Ich habe eine kleine Auswahl einiger Data-Science-Konzepte für Fortgeschrittene zusammengestellt, die Ihnen eine gute Grundlage in diesem Bereich bieten. Viele davon basieren auf einer Reihe von Artikeln, die ich für die hervorragende Data-Science-Ressource deepai.org geschrieben habe. Ich habe die Liste der Data-Science-Konzepte etwas auf die Verarbeitung natürlicher Sprache ausgerichtet, da dies der Bereich ist, in dem ich hauptsächlich arbeite.
Eine Aktivierungsfunktion wird in neuronalen Netzwerken verwendet und fungiert als „Torwächter“. Sie lässt große Signale durch, blockiert jedoch kleine Signale.
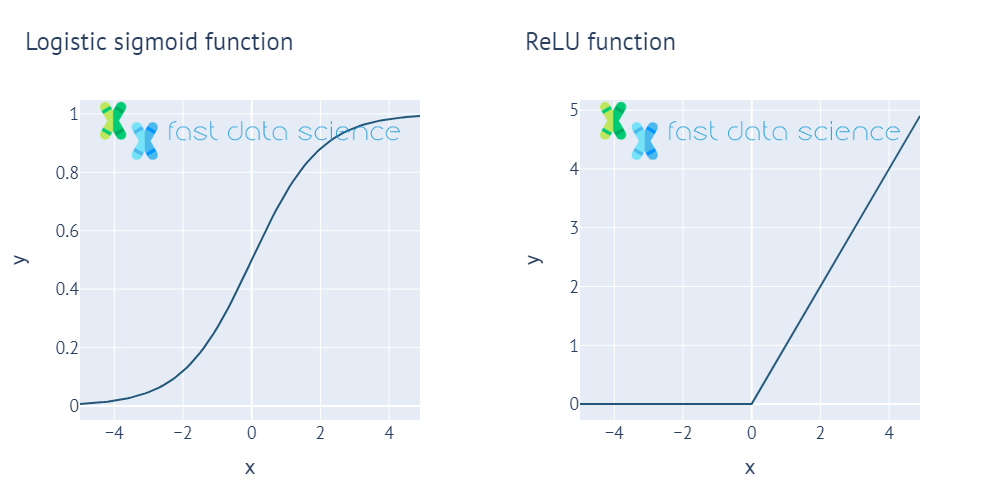
Zwei der häufigsten Aktivierungsfunktionen, die logistische Sigmoidfunktion und die ReLU-Funktion. Alle Aktivierungsfunktionen geben einen kleinen Wert für kleine x und einen großen Wert für große x aus und sind nicht linear.
Die Aktivierungsfunktionen wurden durch das Aktionspotential inspiriert, das in biologischen neuronalen Netzwerken eine Blockierungsfunktion darstellt.

Zwei britische Wissenschaftler, Hodgkin und Huxley, entdeckten Aktionspotentiale bei Lebewesen, indem sie die Nerven eines Tintenfischs sezierten. Dies diente später als Inspiration für die Aktivierungspotentiale, die in neuronalen Netzwerken verwendet werden.
Ohne Aktivierungsfunktionen wären neuronale Netze nicht in der Lage, Objekte und Gesichter zu erkennen. Tatsächlich wären sie nicht besser als ein einfaches Regressionsmodell wie die Regressionsgerade in Excel.
Eine häufig gewählte Aktivierungsfunktion ist die Sigmoid-Funktion .
Backpropagation ist eine Technik zur effizienten Berechnung von Gewichten in tiefen neuronalen Netzwerken. Dabei wird die Verlustfunktion am Ende des Netzwerks berechnet und dann zurück zum Anfang des Netzwerks gegangen, um die Netzwerkgewichte zu aktualisieren.
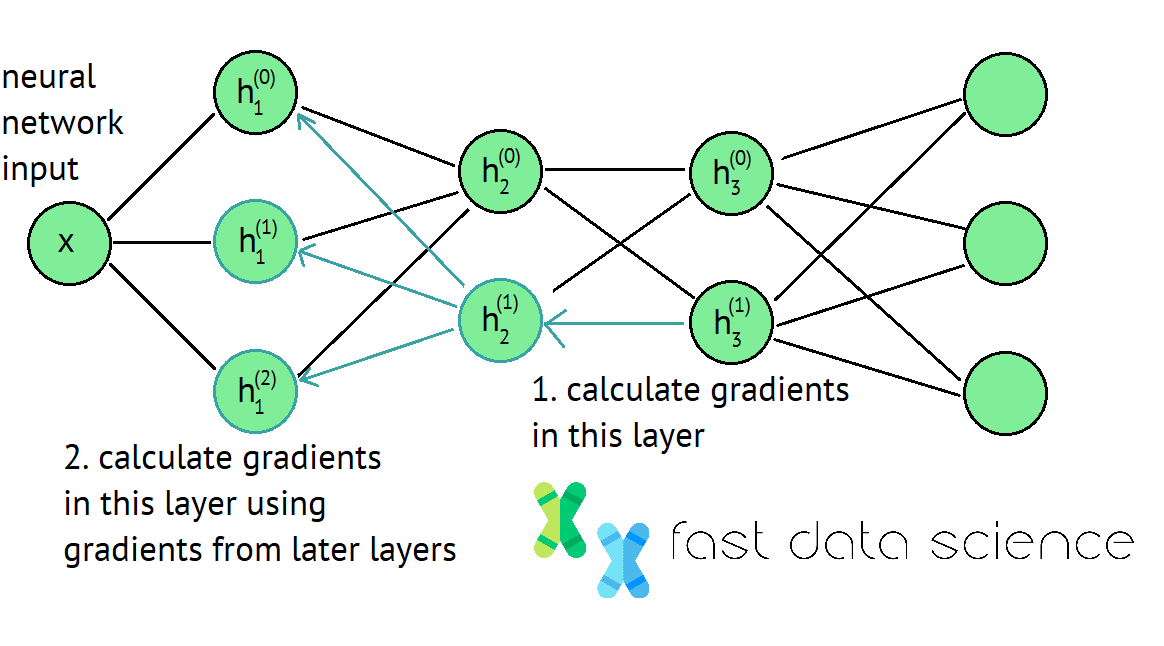
Der Backpropagation-Algorithmus ist der Schlüssel zu Deep Learning und Data Science. Dabei arbeitet man sich rückwärts durch ein neuronales Netzwerk von seinem Ende bis zu seinem Anfang und berechnet an jedem Punkt, wie die Gewichte aktualisiert werden müssen. Weitere Einzelheiten finden Sie hier .
