Suchen Sie Experten in Natürlicher Sprachverarbeitung? Veröffentlichen Sie Ihre Stellenangebote bei uns und finden Sie heute Ihren idealen Kandidaten!
Veröffentlichen Sie einen JobEinige Möglichkeiten, wie wir kausale Effekte mithilfe von maschinellem Lernen , Statistik und Ökonometrie modellieren können, von einem religiösen Text aus dem 6. Jahrhundert bis zum kausalen maschinellen Lernen von 2021, einschließlich der kausalen Verarbeitung natürlicher Sprache .
Stellen Sie sich vor, Sie erhalten einen Datensatz von Schülern und ihren Studienverläufen im Laufe der Zeit und möchten herausfinden, ob eine Karriere-Coaching-Intervention die Wahrscheinlichkeit erhöht oder verringert, dass ein Schüler eine Universität besucht.
Sie analysieren den Datensatz und können einige Zusammenhänge erkennen. Möglicherweise besuchen bestimmte Untergruppen von Studierenden eine Universität, nachdem sie eine Intervention erhalten haben, und bei einigen Gruppen scheint die Wahrscheinlichkeit, dass sie eine Universität besuchen, wenn sie die Intervention erhalten haben, geringer zu sein.
Der Haken ist, dass Studierende, die sich für Coaching interessierten, möglicherweise sowieso daran interessiert waren, eine Universität zu besuchen. Oder bot die Schule Karriere-Coaching vielleicht nur für Schüler an, bei denen das Risiko eines Schulabbruchs bestand, vielleicht für Schüler aus einkommensschwächeren Verhältnissen?
Bei beiden Möglichkeiten beeinflussten das Interesse, die Eignung oder der sozioökonomische Status des Studenten die Chancen, ein Karriere-Coaching zu erhalten, und beeinflussen auch die Chancen, eine Universität zu besuchen. Ein solcher externer Faktor wird als „Confounder“ bezeichnet. Wie können Sie feststellen, ob das Karriere-Coaching die Entscheidung eines Studenten für ein Studium beeinflusst hat, wenn es einen Störfaktor gibt, der sowohl die Entscheidung für ein Karriere-Coaching als auch die Wahrscheinlichkeit, sich für ein Studium zu entscheiden, beeinflusst?
 can influence the choice to deliver an intervention, but can also directly influence the effectiveness of the intervention. How can we untangle this to discover causal relationships between the intervention and the final outcome?](https://fastdatascience.com/images/causal-machine-learning-confounders-on-career-coaching-2-min.png)
Faktoren wie der sozioökonomische Status und die akademische Leistung können die Entscheidung für die Durchführung einer Intervention beeinflussen, können aber auch direkt die Wirksamkeit der Intervention beeinflussen. Wie können wir dies entwirren, um kausale Zusammenhänge zwischen der Intervention und dem Endergebnis zu entdecken?
Selbst bei einem großen, sauberen und ansonsten idealen Datensatz kann es sehr schwierig sein, kausale Auswirkungen zu identifizieren. Der Kausalschluss ist mit Schwierigkeiten verbunden.
Herkömmliche Techniken des maschinellen Lernens basieren auf der Identifizierung von Korrelationen und der Vorhersage von Ergebnissen auf der Grundlage von Mustern in vergangenen Daten. Beispielsweise kann ein sehr einfaches Modell des maschinellen Lernens, etwa ein logistisches Regressionsmodell , darauf trainiert werden, die Wahrscheinlichkeit vorherzusagen, mit der ein hypothetischer Student eine Universität besuchen wird, wenn Informationen darüber vorliegen, ob er eine Intervention erhalten hat oder nicht. Wenn die Intervention jedoch mit der Begabung und dem sozioökonomischen Hintergrund des Schülers verknüpft ist, sagt uns das Modell des maschinellen Lernens möglicherweise nicht viel.
Wenn Sie entweder traditionelles nichtkausales maschinelles Lernen oder Statistiken verwenden, können Sie sogar seltsame Effekte feststellen, wie zum Beispiel die folgenden:
Dieser Effekt kommt überraschend häufig vor und ist als Simpson-Paradoxon bekannt. Modelle, die die Kausalität nicht berücksichtigen, sind anfällig für diese Art der Fehlinterpretation von Daten.
