Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdeckenWas sind die wichtigsten Phasen in einem Data-Science-Projekt? Ein Rezept für einen erfolgreichen Ablauf eines Data-Science-Projekts.
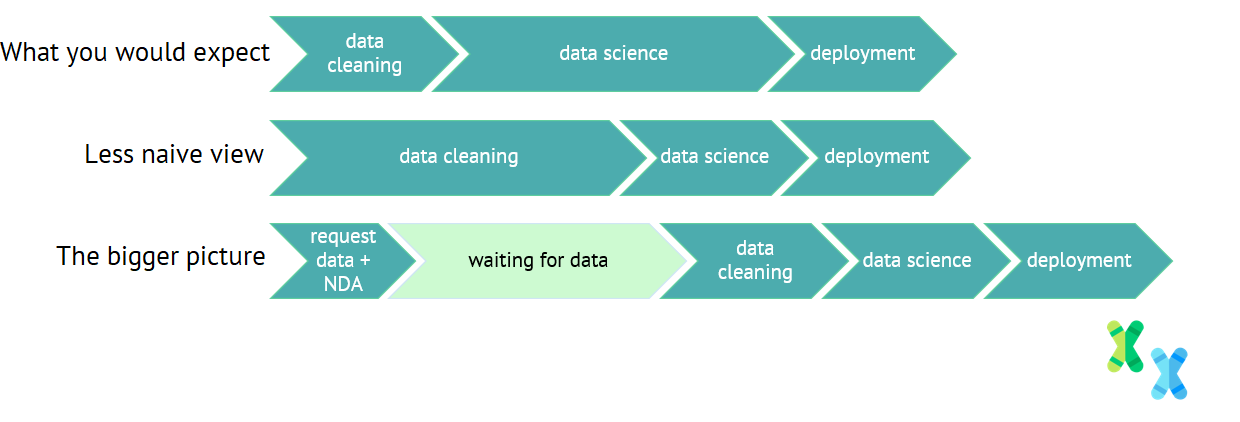
Wenn man ein Data-Science-Projekt plant, kann man es sich leicht als eine einfache Übung mit ein wenig Datenbereinigung, etwas Data-Science-Arbeit und einer Bereitstellungsphase am Ende des Projekts vorstellen. Tatsächlich könnten viele Datenwissenschaftler und Nicht-Datenwissenschaftler einen solchen idealisierten Datenwissenschaftsprojektablauf erwarten.

Ein fiktiver idealisierter Datenwissenschaftsprojektablauf
Leider ist die Realität selten so einfach.
Wenn Daten von einem Kunden bereitgestellt werden, sind diese wahrscheinlich chaotisch, enthalten Inkonsistenzen und erfordern viel Arbeit, um sie zu verstehen und nutzbar zu machen. Diese Arbeit wird oft als „Data Wrangling“ bezeichnet. Das bedeutet, dass die Phase der Datenbereinigung wahrscheinlich länger dauert als erwartet und sich in der Regel mit der Phase der Datenwissenschaft überschneidet.
Aus diesem Grund habe ich viele Beiträge von Datenwissenschaftlern gesehen, die andeuten, dass der Job zu 50 % aus der Datenbereinigung und nur zu 25 % aus der Datenwissenschaftsarbeit besteht.
Ein etwas realistischerer Ablauf eines Data-Science-Projekts.
Ich denke jedoch, dass das obige Modell die Komplexität der Bereitstellung nicht berücksichtigt.
Sobald die maschinelle Lernarbeit abgeschlossen ist, muss das Data-Science-Modell bereitgestellt werden.