Convolutional Neural Networks sind eine spezielle Art von tiefen neuronalen Netzwerken, die hauptsächlich zur Bilderkennung eingesetzt werden. Sie haben eine starre Struktur, die es ihnen ermöglicht, Muster innerhalb eines Bildes sowie Kombinationen von Mustern zu erkennen.
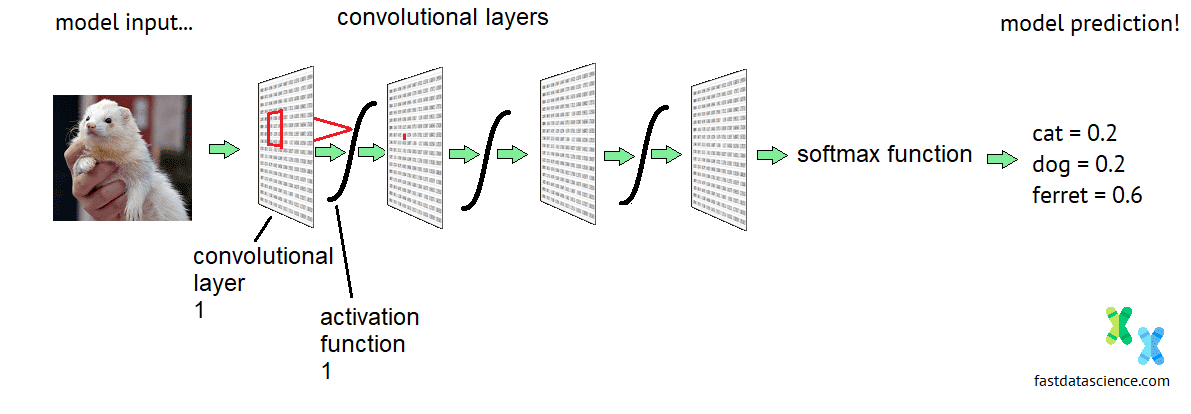
Schematische Darstellung der Architektur eines Convolutional Neural Network. Normalerweise haben Netzwerke, die Fotos oder Gesichter verarbeiten, mindestens 20 Schichten.
Interessanterweise sind Faltungsneuronale Netze nicht nur für Bilder nützlich. Sie können auch für Tonsignale umfunktioniert werden (Sie können jede Tonaufnahme nehmen und sie in ein Spektrogramm umwandeln, und dann verhält sie sich wie ein Bild). Sie können auch ein Dokument in Englisch oder einer anderen Sprache nehmen und es in eine bildähnliche Form umwandeln, indem Sie jedes Wort durch sein Wortvektor-Embedding ersetzen.
Deep Learning ist eine Art maschinelles Lernverfahren, bei dem viele einfachere Modelle des maschinellen Lernens übereinander gelegt und mit einer Aktivierungsfunktion zusammengefügt werden. Der Aufstieg des Deep Learning hat einen Großteil der fortgeschrittenen KI ermöglicht, die wir heute sehen, von der maschinellen Übersetzung bis hin zu Snapchat-Filtern.
Convolutional Neural Networks , wie oben beschrieben, sind eine Art Deep-Learning-Modell.
Traditionelle Modelle des maschinellen Lernens beinhalten eine viel geringere Anzahl von Parametern und führen oft nur ein paar einfache Operationen mit einigen eingehenden Zahlen aus. Beim Deep Learning hingegen wird eine Zahl eingegeben (z. B. ein Pixel oder ein Fragment eines Audiosignals) und durchläuft viele Schichten mathematischer Operationen, bevor das Modell seine Ausgabe erzeugt:
