Why is it so difficult to apply traditional project management to data science projects? How to make your data science project management go smoothly.
A foolish consistency is the hobgoblin of little minds.
Ralph Waldo Emerson (1803-1882)
Data science does not normally fit very well into standard project management approaches that have been long established in other disciplines. Why is this?
Data science projects traditionally involve a long exploration phase and many unknowns even quite late into a project. This is different from traditional software development, where it is possible to enumerate and quantify tasks at the outset. A software project manager may often define the duration and final result of the project before a line of code has been written.
The best known traditional project management approaches are
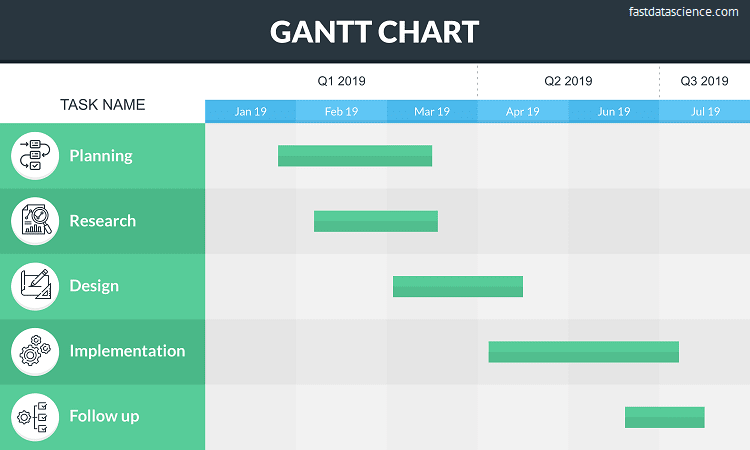
Waterfall - known for the Gantt chart, a kind of cascading bar chart showing tasks and their dependencies.
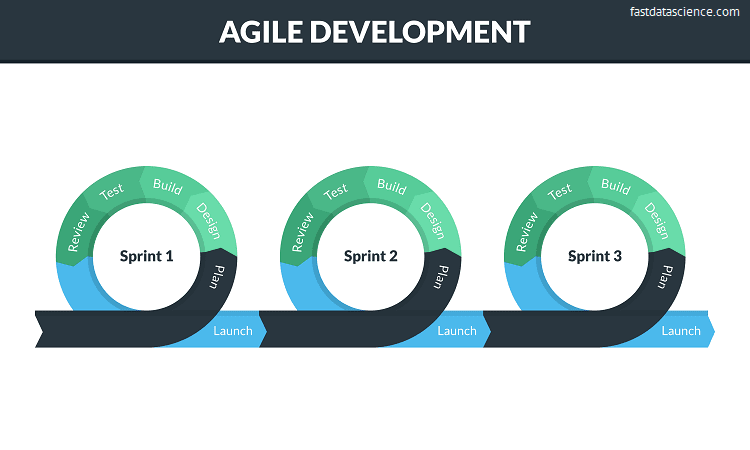
Agile - tasks divided into sprints of 1-2 weeks.
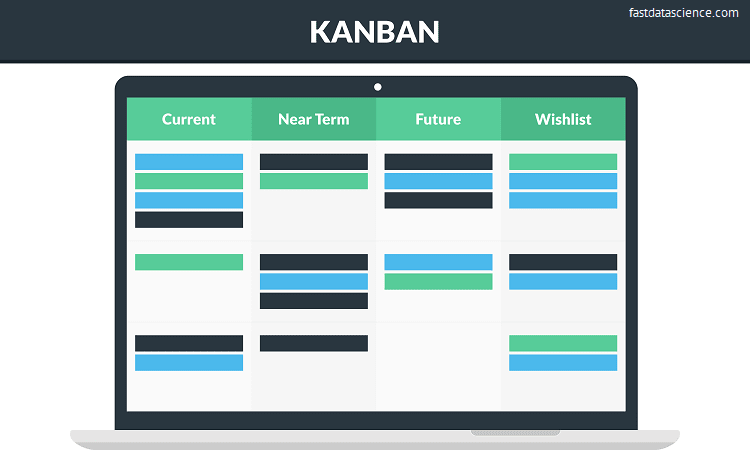
Kanban - cards moving left to right across a board from to do to in progress to done.
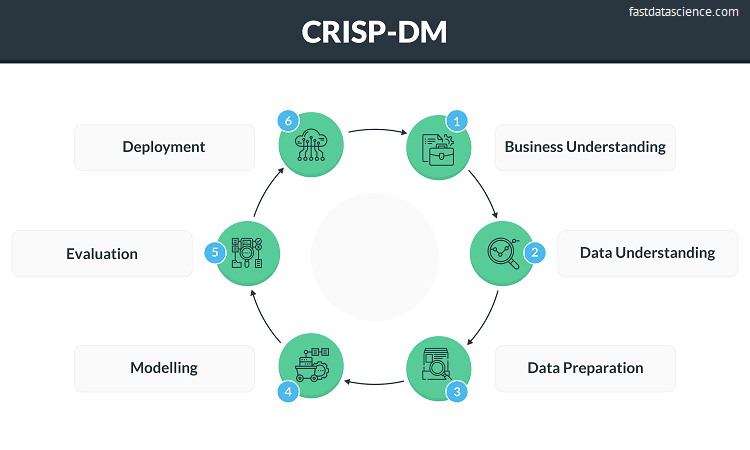
There is also a data-science-oriented project management system called CRISP-DM, which involves a series of phases of the project: business understanding, data understanding, data preparation, modelling, evaluation, and deployment.