Dies erfordert den Dialog mit dem Technik- und Geschäftsteam des Kunden und einen erheblichen Programmieraufwand, der in den Rückstand des Technikteams einfließen muss. Diese Phase unterliegt auch der Politik innerhalb der Kundenorganisation. Beispielsweise möchten einige Personen das Modell möglicherweise nicht bereitstellen, weil es in ihrer Abteilung schlecht aussieht, oder sie möchten es umgekehrt möglicherweise innerhalb ihrer Abteilung bereitstellen, um Anerkennung zu erhalten . Aufgrund all dieser Faktoren dürfte auch die Bereitstellungsphase deutlich länger dauern als erwartet.
Darüber hinaus gibt es meines Erachtens eine große Ursache für Verzögerungen, die oft völlig übersehen wird. Bevor das Data-Science-Projekt beginnen kann, müssen wir einige Schritte befolgen:
das Vertrauen des Kunden gewinnen
eine NDA unterzeichnen
Zugriff auf die Daten erhalten
Zugriff auf die Systeme des Kunden erhalten
Verstehen Sie, wer die wichtigsten Stakeholder des Projekts sind, wer es beschleunigen und wer es behindern kann.
Während Sie auf die Daten warten, prüfen Sie immer wieder, ob Blocker vorhanden sind, und bleiben Sie mit den Stakeholdern in Kontakt.
Fast Data Science - London
Ich denke, es ist fair, einen Monat einzuplanen, um an die Daten zu kommen. Ich habe teilweise Wartezeiten von 6 Monaten und mehr erlebt, und ich habe auch erlebt , dass Projekte scheiterten , weil die Daten nicht abgerufen werden konnten.
Daher würde ich die Phasen des Data-Science-Projekts wie folgt aufteilen:

Eine realistischere Sicht auf den Data-Science-Projektablauf für ein externes Data-Science-Beratungsunternehmen unter Berücksichtigung der Schwierigkeit der Datenbeschaffung und der entsprechenden Wartezeit.
Es gibt eine Reihe von Gründen, warum es schwierig sein kann, Daten für ein Projekt zu erhalten. Einige davon gelten unabhängig davon, ob Sie Mitarbeiter oder externer Berater sind, aber die Probleme sind für externe Data-Science-Berater tendenziell akuter als für interne Data-Scientists.
Wir können Daten in zwei Kategorien einteilen:
Offene oder öffentliche Daten – dabei handelt es sich um Daten, die für jeden im Internet kostenlos herunterladbar sind. Denken Sie an Regierungsstatistiken, Coronavirus-Statistiken, historische Datensätze und Kaggle-Wettbewerbe.
private/interne Daten. Hierbei handelt es sich um Daten, die ein Unternehmen über seine Kunden speichert, oder um andere wirtschaftlich oder rechtlich sensible Daten. Es ist oft durch Gesetze wie DSGVO oder HIPAA geschützt.
Für Data-Science-Projekte mit einem zahlenden Kunden wären normalerweise private Daten erforderlich. Die internen Daten eines Unternehmens können sein wertvollstes Gut sein. Dies ist nicht nur bei Technologieunternehmen der Fall, sondern zunehmend auch bei einigen stationären Unternehmen.
Damit ein Unternehmen seine Daten weitergeben kann, müssen alle Beteiligten an Bord sein und bereit sein, der datenwissenschaftlichen Beratung zu vertrauen. Der Kunde und das Beratungsunternehmen müssen sich auf die Geschäftsbedingungen einigen und eine Vertraulichkeitsvereinbarung (NDA) unterzeichnen. Wenn dies das erste Mal ist, dass das Kundenunternehmen Data Science betreibt, ist es möglicherweise mit diesem Prozess nicht vertraut und die Ausarbeitung der NDA kann einige Zeit in Anspruch nehmen. Die Weitergabe von Daten an Außenstehende ist für Unternehmen kein großes Anliegen, wenn dies nicht unbedingt erforderlich ist.
Aus diesem Grund gibt es viele Unternehmen in traditionellen Branchen wie Versicherungen und Rechtswesen, die über Goldminen an Daten, insbesondere Textdaten, verfügen, aber nicht über die interne Expertise verfügen, um daraus einen Mehrwert zu ziehen.
