Wie wir mithilfe eines Clustering-Algorithmus für die Verarbeitung natürlicher Sprache dem Pharmaunternehmen Boehringer Ingelheim dabei geholfen haben, Einblicke in seine Herstellungsprozesse zu gewinnen und Probleme zu erkennen. Das Pharmaunternehmen Boehringer Ingelheim stellt eine Reihe von Medikamenten gegen Diabetes und Krebs sowie Tiergesundheitsprodukte her. Boehringer verfügt über ein großes Netzwerk von Produktionsstätten auf der ganzen Welt. Medikamente können in einem Land synthetisiert, in einem anderen verpackt und zur Verteilung in ein Drittland verschifft werden.
Fast Data Science - London
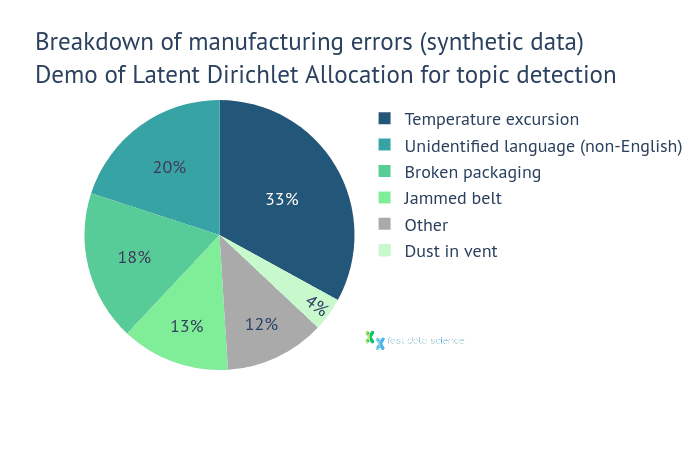
In den Produktions-, Verpackungs- und Vertriebsanlagen überwachen Mitarbeiter die Geräte und Produkte in allen Phasen auf Anomalien. Wenn ein Fehler auftritt, wird er in einem Computersystem mit einer freitextlichen Beschreibung des Problems protokolliert, z. B. „Temperaturschwankung aufgrund verstopfter Entlüftung“, „Verpackung beim Transport gerissen“ usw. Oft werden diese Fehler in einer lokalen Sprache und nicht in Englisch protokolliert.
Das Produktions- und Vertriebsteam von Boehringer wollte die häufigsten Herstellungsfehler identifizieren und in Kategorien einteilen. Leider war es aufgrund der Menge des Textes nicht praktikabel, dies manuell zu tun.
Zu diesem Zweck beauftragten sie Thomas Wood von Fast Data Science mit der Analyse des Textdatensatzes mithilfe von NLP-Techniken. Er erstellte ein Clustermodell (Themenfindung) mithilfe der Latent Dirichlet Allocation . Dieses Modell konnte die häufigsten Herstellungsfehler identifizieren und in Clustern zusammenfassen. Anhand der Ergebnisse der statischen Analyse konnte Boehringer klar erkennen, welche die Hauptursachen für Herstellungsfehler in ihrer Lieferkette waren.
Wenn Sie über eine große Anzahl unstrukturierter Textdokumente verfügen und Fast Data Science Sie bei der Themenfindung, Clusteranalyse oder einer anderen NLP-Analyse unterstützen soll, nehmen Sie bitte Kontakt mit uns auf .
What we can do for you