
Suchen Sie Experten in Natürlicher Sprachverarbeitung? Veröffentlichen Sie Ihre Stellenangebote bei uns und finden Sie heute Ihren idealen Kandidaten!
Veröffentlichen Sie einen JobKönnen symbolische KI, maschinelles Lernen oder hybride KI (eine Mischung aus beiden) für rechtliche Überlegungen verwendet werden?
Ich habe mich mit dem Problem der rechtlichen Argumentation mit KI befasst. Beim juristischen Denken handelt es sich um den Prozess, eine rechtliche Entscheidung auf der Grundlage von Sachinformationen und Informationen über das Gesetz zu treffen, und es handelt sich um eines der schwierigsten Probleme innerhalb der juristischen KI . Während ML-Modelle und andere praktische Anwendungen der Datenwissenschaft die einfacheren Teile der KI-Strategieberatung sind, ist die rechtliche Argumentation viel schwieriger.
Ein Richter zieht rechtliche Argumente heran, um zu einer logischen Schlussfolgerung zu gelangen, beispielsweise um zu entscheiden, ob ein Angeklagter schuldig ist oder nicht.
Um rechtliche Überlegungen anzustellen, muss ein Richter den Sachverhalt eines Falles, die Frage, die relevanten Rechtsvorschriften und etwaige Präzedenzfälle (in Rechtsordnungen des Common Law) identifizieren.
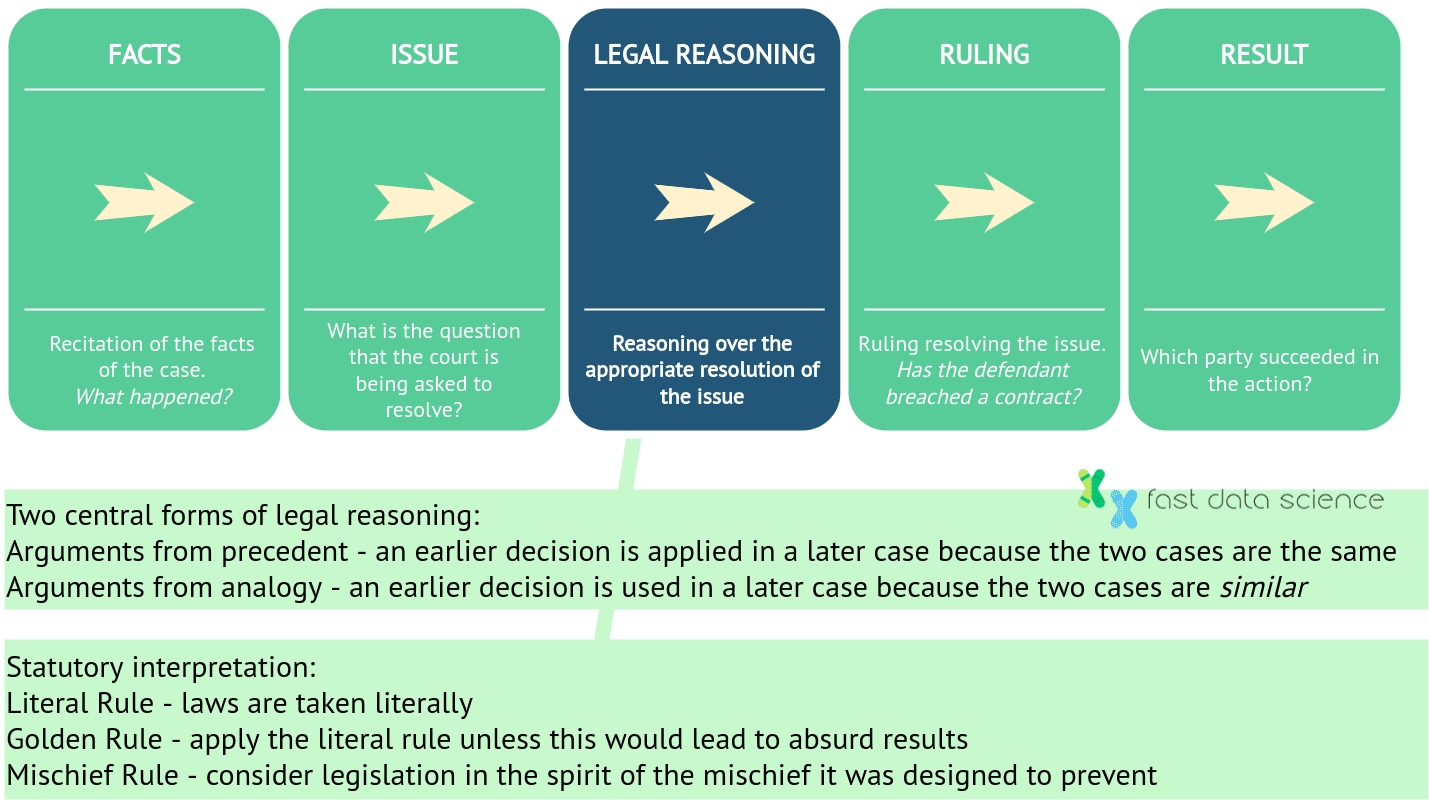
In Common-Law-Systemen wie England und den USA besteht ein Urteil aus fünf Schritten: Zuerst müssen die Sachverhalte des Falles festgestellt werden, das Rechtsproblem oder die Rechtsfrage muss identifiziert werden, und dann wird eine rechtliche Begründung auf den Sachverhalt und die Frage angewendet. Abschließend wird ein Urteil gefällt und das Gericht entscheidet über den Ausgang. Zur rechtlichen Argumentation gehört die Betrachtung früherer Fälle sowie des Gesetzesrechts. Die Frage ist, ob symbolische KI, maschinelles Lernen oder hybride KI (eine Mischung aus beiden) zu rechtlichen Überlegungen fähig sind.
