We are excited to introduce the new Harmony Meta platform, which we have developed over the past year. Harmony Meta connects many of the existing study catalogues and registers.
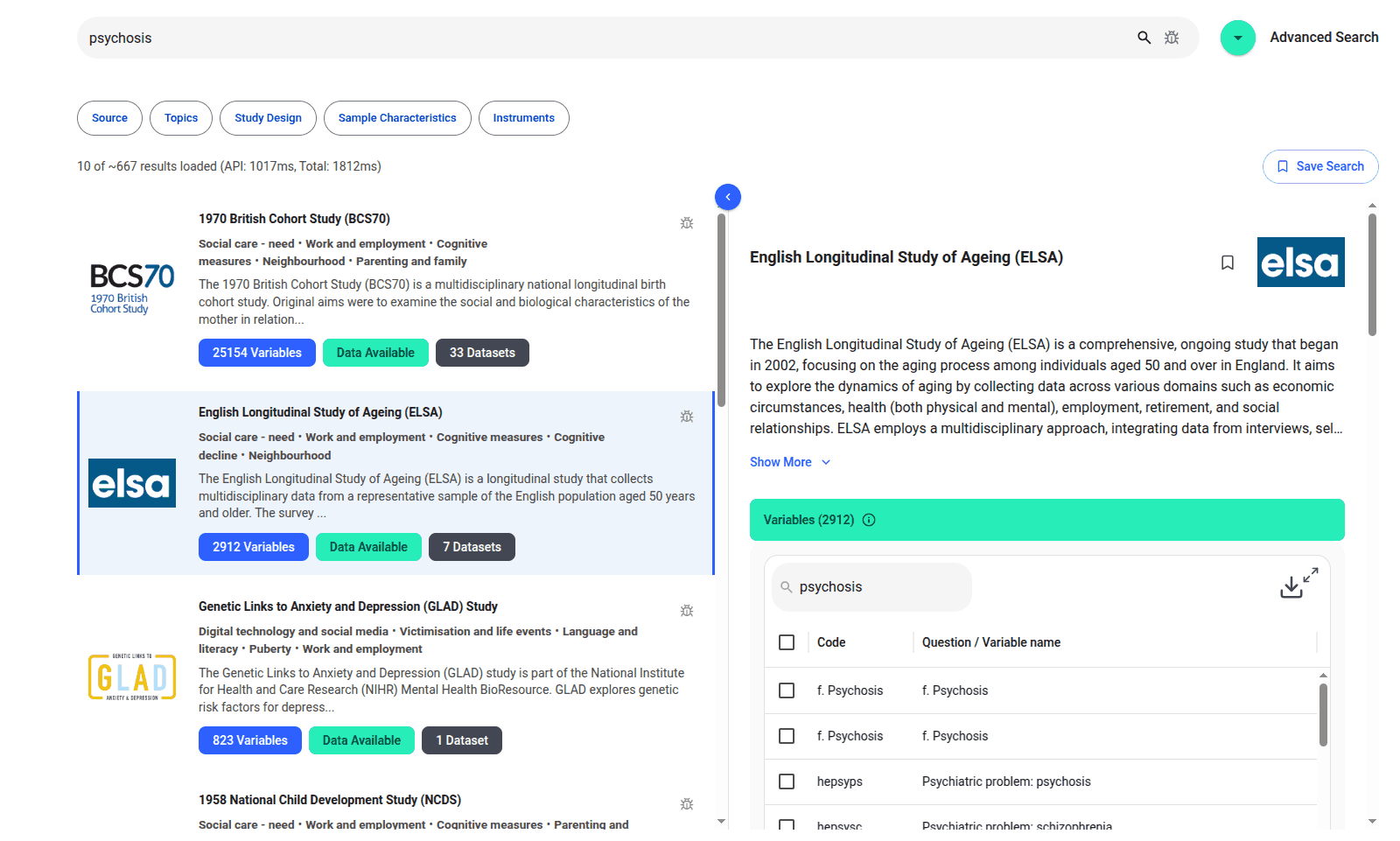
If you want to search for longitudinal studies that measured a particular variable such as “psychosis in adolescence” and you don’t know the exact wording that was used by the researchers, you can now use the AI search on Harmony Meta.
Try it here: https://harmonydata.ac.uk/search
Other examples of things you can search for
All of these will turn up studies that measured these values or approximate synonyms. If the researchers asked a question such as “difficulty reading”, your search for “dyslexia” will find it.
We have 5.5 million variables indexed. As far as I can tell, this is every large longitudinal study run in the UK ever, including well known studies such as the Millennium Cohort Study, the 1970 British Cohort Study, and Born in Bradford.
Harmony Meta works with a vector index so all 5.5 million variables are converted to vectors using a large language model.
Investigators on this project were Bettina Moltrecht and Eoin McElroy. Rachel Holland Gomes worked on the UI, John Rogers on the front end, Thomas Wood (Fast Data Science) on the back end, with Jay Dugad working on community management.
Harmony Meta was funded by ESRC, the Economic and Social Research Council. We would like to acknowledge partners Population Research UK (PRUK), UCL Centre for Longitudinal Studies, DATAMIND UK, The Alan Turing Institute, National Centre for Research Methods, UK Research and Innovation, Wellcome Trust, National Centre for Social Research, and Social Finance.
Unleash the potential of your NLP projects with the right talent. Post your job with us and attract candidates who are as passionate about natural language processing.
Hire NLP Experts
Unlock your business potential with expert AI consulting services from Fast Data Science. Discover strategies to accelerate growth and outperform competitors.

Financial advisors, like lawyers, are regulated in the UK. All financial advisors should be registered with the Financial Conduct Authority (FCA) and must have certain qualifications and have signed up to a code of ethics. UK financial advisors must also complete professional training every year.
What we can do for you
