
Suchen Sie Experten in Natürlicher Sprachverarbeitung? Veröffentlichen Sie Ihre Stellenangebote bei uns und finden Sie heute Ihren idealen Kandidaten!
Veröffentlichen Sie einen JobWie NLP- Dokumentähnlichkeitsalgorithmen verwendet werden können, um ähnliche Dokumente zu finden und Dokumentempfehlungssysteme zu erstellen.
Stellen wir uns vor, Sie lesen ein Dokument und möchten herausfinden, welche anderen Dokumente in einer Datenbank diesem am ähnlichsten sind. Dies wird als Dokumentähnlichkeitsproblem oder semantisches Ähnlichkeitsproblem bezeichnet.
 and [machine learning](/machine-learning-consulting-businesses-benefit) be used to find similar documents?](https://fastdatascience.com/images/nlp_machine_learning_finding_similar_documents-min.png)
Wir können uns ein paar Beispiele aus der Praxis vorstellen, bei denen Ihnen das passieren könnte:
Es gibt eine Reihe von Möglichkeiten, dieses Problem mithilfe der Verarbeitung natürlicher Sprache anzugehen.
Bevor ich mir jedoch die verfügbaren Technologien ansehe, möchte ich zunächst das Problem definieren.
Eine Frage, die vor der Erstellung eines NLP- Modells zur Berechnung der Dokumentähnlichkeit gestellt werden muss, lautet: Was soll es leisten?
In dem Unternehmen, für das Sie es erstellen, ist es unwahrscheinlich, dass es einen Datensatz gibt, der angibt, welche Dokumente welchen anderen ähneln.
Bevor Sie mit einer praktischen datenwissenschaftlichen Arbeit beginnen, würde ich Ihnen raten, zu versuchen, zumindest einige Daten (einen „Goldstandard“ oder eine „Grundwahrheit“) aufzubauen, die zum Testen und Bewerten eines zukünftigen Modells verwendet werden können. Dies ist das maschinelle Lernanalogon der testgetriebenen Entwicklung .
Wenn Sie mit der Entwicklung Ihrer Modelle beginnen, haben Sie sofort die Möglichkeit, diese zu bewerten.
Allerdings ist es oft nicht möglich, einen Datensatz zur Bewertung eines Dokumentähnlichkeitsmodells zu erstellen. Manchmal ist die Dokumentenähnlichkeit subjektiv und liegt in den Augen des Kunden. In einem solchen Fall würde ich dazu raten, ein Grundmodell zu erstellen und den Stakeholdern eine Reihe von Empfehlungen vorzulegen und sie zu bitten, zu bewerten, welche Empfehlungen gut und welche weniger genau waren.
Das Ergebnis dieser Übung kann in einen Prüfstand umgewandelt werden, der zukünftige Iterationen des Ähnlichkeitsmodells bewerten kann.
Es gibt eine Reihe von Metriken, die zur Bewertung eines Dokumentähnlichkeitsmodells verwendet werden können. Eine der bekanntesten ist die mittlere durchschnittliche Präzision . Hierbei handelt es sich um eine Zahl, die die Qualität der Empfehlungen einer Suchmaschine messen kann und Modelle hoch bewertet, die sehr relevante Dokumente an erster Stelle einstufen, und ein Modell bestraft, das relevante Dokumente an das Ende der Liste setzt. Es gibt eine Reihe anderer Metriken, aber ich würde empfehlen, mit der Bewertung Ihrer Modelle anhand Ihres Goldstandard-Datensatzes zunächst unter Verwendung der durchschnittlichen Präzision zu beginnen.

Paul Jaccard, Entwickler des Jaccard-Index. Quelle: Wikimedia . Lizenz: CC4.0 .
Der einfachste Weg, zwei Dokumente zu vergleichen, besteht darin, einfach die Wörter zu nehmen, die in beiden Dokumenten vorhanden sind, und den Grad der Überlappung zu berechnen. Wir können die Information darüber, welches Wort mit welchem anderen Wort im Satz gleichzeitig vorkam, verwerfen. Da diese Darstellung eines Satzes damit vergleichbar ist, eine Reihe von Wörtern in eine Tüte zu stecken und sie vor dem Vergleich durcheinander zu bringen, wird diese Technik als „Bag-of-Words“-Modell bezeichnet.