Seit den 1970er Jahren experimentieren KI-Forscher mit symbolischer KI für rechtliche Probleme. Bei der symbolischen KI wurde traditionell eine Darstellung der realen Welt mithilfe einer logischen Programmiersprache wie Lisp oder Prolog in einen Computer codiert.
Logische Programmiersprachen sind Sprachen, die gut darin sind, Konzepte wie „ Eine Katze ist ein Säugetier“ , „Alle Säugetiere produzieren Milch“ und daraus zu schließen, dass eine Katze „Milch“ produziert, gut darzustellen.
Das obige Beispiel kann in Prolog wie folgt ausgedrückt werden:

Ein Beispiel-Logikprogramm in Prolog.
Heutzutage scheint die symbolische KI etwas in Ungnade gefallen zu sein. Ich habe nicht viele Unternehmen gesehen, die symbolische KI für kommerzielle Zwecke nutzen. In der Wissenschaft ist symbolische KI immer noch ein heißes Thema. Datenwissenschaftler in der Industrie verwenden in der Regel Techniken des maschinellen Lernens und der prädiktiven Modellierung, die in Bereichen, in denen große Datenmengen verfügbar sind, leistungsstark sind und datengesteuerte Ansätze wie neuronale Netze das Feld dominieren. Andererseits erfordert symbolische KI oft einen enormen manuellen Aufwand, um die reale Welt in eine Wissensdatenbank zu kodieren, und kann schwierig zu skalieren sein.
Schon vor dem Zweiten Weltkrieg versuchten KI-Forscher, Übersetzungssysteme zu entwickeln, indem sie die gesamte Grammatik zweier Sprachen in einen Computer kodierten und auf das Beste hofften. Daraus entsteht die apokryphe Geschichte über die CIA-Übersetzung von „Der Geist ist bereit, aber das Fleisch ist schwach“ ins Russische und wieder ins Englische, was zu „Der Wodka ist gut, aber das Fleisch ist faul“ führte.
Heutzutage käme niemand mehr auf die Idee, ein computergestütztes Übersetzungssystem mit symbolischer KI aufzubauen. Google Translate basiert hauptsächlich auf statistischen Modellen.
Ich werde einige der Ansätze besprechen, die im Laufe der Jahre zur rechtlichen KI verfolgt wurden. Für einige Aufgaben war die handcodierte symbolische KI in Prolog beliebt, während Forscher dort, wo die Aufgabe einfacher ist und die entsprechenden Daten verfügbar waren, Modelle für maschinelles Lernen trainiert haben. Wenn symbolische KI mit maschinellem Lernen kombiniert wird, spricht man oft von hybrider KI. In den nächsten Abschnitten werde ich einen Überblick über die beiden Ansätze geben.
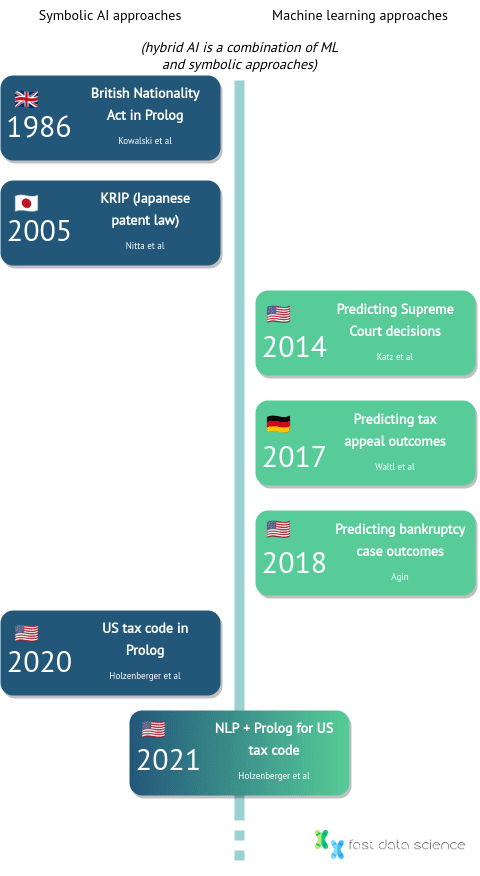
Eine Zeitleiste der Entwicklung einiger wichtiger juristischer KI-Systeme, von Kowalskis British Nationality Act im Jahr 1986 bis heute.