Da die Folgen einer Nichtverfügbarkeit der Daten zu Projektbeginn sowohl für den Kunden als auch für den Berater schwerwiegend sind, würde ich vorschlagen, so viele Schritte wie möglich zu unternehmen, um dies zu verhindern.
Zunächst einmal würde ich einen Monat vor Projektstart folgende Schritte unternehmen:
- NDA
- Access to the data
- Access to cloud computing account, source control accounts, any internal document repositories – if applicable
- Identification of all key stakeholders, who to report to, any other concerned individuals in the organisation
- specify an individual to contact in case of project blockers
Vereinbaren Sie eine Woche nach dieser E-Mail und einen Monat vor Projektstart ein Kickoff-Meeting , bei dem im Idealfall einige der oben genannten Punkte bereitgestellt worden wären
Besprechen Sie beim Kickoff-Meeting alle offenen Fragen, die das Projekt blockieren könnten
Bleiben Sie nach dem Treffen mit den Stakeholdern in Kontakt, um sicherzustellen, dass alles bereit ist, um mit dem Projekt zu beginnen.
Durch diese Maßnahmen können wir sicherstellen, dass alle Daten vor dem ersten abrechenbaren Tag des Projekts verfügbar sind und etwaige Hindernisse frühzeitig identifiziert werden können.
Der Kunde kann Ihnen sagen, dass das Kickoff-Meeting nicht notwendig ist und dass Sie sich keine Sorgen machen sollten, da alles für Montagmorgen vorbereitet ist, wenn das Projekt beginnen soll. Ich würde empfehlen, dies mit einer Prise Salz einzunehmen! Ein Hindernis, an das niemand gedacht hat, wird am Montag um 9 Uhr in letzter Minute auftauchen. Vielleicht ist jemand im Tech-Support-Team im Urlaub, ein Anwalt muss die Vertraulichkeitsvereinbarung mit seinem Vorgesetzten abklären oder ein hochrangiger Manager im Unternehmen hat gerade von dem Projekt gehört und möchte seinem Chef seinen Stempel aufdrücken, weil er … Der Jahresrückblick steht an.
Wichtige Schritte in einem Data-Science-Projekt: drei verschiedene Ansichten des Data-Science-Projektablaufs.
Wir übersehen oft die Hindernisse, die einem Data-Science-Projekt im Weg stehen. So wie ein Auto nicht ohne Treibstoff fahren kann, kann ein Data-Science-Projekt nicht ohne Daten laufen. Die Beschaffung interner Daten für ein Kundenprojekt ist selten einfach und kann durch eine Vielzahl interner und externer Faktoren blockiert werden. Aus diesem Grund ist die NDA eines der wichtigsten und kritischsten Elemente eines Data-Science-Projekts.
Wenn die Daten nicht rechtzeitig eingeholt werden, führt dies zu unnötigen Verzögerungen bei einem Projekt. Das Risiko lässt sich am besten durch eine sorgfältige Planung und Nachverfolgung seitens des Data-Science-Beraters mindern.
Um Sie bei der Planung Ihres Data-Science-Projekts zu unterstützen, haben wir im Abschnitt „ Ressourcen “ unserer Website eine Data-Science-Projekt-Kickoff-Checkliste bereitgestellt, zusammen mit einem browserinternen Gantt-Diagrammgenerator für NLP-Projekte , einem Data-Science-Roadmap-Planer und einem Projektkostenplaner Tabellenkalkulation und ein Projektrisikotool .
Eine frühere Version dieses Artikels erschien ursprünglich auf freelancedatascientist.net .
Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdecken
Mittlerweile sind es Organisationen aller Größenordnungen und fast aller Sektoren werden zunehmend datengesteuert, insbesondere als größere Datenspeicher Systeme und schnellere Computer treiben die Leistungsgrenzen immer weiter voran.

