
Data Science beginnt in einer Organisation mit drei separaten Unterteams: dem Data-Science-Team, dem Data-Engineering-Team und dem Data-Operations-Team.
Wenn Sie ein kleines bis mittelgroßes Unternehmen haben, das seit mehreren Jahren erfolgreich ist, sich aber noch nicht in die Welt der Datenwissenschaft gewagt hat, fragen Sie sich vielleicht, wie Sie eine Datenwissenschaftsinitiative in Ihrem Unternehmen starten können.
Anfangs können Sie einige Ergebnisse erzielen, indem Sie für Ihre Data-Science-Arbeit externe Berater engagieren , irgendwann wird es jedoch notwendig, ein Data-Science-Team einzustellen.
Hier werde ich einen Überblick darüber geben, wie wir an den Aufbau eines Data-Science-Teams herangehen und worauf wir bei der technischen Due-Diligence -Prüfung von KI-Unternehmen achten.
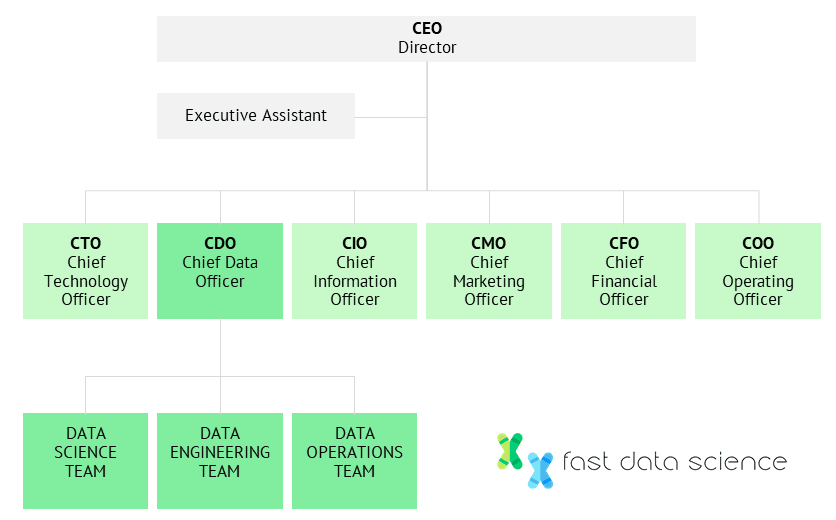
Ein mögliches Organigramm zeigt, dass das Data Science-Team, das Data Engineering-Team und das Data Operations-Team einer Führungskraft auf C-Ebene unterstellt sind, die eng mit dem CTO zusammenarbeitet, aber direkt dem CEO unterstellt ist. Bei dieser Art von Organisation haben die Data Scientists die Führung bei Projekten, an denen andere Abteilungen beteiligt sind.
Jesse Anderson, ein Data-Science- Berater und führender Experte auf diesem Gebiet , empfiehlt in seinem Buch „Data Teams“ [1], drei separate Teams einzustellen: das Data-Science-Team, das Data-Engineering-Team und das Operations-Team.
Das Data-Science-Team würde aus Personen mit akademischem Profil und fundierten Kenntnissen von Algorithmen des maschinellen Lernens bestehen.
Das Datentechnikteam erstellt Datenpipelines und befasst sich mit Skalenproblemen.
Schließlich ist das Betriebsteam dafür verantwortlich, dass die Infrastruktur reibungslos läuft.
Anderson empfiehlt, zunächst einen Dateningenieur und keinen Datenwissenschaftler einzustellen. Ein Dateningenieur kann eine Infrastruktur für die Datenwissenschaft besser einrichten als ein reiner Datenwissenschaftler. Er hält es für einen Fehler, zuerst Datenwissenschaftler einzustellen, da diese oft einen akademischen Hintergrund haben und wenig Verständnis für gute Programmier- und Ingenieurpraxis haben.