Eine Reihe von Forschern hat die Möglichkeit symbolischer KI im Recht untersucht. Ein von einigen Informatikern verfolgter Ansatz besteht darin, ein Gesetz, beispielsweise ein Parlamentsgesetz, als Logikprogramm darzustellen, die Fakten eines Falles in dieselbe logische Darstellung umzuwandeln und rechtliche Überlegungen als Abfrage in dieser Logiksprache durchzuführen.
Dies scheint mir einfacher zu sein, als zu versuchen, die Rechtsprechung zu modellieren und Argumente aus Präzedenzfällen oder Analogien rechnerisch zu simulieren. KI-basierte rechtliche Überlegungen mögen für das kontinentale Recht einfacher sein als für das englische und amerikanische Recht, da die kontinentalen Rechtssysteme auf Gesetzen basieren, aber ich bräuchte einen Rechtsexperten, um dies zu bestätigen.
Einer der bahnbrechenden Versuche , gesetzliche Argumentation anzuwenden, ist die Modellierung des britischen Staatsangehörigkeitsgesetzes als Logikprogramm durch den amerikanisch-britischen Logiker Robert Kowalski und andere, die 1986 veröffentlicht wurde. Das Team entschied sich für die Konzentration auf Gesetzesrecht, weil Gesetzesrecht „ist“ „definitiver Natur“ und lässt sich leichter in die Logik übersetzen. Sie entschieden sich insbesondere für den British Nationality Act von 1981 , weil dieser als präzise Reihe von Regeln angelegt war und relativ in sich geschlossen war – obwohl er einige vage Formulierungen enthielt, wie zum Beispiel „einen guten Charakter haben“ , „eine vernünftige Entschuldigung haben “ und „über ausreichende Kenntnisse verfügen“. auf Englisch .
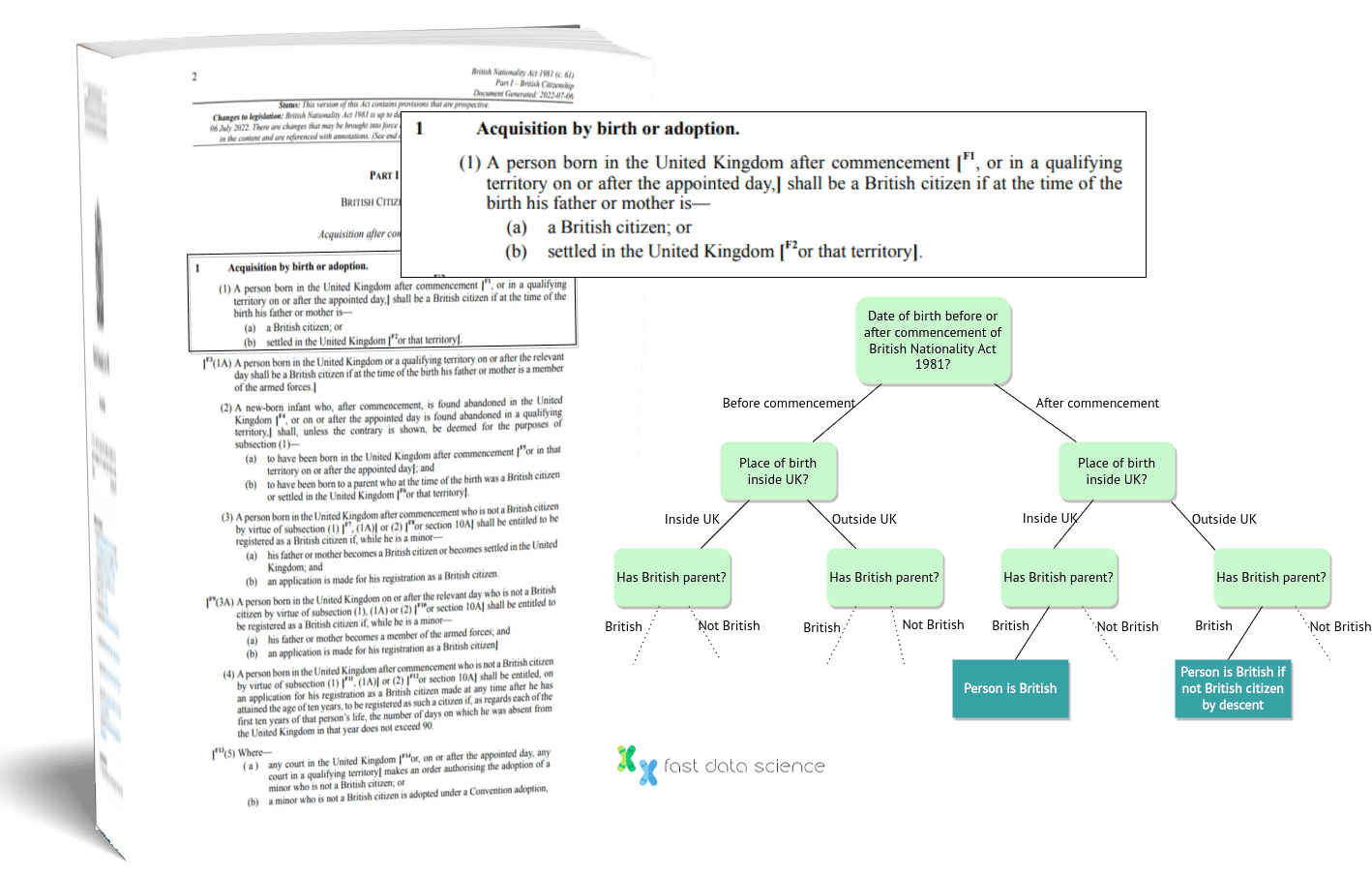
Schematische Ansicht eines Teils von Robert Kowalskis logischer Darstellung des britischen Staatsangehörigkeitsgesetzes.
Obwohl Kowalskis Darstellung des britischen Staatsangehörigkeitsgesetzes bahnbrechend war, sollte es sich nicht um ein voll funktionsfähiges System handeln, und seine Grenzen liegen auf der Hand.