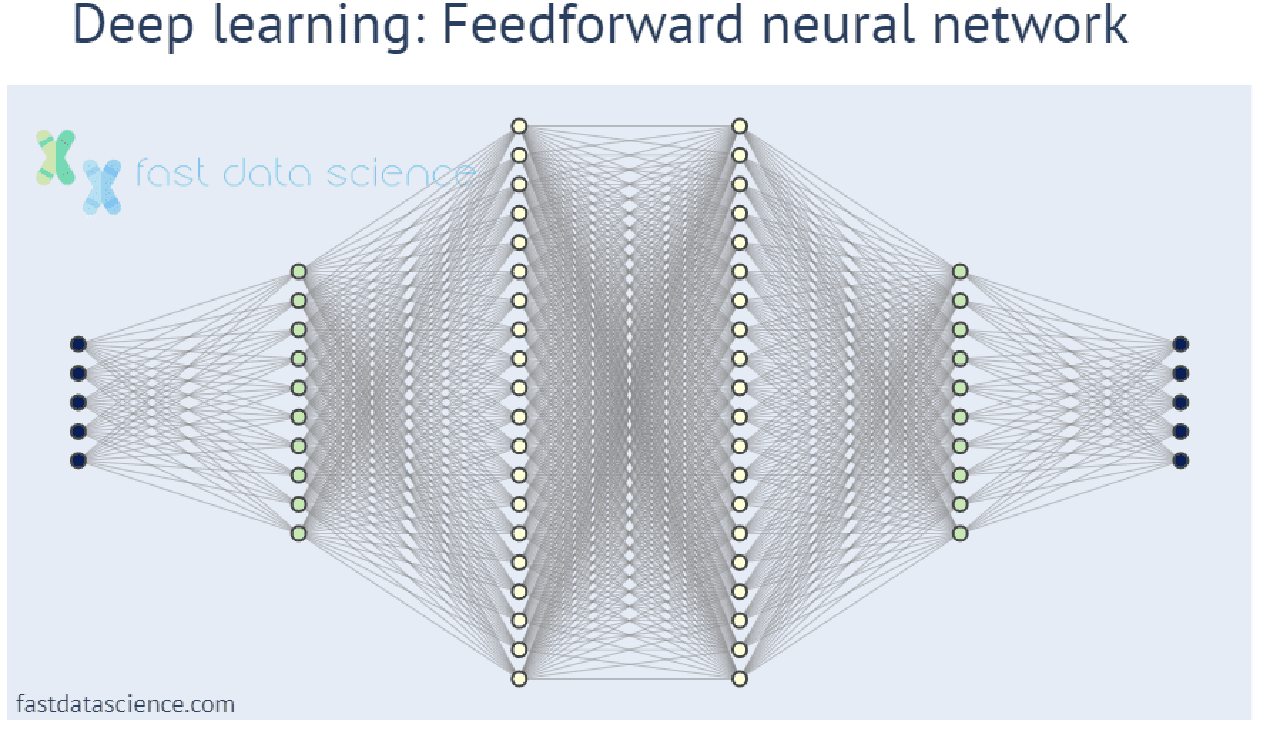

Leider werden Deep-Learning-Modelle immer komplexer und für den Menschen immer schwerer zu verstehen, sodass ein Bedarf an erklärbarer KI und erklärbaren Modellen des maschinellen Lernens entsteht.
Ein Evolutionsalgorithmus ist eine Möglichkeit zur Verbesserung einer KI mithilfe von Methoden, die von der biologischen Evolution inspiriert sind, insbesondere von zufälligen Mutationen und natürlicher Selektion.
Wenn Sie ein maschinelles Lernmodell trainieren, kann es verlockend sein, seine Leistung anhand der Genauigkeit zu messen. Wenn beispielsweise ein Modell zur Erkennung des Vorhandenseins/Fehlens von Tumoren eine Genauigkeit von 90 % erreicht, ist das gut, oder? Aber was, wenn 90 % Ihrer Patienten keinen Tumor haben und das Modell für 100 % Ihrer Patienten „kein Tumor“ vorhersagt? Das Modell ist dann völlig nutzlos, würde aber trotzdem 90 % erreichen! Aus diesem Grund verwenden wir den F-Score , ein robusteres Maß und zentrales datenwissenschaftliches Konzept, das mit unausgewogenen Klassen umgehen kann.
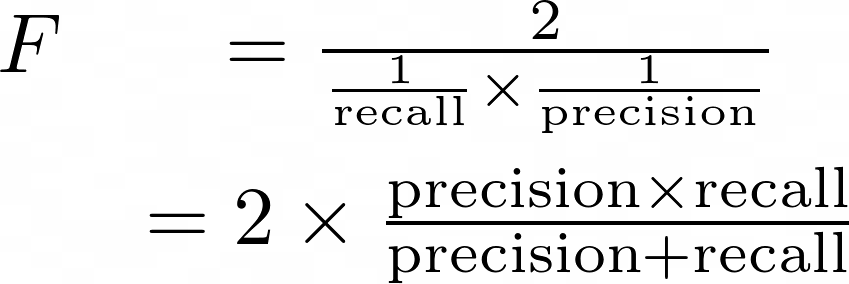
Definition des F-Scores in Bezug auf Präzision und Rückruf
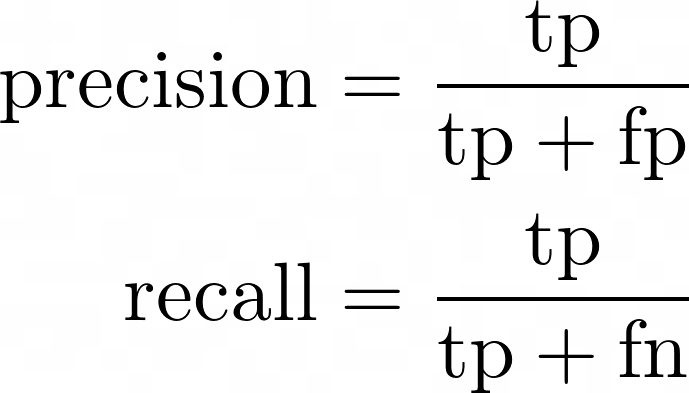
Definition von Präzision und Rückruf in Bezug auf True Positives (tp), False Positives (fp) und False Negatives (fn)
Wenn Sie tatsächlich von jemandem dazu gebracht werden, in ein Data Science-Modell zu investieren, und Ihnen nur eine Zahl wie „90 % Genauigkeit“ genannt wird, sollten Sie sehr misstrauisch sein! Es könnte sich durchaus um ein Problem mit Datenungleichgewichten handeln, bei denen eine Genauigkeit von 90 % sehr leicht zu erreichen ist. Der F-Score ist gegenüber solchen Effekten robuster.

