
What is unsupervised learning?
When we think about acquiring a skill or learning a new subject, most of us see that process involving a teacher passing their knowledge on to us. If you’re teaching a child how to distinguish between different fruits for example, you might show them various images, identifying one as an apple, another as a pear and so on, so that when the child sees these fruits in real life, they can recognise which is which themselves, but initially via the labels you provided. This is known as supervised learning, and is one way in which Artificial Intelligence uses Machine Learning to predict particular outputs, having used data points with known outcomes. However, this is not the only way we, or computers for that matter, learn. Let us introduce to you Unsupervised Learning.

What we give to a supervised learning algorithm

What we give to an unsupervised learning algorithm.
A supervised learning algorithm is shown examples of fruit and told which they are. An unsupervised learning algorithm learns like a toddler: it learns that there are green fruit, orange fruit, yellow fruit and red fruit, and they have different sizes and textures, and eventually it finds patterns and comes up with its own labels for them.
Many projects involving AI in business don’t have neatly labelled data available, so we often have to think outside the box and use unsupervised learning techniques.
Not everything we know is because it’s been taught to us; some of it we’ve learnt ourselves, working things out by observation, connecting the dots one to the other, unassisted, unsupervised. Machines and programs can learn this way too, and it’s known as unsupervised learning.
Let’s look at how we learn unsupervised: one fine summer Saturday, a friend calls you up and tells you that Trevor has been a flake again (oh Trevor). Because of that, there’s a spare ticket to watch the English cricket team play Australia. It’s a bright sunny afternoon, you’re in need of a pint, and it sounds like the seats are pretty decent. There’s just one thing: you have no idea what the rules of cricket are. Regardless, you go anyway - after all, that beer is calling. You take your seat, and the match begins.

