
Haben Sie sich schon einmal Gedanken über die Rolle von KI in der Data Science-Beratung gemacht? Lesen Sie weiter und erfahren Sie mehr über ihre Bedeutung und Relevanz.
Data Science Consulting ist eine relativ neue Unterdisziplin der Unternehmensberatung. Data Science-Berater nutzen die neuesten KI-Technologien, um Veränderungen in Unternehmen einzuführen, die enorme Gewinne einbringen können. Unternehmen aus den unterschiedlichsten Branchen holen externe Berater an Bord, die sie dabei unterstützen, datenbasierte Geschäftsentscheidungen zu treffen und Ergebnisse zu verbessern. Während es für viele Organisationen üblich ist, ein eigenes Data Science-Team zu haben, nehmen selbst große Unternehmen die Dienste von Data Science-Beratern in Anspruch, da es an Experten mangelt und die Vielfalt der erforderlichen Data Science-Spezialisierungen unterschiedlich ist.

Früher wurde bei der Datenerfassung nur mit Tabellenkalkulationen und Papieraufzeichnungen gearbeitet. Diese Zeiten sind lange vorbei. Heute können Daten auf verschiedene Arten erfasst werden. Maschinelles Lernen gibt es schon seit den 1950er Jahren, aber in den letzten Jahren hat die Technologie große Fortschritte gemacht.
Aufgrund der hohen Nachfrage nach Data-Science-Diensten und des Mangels an interner Erfahrung in vielen Organisationen wird ein Data-Science-Beratungsmodell immer üblicher.
Heute sind die Implementierungen von Algorithmen deutlich verbessert, sodass Computer Daten nicht nur verstehen, sondern auch daraus lernen und darauf basierende Entscheidungen treffen können. Darüber hinaus ermöglicht KI Maschinen, ihr Wissen zu verbessern, wenn neue Eingaben hinzugefügt werden, die nicht Teil des ursprünglichen Datensatzes waren.
KI muss über ausreichend Daten verfügen, um daraus lernen zu können. Wenn zum Trainieren von KI-Modellen nur begrenzte Datenpools verwendet werden, ist die Entscheidungs- und Vorhersagegenauigkeit gering. Je mehr Daten verfügbar sind, desto besser ist also das Training des KI-Modells und desto genauer ist das Ergebnis. Schnellere Computerleistung ist mit dem Aufstieg von Big Data verbunden, und dies hat dazu geführt, dass viele CEOs an Möglichkeiten zur Innovation ihrer Organisationen arbeiten.
Wenn Manager bereit sind, neue Dienstleistungen oder Produkte auf den Markt zu bringen, verlassen sie sich heute auf die Datenwissenschaft, um Erkenntnisse über Nachfrage, Markt, Zielgruppe und vieles mehr zu gewinnen. Es ist daher keine Überraschung, dass KI und ihre Untergruppen maschinelles Lernen und Deep Learning so bereitwillig in die Unternehmenswelt übernommen werden.
Obwohl viele große Unternehmen mittlerweile über eigene Data Science-Teams verfügen, ist es oft notwendig, externe Data Science-Berater einzustellen, um an der gesamten Datenstrategie zu arbeiten, die Datenerfassung, -speicherung, -lagerung, Modellentwicklung, -analyse, -bereitstellung und -wartung umfasst. Insbesondere öffentliche Stellen können aufgrund von Budgetbeschränkungen oft nicht genügend Vollzeit-Data Scientists einstellen und greifen daher immer häufiger auf Ausschreibungsverfahren zurück, um Data Science-Beratungsunternehmen auf Projektbasis zu beauftragen.
Eine Herausforderung für Data Science-Berater besteht darin, den Umfang, die Definition und die Preisgestaltung von Projekten festzulegen. Viele Vordenker in der Beratungsbranche, wie z. B. Alan Weiss , plädieren dafür, Projekte nach dem für den Kunden erbrachten Wert zu bepreisen und nicht nach einem Tagessatz, unabhängig von der vom Berater aufgewendeten Zeit.
Beratungsunternehmen, die Dienstleistungen wie Softwareentwicklung anbieten, verwenden häufig auch projektbasierte Preise. Dies ist jedoch in der Data-Science-Beratung immer noch selten. Der Hauptgrund ist das Risiko : Ein Data-Science-Projekt hat selbst mitten im Projekt so viele Unbekannte, dass es für den Berater äußerst schwierig ist, genau zu definieren, was erreichbar sein wird. Aus diesem Grund ziehen es viele Data-Science-Berater vor, einen Tagessatz abzurechnen.