Ein synthetisches Gesicht, das von einem generativen kontradiktorischen Netzwerk erzeugt wurde
Generative Adversarial Networks sind ein cleveres Design neuronaler Netzwerke, bei dem wir zwei neuronale Netzwerke zusammenbringen und sie gegeneinander antreten lassen (daher das „Adversarial“ im Namen). Einem Netzwerk wird die Aufgabe zugewiesen, Dinge zu generieren (z. B. Gesichtsbilder), und die Aufgabe des anderen Netzwerks besteht darin, das Generierte vom Original zu unterscheiden (es muss also lernen, falsche Gesichter von echten Gesichtern zu unterscheiden). Mit der Zeit erhalten wir durch diese konfrontative Konfiguration einen sehr ausgefeilten Generator, der lebensechte Gesichtsbilder, Musik, Kunstwerke, Videos und sogar Texte erstellen kann.
Bei der Hyperparameteroptimierung geht es darum, die besten Hyperparameter oder Lernparameter für einen maschinellen Lernalgorithmus auszuwählen. Wenn Sie beispielsweise einen Gesichtserkenner mit einem neuronalen Netzwerk erstellen, möchten Sie möglicherweise mit unterschiedlichen Lernraten, Schichtenzahlen, Lernalgorithmen, Bildabmessungen usw. experimentieren. Da jedes Training eines Modells Monate dauern kann, ist es nicht praktikabel, mit jeder möglichen Kombination von Hyperparametern zu experimentieren. Daher werden häufig clevere Algorithmen verwendet, die schnell zu den besten Werten konvergieren.
Wenn wir einen Entscheidungsbaum trainieren, ist der Informationsgewinn die Entropiereduzierung oder Überraschungswirkung, die wir durch die Aufteilung unseres Datensatzes auf einen bestimmten Wert einer Variablen erzielen.
Wenn wir beispielsweise entscheiden möchten, ob wir einem Entscheidungsbaum mit einem Schwellenalter > 50 einen Zweig hinzufügen, würden wir herausfinden, ob dieser Grenzwert zu zwei Datensätzen führt, die jeweils homogener sind als der ursprüngliche Datensatz. Die Änderung der Entropie entspricht dem Informationsgewinn.
Der Jaccard Similarity Index ist eine Zahl, die angibt, wie ähnlich sich zwei Dokumente sind. Es kann sich um einen Prozentsatz oder eine Zahl zwischen 0 und 1 handeln.
Stellen Sie sich vor, Sie möchten herausfinden, wie ähnlich diese beiden Sätze sind:
Dokument A: „Data Science zu lernen ist einfach “
Dokument B: „Es ist einfach, Datenwissenschaftler zu werden“
Ich habe die Wörter fett markiert, die in beiden Sätzen vorkommen.
Unabhängig davon, ob wir den Aussagen zustimmen, können wir die Formel des Jaccard Similarity Index verwenden, um zu berechnen, wie ähnlich Dokument A Dokument B ist:
