Können wir die Voreingenommenheit gegenüber KI beseitigen?
Voreingenommenheit ist eine der vielen Unvollkommenheiten der Menschheit, die uns Fehler machen lässt und uns daran hindert, zu wachsen und innovativ zu sein. Voreingenommenheit ist jedoch nicht nur eine menschliche Realität, sondern auch eine Realität der künstlichen Intelligenz . KI-Voreingenommenheit ist ein gut dokumentiertes Phänomen, das bei maschinellen Lernwerkzeugen aus einer Vielzahl von Sektoren weit verbreitet ist und bekanntermaßen schwer zu beseitigen ist.
Im Jahr 2020 berichtete der Guardian , dass mehr als die Hälfte der Gemeinden in England Algorithmen verwenden, um Entscheidungen über Sozialleistungen zu treffen, ohne die Öffentlichkeit über diesen Einsatz der Technologie zu konsultieren. Wenn sie irgendeine Art voreingenommener KI verwenden, könnte dies schwerwiegende Folgen für die Benachteiligten der Gesellschaft haben.
Künstliche Intelligenz soll uns von unseren menschlichen Beschränkungen befreien. Die Fähigkeit einer Maschine, riesige Datenmengen zu scannen und innerhalb von Minuten Trends und Muster zu erkennen, ist ein unschätzbares Werkzeug, das uns hilft, Zeit zu sparen und die Effizienz zu steigern. Schließlich können Maschinen nicht nur Daten viel schneller analysieren als Menschen, sondern auch Muster erkennen, die ein Mensch allein nicht erkennen könnte. Wenn die von uns verwendete künstliche Intelligenz jedoch voreingenommen ist, sind die Extrapolationen, die wir von der KI erhalten, fehlerhaft. Lassen Sie uns einige der häufigsten Voreingenommenheiten bei KI durchgehen.
Ein KI-Bias liegt vor, wenn falsche Annahmen im maschinellen Lernprozess zu systematisch verzerrten Ergebnissen führen. Dieser maschinelle Lernbias kann durch menschliche Voreingenommenheit der Personen entstehen, die das System entwickeln oder trainieren, oder er kann durch unvollständige oder fehlerhafte Datensätze entstehen, die zum Trainieren des Systems verwendet werden.
Wenn Sie beispielsweise einen Algorithmus trainieren, bestimmte Hautkrankheiten anhand einer Vielzahl von Bildern von Hautkrankheiten zu erkennen, und die von Ihnen verwendeten Bilder hauptsächlich von Menschen mit heller Haut stammen, kann dies die Fähigkeit der KI beeinträchtigen, dieselben Hautkrankheiten auch bei dunklerer Haut zu erkennen. Unabhängig von der Ursache hat die Voreingenommenheit der KI negative Auswirkungen auf die Gesellschaft, von den Algorithmen, die wir bei Einstellungsverfahren verwenden, bis hin zur KI, die zur Bestimmung von Angeklagten mit hohem Risiko in Strafverfahren eingesetzt wird.

KI-Voreingenommenheit hat eine lange und komplizierte Geschichte, die bis in die frühen Tage von Computern und maschinellem Lernen zurückreicht. Hier ist ein Beispiel für eine frühe KI-Voreingenommenheit: 1988 stellte die britische Kommission für Rassengleichheit fest, dass eine britische medizinische Fakultät sich der Diskriminierung schuldig gemacht hatte, weil ihre Computerprogrammierung KI-Voreingenommenheit aufwies. Es wurde festgestellt, dass ihr Computerprogramm bei der Auswahl von Kandidaten für das Vorstellungsgespräch Frauen und Personen mit nicht-europäisch klingenden Namen unfair diskriminierte .
Interessanterweise wurde dieses Computerprogramm so konzipiert, dass es die Entscheidungen der menschlichen Zulassungsbeamten widerspiegelte, was ihm mit einer Genauigkeit von 90–95 % gelang. Da die KI-Technologie entwickelt wurde, um menschliche Entscheidungen nachzuahmen, wurden unbeabsichtigt auch menschliche Vorurteile in die KI-Voreingenommenheit einbezogen, was häufig dazu führte, dass Frauen und Angehörigen ethnischer Minderheiten Vorstellungsgespräche verweigert wurden.

Fast Data Science - London
Künstliche Intelligenz wird im Strafrechtssystem häufig eingesetzt, um Bürger zu kennzeichnen, die eher als „Hochrisiko“ eingestuft werden. Da viele dieser maschinellen Lerntools anhand vorhandener Polizeiakten trainiert werden, können diese Tools menschliche Voreingenommenheit in ihre Algorithmen einbeziehen.
Einige Polizisten haben beispielsweise Bedenken geäußert , dass junge schwarze Männer häufiger auf der Straße angehalten und durchsucht werden als junge weiße Männer. Dies beeinflusse die Datensätze, die dann zur KI-Kriminalitätsvorhersage verwendet werden, und fördere so die rassistische Voreingenommenheit. Es wurden auch Bedenken geäußert, dass Menschen aus sozial schwachen Schichten öffentliche Dienste häufiger nutzen. Dadurch werde ihre Darstellung in den Daten verzerrt und sie würden eher als Risiko gekennzeichnet.
