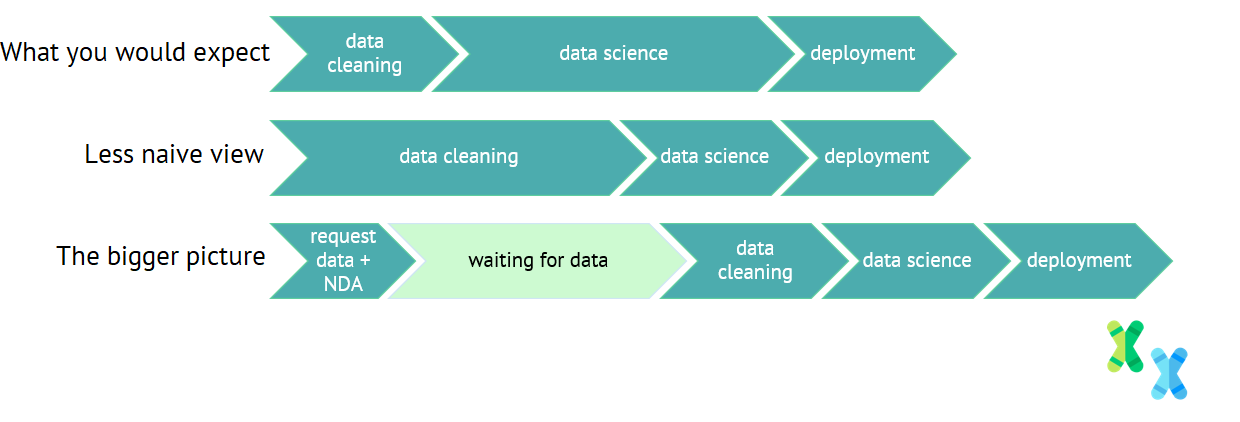
What are the key stages in a data science project? A recipe for a successful data science project flow.
When planning a data science project, it’s easy to think of it as a simple exercise in a little bit of data cleaning, some data science work, and a deployment stage at the end of the project. In fact, many data scientists and non-data scientists might expect this kind of idealised data science project flow.

An fictional idealised data science project flow
Unfortunately the reality is rarely this simple.
When data is provided by a client, it is likely to be messy, contain inconsistencies, and require considerable work in order to understand it and make it usable. This work is often called ‘data wrangling’. This means that the data cleaning stage is likely to take longer than expected, and usually overlap with the data science stage.
For this reason, I’ve seen a lot of posts by data scientists implying that the job is 50% data cleaning, and only 25% data science work.
A slightly more realistic data science project flow.
However, I think that the above model doesn’t take into account the complexity of deployment.
Once the machine learning work has been completed, the data science model will need to be deployed.
This involves dialogue with the client’s technical and business team, and considerable coding work which will have to go into the technical team’s backlog. This stage is also subject to politics within the client organisation - for example, some individuals may not want to deploy the model in case it looks their department look bad, or conversely they may want to deploy it but within their division in order to take credit. Due to all these factors, the deployment phase is also likely to take much longer than expected.
In addition, I think there is a large source of delays which is often completely overlooked. Before the data science project can begin, we need to follow some steps:
gain the client’s trust
sign an NDA
get access to the data
get access to the client’s systems
understand who are the key stakeholders on the project, who can accelerate it and who can hinder it.
while waiting for the data, repeatedly check for blockers and stay in contact with the stakeholders.
Fast Data Science - London
I think it’s fair to plan for a month to get hold of the data. I have sometimes seen waiting times of 6 months or more, and I have also seen projects fail because the data could not be obtained.
So I would break down the stages of the data science project as follows:

A more realistic view of the data science project flow for an external data science consultancy, taking into account the difficulty of obtaining data and the corresponding waiting time.
There are a number of reasons why it can be difficult to obtain data for a project. Some of them apply whether you are an employee or external consultant, but the problems tend to be more acute for external data science consultants than for internal data scientists.
We can divide data into two categories:
open or public data - this is data that is freely downloadable to anyone on the internet. Think government statistics, coronavirus statistics, historical datasets, Kaggle competitions.
private/internal data. This is data that a company holds on its customers, or other commercially or legally sensitive data. It is often protected by legislation such as GDPR or HIPAA.
Data science projects with a paying client would normally require private data. A company’s internal data may be its most valuable asset. This is the case not only with tech firms but increasingly even with some brick-and-mortar firms.
For a company to share its data, everybody in the chain of command must be on board and ready to trust the data science consultancy. The client and the consultancy must agree on terms and conditions and sign an NDA. If this is the first time that the client company is doing data science, they may be unfamiliar with this process, and the drafting of the NDA could take time. Sharing data with outsiders is not something that companies are keen to do if it is not absolutely necessary.
For this reason, there are many companies in traditional industries such as insurance and legal, who possess gold mines of data, in particular text data, but do not have the in-house expertise to extract value from it.
Since the consequences of the data not being available at project start are severe both for the client and consultant, I would suggest to take as many steps as possible to avoid this happening.
First of all, one month before the project is due to start, I would take the following steps:
send a list of requirements to the client, requesting the following:
NDA
Access to the data
Access to cloud computing account, source control accounts, any internal document repositories – if applicable
Identification of all key stakeholders, who to report to, any other concerned individuals in the organisation
specify an individual to contact in case of project blockers
arrange a kickoff meeting for one week after this email, and one month before project start date, when ideally some of the above would have been provided
at the kickoff meeting, discuss any outstanding issues that could block the project
following the meeting, keep in touch with the stakeholders to make sure that everything will be in place to begin the project.
By taking these steps, we can ensure that all data will be available before the first billable day of the project, and any blockers can be identified early.
The client may tell you that the kickoff meeting is not necessary, and that you shouldn’t worry, because they will have everything in place for Monday morning when the project is due to start. I would recommend to take this with a pinch of salt! An obstacle that nobody has considered will turn up at the last minute on Monday at 9am. Maybe someone in the tech support team is on holiday, a lawyer needs to clear the NDA with their supervisor, or a high-ranking manager in the company has just heard of the project and wants to leave their mark on it for their boss because their annual review is coming up.
Key steps in a data science project: three different views of the data science project flow.
We often overlook the obstacles to getting a data science project off the ground. Just as a car cannot run without fuel, a data science project cannot run without data. Obtaining internal data for a client project is rarely straightforward, and can be blocked by a variety of internal and external factors. For this reason, the NDA is one of the most important and critical elements of a data science project.
If the data is not obtained in time, this will cause unnecessary delays to a project. The risk is best mitigated with meticulous planning and following-up on the part of the data science consultant.
To assist you in planning your data science project, we have provided a data science project kickoff checklist on the Resources section of our website, together with an in-browser Gantt chart generator for NLP projects, a data science roadmap planner, a project cost planner spreadsheet, and a project risk tool.
An earlier version of this article originally appeared on freelancedatascientist.net.
Looking for experts in Natural Language Processing? Post your job openings with us and find your ideal candidate today!
Post a Job
Unlock your business potential with expert AI consulting services from Fast Data Science. Discover strategies to accelerate growth and outperform competitors.

Financial advisors, like lawyers, are regulated in the UK. All financial advisors should be registered with the Financial Conduct Authority (FCA) and must have certain qualifications and have signed up to a code of ethics. UK financial advisors must also complete professional training every year.
What we can do for you