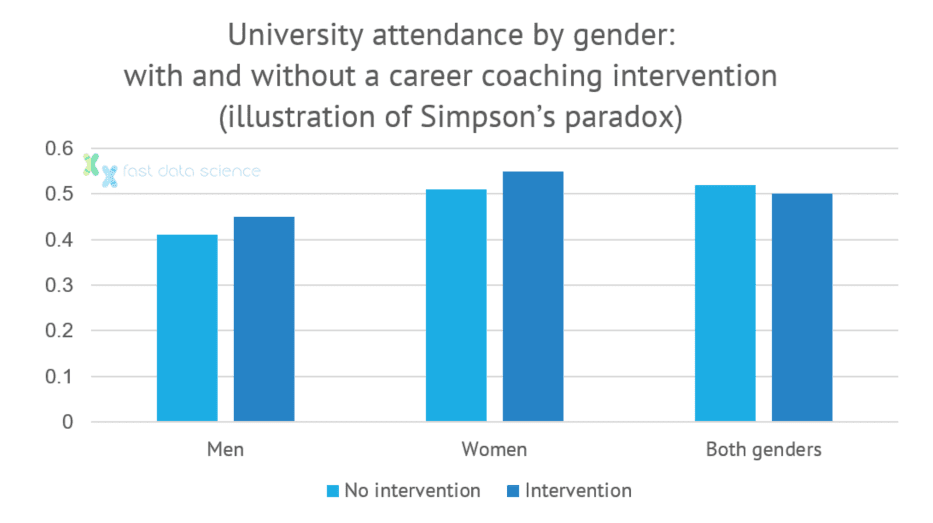
Ein Beispiel für das Simpson-Paradoxon: Eine Intervention scheint einen negativen Effekt zu haben, wenn wir beide Geschlechter zusammen betrachten, aber wenn wir jedes Geschlecht isoliert betrachten, hat die Intervention einen positiven Effekt.
Wenn Sie die Anzahl der an das Modell übergebenen Karriere-Coaching-Interventionen erhöhen, wird ein hypothetischer Student simuliert, der mehr Interventionen erhalten hat, aber implizit hat dieser fiktive Student jetzt einen anderen sozioökonomischen Hintergrund und war schon vor dem Modell mit mehr oder weniger hoher Wahrscheinlichkeit an der Universität Intervention hat stattgefunden!
Unabhängig davon, ob wir nur eine Grafik unserer Daten betrachten, Zahlen durchforsten oder ein Modell für maschinelles Lernen erstellen, wird das Ergebnis dasselbe sein: Wir wissen nicht, inwieweit und in welchem Ausmaß ein Unterschied in den Ergebnissen der Schüler auf eine Intervention zurückzuführen ist es liegt am Hintergrund des Schülers.
Weitere analoge Beispiele für das obige Problem sind:
Wir möchten anhand eines Datensatzes von einigen tausend Patienten herausfinden, ob eine medizinische Behandlung zur Genesung geführt hat. Patienten, die sich für die Behandlung entscheiden, sind jedoch tendenziell in einem schlechteren Zustand als diejenigen, die dies nicht tun.
In diesem Fall ist der anfängliche Gesundheitszustand des Patienten ein Störfaktor. Wenn wir uns nur die Kohorten von Patienten mit und ohne Behandlung ansehen, scheinen sich diejenigen ohne Behandlung besser erholt zu haben, was den Eindruck erweckt, dass die Behandlung eher schädlich als nützlich war.
Unten können Sie ein reales Beispiel des Simpson-Paradoxons aus einer 1986 in London durchgeführten Studie über Nierensteine testen [14] . Die Forscher wollten herausfinden, welche der beiden Behandlungen von Nierensteinen eine bessere Heilungsrate hatte. Das Paradoxe besteht darin, dass Behandlung B wirksamer zu sein scheint, wenn wir beide Größen von Nierensteinen zusammen betrachten, während Behandlung A eine bessere Heilungsrate aufweist, wenn wir beide Größen isoliert betrachten. Durch Anpassen der Zahlen können Sie das Verhältnis ändern und herausfinden, welche Zahlen das Simpson-Paradoxon erscheinen oder verschwinden lassen.