If you learn the rules of cricket by observation only, this is an analogy for unsupervised learning.
This is where you start learning about the game: you analyse the movements between the players, the signals of the umpires, and the reactions of your friends. There are two teams, one in white, the other in yellow. Your English friends cheer whenever the white team look happy and the yellow team look sad - so you conclude England must be in white, and Australia in yellow. There are 15 people on the field: 11 in white, 2 in yellow and another 2 in long coats and black trousers. This latter group don’t interfere with play, and instead are presiding over the game and enforcing rules - they must be the umpires. If the ball is caught by the fielders, the batsman leaves the field of play - clearly hitting the ball into an opposing player’s hands means you’re out. All these conclusions are inferred by your observation, picking up the rules yourself from various trends and similarities compiled without anyone else telling you or “attaching labels” to them. This is unsupervised learning - but how does it work in the context of AI and Machine Learning?
Machine learning can broadly be assigned to three categories: unsupervised learning, supervised learning, and reinforcement learning.
As mentioned previously, the biggest difference between unsupervised learning and supervised learning is the existence of labels (or not) within the dataset. Let’s say you have a number of flower photos on file, and you want your program or algorithm to differentiate between images of tulips and daisies. Your first option is to add identifiers yourself, indicating whether a flower is a tulip or a daisy (this is known as labelling). Then you can give your labelled images to an AI algorithm which will try to learn the key characteristics of tulips and daisies.
Fast Data Science - London
On the other hand, you could try just feeding all of these images into a model that tries to explicitly identify two broad kinds of flowers in the dataset, without labelling.
The first (labelled) example is supervised learning. The second (unlabelled) example is unsupervised learning.
There are several benefits to using unlabelled over labelled data. First, it takes a lot of resources to label data, and you just might not have access to the necessary time or team. Secondly, the process of labelling data can be error-prone and “noisy” due to the errors or implicit biases that those who are labelling the data might have (we are human after all). Finally, labels make sense when you know exactly what you want to predict, but in many cases, you might actually want to discover new patterns in your data, conclusions that might beyond the human capacity to figure out (or least not without tremendous time and effort), but instead are well within the means of AI via Unsupervised Learning.