Im Jahr 2005 entwickelte Katsumi Nitta ein System namens KRIP , ein Expertensystem für japanisches Patentrecht. Er nutzte symbolische KI (Prädikatenlogik), um einen begrenzten Rechtsabschnitt für einen engen Bereich (Patentrecht) zu kodifizieren, dessen Regeln sich relativ einfach in eine Wissensdatenbank einfügen lassen.
Im Jahr 2021 kodierte Nils Holzenberger von der Johns Hopkins University zusammen mit einer größeren Forschungsgruppe einen Abschnitt des US-Steuergesetzes in Prolog . Sie haben ein System erstellt, in dem der Benutzer Fragen stellen kann, z. B .: Wenn Mary 2018 geheiratet hat und letztes Jahr 40.000 US-Dollar verdient hat, wie viel Steuern sollte sie zahlen ?
Das Steuerrecht ist ein interessanter Fall, da die meisten Probleme eine einfache, eindeutige Antwort haben ( wie viel Steuer muss gezahlt werden? ) und die Regeln größtenteils gesetzlich festgelegt sind (obwohl Anwälte über die Bedeutung von Wörtern streiten können).
Das Team ging das Problem zunächst an, indem es Statuten und den Sachverhalt eines Falles manuell in eine logische Darstellung in Prolog übersetzte. Sie können den Schieberegler unten verschieben, um zu sehen, wie ein Absatz des Steuergesetzes aussieht, nachdem er in Prolog übersetzt wurde:

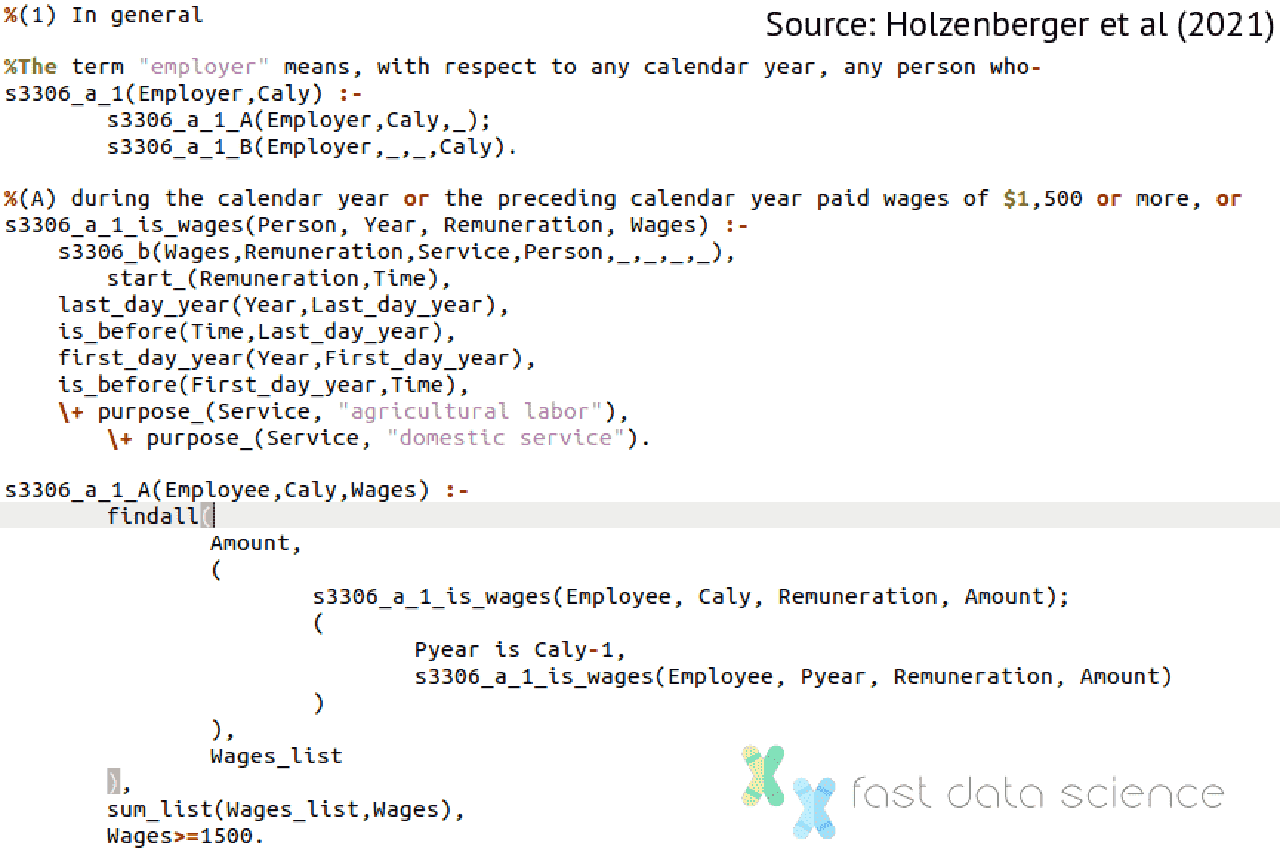
Da der Prolog-Code in diesem Fall manuell generiert wurde, hatte das Modell per Definition eine 100-prozentige Genauigkeit – vorausgesetzt natürlich, dass der Prolog-Code keine Fehler enthält.
Das Problem besteht jedoch darin, dass juristische Texte nicht in Prolog-Form vorliegen und es schwierig ist, alles in Prolog zu übersetzen.
Anschließend experimentierte das Team mit NLP- Tools wie Transformern , um Gesetze und Fakten zu analysieren und die geschuldete Steuer als Regressionsproblem unter Umgehung der Prolog-Darstellung vorherzusagen.
