanying diagrams from thousands of building inspections or land title deeds. A patent attorney’s office may have records of patent applications in PDF format.

On 20 May, I attended the Expert Witness Conference in Dublin, Ireland, organised by La Touche Training. It was an eye opening event with a mixture of lawyers and expert witnesses in different fields from Ireland and abroad. The event was chaired by Mr Justice Michael Peart, with a keynote address by the Honourable Mr Justice David Barniville, President of the High Court of Ireland.
What we can do for you