Künstliche Intelligenzprogramme werden auch häufig eingesetzt, um Lebensläufe von Bewerbern zu prüfen und so die besten Talente zu rekrutieren. Es ist jedoch bekannt, dass diese Algorithmen eine KI-Voreingenommenheit aufweisen, die dazu führt, dass qualifizierte Kandidaten allein aufgrund ihrer Rasse oder ihres Geschlechts ausgeschlossen werden. Amazon hat die Nutzung seines KI-Rekrutierungstools 2018 eingestellt, nachdem das Unternehmen erkannte, dass das Programm gegenüber Frauen voreingenommen war.
Amazons künstliche Intelligenz wurde darauf trainiert, Muster in Lebensläufen zu erkennen. Dabei fiel auf, dass die Mehrheit der Bewerber Männer waren. Das führte dazu, dass das Programm unbeabsichtigt männliche Bewerber bevorzugte. Dies geschah, indem Bewerbungen, die das Wort „Frauen“ enthielten, herabgestuft wurden, etwa Bewerber, die eine Frauenhochschule besucht oder sich in einer Frauengruppe oder -organisation engagiert hatten. Obwohl Amazon versuchte, diese Voreingenommenheit in seinem Programm herauszufiltern, wurde es letztendlich vollständig abgeschafft.

Es zeigt sich, dass die Überprüfung, ob ein Bewerber häufig in einem Manga-Forum aktiv ist, eine sexistische Methode der Mitarbeiterauswahl ist.
Eine Online-Plattform für die Einstellung von Technikern namens Gild ging sogar so weit, die Social-Media-Präsenz der Bewerber zu analysieren, um daraus einen Einstellungswert zu ermitteln. Dabei wurde die Aktivität auf Technikseiten wie Github berücksichtigt, aber der Algorithmus vergab auch Extrapunkte an Bewerber, die in einem bestimmten japanischen Manga-Forum aktiv waren, das einen hohen Anteil männlicher Nutzer hatte. Die Begründung lautete, dass das Interesse an Manga ein starker Indikator für Programmierkenntnisse sei, aber die Entwickler dieses Algorithmus vernachlässigten die implizite Geschlechtervoreingenommenheit, die sie in die Einstellungspraktiken einführten – diese Voreingenommenheit in der KI führte ebenfalls zu verzerrten Ergebnissen.
Viele Modelle zur Verarbeitung natürlicher Sprache werden mit Daten aus der realen Welt trainiert. Da Nachrichtenartikel und Literatur typischerweise auf Männer ausgerichtet sind, entsteht dadurch eine Voreingenommenheit.
Hier ist ein Beispiel für eine NLP- KI-Voreingenommenheit.
In der Vergangenheit hat Google Translate die geschlechtsneutrale türkische Phrase o bir hemşire als „sie ist Krankenschwester“ wiedergegeben, während o bir doktor als „er ist Krankenpfleger“ übersetzt wurde. Das Pronomen o ist geschlechtsneutral und kann gleichermaßen als „er“ oder „sie“ übersetzt werden.
Als ich 2023 nachgesehen habe, war Google Translate glücklicherweise so geändert worden, dass sowohl männliche als auch weibliche Übersetzungen angeboten wurden.
Google Translate bietet nun korrekterweise beide Übersetzungsoptionen aus geschlechtsneutralen Sprachen an, anstatt standardmäßig weibliche oder männliche Pronomen zu verwenden. Bildquelle: Google
Was war also die Ursache für die ursprünglichen voreingenommenen Übersetzungen?
Nun, maschinelle Übersetzungsalgorithmen werden anhand von Korpora trainiert, also großen Textmengen aus Nachrichtenartikeln, Literatur und anderen Inhalten. Die maschinellen Übersetzungsmodelle basieren auf Statistiken, das heißt, sie stützen sich auf die Wahrscheinlichkeit des Vorkommens bestimmter Sätze in einer Sprache. Ein Satz wie „sie ist Krankenschwester“ wäre als wahrscheinlicher berechnet worden als „er ist Krankenpfleger“ – vielleicht kam die weibliche Version in dem Korpus, mit dem Google Translate trainiert wurde, häufiger vor als die männliche.
Schauen wir uns als Beispiel das British National Corpus an, eines der bekanntesten Korpora für britisches Englisch.