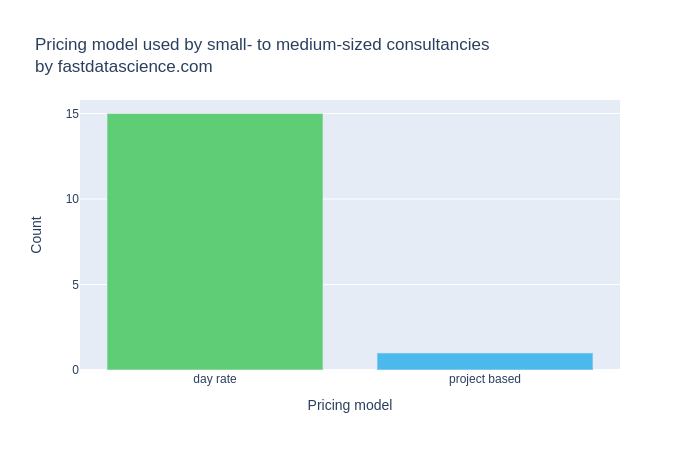
Die überwiegende Mehrheit der befragten kleinen und mittelgroßen Data-Science-Beratungsunternehmen bot ihre Preise nur nach Tagessätzen und nicht auf Projekt- und Meilensteinbasis an.
Bei Fast Data Science haben wir eine Umfrage unter 16 kleinen bis mittelgroßen Data Science-Beratungsunternehmen in den USA und Europa durchgeführt, deren Mitarbeiterzahl zwischen 1 oder 2 und 80 Personen lag. Fast alle Beratungsunternehmen berechneten ihre Projekte in der Regel auf Tagesbasis, und wir konnten nur eines finden, das projekt- oder produktbasierte Preise anbot. Große Data Science-Beratungsunternehmen wie die Big Four können jedoch Tarife verlangen, die hoch genug sind, um das Risiko abzudecken, und berechnen ihre Beratungsleistungen auf Projektbasis mit einer Geld-zurück-Garantie.
Anschließend führten wir eine Umfrage unter 10 potenziellen Kundenunternehmen in unserem Netzwerk durch, die Data Science-Beratungen beauftragen, darunter sowohl unsere Kunden als auch Nicht-Kunden. Von den 10 Befragten bevorzugten 50 % tatsächlich eine projektbasierte Zahlungsbasis.

50 % der Kunden von Data Science-Beratungen in unserer Fokusgruppe bevorzugten eine projektbasierte Zahlungsstruktur
Das ist interessant, weil es eine Diskrepanz zwischen dem, was Kunden von Data Science-Beratungen suchen, und dem, was die Beratungsunternehmen anbieten, aufzeigt. Kurz gesagt, beide Seiten wollen, dass die andere das Risiko übernimmt. Das ist für mich der Hauptunterschied zwischen Data Science-Beratung und anderen Beratungsarten: Risiko und Unbekanntes werden das Gespräch und die Beziehung zwischen Berater und Kunde dominieren.
Trotzdem würde ich nicht empfehlen, ein großes Beratungsunternehmen zu engagieren, wenn Sie einen externen Data Science-Berater benötigen. Große Unternehmen versuchen oft, alle Bereiche abzudecken, und verfügen daher nicht über die Nischenkompetenz, die ein kleines Data Science-Beratungsunternehmen bieten kann. Darüber hinaus verlangen große Unternehmen mehr als doppelt so hohe Honorare wie kleinere Beratungsunternehmen, wodurch sie das Risiko schlucken können.
Bei Fast Data Science sind wir auf die Verarbeitung natürlicher Sprache spezialisiert. Unsere Fachkompetenz in diesem Nischenbereich der Datenwissenschaft ermöglicht es uns, unseren Kunden in sehr kurzer Zeit einen gleichbleibend hohen Mehrwert zu bieten. Darüber hinaus zielen wir strategisch auf Branchen ab, die naturgemäß große Mengen an Textdaten enthalten, wie etwa Gesundheitswesen , Pharma, Versicherungen und Versand , sodass wir sowohl unsere technische als auch unsere Facherfahrung auf die Website des Kunden bringen und sofort loslegen können. Obwohl wir kein großes Unternehmen sind, sind wir bereit, je nach den Wünschen des Kunden entweder projekt- oder zeitbasierte Preise anzubieten.
Aus Sicht vieler der von uns befragten Kundenunternehmen ist es vorteilhafter, einen Data Science-Berater mit genau der erforderlichen Erfahrung zu engagieren, als sich an ein großes Beratungsunternehmen zu wenden, das behauptet, Expertise in allen Bereichen der Data Science anbieten zu können.