Der Dateningenieur sollte Erfahrung in der Softwareentwicklung haben, sich für Datenwissenschaften interessieren und insbesondere in der Lage sein, mit Skalen-, Datenbank- und Data Warehousing-Problemen umzugehen sowie Kenntnisse guter Programmierpraktiken zu besitzen.
Unternehmen, die zunächst einen Datenwissenschaftler einstellen, haben am Ende oft sehr frustrierte Datenwissenschaftler, die kaum Zugriff auf die Daten oder die Infrastruktur haben, die sie benötigen, und die schließlich nach sechs Monaten kündigen.
Sobald der Dateningenieur lange genug dabei ist, um mit der Einrichtung der Umgebung für die Datenwissenschaftsarbeit zu beginnen, ist es an der Zeit, den ersten Datenwissenschaftler einzustellen. Der Datenwissenschaftler sollte über ausgezeichnete Mathematikkenntnisse verfügen. Viele Organisationen, die ich gesehen habe, berücksichtigen nur Doktoranden oder zumindest Absolventen von Oxbridge und der Ivy League – ich denke, das geht zu weit. Da es Datenwissenschaft als Studiengang noch nicht sehr lange gibt, müssen Sie wahrscheinlich Absolventen aus MINT-Fächern wie Physik und Chemie in Betracht ziehen.
Fast Data Science - London
Ihr Datenwissenschaftler entwirft und trainiert Modelle für maschinelles Lernen , erstellt statistische Modelle und erledigt alles, was mit erweiterter Analytik zusammenhängt.
Während Ihr Datenwissenschaftler brauchbare Modelle erstellt, die in die Produktion gehen können, müssen Sie auch jemanden einstellen, der die Kontrolle über den Betrieb übernimmt – den täglichen Betrieb der Modelle, die Qualitätskontrolle , die Sicherstellung des Betriebs der Server, den Lastausgleich usw.
Im Laufe der Zeit können Sie die drei Datenteams rekrutieren und erweitern. Es gibt eine Reihe möglicher Berichtsstrukturen, die Sie wählen können. Meiner Erfahrung nach ist es jedoch am besten, sicherzustellen, dass das Datenwissenschaftsteam Zugriff auf eine Person mit ausreichend hohem Rang in der Organisation hat, die bei Bedarf Dinge in Gang setzen kann. Aus diesem Grund ist es oft eine gute Idee, direkt dem CTO, CEO oder einem Chief Data Officer zu berichten.
Zusätzlich zu den hervorragenden Empfehlungen von Jesse Anderson möchte ich einige der Probleme erläutern, die ich persönlich beobachtet habe, als Organisationen versucht haben, Data-Science-Initiativen zu starten.
Data-Science-Projekte benötigen häufig Zeit und Ressourcen anderer Abteilungen. Ein Projekt zur Optimierung von Lieferungen in einem Einzelhandelsunternehmen erfordert beispielsweise eine enge Zusammenarbeit mit der Logistikabteilung. Wenn das Data-Science-Team in der Hierarchie der Organisation weit unten angesiedelt ist, gibt es in der Logistikabteilung keinen Befürworter für das Projekt und die Data Scientists werden Mühe haben, Zeit oder Engagement von dieser Abteilung zu erhalten.
Manchmal arbeiten in einem Unternehmen mehrere Data Science-Teams an denselben Problemen, möglicherweise an unterschiedlichen Standorten, aufgrund früherer Akquisitionen oder anderer Faktoren. Vielleicht hat jemand in der Marketingabteilung an einem Machine-Learning-Projekt gearbeitet, bevor die unternehmensweite Data Science-Abteilung gegründet wurde. Dies kann zu einem Kompetenzstreit führen, da Manager in verschiedenen Teilen des Unternehmens um die Lorbeeren für tolle Data Science-Projekte buhlen.
Manager mit langjähriger Erfahrung in der Leitung von Softwareentwicklern neigen möglicherweise dazu, Data Science als eine Erweiterung von Softwareentwicklungsprojekten zu betrachten. Das bedeutet, dass sie den Data Scientists strikte Fristen für die Lieferung bestimmter Ergebnisse oder – noch schlimmer – KPIs auferlegen (Sie erhalten am Monatsende einen Bonus, wenn Ihr Modell eine Genauigkeit von 98 % erreicht).