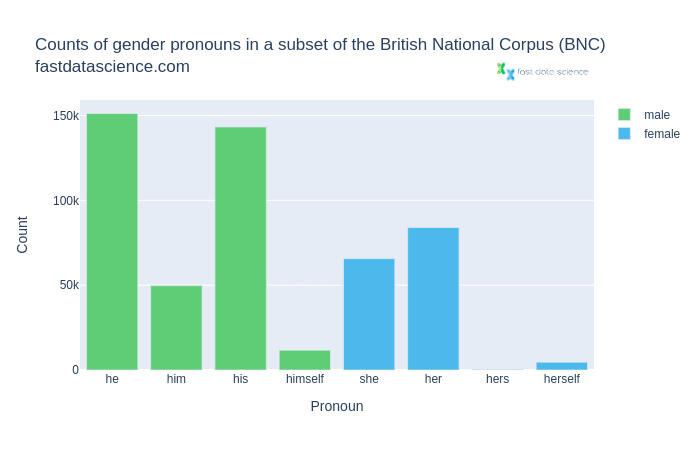
Anzahl geschlechtsspezifischer Pronomen im British National Corpus. Männliche Pronomen wie er, ihm, sein und sich selbst sind viel häufiger als weibliche Pronomen.
Wir können feststellen, dass die männlichen Pronomen im Allgemeinen viel häufiger vorkommen als die weiblichen.
Angesichts dieses Ungleichgewichts ist es kein Wunder, dass maschinelle Übersetzungsalgorithmen eine geschlechtsspezifische Voreingenommenheit in übersetzten Texten aufnehmen und weiter verbreiten.
Obwohl KI-Voreingenommenheit ein ernstes Problem ist, das die Genauigkeit vieler maschineller Lernprogramme beeinträchtigt, kann sie in mancher Hinsicht auch leichter zu bewältigen sein als menschliche Voreingenommenheit. Im Gegensatz zu menschlicher Voreingenommenheit, die oft unbewusst und unbemerkt ist, ist KI-Voreingenommenheit viel leichter zu erkennen. Algorithmen können viel einfacher nach Voreingenommenheit durchsucht werden, was oft unbemerkte menschliche Voreingenommenheit in den in das System eingegebenen Datensätzen aufdecken kann. Dies kann uns helfen, systemische Voreingenommenheit zu erkennen, unseren Ansatz zur Datenerfassung zu ändern und Voreingenommenheit in KI-Modellen zu reduzieren.
Obwohl es schwierig ist, die Voreingenommenheit von KI zu beheben, gibt es Möglichkeiten, die Voreingenommenheit in KI-Modellen und -Algorithmen zu reduzieren . Indem wir Algorithmen in Umgebungen testen, die denen in der realen Welt ähnlich sind, können wir KI effektiv trainieren, entsprechende Muster zu erkennen, ohne unbewusste Voreingenommenheit einzubauen. Entwickler müssen auch darauf achten, dass die Datensysteme, die sie zum Trainieren des maschinellen Lernens verwenden, sowohl frei von Voreingenommenheit als auch genau repräsentativ für alle Rassen und Geschlechter sind.
Forscher haben versucht, „Fairness“ in KI-Algorithmen zu definieren, indem sie entweder von KI-Modellen verlangten, dass sie für alle Gruppen den gleichen Vorhersagewert haben, oder indem sie von ihnen verlangten, dass sie gleiche Raten an falsch-positiven und falsch-negativen Ergebnissen aufweisen. Sie sind sogar so weit gegangen, kontrafaktische Fairness in ihre KI-Modelle einzubauen, indem sie testen, ob die Ergebnisse in einer Welt, in der allgemein sensible Attribute wie Rasse oder Geschlecht geändert würden, dieselben wären.
In einem früheren Blogbeitrag habe ich mich für die Einführung eines Standards für Penetrationstests ausgesprochen, bei dem KI-Algorithmen einem Stresstest auf Voreingenommenheit unterzogen werden und ein Tester versucht, geschützte Merkmale zu rekonstruieren, die aus den Trainingsdaten entfernt wurden.
Der beste Weg, Verzerrungen in KI-Modellen zu reduzieren, besteht letztlich darin, dass sowohl die Leute, die die künstliche Intelligenz trainieren, als auch die Leute, die sie testen, auf mögliche Verzerrungen achten und natürlich die Vielfalt in den Entwicklerteams, die am Algorithmus arbeiten, aufrechterhalten. Indem sie auf beiden Seiten nach unbewussten Vorurteilen Ausschau halten, können Entwickler Ungenauigkeiten schnell erkennen und die notwendigen Änderungen vornehmen.
Cathy O’Neil, Wie Algorithmen unser Arbeitsleben bestimmen , The Guardian (2016)
Caroline Criado Perez, Unsichtbare Frauen (2019)
The British National Corpus , Version 3 (BNC XML Edition). 2007. Verteilt von Bodleian Libraries, University of Oxford, im Auftrag des BNC Consortium. URL: http://www.natcorp.ox.ac.uk/
Marsh und McIntyre, Fast die Hälfte der Gemeinden in Großbritannien nutzt Algorithmen zur Entscheidungsfindung bei Ansprüchen , The Guardian, 2020
Bereit für den nächsten Schritt in Ihrer NLP-Reise? Vernetzen Sie sich mit Top-Arbeitgebern, die Talente in der natürlichen Sprachverarbeitung suchen. Entdecken Sie Ihren Traumjob!
Finden Sie Ihren Traumjob
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you