Unternehmen sammeln heutzutage riesige Mengen an Daten, und diese Daten sind wertvoll. Mit mehr Daten können Unternehmen Geschäftseinblicke gewinnen, die zu höheren Umsätzen führen. Dank Data Science-Beratern ist es möglich, Muster in Daten aufzudecken, die vorher nie offensichtlich gewesen wären. Unternehmen nutzen diese Technologien jetzt, um Empfehlungsmaschinen zu erstellen, das Nutzerverhalten vorherzusagen und mehr.
](https://fastdatascience.com/images/111hyn66hcw.jpg)
Datenwissenschaft wird zur Bekämpfung von Kreditkartenbetrug eingesetzt
Der Finanzsektor nutzt zunehmend künstliche Intelligenz und Data Science-Berater, um Betrug bei Finanztransaktionen aufzudecken. TensorFlow und Keras sind nur zwei Frameworks für neuronale Netzwerke , die Data Science-Berater für Deep Learning verwenden. Mithilfe dieser Pakete können Forscher immer ausgefeiltere Algorithmen zur Anomalieerkennung verwenden, um betrügerische Transaktionen zu identifizieren.
Banken können heute die Finanztransaktionen, Kreditscores und Bankhistorien von Millionen von Kunden sorgfältig prüfen, um Versicherungs- oder Kreditbetrug in Echtzeit zu erkennen und zu verhindern. Dies gibt ihren Kunden mehr Sicherheit und ein besseres Gefühl für ihr Geschäft. Dadurch konnten in den letzten Jahren enorme Geldsummen eingespart werden und Betrügern wurde die Arbeit deutlich erschwert.
Bei Fast Data Science haben wir eine Reihe von Data-Science-Beratungsaufträgen im Gesundheitswesen übernommen. Die Branche verfügt über eine große Menge unstrukturierter Daten, die durch Datenschutzbestimmungen wie die DSGVO (in Europa) oder HIPAA (in den USA) gesperrt wurden. Dies bedeutet, dass es ein großes ungenutztes Potenzial für die Wertschöpfung durch Data Science gibt. Da groß angelegte Data Science im Gesundheitswesen relativ neu ist und die betreffenden Organisationen oft keine eigenen Data Scientists mit der richtigen Spezialisierung haben, wird häufig auf Berater zurückgegriffen.
Beispielsweise sucht der britische National Health Service (NHS) regelmäßig nach Beratungsfirmen, die bei datenwissenschaftlichen Problemen helfen. Der NHS hatte ein Problem mit massiver Fluktuation seiner Mitarbeiter . Er beschäftigt in Großbritannien 1,2 Millionen Menschen und investiert im Fall von Assistenzärzten oft Hunderttausende Pfund in deren Ausbildung. Wenn ein Arzt seine Ausbildung verlässt, bedeutet dies einen großen finanziellen Verlust für den NHS und letztlich für den britischen Steuerzahler.
Der NHS hat auf dem Digital Marketplace der britischen Regierung nach Data Science-Beratungsleistungen gesucht, und Fast Data Science konnte sich gemeinsam mit einem anderen Data Science-Beratungsunternehmen erfolgreich um das Projekt bewerben. Wir konnten eine Analyse der Mitarbeiterliste des NHS durchführen, um gemeinsame Faktoren für das Ausscheiden von Mitarbeitern aus dem Unternehmen zu ermitteln, und haben sogar ein prädiktives maschinelles Lernmodell erstellt, das die höchst persönlichen Daten, die der NHS über jeden Mitarbeiter speichert, nutzen und die Wahrscheinlichkeit vorhersagen kann, mit der diese Person den Dienst verlässt. Weitere Informationen zum Projekt finden Sie hier .
Die Analyse und das Vorhersagemodell wurden von der NHS-Leitung übernommen und in die künftige Politikgestaltung integriert, um die Mitarbeiterfluktuation zu reduzieren.
Pharmaunternehmen verfügen über große Mengen an Textdaten in Form von Herstellungsdokumenten, Protokollen klinischer Studien und wissenschaftlicher Literatur. Da wir bei Fast Data Science auf die Verarbeitung natürlicher Sprache spezialisiert sind, haben wir festgestellt, dass diese Branche ein idealer Schwerpunkt für unsere Fähigkeiten ist.
