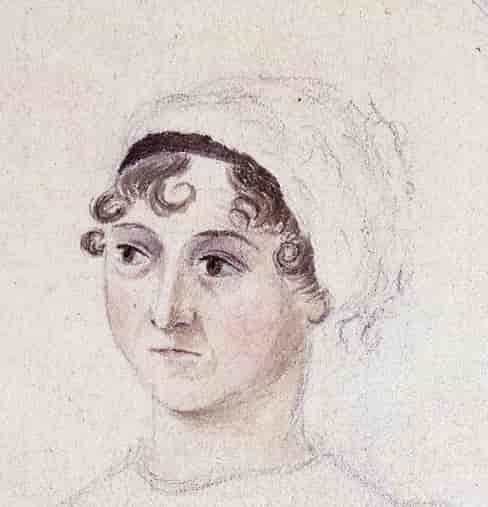
Fast Data Science hat ein einzigartiges forensisches Stilometriemodell entwickelt, mit dem Sie den Autor eines Textes anhand seines einzigartigen stilistischen und linguistischen „Fingerabdrucks“ identifizieren können. Für eine genaue Identifizierung ist ein relativ langer Text erforderlich, beispielsweise einige Kapitel eines Buches.
For best results try entering at least two or three paragraphs of text. You can get some free writing samples by visiting Project Gutenberg, or the contemporary authors' websites (Pottermore, Dan Brown, Philip Pullman). JK Rowling wrote some books under the pseudonym Robert Galbraith. Try testing if the model can correctly identify the author. If the text has no resemblance to any of the known author’s works, the model will output some very small probabilities.
Das Modell wurde anhand der folgenden Bücher trainiert. Wenn Sie ihm also ein Buch wie Villette von Charlotte Brontë geben, das nicht auf der Liste steht, wird es hoffentlich Brontë als die richtige Autorin identifizieren, obwohl es das Buch nie gesehen hat.
Jane Austen (1775-1817) war vor allem für „Stolz und Vorurteil“ bekannt, schrieb aber tatsächlich sechs Romane. Das forensische Stilometriemodell wurde anhand von drei ihrer Romane trainiert. Kann es die anderen erkennen?
Ich habe hier ein Tutorial zur Verwendung der forensischen Stilometrie mit der Python-Bibliothek Faststylometrie geschrieben: Fast Stylometrie-Tutorial .
Eine hervorragende Einführung in verschiedene Stilometrietechniken finden Sie hier: Einführung in die Stilometrie mit Python .
Ich empfehle außerdem die Lektüre des Aufsatzes „Stylometry with R: A Package for Computational Text Analysis“ von Maciej Eder, Jan Rybicki und Mike Kestemont, der einen Überblick darüber bietet, wie man mit dem Grafikpaket Stylo in R wissenschaftlich fundierte stilometrische Analysen von Texten durchführt.
Mithilfe von Stylo und anderen wissenschaftlichen Paketen können Linguisten und Geisteswissenschaftler Texte in verschiedenen Sprachen auf Fälle umstrittener historischer Urheberschaft analysieren. Ich hatte beispielsweise eine Anfrage zu einer Reihe lateinischer Texte, bei denen sich die Wissenschaftler nicht einig waren, welcher Historiker der wahre Autor ist! Die Technik wird auch von forensischen Linguisten für Rechtsfälle eingesetzt.
Die von diesem Stilometriemodell ausgegebenen Wahrscheinlichkeiten werden aus einem Wahrscheinlichkeitskalibrierungsprozess abgeleitet, der die Burrows-Delta-Statistik in einen Wahrscheinlichkeitswert umwandelt, der auf der Verteilung der Burrows-Delta-Werte in den Trainingsdaten basiert. Das bedeutet, dass allen Autoren eine Wahrscheinlichkeit nahe Null zugewiesen wird, wenn der von Ihnen eingegebene Text keinem der bekannten Autoren ähnelt. Umgekehrt können die Wahrscheinlichkeiten eine Zahl größer als 1 ergeben, da jede Wahrscheinlichkeit unabhängig berechnet wird.
Viele Modelle des maschinellen Lernens, die Sie ausprobieren können (beispielsweise die iPhone-Apps, die Sie herunterladen können und die Ihnen sagen, welcher Hunderasse Ihr Hund angehört oder wie alt Ihr Gesicht aussieht), neigen dazu, unangemessene Wahrscheinlichkeiten auszugeben, weil sie auf einer Softmax-Schicht basieren, die alle Ausgabewerte so zwingt, dass die Summe 1 ergibt. Eine Softmax-Schicht neigt dazu, Wahrscheinlichkeiten auszugeben, die entweder sehr nahe bei 0 oder sehr nahe bei 1 liegen.
Ich habe mich für die Verwendung einer Wahrscheinlichkeitskalibrierungstechnik für diese Demo entschieden, um die merkwürdigen Effekte zu vermeiden, die mit der (Fehl-)Interpretation einer Softmax-Ausgabe als Wahrscheinlichkeit verbunden sind.
Wir können die Wahrscheinlichkeit berechnen, dass ein Text von einem generativen KI-Modell wie BARD oder ChatGPT verfasst wurde, indem wir die Perplexität des Modells berechnen (wie überrascht es von dem Dokument ist). In letzter Zeit kommt es im Hochschulbereich häufig zu Streitigkeiten, bei denen ein Student beschuldigt werden kann, KI zum Schreiben einer Arbeit verwendet zu haben.
Probieren Sie unseren generativen KI-Detektor aus .
Wenn Sie in den Bereichen KI, NLP oder anderen Bereichen forschen und Ihre Ergebnisse veröffentlichen, wäre ich Ihnen dankbar, wenn Sie das Projekt zitieren könnten.
Wood, TA, Fast Stylometry [Computersoftware] (1.0.4). Data Science Ltd. DOI: 10.5281/zenodo.11096941, abgerufen unter https://fastdatascience.com/fast-stylometry-python-library , Fast Data Science (2024)
![]()
Ein BibTeX-Eintrag für LaTeX-Benutzer lautet:
@software{faststylometrie,
author = {Wood, T.A.},
title = {Fast Stylometry (Computer software), Version 1.0.4},
year = {2024},
url = {https://fastdatascience.com/fast-stylometry-python-library/},
doi = {10.5281/zenodo.11096941},
}
What we can do for you