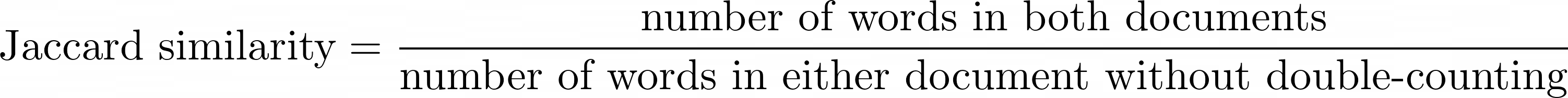
Mathematische Definition des Jaccard Similarity Index
Unsere beiden Sätze haben also zwei gemeinsame Wörter und insgesamt zehn Wörter. Wir können die Berechnung in einem Venn-Diagramm visualisieren:
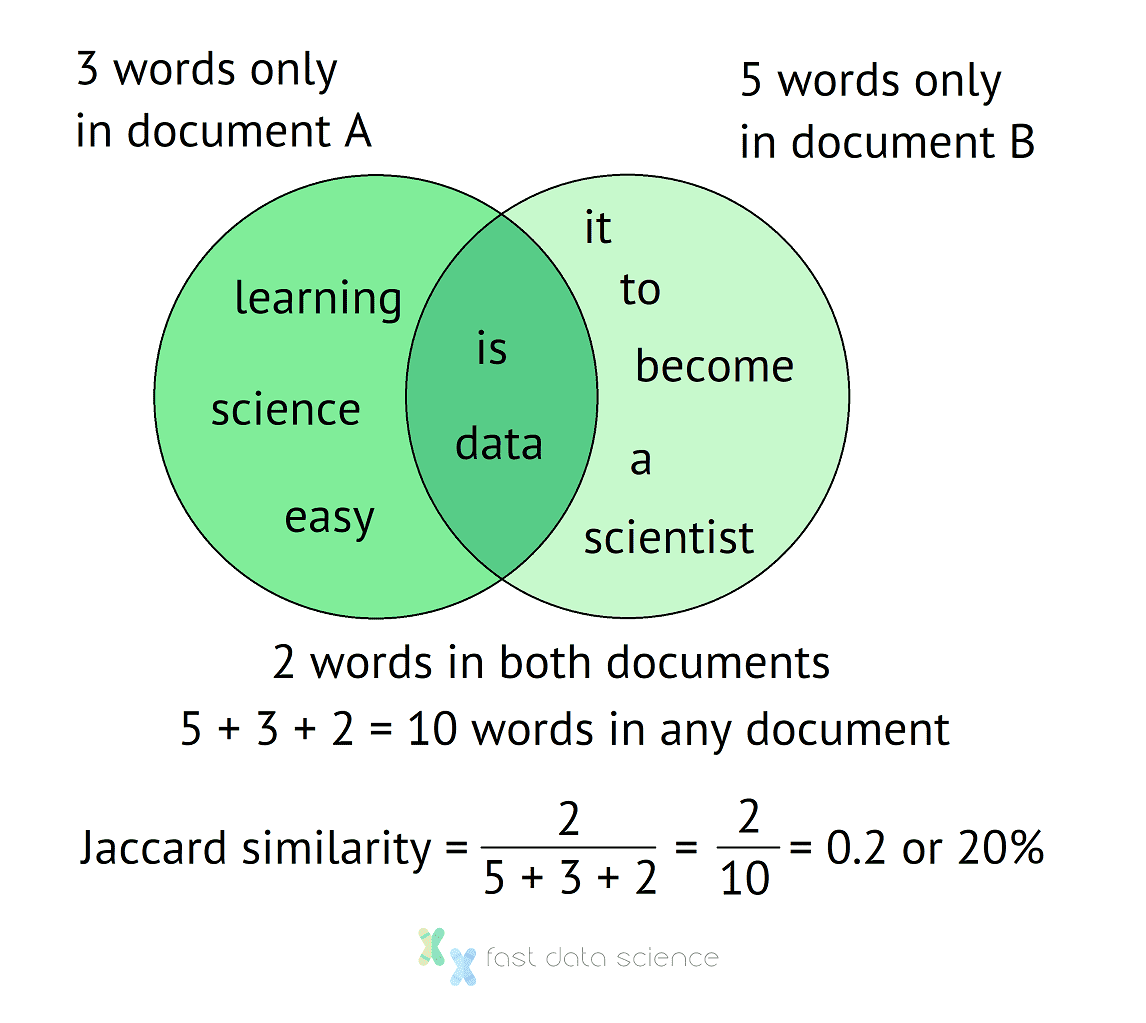
Venn-Diagramm zur Berechnung des Jaccard-Ähnlichkeitsindex für zwei Sätze. Die Sätze haben insgesamt 10 Wörter, ohne doppelt gezählt zu werden, und zwei Wörter kommen in beiden Dokumenten vor, was einen Jaccard-Ähnlichkeitsindex von 20 % ergibt.
Aus dem Venn-Diagramm lässt sich leicht erkennen, dass die beiden Dokumente eine Jaccard-Ähnlichkeit von 20 % aufweisen, d. h., sie sind einander zu 20 % ähnlich. Wenn die Dokumente keine gemeinsamen Wörter hätten, wäre die Ähnlichkeit gleich 0.
Da es fraglich ist, ob „science“ und „scientist“ eine gewisse Ähnlichkeit aufweisen, können wir den Jaccard-Index manchmal auf Unterwortebene verwenden. Wir könnten beispielsweise Sequenzen aus drei Buchstaben nehmen, die Trigramme genannt werden: „sci“, „cie“, „ien“, „ent“, „nti“, „tis“, „ist“ – mit diesem Maß haben „science“ und „scientist“ eine Ähnlichkeit von 33 %.
Es gibt eine Reihe von Alternativen zum Jaccard-Index, beispielsweise den Cosine Similarity Index .
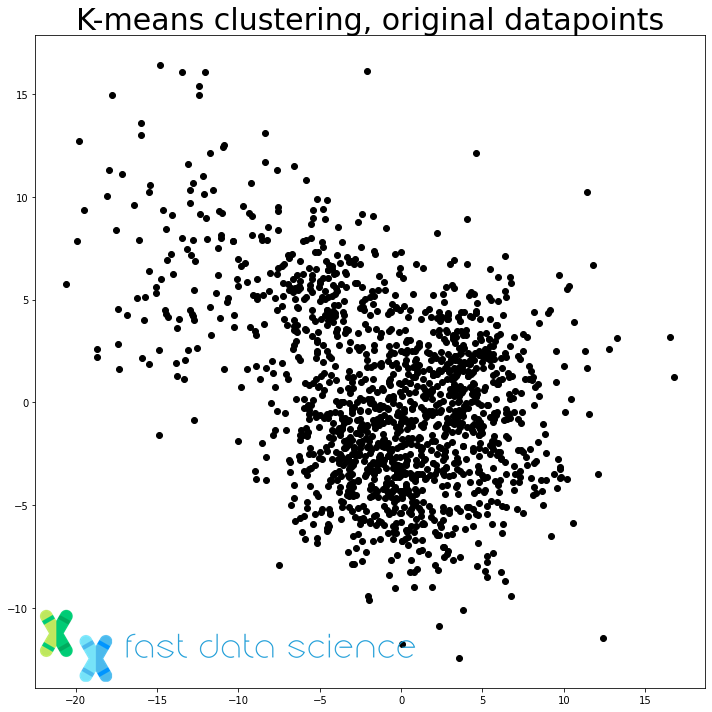
K-Means-Clustering ist ein extrem einfacher Algorithmus zum Clustering oder zum Entdecken von Gruppen und Themen in einem Datensatz. Stellen Sie sich beispielsweise vor, Sie haben 100 Nachrichtenartikel zu verschiedenen Themen. Mit dem K-Means-Clustering-Algorithmus können Sie herausfinden, dass der Datensatz 5 Themen enthält: Sport, Politik, Technologie, Welt und Wirtschaft. K-Means funktioniert für alle Arten von Daten, nicht nur für Text. Unternehmen können ihre Kunden beispielsweise anhand von Vorlieben und Ausgabemustern in Schichten gruppieren.
Fast Data Science - London
Animation, die zeigt, wie der K-Means-Algorithmus funktioniert. Zunächst werden die Clusterzentren zufällig ausgewählt. Dann wird abwechselnd jedem Datenpunkt sein nächstgelegenes Cluster zugewiesen und anschließend das Zentrum jedes Clusters anhand aller seiner Datenpunkte neu berechnet, bis sich die Clusterzuweisungen nicht mehr ändern.
Latent Dirichlet Allocation (LDA) ist ein Algorithmus, der in der Verarbeitung natürlicher Sprache zum Clustern von Textdokumenten verwendet wird. LDA ist ausgefeilter als K-Means und kann Dokumente mit jeweils einer Wahrscheinlichkeit mehreren Kategorien zuordnen.
