
Lesen Sie mehr über KI für Unternehmen auf fastdatascience.com
Ich bin sicher, Sie haben Nachrichtenartikel und Social-Media-Beiträge über die neueste Generation von Sprachmodellen gesehen, die menschenähnliche Texte generieren können. Ich habe beispielsweise Behauptungen gesehen, dass GPT-3 oder ChatGPT von OpenAI Aufsätze, YouTube-Skripte oder Blogbeiträge schreiben und sogar eine Anwaltsprüfung ablegen können.

Was sind künstliche neuronale Netze und wie lernen sie? Wofür verwenden wir sie? Was sind einige Beispiele für künstliche neuronale Netze? Wie verwenden wir neuronale Netze?
Wir haben das Clinical Trial Risk Tool entwickelt, ein Tool zur Risikobewertung klinischer Studien, das KI und NLP nutzt, um das Risiko eines nicht informativen Studienendes zu quantifizieren. Kontaktieren Sie uns, wenn Sie eine individuelle KI-Strategieberatung für das Gesundheitswesen benötigen.

Im Jahr 2009 wurde Hal Varian, Chefökonom bei Google, gegenüber dem McKinsey Quarterly mit den Worten zitiert: „Der attraktivste Job der nächsten zehn Jahre wird der des Statistikers sein.“

„Data Scientist“ wurde kürzlich von LinkedIn zum „vielversprechendsten Beruf“ gekürt und einem Bericht des US Bureau of Labour Statistics zufolge wird die Zahl der Arbeitsplätze im Bereich Data Science bis 2026 weltweit im Durchschnitt um 28 % steigen.

Ein Überblick über die Herausforderungen, denen Sie bei der Verarbeitung natürlicher Sprache auf mehrsprachige Daten begegnen. Die meisten Projekte, die ich übernehme, beinhalten unstrukturierte Textdaten nur in englischer Sprache, aber in letzter Zeit habe ich immer mehr Projekte gesehen, die Text in verschiedenen Sprachen beinhalten, oft auch alle miteinander vermischt. Das ist eine lustige Herausforderung.
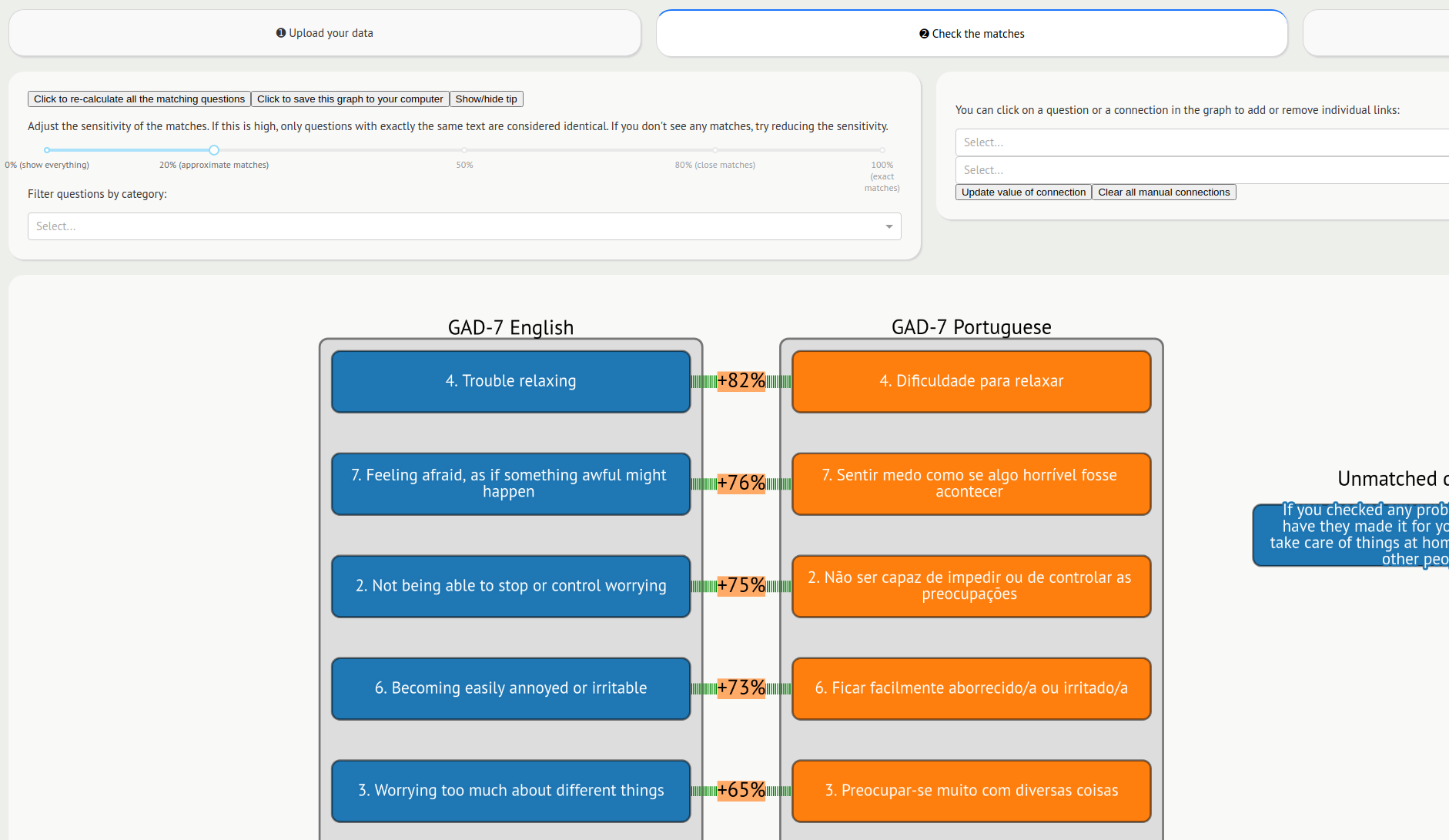
Müssen Sie Fragebogendaten verschiedener Studien vergleichen? Sind die Elemente inkonsistent oder sind verschiedene Versionen desselben Fragebogens im Umlauf? Haben Sie Fragebögen in verschiedenen Sprachen, die Sie vergleichen möchten?
Wir haben ein Tool entwickelt, das auf der Verarbeitung natürlicher Sprache basiert und Forschern in den Sozialwissenschaften dabei helfen soll, Datensätze aus unterschiedlichen Kontexten zu harmonisieren . Dies ist Teil eines umfassenderen Projekts namens Harmony , das Teil eines Beitrags ist, den wir gemeinsam mit dem Centre for Longitudinal Studies am UCL , der Ulster University und der Universidade Federal de Santa Maria in Brasilien für den Wellcome Mental Health Data Prize einreichen.

Wir freuen uns, bekannt geben zu können, dass wir für den Wellcome Trust Mental Health Data Prize an einem neuen Projekt namens „Harmony“ arbeiten. Dabei wird die Verarbeitung natürlicher Sprache verwendet, um sozialwissenschaftliche Daten aus verschiedenen Fragebögen wie dem GAD-7 und Beck’s Anxiety Inventory zu kombinieren, selbst wenn die Fragebögen in verschiedenen Sprachen verfasst sind!
What we can do for you