Holzenbergers Team versuchte dann, das Problem in mehrere Schritte des Sprachverständnisses zu zerlegen, gefolgt von einer Lückenfüllphase, in der Variablen (wie Gehalt, Ehepartner, Wohnort) mit Informationen für den konkreten Fall gefüllt werden. Dies schnitt etwas besser ab als der vorherige Ansatz. Sie stellten jedoch fest, dass es sehr schwierig war, die Struktur eines Satzes zu analysieren, da der Wortlaut so variabel sein kann.
Andere Forscher wenden sich von der Logikprogrammierung ab und nutzen in der Rechtswissenschaft Ansätze des maschinellen Lernens. Im Jahr 2014 trainierten Daniel Katz und sein Team von der Illinois Tech ein maschinelles Lernmodell , um die Entscheidungen von Richtern des Obersten Gerichtshofs vorherzusagen.
In Deutschland trainierten Bernhard Waltl und andere Forscher der Technischen Universität München 2017 einen maschinellen Lernklassifikator für 5990 Steuerbeschwerden, um anhand von 11 Merkmalen das Ergebnis einer neuen Steuerbeschwerde vorherzusagen.
Im Jahr 2018 trainierte Warren Agin ein maschinelles Lernmodell, um Erfolg oder Misserfolg in Insolvenzfällen nach Kapitel 13 vorherzusagen. Dabei nutzte er Merkmale wie die Bezirkserfolgsquote (die Insolvenzerfolgsquote nach Standort), die gesamten ungesicherten nicht vorrangigen Schulden, die Einkommens-/Ausgabenlücke, und andere, die in der Lage waren, den Ausgang eines Insolvenzantrags mit einer Genauigkeit von 70 % und einem AUC von 71 % vorherzusagen.
Ich glaube, dass maschinelles Lernen im juristischen Bereich funktionieren kann, wo es viele analoge Fälle gibt, wie etwa Steuerurteile, Insolvenzanträge und familienrechtliche Ergebnisse. Allerdings wären allgemeinere juristische Arbeiten, die eine komplexe Analyse von Gesetzen und Präzedenzfällen erfordern können, mit maschinellem Lernen nur sehr schwer zu lösen.