Wenn wir zum Beispiel diese beiden Sätze aus Papierzusammenfassungen haben:
Indien ist eines der Epizentren der weltweiten Diabetes-Mellitus-Pandemie.
Diabetes mellitus tritt häufig bei älteren Patienten auf und wird häufig nicht diagnostiziert.
Dann besteht eine sehr einfache Möglichkeit, die Ähnlichkeit zu messen, darin, Stoppwörter ( , und usw.) zu entfernen und dann die Anzahl der Wörter in beiden Dokumenten dividiert durch die Anzahl der Wörter in einem beliebigen Dokument zu berechnen. Diese Zahl wird Jaccard-Index genannt und wurde vor über einem Jahrhundert vom Schweizer Botaniker Paul Jaccard entwickelt:
Die Non-Stoppwörter in Dokument 1 sind also:
„ {‘diabetes’, ‘epicentres’, ‘global’, ‘india’, ‘mellitus’, ‘one’, ‘pandemic’} „
und die Non-Stoppwörter in Dokument 2 sind:
„ {‘häufig’, ‘Diabetes’, ‘häufig’, ‘mellitus’, ‘tritt auf’, ‘älter’, ‘Patient’, ‘nicht diagnostiziert’} „
Es gibt zwei gemeinsame Wörter ( Diabetes , mellitus ) und insgesamt 13 Wörter.
Der Jaccard-Ähnlichkeitsindex der beiden Dokumente beträgt also 2/13 = 15 %.
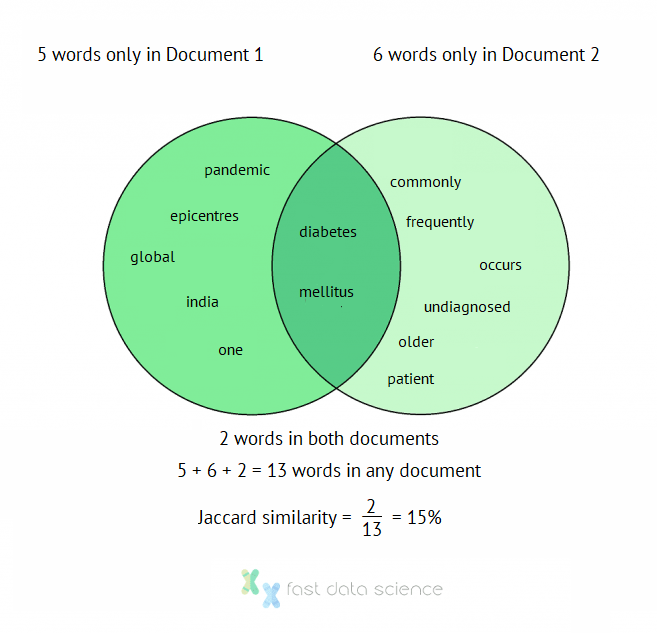
Darstellung der Berechnung des Jaccard-Dokumentenähnlichkeitsindex als Venn-Diagramm
Trotz ihrer Grobheit sind Bag-of-Word-Modelle wie der Jaccard-Index und die ähnliche Kosinusähnlichkeit sehr leistungsfähig, weil sie so schnell zu implementieren und leicht zu verstehen sind.
Ich würde aus zwei Gründen empfehlen, zu Beginn eines Modellentwicklungszyklus einen Bag-of-Words-Ansatz zu verwenden: Erstens, falls es das tut, was Sie brauchen, und zweitens, um eine Basislinie zu haben und genau beurteilen zu können, ob es sich um ein ausgefeilteres Modell handelt , das den Kontext berücksichtigt, bietet tatsächlich einen Mehrwert.