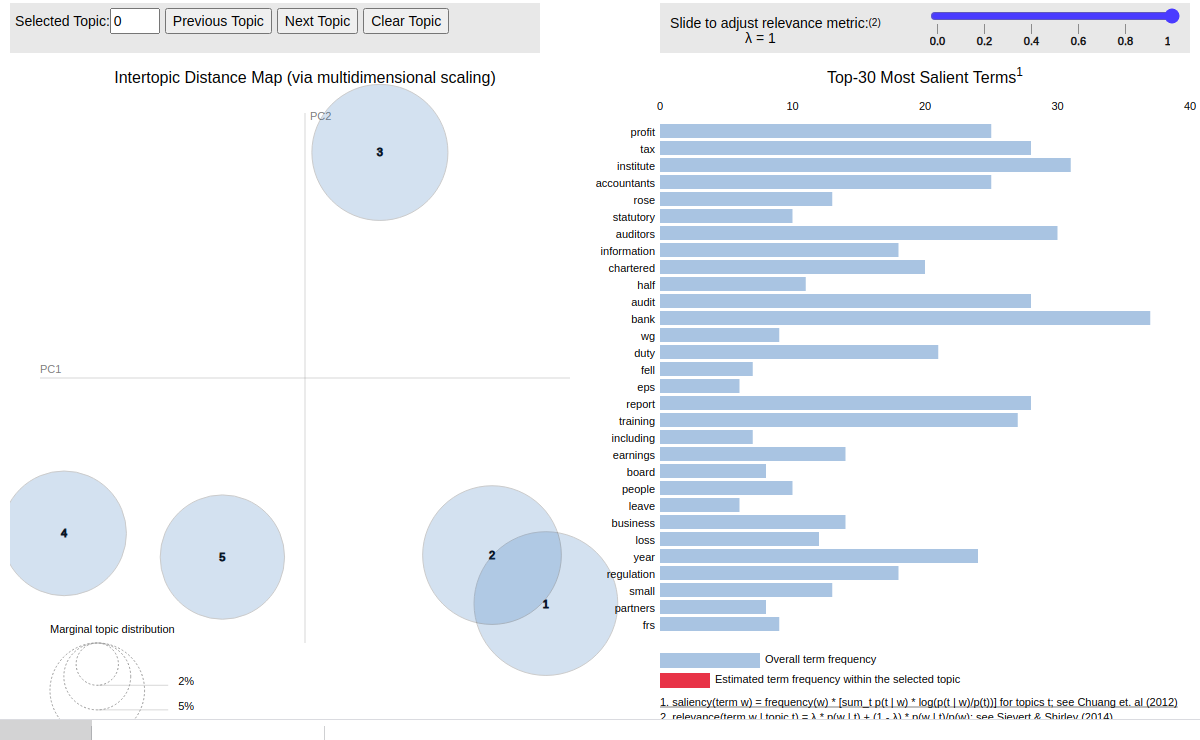
Visualisierung von Clustern, die durch latente Dirichlet-Analyse zugewiesen wurden, unter Verwendung von Text aus dem British National Corpus (BNC). Der Clusteralgorithmus gibt auch Gewichte für Wörter im Corpus aus, sodass wir jedes neu eingehende Dokument problemlos einem Cluster zuordnen können.
Eine Markow-Kette ist ein einfaches Modell, mit dem der Zustand eines Systems als Knoten in einem Diagramm definiert wird. Ein Aufzug hat beispielsweise drei Zustände: angehalten, aufwärts und abwärts. Eine Markow-Kette könnte so gestaltet werden, dass diese drei Zustände als Knoten in einem Diagramm dargestellt werden, wobei Übergangswahrscheinlichkeiten angeben, wie wahrscheinlich es ist, dass das System von einem Zustand in einen anderen wechselt.
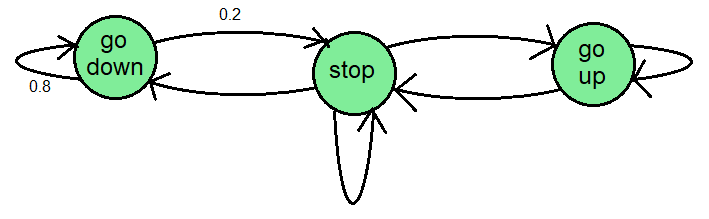
Eine schematische Darstellung, wie eine Markow-Kette für einen Aufzug aussehen könnte. Es gibt drei Zustände, und die Zahlen an den Übergängen geben die Wahrscheinlichkeiten an.
Viele Modelle des maschinellen Lernens, insbesondere Modelle zur Sprach- und Handschrifterkennung, basieren auf Hidden-Markov-Modellen , die dem Konzept der Markov-Kette ähneln, mit dem Unterschied, dass der Zustand des Modells nicht sichtbar ist (er stellt beispielsweise das in einer Sprachaufzeichnung ausgesprochene Wort dar) und wir nur die von jedem Zustand ausgegebenen Werte beobachten können (die die in der Aufzeichnung aufgezeichneten Daten darstellen).

Schließlich sind Markov-Chain-Monte-Carlo -Modelle (MCMC) sehr leistungsfähige Werkzeuge im maschinellen Lernen (obwohl sie sehr langsam und schwer zu berechnen sind). Sie ermöglichen es uns, Stichproben aus einer beliebigen Wahrscheinlichkeitsverteilung zu generieren. Dadurch können wir Wahrscheinlichkeitsverteilungen auf clevere Weise manipulieren. Sie können beispielsweise eine Regressionsgerade für einen Datensatz berechnen und dabei die starke Annahme einbeziehen, dass der Achsenabschnitt 0 ist. Das bedeutet, dass Sie Modelle erstellen können, die Informationen aus Trainingsdaten und Informationen aus Vorannahmen kombinieren.