Obwohl das US-Steuerrecht unglaublich komplex ist, ist es immer noch eine Frage der Gesetzesauslegung und kann mit genügend Geduld in Prolog kodiert werden.
Was können wir tun, wenn wir ein rechtliches Problem haben, das sowohl Gesetze als auch Präzedenzfälle betrifft, wie es in Rechtsordnungen des Common Law wie England und den USA üblich ist?
Im englischen Recht gibt es eine Reihe von Grundsätzen, die Richter zur Auslegung von Gesetzen heranziehen können. Es gibt eine wörtliche Regel , die besagt, dass Gesetze wörtlich im üblichen Wortsinn ausgelegt werden müssen. Auch Richter haben die Goldene Regel , die besagt, dass der Wortlaut von Gesetzen wörtlich ausgelegt werden sollte, es sei denn, dies würde zu absurden Implikationen führen. Schließlich gibt es noch die Unfug-Regel , die besagt, dass ein Richter berücksichtigen soll, welchen Unfug ein Gesetz verhindern soll. Diese wurden zu verschiedenen Zeitpunkten in der Geschichte entwickelt und führten zu dem angemessenen Maß an Ermessensspielraum, über den Richter heute verfügen.
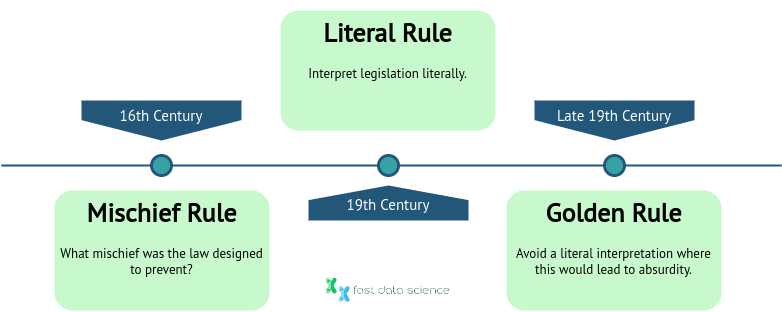
Zeitleiste der Entwicklung der drei Hauptregeln der Gesetzesauslegung: Im 16. Jahrhundert gab die ursprüngliche Unfug-Regel den Richtern ein gewisses Maß an Freiheit, und im viktorianischen Zeitalter ging der Trend in Richtung einer wörtlichen Auslegung des Gesetzes, und schließlich sind wir umgezogen zurück zu einer vernünftigen Interpretation des Zwecks eines Gesetzes mit der goldenen Regel.
Ein Beispiel für die Anwendung der Unfug-Regel ist Corkery gegen Carpenter (1951), wo der Angeklagte betrunken Fahrrad fuhr und aufgrund eines Gesetzes aus der viktorianischen Zeit ( Licensing Act 1872 ) verhaftet wurde, in dem von „Kutschen“ die Rede war. Der Richter entschied, dass der fragliche Unfug derselbe sei, unabhängig davon, ob eine Person Fahrrad oder eine Pferdekutsche fahre.

Der einleitende Absatz des Urteils R gegen Bentham (2005), in dem der Sachverhalt dargelegt wird.
Ein interessanter Fall, in dem AI aufgrund unterschiedlicher Gesetzesauslegungen Schwierigkeiten haben könnte, ist R gegen Bentham , ein Berufungsverfahren, das 2005 beim House of Lords in England eingereicht wurde.
Der Angeklagte Peter Bentham beging einen Raubüberfall und versteckte seinen ausgestreckten Finger unter den Falten seiner Jacke, um absichtlich den Eindruck zu erwecken, er hätte eine Waffe. Sein Opfer, das glaubte, eine Waffe zu haben, übergab ihm Wertsachen.
Vor dem Berufungsgericht wurde Bentham auf der Grundlage des Feuerwaffengesetzes von 1968 verurteilt, das „Nachahmungen von Schusswaffen“ vorsieht.

Kann ein Finger als nachgeahmte Schusswaffe betrachtet werden?
Bentham legte später Berufung ein, und der Fall ging an das House of Lords, das seiner Berufung stattgab, da nach Ansicht der Richter ein menschlicher Finger nicht als nachgeahmte Schusswaffe angesehen werden kann, da er ein Teil des Körpers ist.
Das untere Gericht (das Berufungsgericht) wandte die Unfug-Regel an, aber das House of Lords legte das Feuerwaffengesetz wörtlicher aus und hob die Verurteilung aus Formsache auf.
Angesichts der enormen Fortschritte bei Transformatoren in den letzten Jahren war mein erster Instinkt, dass ein Transformatormodell wie BERT oder GPT-2 in der Lage sein sollte, Fragen zu diesem Fall zu beantworten.