Bag-of-Words ist wahrscheinlich die beste Wahl für sehr kurze Dokumenttypen wie Artikeltitel oder Suchanfragen, bei denen der Kontext wahrscheinlich keine Rolle spielt. Wenn Sie beispielsweise über ein Jobsuchportal verfügen und Benutzern, die nach einem ähnlichen Begriff gesucht haben, Berufsbezeichnungen empfehlen möchten, ist ein „Bag-of-Words“-Ansatz wahrscheinlich das beste Modell, das Sie ausprobieren sollten.
Im obigen Beispiel haben wir Diabetes und mellitus bei der Berechnung des Jaccard-Ähnlichkeitsindex als zwei separate Wörter gezählt. In Wirklichkeit fungieren sie als ein einzelner Begriff (ein Mehrwortausdruck oder MWE). Bei einem „Bag-of-Words“-Ansatz werden Ausdrücke mit mehreren Wörtern nicht korrekt verarbeitet, da diese in einzelne Wörter aufgeteilt werden.
Eine Möglichkeit, dies zu umgehen, besteht darin, alle Zwei-Wort-Sequenzen zu nehmen und anhand dieser den Ähnlichkeitsindex zu berechnen. Das zweite Dokument würde also die folgenden Zwei-Wort-Teilsequenzen generieren:
„ {‘und ist’, ‘häufig in’, ‘Diabetes Mellitus’, „häufig nicht diagnostiziert“, ‘im’, „kommt häufig vor“, „Mellitus tritt auf“, „kommt häufig vor“, „älterer Patient“, ‘geduldig und’, ‘die älteren’} „
Die oben genannten Begriffe sind die Bigramme des Dokuments, und die Technik, Teilfolgen der Länge N zu nehmen, wird als N-Gramm-Ansatz bezeichnet.
N-Gramme sind immer noch relativ einfach zu implementieren und haben den Vorteil, dass einige Kontextinformationen erhalten bleiben. Beispielsweise wird Diabetes mellitus als ein einziger Begriff behandelt. Ein N-Gramm-basiertes Dokumentähnlichkeitsmodell ist nicht so „dumm“ wie der Vanilla-Bag-of-Words-Ansatz. Normalerweise kombiniere ich das Bigramm-Modell mit dem Bag-of-Words-Modell, um das Beste aus beiden Welten herauszuholen.
Die oben beschriebenen Bag-of-Words- und N-Gramm-Ansätze haben alle einen großen Nachteil: Wenn Dokument 1 das Wort Diabetiker und Dokument 2 das Wort Diabetes enthält und Dokument 3 T2DM (eine andere Abkürzung) erwähnt, wie würden wir dann eine Ähnlichkeit erkennen? ?
Im Jahr 2013 hatte der tschechische Informatiker Tomáš Mikolov die Idee, Wörter in einem „ semantischen Raum“ darzustellen, in dem jedes Wort eine Reihe von Koordinaten im Raum hat und Wörter, deren Bedeutung nahe beieinander liegt, einen kurzen Abstand zwischen ihnen haben. Dieser Algorithmus heißt word2vec und basiert auf der Idee, dass Wörter, die in ähnlichen Kontexten vorkommen, semantisch ähnlich sind. Unten können Sie einen Word2vec- Datensatz erkunden, den ich anhand einer Reihe von Dokumenten zu klinischen Studien trainiert habe.
Beachten Sie, dass Wörter, die konzeptionell ähnlich sind, in der Grafik nahe beieinander liegen. Als Maß für die Ähnlichkeit wird häufig der euklidische Abstand verwendet.
Später erweiterte Mikolov word2vec auf Dokumente und schuf einen Algorithmus, der jedes Dokument beispielsweise als 500-dimensionalen Vektor darstellen kann. Die Ähnlichkeit zwischen zwei Dokumenten wird durch die Nähe ihrer Vektoren angezeigt.
Die oben genannten Methoden sollten ausreichen, um die Dokumentähnlichkeit für beide Anwendungsfälle zu messen. Wenn Sie jedoch noch ein paar zusätzliche Leistungseinbußen herausholen möchten, sind die Transformers derzeit die modernsten Modelle. Das bekannteste transformatorbasierte Modell heißt BERT , es gibt aber auch andere Modelle wie ELMO, RoBERTa, DistilBERT und XLNet.