Der einfachste Textklassifizierer, den Sie erstellen können, ist ein Naive-Bayes-Klassifizierer. Dies ist ein grundlegendes Konzept der NLP und der Datenwissenschaft. Wenn Sie beispielsweise einen Spamfilter erstellen möchten, der E-Mails als Spam oder Ham (unerwünschte vs. erbetene E-Mails) kategorisiert, ist der Naive-Bayes-Klassifizierer das einfachste Tool für diese Aufgabe. Er wird als „naiv“ bezeichnet, weil er davon ausgeht, dass Text aus einer Gruppe zufällig auftretender Wörter besteht, die voneinander unabhängig sind. Obwohl dies nicht zutrifft, funktionieren Naive-Bayes-Klassifizierer überraschend gut und es ist recht einfach, einen eigenen funktionierenden Textklassifizierer zu erstellen.
Mathematische Optimierung ist eine ergänzende Technik zum maschinellen Lernen und überschneidet sich manchmal mit diesem. Optimierung wird oft wie folgt ausgedrückt: Auswahl der besten Option aus einer Menge von vielen Optionen, wodurch die Kosten minimiert werden.
Beispiele für klassische Optimierungsprobleme sind das Problem des Handlungsreisenden (bei dem ein Handlungsreisender die kürzeste Route durch alle Städte auf seiner Reiseroute finden muss) und das Behälterpackproblem, bei dem Gegenstände unterschiedlicher Größe effizient in eine begrenzte Anzahl von Behältern gepackt werden müssen.
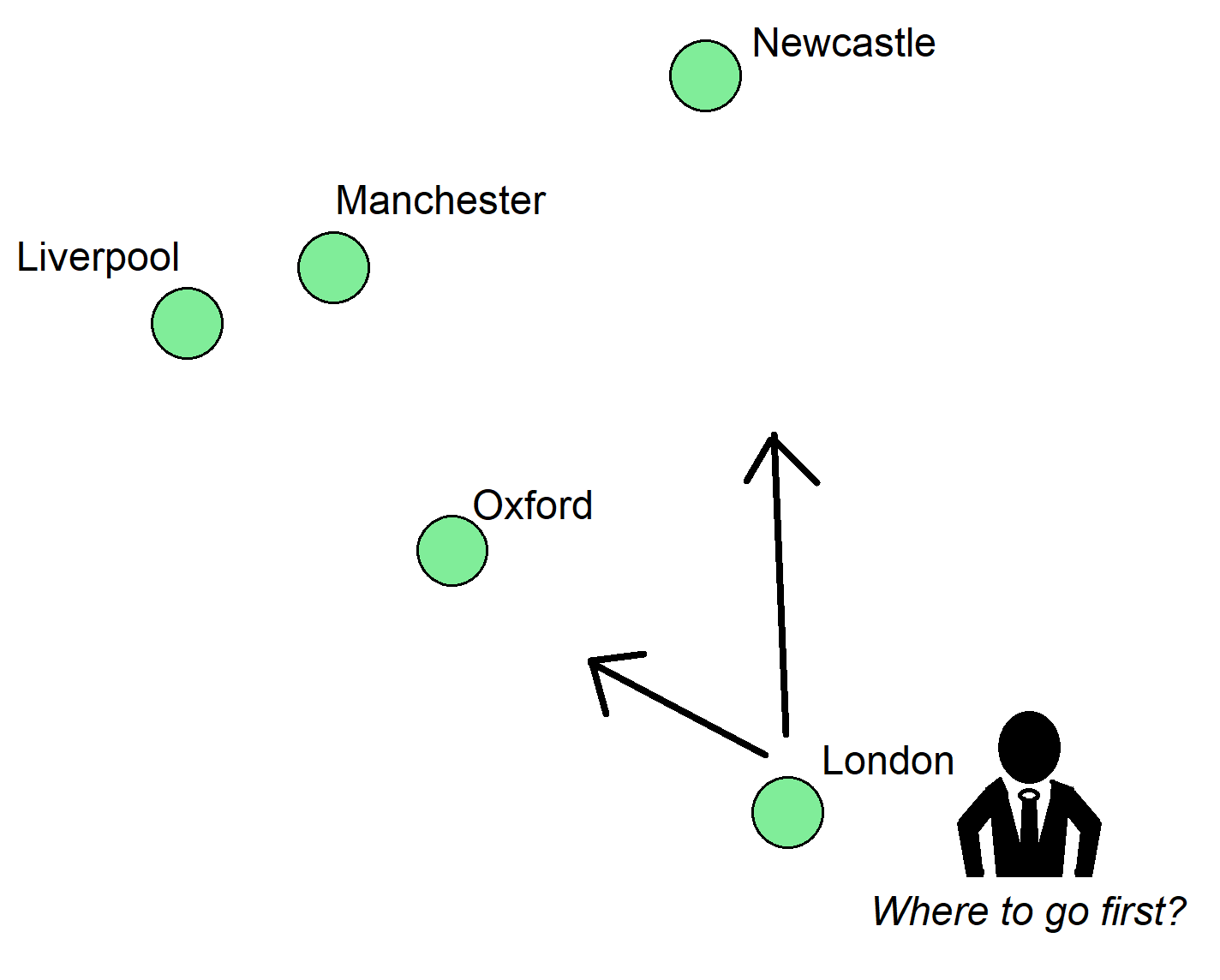
Das Problem des Handlungsreisenden ist ein klassisches Optimierungsproblem. Stellen Sie sich vor, unser Handlungsreisender muss diese fünf Städte besuchen. Wenn er die Entfernungen zwischen ihnen kennt, was ist die kürzeste Route, die in jeder Stadt nur einmal Halt macht?