Ich habe versucht, die Fakten des Falles in BERT aufzunehmen und Fragen zu stellen wie: Wer ist der Beschwerdeführer? , was wird dem Beschwerdeführer vorgeworfen? , und wann geschah das Verbrechen ? Obwohl BERT manchmal in der Lage war, die Antworten im Text zu lokalisieren und Teilzeichenfolgen des Textes zu lokalisieren, ist dies weit davon entfernt, tatsächlich Informationen zu verstehen und abzurufen. Im Wesentlichen stellte ich fest, dass es sich um ein sehr ausgefeiltes Informationsabrufsystem handelte, das jedoch nicht annähernd die Komplexität erreichte, die zur Modellierung der realen Welt erforderlich ist.
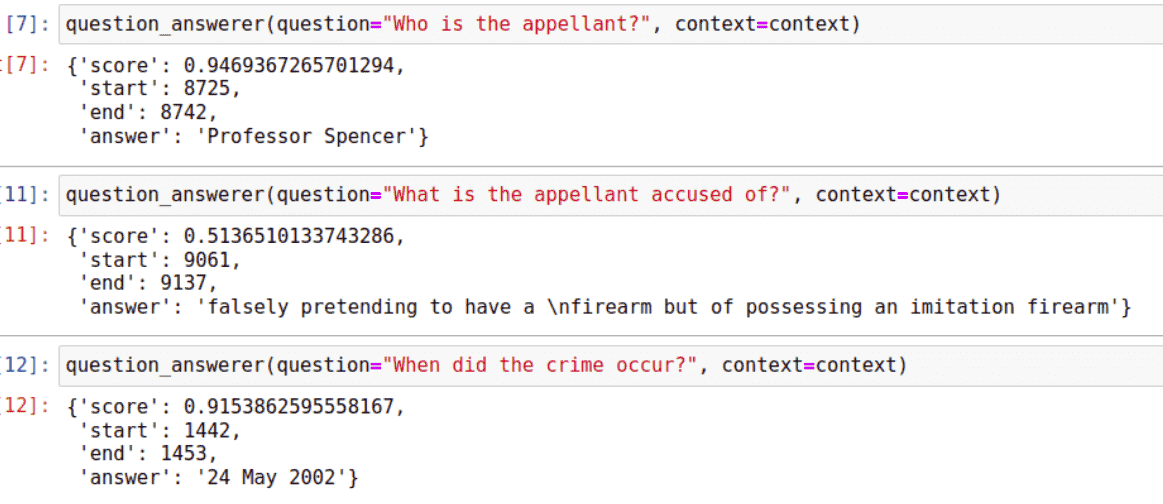
Wie BERT auf Fragen zu R gegen Bentham antwortete
Es gibt eine Reihe von Möglichkeiten, reale Ereignisse und ihre Auswirkungen in logischen Sprachen wie Prolog darzustellen, beispielsweise den Ereigniskalkül , eine logische Methode zur Darstellung von Ereignissen und ihren Auswirkungen, die 1986 von Robert Kowalski und Marek Sergot entwickelt wurde.
Ich habe eine relativ einfache Methode zur Modellierung natürlichsprachlicher Texte gewählt, bei der alle Verben oder Präpositionen in einen Prolog-Ausdruck der Form übersetzt werden:
„ Aktion (Subjekt, Objekt, Zeit) „
Die Urteile , dass der Angeklagte am 9. Juli 2001 in das Haus eingebrochen war oder dass der Angeklagte am 9. Juli 2001 in das Haus eingebrochen war, würden also beide lauten:
„ Einbruch (Beklagter, Haus, Datum_20010709) „
Wenn alle Informationen in einem Text in dieses Format übersetzt werden, ist die Abfrage einfacher, obwohl es einige Mängel aufweist, wie z. B. die Darstellung von Unterabschnitten.
Auf diese Weise kann eine Abfolge von Ereignissen in eine Reihe unabhängiger Prädikate zerlegt werden. Der große Vorteil von Prolog besteht darin, dass es fehlertolerant ist und Fehler in einer Zeile normalerweise ignoriert und mit der nächsten Zeile fortfährt.
Urteile des House of Lords können im PDF-Format vom Webportal des britischen Parlaments heruntergeladen werden.
Ich habe eine einfache Weboberfläche entwickelt, die ein PDF eines Urteils verarbeiten, den Sachverhalt ermitteln und die relevanten gesetzlichen Begründungen anwenden kann – in einem sehr engen Rahmen.