Transformer funktionieren auch, indem sie Wörter und Sätze als Vektoren darstellen, allerdings mit dem entscheidenden Unterschied, dass die Vektordarstellung eines Wortes nicht festgelegt ist, sondern selbst vom Kontext des Wortes abhängt. Beispielsweise wird das Wort „ it“ im Vektorraum unterschiedlich dargestellt, je nachdem, worauf sich „es“ bezieht – eine Funktion, die nützlich ist, wenn Transformatormodelle zum Übersetzen aus dem Englischen in eine geschlechtsspezifische Sprache verwendet werden, wo es je nach Wort unterschiedliche Übersetzungen haben kann bezieht sich auf.
Transformer sind sehr rechenintensiv (sie benötigen GPUs und laufen nicht auf einem normalen Laptop) und sind oft auf kurze Sätze beschränkt. In den meisten kommerziellen Anwendungsfällen können sie aufgrund der schwierigen Implementierung unhandlich sein. Wenn Sie jedoch ein Transformatormodell anhand Ihrer Daten trainieren können, ist es wahrscheinlich besser als die oben aufgeführten Alternativen.
Es ist sehr schwierig, die Einzelheiten der genauen Funktionsweise von Transformatoren zu klären. In der Praxis können Sie für den Einstieg in Transformers einen Cloud-Anbieter wie Microsoft Azure ML, Google Cloud Platform oder AWS Sagemaker nutzen. Die Textklassifizierungsbeispiele auf diesen Plattformen ermöglichen es Ihnen, vorab trainierte Transformatormodelle relativ schnell für Dokumentähnlichkeitsberechnungen zu verwenden, ohne dass Sie auf die Details der Funktionsweise von Transformatoren eingehen müssen.
Es stehen eine Reihe von Dokumentähnlichkeitsmodellen zur Verfügung. Ich würde empfehlen, sich einem Dokumentähnlichkeitsproblem zu nähern, indem Sie die Aufgabe und einen Goldstandard definieren und eine Bewertungsmetrik auswählen und dann eine Reihe von Modellen trainieren, von den einfacheren Optionen bis zu den komplexeren Alternativen, bis Sie das Modell gefunden haben, das am besten zum Anwendungsfall passt .
Auch die Algorithmen zur Dokumentähnlichkeit machen rasche Fortschritte, und transformatorbasierte Methoden dürften in den nächsten Jahren an Bedeutung gewinnen.
P. Jaccard, Distribution de la flore alpine dans le bassin des Dranses et dans quelques régions voisines. Bulletin de la Société Vaudoise des Sciences Naturelles 37, 241-272 (1901)
T. Mikolov et al.. Efficient Estimation of Word Representations in Vector Space, arXiv:1301.3781 (2013)
Entfesseln Sie das Potenzial Ihrer NLP-Projekte mit dem richtigen Talent. Veröffentlichen Sie Ihre Stelle bei uns und ziehen Sie Kandidaten an, die genauso leidenschaftlich über natürliche Sprachverarbeitung sind.
NLP-Experten einstellen
Mittlerweile sind es Organisationen aller Größenordnungen und fast aller Sektoren werden zunehmend datengesteuert, insbesondere als größere Datenspeicher Systeme und schnellere Computer treiben die Leistungsgrenzen immer weiter voran.

Aufgrund des umfangreichen Einsatzes von Technologie und der Arbeitsteilung hat die Arbeit des durchschnittlichen Gig-Economy-Arbeiters jeden individuellen Charakter und damit auch jeden Charme für den Arbeitnehmer verloren.
Die Auswirkungen von KI auf die Humanressourcen Die Arbeitswelt verändert sich rasant, sowohl aufgrund der Einführung traditioneller Data-Science-Praktiken in immer mehr Unternehmen als auch aufgrund der zunehmenden Beliebtheit generativer KI-Tools wie ChatGPT und Googles BARD bei nicht-technischen Arbeitnehmern.
What we can do for you