So, let’s say you run a florist where your flowers are currently organised by colour. Now though, you want to change up your display and organise your flowers differently. In this case, you will want to discover groups of flowers that are similar in ways you haven’t thought of before. Unsupervised learning to the rescue!
There are a few different ways in which unsupervised learning algorithms analyse their data, but the most common type is clustering. This uses data segregation based on the similarity found between data instances, and for our purpose, finds underlying traits in the flowers, which can then be categorised into different groups you never previously saw yourself.
Another common example is factory error reports. Imagine a large manufacturing company has a fault logging system. Every kind of accident or incident is logged into a database by employees in plain text. Some are simple such as ‘conveyor belt jammed’, others may be more complex such as ’the packaging was cracked during transit due to poor handling’. If you arrive on the scene as a data scientist, and the factory owner asks you to identify the ten most common faults in the factory, how would you go about it?
There is the painstaking manual approach of reading through all the reports and trying to assign them to an arbitrary set of categories. Alternatively, you can use natural language processing and unsupervised learning technique such as clustering, to identify topics and clusters.
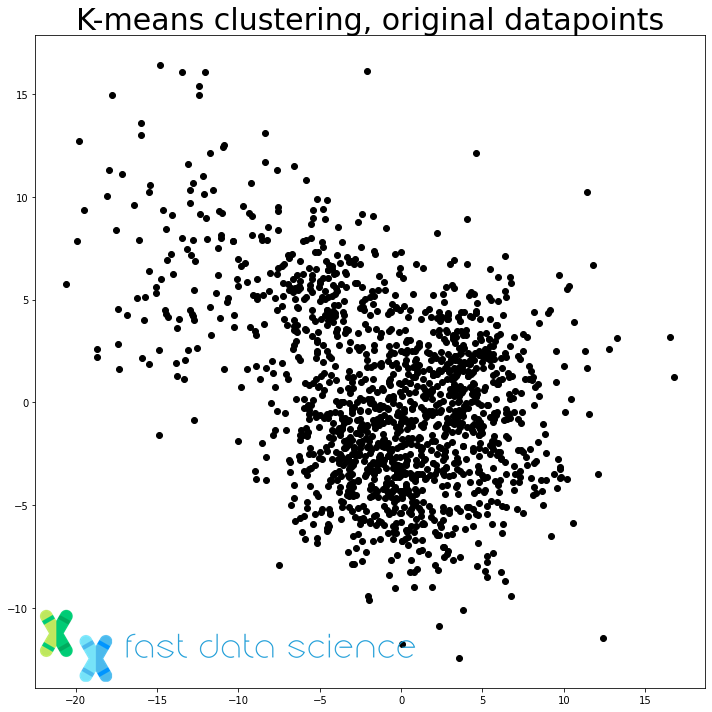
Clustering, one of the commonest unsupervised learning techniques, starts with a set of unlabelled data and discovers groups and patterns in the noise.
Cluster analysis is an important approach in the field of unsupervised learning. Because unsupervised learning doesn’t begin with labels, the output of a clustering algorithm would be assignments of each flower to a group. It charts similarities and common traits together in groups. These groups don’t have a predefined meaning, but instead are discovered through clustering. At this point, you would go through the items in each group to see what the commonalities the AI has found are. For example, you might notice that the groups correspond to flowers with different types of textures, or height, petal length or stem width. The result is a series of patterns that exist in your flowers that you might not have thought of before. Or you just might not be able to figure out what’s going on in the groups that your algorithm discovered.

Plot of sepal length vs sepal width for three species of iris flower (using the well-known Iris dataset). This data is labelled, but if the labels were taken away, a clustering algorithm would probably be able to differentiate setosa from the other two species.
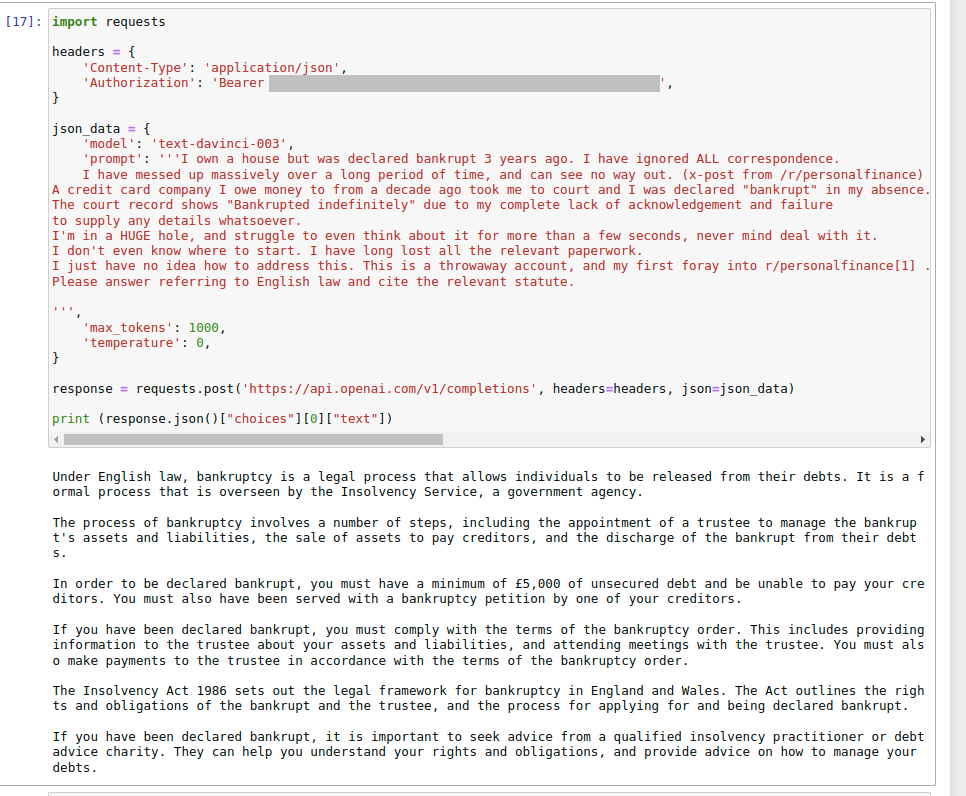
The DVLA is the organisation in the UK which inspects vehicles for road safety, the equivalent of the DMV in the United States. It’s possible to download all vehicle inspection reports in the country from the DVLA’s website. An inspection report often contains a description of the fault in plain text.

