How we used a Natural Language Processing clustering algorithm to assist pharmaceutical company Boehringer Ingelheim to gain insights into and discover topics in their manufacturing processes. The pharmaceutical company Boehringer Ingelheim manufactures a number of diabetes and cancer medication and animal health products. Boehringer has a large network of manufacturing facilities stretching across the globe. Drugs may be synthesised in one country, packaged in another, and shipped to a third country for distribution.
Fast Data Science - London
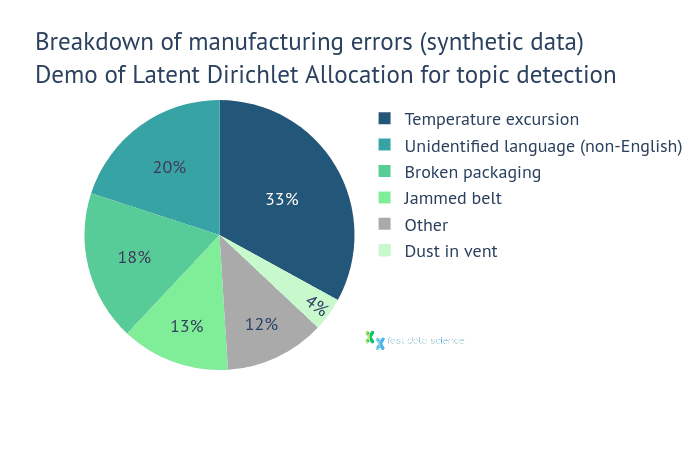
In the manufacturing, packaging and distribution facilities, employees monitor the equipment and product at all stages for any anomalies. When an error occurs, it is logged in a computer system with a free text description of the problem, such as ’temperature excursion due to blocked vent’, ‘packaging cracked in transit’, etc. Often these errors are logged in a local language rather than English.
The manufacturing and distribution team at Boehringer wanted to identify the commonest manufacturing defects and group them into categories. Unfortunately, the volume of text rendered it impractical to do this manually.
To this end, they contracted Thomas Wood of Fast Data Science to analyse the text dataset with NLP techniques. He built a clustering model (topic discovery) using Latent Dirichlet Allocation. This model was able to identify the commonest manufacturing errors and group them into clusters. The result of the static analysis allowed Boehringer to see clearly which were the main causes of manufacturing errors in their supply chain.
If you have a large number of unstructured text documents and would like Fast Data Science to assist you in topic discovery, cluster analysis, or another NLP analysis, please get in touch with us.
What we can do for you