Der Prozess funktioniert wie folgt:
Um das rechtliche Argumentationsmodell von Prolog in R gegen Bentham zu testen, habe ich die relevanten Abschnitte des Firearms Act 1968 manuell in Prolog übersetzt. Im entsprechenden Abschnitt des Schusswaffengesetzes heißt es lediglich, dass eine Person schuldig ist, wenn sie eine Straftat wie einen Raub begeht und im Besitz einer Schusswaffe oder einer Schusswaffenimitation ist. Es wird jedoch nicht ausdrücklich angegeben, ob ein Finger als Schusswaffenimitation gelten könnte.
Ich habe eine Option in meinen Prolog-Code aufgenommen, um die Unfug-Regel anzuwenden oder zu ignorieren, was eine strenge oder lockere Auslegung des Gesetzes ermöglicht.
Ich habe den Prolog-Kodex für die Gesetzgebung und den Prolog-Kodex, der den Sachverhalt im Fall R gegen Bentham beschreibt, zusammengefügt und konnte nachfragen, ob jemand nach dem Firearms Act 1968 schuldig war.
Durch die Möglichkeit, die Unfug-Regel ein- und auszuschalten, kann ein Benutzer beide Interpretationen eines Urteils sehen.
Mit dieser Flexibilität konnte mein Prolog-Code die Urteile sowohl des ursprünglichen Berufungsgerichts, das Bentham verurteilt hatte, als auch des House of Lords, das ihn freisprach, reproduzieren.
Im folgenden Video können Sie sehen, wie der Prolog-Code schnell aus den Rohdaten des Falles generiert werden kann und wie rechtliche Überlegungen auf dem Prolog durchgeführt werden können:
Die Umwandlung des Sachverhalts eines Falles und relevanter Rechtsvorschriften in Prolog ist ein interessantes Problem, da es sich dabei um eine Interpretation realer Ereignisse handelt, die in Prolog einbezogen werden müssen. Damit eine KI erkennen kann, dass ein menschlicher Finger keine nachgeahmte Schusswaffe ist, weil er Teil des Körpers ist, muss eine große Menge an realem Wissen in diese KI kodiert werden, und ich glaube nicht, dass es sich um statistische KI oder maschinelles Lernen handelt ist zu diesem Verständnisniveau fähig.
Was für eine KI auch äußerst schwierig wäre, wäre die Anwendung von Präzedenzfällen. Eine KI bräuchte reales Wissen, um zu entscheiden, dass ein bestimmter Schusswaffenfall einem anderen Fall analog oder ähnlich genug ist.
Meine kurzen Experimente mit Prolog zeigen, dass es möglich ist, mit symbolischer KI im Rechtswesen einige begrenzte Ergebnisse in einem begrenzten Bereich zu erzielen. Die Kombination eines statistisch basierten Modells wie eines Parsers für natürliche Sprache mit einer symbolischen KI in Form eines hybriden KI-Systems ist sehr leistungsfähig, weist jedoch viele Einschränkungen auf und ist noch lange nicht in der Lage, die Aufgabe zu erfüllen eines Anwalts oder eines Richters.
Der Grund für die Entscheidung der Lords im Fall R gegen Bentham hing von der Bedeutung des Wortes „ besitzen“ ab – in Anlehnung an einen Grundsatz des römischen Rechts, dass eine Person keinen Teil ihres Körpers besitzen darf. Leider lässt sich dies mit KI nur sehr schwer modellieren, da Richter und Anwälte über Kenntnisse dieser gemeinsamen Grundsätze verfügen, die nicht immer gesetzlich verankert sind.
Es ist möglich, dass wir den notwendigen Grad an Verständnis erst erreichen, wenn künstliche allgemeine Intelligenz (AGI) Realität wird. Auch wenn AGI weiterhin Science-Fiction ist, glaube ich nicht, dass juristische KI wichtige Entscheidungen treffen wird, obwohl sie derzeit hauptsächlich zur Unterstützung von Anwälten im Bereich der Informationsbeschaffung eingesetzt wird.
Mir hat dieser hervorragende Vortrag von Nils Holzenberger zum Thema NLP und Steuerrecht in den USA gefallen:
Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdecken
Mittlerweile sind es Organisationen aller Größenordnungen und fast aller Sektoren werden zunehmend datengesteuert, insbesondere als größere Datenspeicher Systeme und schnellere Computer treiben die Leistungsgrenzen immer weiter voran.

Aufgrund des umfangreichen Einsatzes von Technologie und der Arbeitsteilung hat die Arbeit des durchschnittlichen Gig-Economy-Arbeiters jeden individuellen Charakter und damit auch jeden Charme für den Arbeitnehmer verloren.
Die Auswirkungen von KI auf die Humanressourcen Die Arbeitswelt verändert sich rasant, sowohl aufgrund der Einführung traditioneller Data-Science-Praktiken in immer mehr Unternehmen als auch aufgrund der zunehmenden Beliebtheit generativer KI-Tools wie ChatGPT und Googles BARD bei nicht-technischen Arbeitnehmern.
What we can do for you