An example of vehicle inspection reports downloaded from the DVLA’s website
However, if we just have these texts and no other structured data, it would be quite hard to identify common kinds of vehicle fault.
If we want to quickly discover common themes in the reports, we can generate a word cloud of the texts, where words which are common appear in large font. This lets us see at a glance the commonest phrases but doesn’t give us a list of topics.
A word cloud for the vehicle inspection reports. We have no labels attached to the reports, so we can only use unsupervised learning to process them.
We can use an unsupervised learning algorithm called LDA, or Latent Dirichlet Allocation, to split up the reports into five topics:
Output of the LDA algorithm on vehicle inspection reports. You can see that the topics discovered appear to be to do with brakes, lights, rear of vehicle, axles, and suspension. LDA (Latent Dirichlet Allocation) is a common unsupervised learning technique used on text data.
And finally it’s possible to plot the topics in a graph space. This visualisation lets us see that topics 1 and 4 are quite close together, for example.
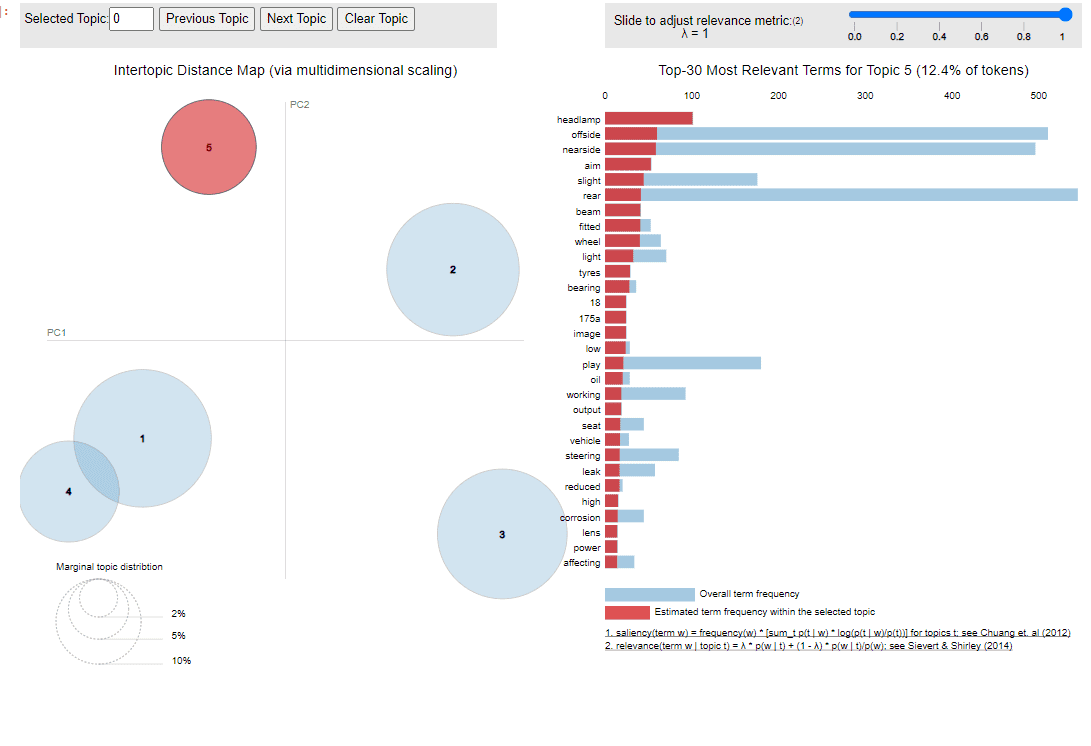
Visualisation of the LDA output on vehicle inspection reports.
The above LDA analysis is a simple example that took me less than half an hour. We can only imagine how powerful it would be for discovering topics in factory error reports, survey data, and other kinds of unstructured text data.
This is the double-edged sword of unsupervised learning: because you don’t have predefined labels, your AI program has the ability to find novel, innovative discoveries and patterns in your data. At the same time, because your AI is not learning from labels, it’s harder to predict what the algorithm is going to learn - thus you don’t have a guarantee that the output will be useful or meaningful. Yan LeCun, the director of Facebook AI Research, said:
“if intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).”
Yann LeCun
Unsupervised learning is just one but still significant, element of Machine Learning that will help progress AI towards a dependable and dynamic future.
Looking for experts in Natural Language Processing? Post your job openings with us and find your ideal candidate today!
Post a Job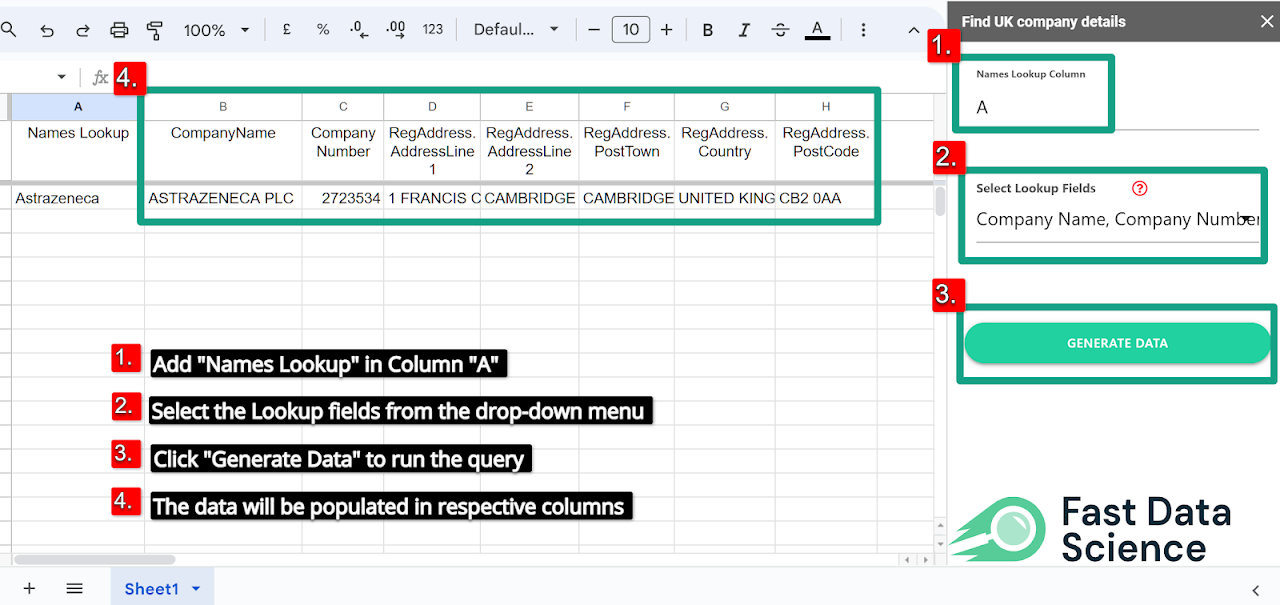
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.

This is an article based on my presentation on “The Role of Artificial Intelligence in Expert Investigations and the Preparation of reports” which I gave at the Expert Witness Conference on 20 May 2026.

Many companies and organisations have large datasets that are stored in a very unstructured format. For example, you could work for a US based healthcare provider or insurer and have patient records stored in a free text format such as HL7 files or PDFs. A building regulator, land registry, or mortgage provider may have texts and accompanying diagrams from thousands of building inspections or land title deeds. A patent attorney’s office may have records of patent applications in PDF format.
What we can do for you