
Why do we now need AI ethics? What is AI ethics?
The ever-expanding availability of big data and cloud computing, improved computing power, and recent developments in deep learning algorithms have paved the way for machine learning algorithms to transform nearly every industry.
The data revolution is allowing AI to improve society and quality of life in myriad ways. Essential services such as healthcare are beginning to be transformed, but as with all new technologies, we have much to learn about harmful impacts of AI. A need has arisen to study and define AI ethics.
Machine learning algorithms gain their insights from the societies that they analyse. This means that they are also able to learn implicit bias and perpetuate inequalities such as sexism and racism in their algorithms.
For example, a machine learning algorithm used to predict the likelihood of recidivism (a repeat criminal offence) may unwittingly become biased, if the past data used to train it contains a bias. If the justice system is more likely to convict a person of one race than another, then a machine learning algorithm trained on the decisions of that justice system will be subject to the same bias and prejudice. If such a biased AI is used, for example, on parole or sentencing decisions, this can result in a feedback loop where the biased AI further entrenches the disadvantages of marginalised groups in society.
An case of a biased AI was brought to the Wisconsin Supreme Court in 2017 in Loomis v. Wisconsin, illustrating how biased AI in justice systems is no longer the preserve of science fiction.
Fast Data Science - London
Fortunately, there are AI ethics methods to detect, prevent, and remedy algorithmic bias. One simple option is to play ‘devil’s advocate’ with an AI in development and subject it to a kind of bias penetration testing. This is one of the most important areas of AI ethics.
If you would like to ensure that an AI that you are developing is free of bias, please get in contact and we will be pleased to assist you with AI ethics consulting.
Many AI systems, such as deep neural networks, operate in a high dimensional space with millions of parameters, and generate decisions with minimal accountability. Imagine being denied a car loan, or being given a high insurance premium, without a comprehensible explanation.
In some cases, the lack of explainability may be acceptable. However there is often a business requirement, or regulatory requirement, or simply an ethical obligation, to provide an explanation of decisions, especially when they impact private individuals. In Europe, the GDPR guarantees a right to explanation which can be interpreted as an obligation for companies to explain AI decisions to customers on request.
The data subject should have the right not to be subject to a decision, which may include a measure, evaluating personal aspects relating to him or her which is based solely on automated processing and which produces legal effects concerning him or her or similarly significantly affects him or her, such as automatic refusal of an online credit application or e-recruiting practices without any human intervention.
EU GDPR, Recital 71
In the United States, the Health Insurance Portability and Accountability Act (HIPAA) has imposed some similar but less stringent regulations.
This has generated a need for algorithmic explanations. Companies may encounter a difficult balancing act between developing a complex model with optimal predictive power, and providing explainability, and sometimes model performance may need to be compromised in order to comply with explainability requirements.
Fortunately, improvements in computing power have allowed for nearly any machine learning decision to be ‘explained’. In cases where a model is too complex for its inner parameters to be interpreted directly, it is possible to apply a perturbation to the model input and measure any change in the model decision. A number of machine learning explainability packages and algorithms have appeared in recent years to meet this need.
If you are struggling with balancing model explainability against performance, would simply like to comply with your obligations regarding GDPR Recital 71 or similar, or would like to discuss AI ethics in more detail, please get in contact with Fast Data Science and we will arrange a consultation.
Many big data AI projects involve the storage and processing of large amounts of personal data. In many countries, tech giants have come under fire from the media and government for flagrant abuse of user consent, data misuse, unlicenced sharing with third parties, and other dubious practices. AI systems have been known to target or profile subjects in unethical ways, such as targeted advertising without consent.
It is an essential component of AI ethics to obtain user consent at the point that data is gathered to ensure legal compliance, especially as regulation is likely to change in this area in the future.
Unleash the potential of your NLP projects with the right talent. Post your job with us and attract candidates who are as passionate about natural language processing.
Hire NLP Experts
Senior lawyers should stop using generative AI to prepare their legal arguments! Or should they? A High Court judge in the UK has told senior lawyers off for their use of ChatGPT, because it invents citations to cases and laws that don’t exist!

Fast Data Science appeared at the Hamlyn Symposium event on “Healing Through Collaboration: Open-Source Software in Surgical, Biomedical and AI Technologies” Thomas Wood of Fast Data Science appeared in a panel at the Hamlyn Symposium workshop titled “Healing Through Collaboration: Open-Source Software in Surgical, Biomedical and AI Technologies”. This was at the Hamlyn Symposium on Medical Robotics on 27th June 2025 at the Royal Geographical Society in London.
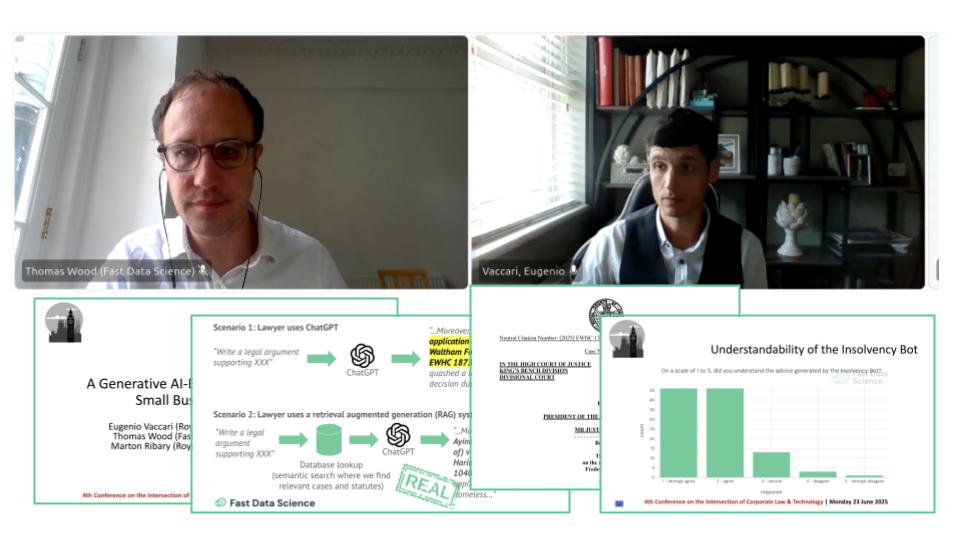
We presented the Insolvency Bot at the 4th Annual Conference on the Intersection of Corporate Law and Technology at Nottingham Trent University Dr Eugenio Vaccari of Royal Holloway University and Thomas Wood of Fast Data Science presented “A Generative AI-Based Legal Advice Tool for Small Businesses in Distress” at the 4th Annual Conference on the Intersection of Corporate Law and Technology at Nottingham Trent University
What we can do for you