Pharmaunternehmen haben uns als Data-Science-Berater an Bord geholt, um:
Ein weiteres Beispiel für die Anwendung von KI im medizinischen Bereich ist IBM Watson Health. Diese Technologie nutzt die Leistungsfähigkeit der Datenwissenschaft, um Ärzten dabei zu helfen, wichtige Informationen in den Krankenakten von Patienten schnell zu identifizieren, damit relevante Beweise vorgelegt und die am besten geeigneten Behandlungsoptionen untersucht werden können. Im Wesentlichen vergleicht sie die Krankenakten eines Patienten mit Informationen aus einer riesigen Sammlung von Lehrbüchern, Texten und Zeitschriften, um personalisierte Empfehlungen zu geben. Dadurch können Ärzte sofort auf eine große Fülle personalisierter Informationen zugreifen, die auf den einzelnen Patienten zugeschnitten sind. IBM hat einer Reihe von Gesundheitsorganisationen, wie beispielsweise den New York City Social Services, Beratungsdienste im Bereich Datenwissenschaft angeboten.
Neben den oben genannten Beispielen aus dem Gesundheitswesen hat Fast Data Science auch einige Projekte für den großen britischen Einzelhändler Tesco durchgeführt. Dies verdeutlicht die Vielseitigkeit von Data-Science-Kenntnissen und zeigt, wie ein Data-Science-Beratungsunternehmen problemlos zwischen verschiedenen Branchen wechseln kann.
Tesco verfügt über ein Online-Bestellsystem für Lebensmittel, mit dem Kunden, die von zu Hause aus einkaufen, Bestellungen zur Lieferung aufgeben können. Die Benutzeroberfläche zeigt dem Kunden verfügbare Liefertermine an, er wählt einen Termin aus und wählt dann seine Einkäufe aus. Das Problem bei Tesco besteht darin, dass ein Kunde nach der Zuweisung eines Termins unerwartet eine große Menge an Artikeln in seinen Einkaufskorb legen kann und der Lieferwagen dann nicht alle Einkäufe transportieren kann, da er zu schwer ist.
Fast Data Science kam als Berater an Bord und konnte ein Vorhersagemodell implementieren, um das Gewicht des Einkaufs eines Kunden in Kilogramm vorherzusagen, basierend auf der Einkaufshistorie dieser Person, demografischen Daten und saisonalen Trends (z. B. dem Weihnachtsgeschäft). Dadurch konnte Tesco die Nachfrage der Käufer besser vorhersehen und den Käufern Lieferfenster effizienter zuweisen. Die Supermarktkette konnte die Zahl der Lieferwagen, die zur Auslieferung einer festgelegten Einkaufsmenge eingesetzt wurden, um bis zu 3 % reduzieren. Dies zeigt die Leistungsfähigkeit der Data-Science-Beratung im Kontext eines großen Unternehmens.
Heutzutage ist der Begriff „ Fake News “ weit verbreitet. Organisationen werden häufig verklagt, weil sie die Verbreitung unwahrer Nachrichten auf ihren sozialen Plattformen nicht unter Kontrolle bringen. Dies hat dazu geführt, dass Unternehmen künstliche Intelligenz in Kombination mit Datenwissenschaft einsetzen, um auf diesen Plattformen verbreitete Fake News zu erkennen, damit sie die notwendigen Maßnahmen ergreifen können, um die Geschichten zu entfernen, bevor sie sich verbreiten.
Die andere Seite der Medaille ist, dass KI-Modelle wie GPT-3 natürlich dazu verwendet werden können, die Erstellung von Fake News viel einfacher zu machen. Mit minimaler (aber nicht völliger) menschlicher Aufsicht ist KI heute in der Lage, Nachrichtenartikel zu schreiben. Diesen Monat veröffentlichte der Guardian einen Artikel mit dem Titel „ Ein Roboter hat diesen ganzen Artikel geschrieben. Hast du schon Angst, Mensch?“, der die erstaunliche Leistungsfähigkeit von Deep Learning bei der Erstellung von Inhalten verdeutlichte.

Wie bei allen Technologien gibt es auch bei der Datenwissenschaftsberatung Vor- und Nachteile von KI. Einige der Vorteile sind:
Wie zu erwarten, stehen Data Science-Beratungen jedoch auch vor einigen Herausforderungen. Dies dürfte insbesondere dann der Fall sein, wenn das volle Potenzial der KI bis zum Äußersten ausgeschöpft wird und nicht nur auf die Reproduktion menschlicher Aufgaben beschränkt wird. Beispiele für die Probleme, mit denen das Feld derzeit konfrontiert ist, sind:
Im dritten Jahrzehnt des 21. Jahrhunderts werden KI und Datenwissenschaft immer mehr Einfluss auf unser Leben gewinnen. Viele Dinge, die einst als Science-Fiction galten, stehen bereits kurz davor, zur wissenschaftlichen Realität zu werden. Die Datenwissenschaft lässt einige futuristische Technologien wie selbstfahrende Autos Wirklichkeit werden. Prototypmodelle werden bereits getestet und einige Basisversionen sind heute schon auf der Straße unterwegs.
