
Data science in an organisation starts with three separate sub-teams: the data science team, the data engineering team, and the data operations team.
If you have a small to medium-sized business which has been successful for a number of years, but has not yet ventured into the world of data science, you may be wondering how you can start a data science initiative in your business.
Initially, you can achieve some results by hiring external consultants to do your data science work, but at some point, it becomes necessary to hire a data science team.
Here I will give a walkthrough of how we approach building a data science team, and what we look for in data science teams when undertaking corporate technical due diligence investigations on AI companies.
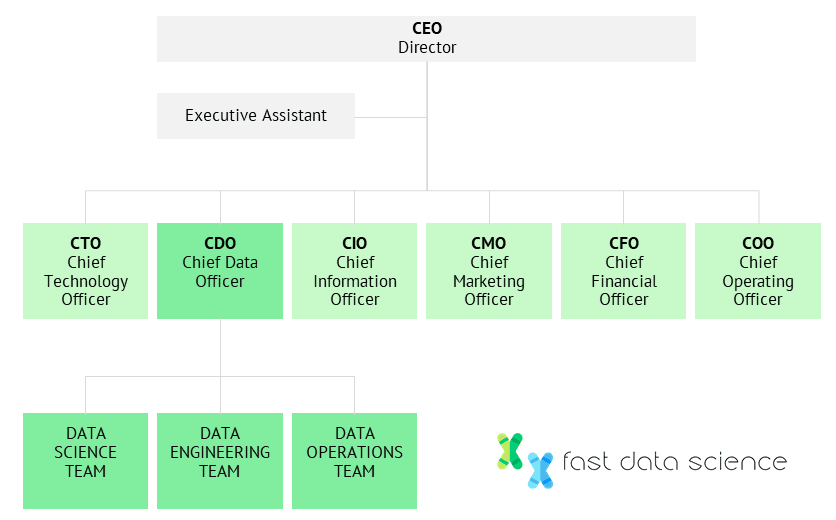
One possible organisational chart, showing the data science team, data engineering team and data operations team reporting to a C-level executive who works closely with the CTO but reports directly to the CEO. This kind of arrangement puts the data scientists in the driving seat in projects involving other departments.
Jesse Anderson, a data science consultant and leading expert in the field, recommends in his book Data Teams[1] that you hire three separate teams: the data science team, the data engineering team, and the operations team.
The data science team would consist of people with academic profiles and in-depth knowledge of machine learning algorithms.
The data engineering team creates data pipelines and deals with problems of scale.
Finally, the operations team are responsible for keeping the infrastructure running smoothly.
Anderson recommends starting by hiring a data engineer rather than a data scientist. A data engineer will be able to set up an infrastructure for data science work better than a pure data scientist. He views it as a mistake to hire data scientists first, as they often come from academic backgrounds and have little understanding of good programming and engineering practice.
The data engineer should have experience in software engineering, be interested in data science, and be particularly able to handle problems of scale, databases, data warehousing, and be knowledgeable about good programming practice.
Companies that hire a data scientist first often end up with very frustrated data scientists who have little access to the data or infrastructure that they need, and who end up quitting after six months.
Once the data engineer has been around for long enough to begin setting up the environment for data science work to take place, the time is right to hire the first data scientist. The data scientist should have excellent maths skills. Many organisations I’ve seen will only consider PhDs, or at the very least Oxbridge and Ivy League graduates – I think this is going too far. Since data science has not been around as a degree programme for very long, you probably need to consider graduates in STEM fields such as Physics and Chemistry.
Fast Data Science - London
Your data scientist will design and train machine learning models, build statistical models, and do everything related to advanced analytics.
As your data scientist produces viable models which can go into production, you will also need to hire somebody to take control of operations – the day-to-day running of the models, quality control, ensuring servers stay operational, load balancing, etc.
As time goes on you can recruit and grow the three data teams. There are a number of possible reporting structures that you can choose, however in my experience it’s best to ensure that the data science team has access to a high-enough ranking person in the organisation who can make things happen when needed. For that reason, reporting directly to the CTO, CEO or a Chief Data Officer is often a good idea.
In addition to Jesse Anderson’s excellent recommendations, I’d like to share some of the problems that I have personally observed when organisations have tried to start data science initiatives.
The data science projects will often need to borrow time and resources from other departments. For example, a project focusing on optimising deliveries in a retail business will need to interact significantly with the logistics department. If the data science team is far down in the hierarchy of the organisation, then there will be no advocate for the project in the logistics department and the data scientists will struggle to get time or commitment from that department.
Sometimes a company might have multiple data science teams working on the same problems, perhaps in different physical locations, due to historical acquisitions, or other factors. Maybe somebody was working on a machine learning project inside the marketing department before the company-wide data science department was founded. This can lead to a turf war as managers in different parts of the company compete to take credit for snazzy data science projects.
Managers with many years of experience in charge of software developers can be prone to viewing data science as an extension to software development projects, which means imposing strict deadlines on data scientists to deliver particular results, or even worse, KPIs (you get paid a bonus at the end of the month if your model achieves 98% accuracy).
In software development, it is possible to split a project into a series of independent tasks. A PhD research project, on the other hand, consists of a series of experiments. A data science project lies somewhere between the two. There is a lot of experimentation, but the end result is ideally a finished piece of software.
Since data science is so experimental, it is often impossible to say at the outset whether a project is even viable. A manager must be open to this fluidity otherwise they will be very frustrated managing a team of data scientists, and the data scientists in turn will feel misunderstood and will probably leave the company.
I have written another blog post detailing my thoughts and ideas about data science project management which you can read here.
Sometimes the CTO of the company may be in favour of the data science initiative but other executives may be sceptical. If the data science team is perceived as the baby of a particular manager, other managers may be disinterested or even oppose the project. It could even be the case that employees and managers in a part of the business view their jobs as under threat from the data science projects.
In some companies, the data science team can end up with little communication or insight into business processes or decisions. For example, if the data science team works on a project with the marketing department, the data science team ends up without a direct line of communication to the marketing professionals, and are unable to understand the business requirements of the project. This is one of the leading causes of data science projects failing.
In industries such as healthcare and pharmaceuticals, the business problems may themselves be highly technical. In some cases, simply the act of labelling training data is nearly impossible to achieve because only a medical professional can do it, and the necessary personnel are otherwise engaged in the company. The data science managers should be aware of these problems and have sufficient leverage to ensure that the data scientists have access to the individuals needed to complete the project.
Since data science is so new, there is no established pattern for building a team. However, in a small to medium-sized company, you could do worse than follow Jesse Anderson’s recommendation to split up the data science tasks into three teams: data scientists, data engineers, and operations engineers. The first person you should look to recruit should not come from academia and mathematics, but ideally, you can start with a data engineer with experience in software development, data warehousing and databases. This person will help you lay the foundations for a robust data science architecture and team with minimal technical debt.
Ready to take the next step in your NLP journey? Connect with top employers seeking talent in natural language processing. Discover your dream job!
Find Your Dream Job
Unlock your business potential with expert AI consulting services from Fast Data Science. Discover strategies to accelerate growth and outperform competitors.

Financial advisors, like lawyers, are regulated in the UK. All financial advisors should be registered with the Financial Conduct Authority (FCA) and must have certain qualifications and have signed up to a code of ethics. UK financial advisors must also complete professional training every year.
What we can do for you