I believe the major problem of all of these approaches is that data science projects are highly unpredictable and subject to change. Unfortunately, it is often not even possible to predict what can be achieved in a data science project until considerable effort has already been invested.
I would recommend not to decide on a project structure at all until after the initial exploration phase of a week.
Then I would suggest to decide what the business needs:
a deployed predictive model?
a standalone analysis?
a full scale website and API?
The key is flexibility, that these requirements may change later on.
Let’s take an example: a project to deploy a predictive model. Let’s assume that the commercials and buy-in from the stakeholder are already in place.
Imagine that a hypothetical business wants a predictive model to predict which products its customers will buy.
The project might proceed with the following approximate phases. (key stages of a data science project)
2-5 days: understand the business problem.
2-5 days: understand the data available. You are starting to get an idea of if the project is possible at all and whether it will be on a scale of weeks, months or years.
10-20 days: build a ‘quick and dirty’ prototype. This might run on a laptop only but gives the stakeholder a qualitative feel of what is achievable.
Stakeholder meeting: define KPIs and requirements, timescale etc. By this time you will have an idea of how long the project will take - much later than if it was a project in software development, or construction.
3-6 months: refine the model and work out how to make it run on real time data. This involves building typically 200 different models, evaluating each against the KPI. There will also be close communication with the stakeholder throughout this process as the project and model take shape.
3 months: deployment, load testing, quality assurance, making sure it integrates with the client’s systems. This involves developers on the client side and can be project managed with the usual software development tools.
Stakeholder meeting to evaluate the result of the project, close off the project, handover, documentation and plans for maintenance, etc.
Apart from the final deployment phase I would suggest that all stages of the project should be quite flexibly defined.
In particular, if you think a task should take 1 month when you first try to quantify it, in practice it will often take 2 months because of all the unknown snags that are likely to appear. Surprises can occur at any point in the project and all have the effect of lengthening rather than shortening the total duration.
The flip side of this flexibility is that regular meetings, emails and communication with the stakeholder are essential to ensure both that the business is kept up to date on the project progress, and the data scientists receive everything they need (data, access through security, co-operation from the relevant departments of the business, etc).
The key is in the name: data science. Science involves defining a hypothesis and testing it, and data science involves an iterative process of trying, failing and improving. Attempts to shoehorn it into project management techniques of other disciplines end in frustration and increase the probability of the project failing or being abandoned.
I do not want to suggest not to use Agile or Waterfall methodologies at all. In fact they may be essential especially when you have to scale a data science team. However any project management approach that is taken should be used only as a guideline but not strictly adhered to.
If you do decide to use a Waterfall project management philosophy, we have provided an in-browser Gantt chart generator for NLP projects on the Resources section of our website, as well as a a data science project kickoff checklist, a data science roadmap planner, a project cost planner spreadsheet, and a project risk tool.
Looking for experts in Natural Language Processing? Post your job openings with us and find your ideal candidate today!
Post a Job
Fast Data Science appeared at the Hamlyn Symposium event on “Healing Through Collaboration: Open-Source Software in Surgical, Biomedical and AI Technologies” Thomas Wood of Fast Data Science appeared in a panel at the Hamlyn Symposium workshop titled “Healing Through Collaboration: Open-Source Software in Surgical, Biomedical and AI Technologies”. This was at the Hamlyn Symposium on Medical Robotics on 27th June 2025 at the Royal Geographical Society in London.
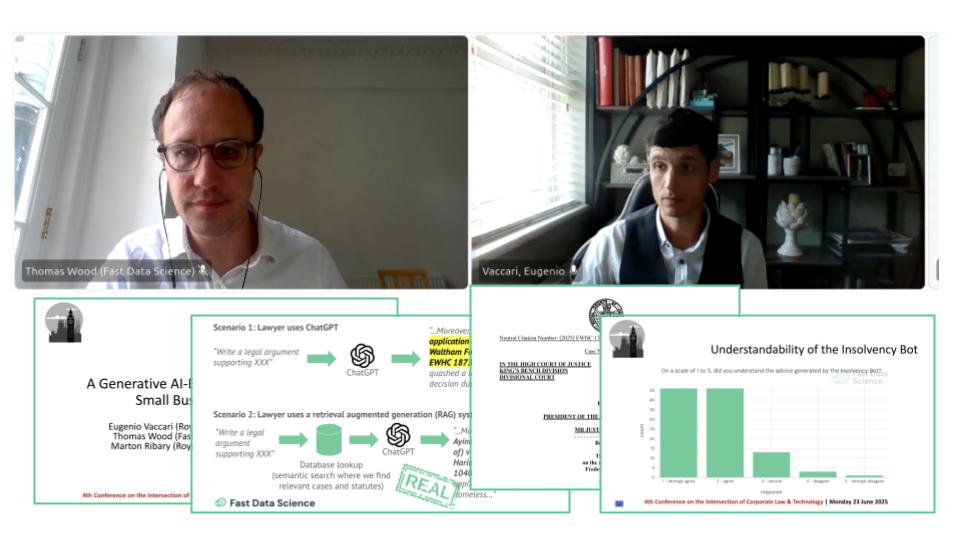
We presented the Insolvency Bot at the 4th Annual Conference on the Intersection of Corporate Law and Technology at Nottingham Trent University Dr Eugenio Vaccari of Royal Holloway University and Thomas Wood of Fast Data Science presented “A Generative AI-Based Legal Advice Tool for Small Businesses in Distress” at the 4th Annual Conference on the Intersection of Corporate Law and Technology at Nottingham Trent University

What is generative AI consulting? We have been taking on data science engagements for a number of years. Our main focus has always been textual data, so we have an arsenal of traditional natural language processing techniques to tackle any problem a client could throw at us.
What we can do for you