In der Softwareentwicklung ist es möglich, ein Projekt in eine Reihe unabhängiger Aufgaben aufzuteilen. Ein Doktoranden-Forschungsprojekt hingegen besteht aus einer Reihe von Experimenten. Ein Data-Science-Projekt liegt irgendwo dazwischen. Es wird viel experimentiert, aber das Endergebnis ist im Idealfall ein fertiges Stück Software.
Da Data Science ein sehr experimentelles Projekt ist, lässt sich oft nicht von Anfang an sagen, ob ein Projekt überhaupt durchführbar ist. Ein Manager muss für diese Unbeständigkeit offen sein, sonst wird er bei der Leitung eines Teams von Data Scientists sehr frustriert sein, und die Data Scientists wiederum fühlen sich missverstanden und verlassen wahrscheinlich das Unternehmen.
Ich habe einen weiteren Blogbeitrag geschrieben, in dem ich meine Gedanken und Ideen zum Data-Science -Projektmanagement ausführlich darlege. Sie können ihn hier lesen.
Manchmal befürwortet der CTO des Unternehmens die Data-Science-Initiative, andere Führungskräfte sind jedoch skeptisch. Wenn das Data-Science-Team als Baby eines bestimmten Managers wahrgenommen wird, sind andere Manager möglicherweise desinteressiert oder lehnen das Projekt sogar ab. Es könnte sogar sein, dass Mitarbeiter und Manager in einem Teil des Unternehmens ihre Arbeitsplätze durch die Data-Science-Projekte bedroht sehen.
In manchen Unternehmen kann es passieren, dass das Data-Science-Team nur wenig Kommunikation oder Einblick in Geschäftsprozesse oder Entscheidungen hat. Wenn das Data-Science-Team beispielsweise gemeinsam mit der Marketingabteilung an einem Projekt arbeitet, hat es am Ende keinen direkten Kommunikationskanal zu den Marketingfachleuten und kann die Geschäftsanforderungen des Projekts nicht verstehen. Dies ist einer der Hauptgründe für das Scheitern von Data-Science-Projekten .
In Branchen wie dem Gesundheitswesen und der Pharmaindustrie können die geschäftlichen Probleme selbst hochtechnischer Natur sein. In manchen Fällen ist es fast unmöglich , Trainingsdaten einfach zu kennzeichnen, weil nur ein Mediziner damit umgehen kann und das erforderliche Personal anderweitig im Unternehmen beschäftigt ist. Die Data-Science-Manager sollten sich dieser Probleme bewusst sein und über genügend Einflussmöglichkeiten verfügen, um sicherzustellen, dass die Data Scientists Zugang zu den Personen haben, die sie zur Durchführung des Projekts benötigen.
Da Data Science so neu ist, gibt es kein etabliertes Muster für den Aufbau eines Teams. In einem kleinen bis mittelgroßen Unternehmen könnten Sie jedoch schlechter dran sein, als Jesse Andersons Empfehlung zu folgen und die Data-Science-Aufgaben in drei Teams aufzuteilen: Data Scientists, Data Engineers und Operations Engineers. Die erste Person, die Sie einstellen sollten, sollte nicht aus der Wissenschaft oder Mathematik kommen, sondern idealerweise mit einem Data Engineer mit Erfahrung in Softwareentwicklung, Data Warehousing und Datenbanken beginnen. Diese Person wird Ihnen helfen, die Grundlagen für eine robuste Data-Science-Architektur und ein Team mit minimalen technischen Schulden zu legen.
Suchen Sie Experten in Natürlicher Sprachverarbeitung? Veröffentlichen Sie Ihre Stellenangebote bei uns und finden Sie heute Ihren idealen Kandidaten!
Veröffentlichen Sie einen Job
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you