Aufgrund des umfangreichen Einsatzes von Technologie und der Arbeitsteilung hat die Arbeit des durchschnittlichen Gig-Economy-Arbeiters jeden individuellen Charakter und damit auch jeden Charme für den Arbeitnehmer verloren.
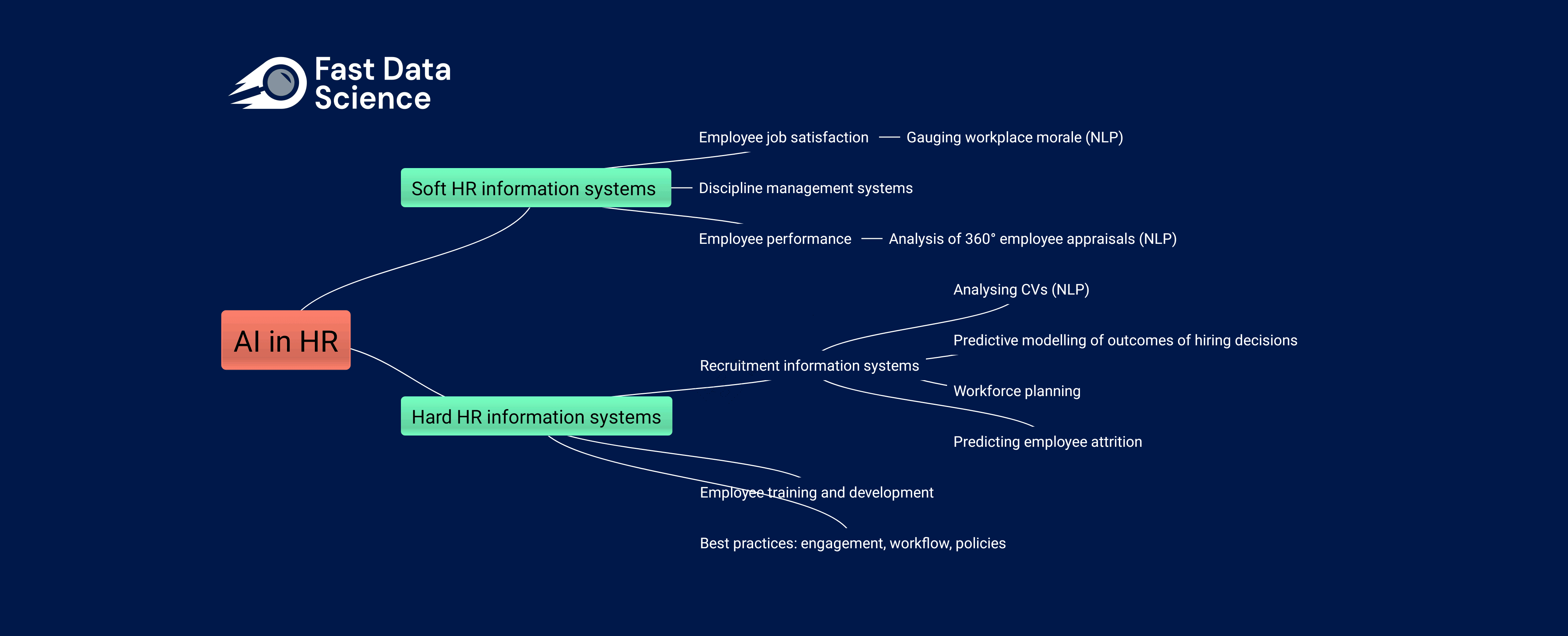
Die Auswirkungen von KI auf die Humanressourcen Die Arbeitswelt verändert sich rasant, sowohl aufgrund der Einführung traditioneller Data-Science-Praktiken in immer mehr Unternehmen als auch aufgrund der zunehmenden Beliebtheit generativer KI-Tools wie ChatGPT und Googles BARD bei nicht-technischen Arbeitnehmern.
What we can do for you