In der Welt von morgen werden wir voll funktionsfähige Fahrzeuge sehen, die kein Zutun des Fahrers benötigen, um von A nach B zu gelangen. Datenwissenschaft und KI werden zudem zusammenwirken, um noch nützlichere intelligente Geräte zu schaffen, insbesondere im Gesundheitssektor. Schon jetzt gibt es winzige Geräte wie Smartphones, die Gesundheitsparameter wie Blutdruck und Blutzucker überwachen können. Die modernsten Smartwatches verfügen sogar über EKG-Lesegeräte. Innerhalb der nächsten zehn Jahre werden wahrscheinlich noch mehr hochmoderne Geräte entwickelt, die mit einer Fülle von Gesundheitsdaten gespeist werden, um bisher unentdeckte Gesundheitsmuster beim Benutzer aufzudecken und zukünftige Krankheiten und Beschwerden vorherzusagen, sodass Benutzer ihren Lebensstil früher ändern können.
Es ist allgemein bekannt, dass Data Science in unserem Geschäfts- und Privatleben allgegenwärtig sein wird. Doch wie sieht die Zukunft der Beratung aus? Immer mehr große Unternehmen bilden Data-Science-Teams. Wird es also weiterhin Bedarf an Data-Science-Beratern geben?
Ich bin überzeugt, dass es immer einen Bedarf an erfahrenen Data Science-Beratern geben wird, die das Nischenwissen bieten, das einem internen Team fehlt. Oft kann ein externer Berater an einem einzigen Tag erreichen, was das interne Team Wochen gekostet hätte. Data Science-Berater werden also auch weiterhin einen immensen Mehrwert für Unternehmen bieten.
Ich erwarte jedoch eine Kommerzialisierung und Produktisierung von Data-Science-Beratungsleistungen, da sich sowohl Berater als auch Kunden immer besser mit den Möglichkeiten der KI auskennen. Data-Science-Beratungsunternehmen werden sich daher produkt- und ergebnisorientierten Preismodellen zuwenden und das Risiko übernehmen, das bisher ihre Kunden trugen. Branchenstandards für Data-Science-Beratung werden üblicher und Unternehmen werden objektive Bewertungen der Beratungsarbeit vornehmen. KI wird zu einem festen Bestandteil der Unternehmensberatungen werden, auch wenn sie nie ihr Kerngeschäft sein wird.
Der Bereich der Data Science-Beratung wird immer voller werden, und die Beratungsunternehmen werden gezwungen sein, immer spezialisiertere Dienstleistungen anzubieten, um sich von der Masse abzuheben. Zertifizierungen werden für Data Science-Beratungsunternehmen zu einem Muss, und das ist in ihrem besten Interesse, um die Branche vor minderwertiger Arbeit zu schützen. Da viele Länder zu informelleren Arbeitsverhältnissen übergehen, werden immer mehr Data Scientists zu Beratern. Vielleicht werden die großen Managementschulen praktische Data Science in ihre MBA-Programme integrieren.
Wenn Sie mehr über Data Science , Beratung und den damit verbundenen Bereich der künstlichen Intelligenz erfahren möchten, können Sie viele interessante Artikel lesen. Zu den interessantesten und relevantesten gehören der Artikel „ Data Science vs. Machine Learning and Artificial Intelligence “ von The Great Learning Blog und der EDUCBA-Artikel „ Data Science vs. Artificial Intelligence “. Beide geben einen tieferen Einblick in dieses Thema.
[1] Chatterjee, (Data Science vs. maschinelles Lernen und künstliche Intelligenz: Der Unterschied erklärt (2023) )[https://www.mygreatlearning.com/blog/difference-data-science-machine-learning-ai/] (2023)
[2] Kevin Casey, Wie Big Data und KI zusammenarbeiten (2019), The Enterprisers Project
[3] Guardian, Ein Roboter hat diesen ganzen Artikel geschrieben. Hast du schon Angst, Mensch? (2020)
Bereit für den nächsten Schritt in Ihrer NLP-Reise? Vernetzen Sie sich mit Top-Arbeitgebern, die Talente in der natürlichen Sprachverarbeitung suchen. Entdecken Sie Ihren Traumjob!
Finden Sie Ihren Traumjob
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you