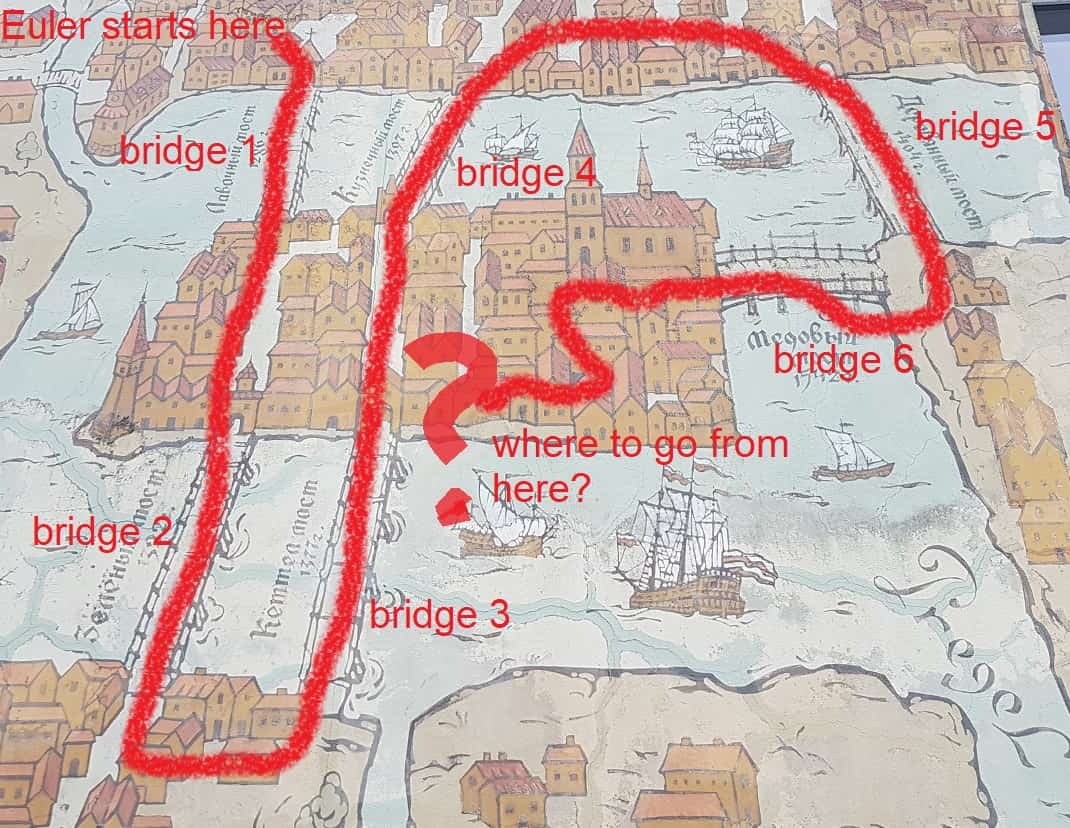
Karte des historischen Kaliningrad, Russland. Der Mathematiker Leonhard Euler stellte fest, dass es unmöglich war, über alle Brücken der Stadt zu gehen und am Ausgangspunkt anzukommen. Dies ist eine Art Optimierungsproblem, das als Routing-Problem bezeichnet wird. Um seinen Sonntagsspaziergang zu verbessern, gründete Euler einen neuen Zweig der Mathematik, die Graphentheorie. Eulers Problem ist bekannt als Die sieben Brücken von Königsberg .
Präzision und Rückruf sind zwei Zahlen, die wir zur Bewertung der Leistung eines Modells verwenden. Am bekanntesten werden sie zur Bewertung von Suchmaschinen verwendet. Die Präzision gibt an, wie relevant die Ergebnisse der Suchmaschine sind, und der Rückruf gibt ihre Abdeckung an. Es ist viel informativer, die Leistung eines Modells in Bezug auf Präzision und Rückruf anzugeben, z. B. Präzision = 0,8, Rückruf = 0,4, als die Genauigkeit zu verwenden.

Mathematische Definitionen von Präzision und Rückruf
Stellen Sie sich vor, Sie arbeiten in einer Fabrik und haben ein maschinelles Lernmodell, das Produktfehler erkennt. Sie testen das Modell an zehn Produkten und stellen fest, dass fünf Produkte richtig als fehlerhaft erkannt wurden ( wahr-positiv ), eines fälschlicherweise als fehlerhaft erkannt wurde, aber in Wirklichkeit in Ordnung war ( falsch-positiv ), zwei richtig als negativ erkannt wurden ( wahr-negativ ) und zwei tatsächlich fehlerhaft waren, aber das Modell sie nicht erkannte ( falsch-negativ ). Wir können eine Konfusionsmatrix erstellen, die darstellt, wie viele Produkte wir richtig und wie viele falsch erkannt haben und welche Arten von Fehlern wir gemacht haben:
| Wirklich defekt | Wirklich nicht defekt | |
|---|---|---|
| Modell als defekt befunden | tp = 5 | fp = 1 |
| Modell hat keinen Defekt gefunden | fn = 2 | tn = 2 |
Konfusionsmatrix eines Machine-Learning-Modells, das Produktfehler identifizieren soll
Wir können die Zahlen aus der Konfusionsmatrix nehmen und sie in die Formeln für Präzision, Rückruf und F-Score oben einsetzen, um Folgendes zu erhalten:
Diese drei Zahlen sind viel aussagekräftiger als die Angabe der Genauigkeit allein.
Q-Learning ist eine Technik des bestärkenden Lernens, die es einem Roboter ermöglicht, eine Richtlinie oder allgemeine Strategie zu erlernen, die er in zukünftigen Situationen anwenden wird. Es gibt eine Belohnungsfunktion Q , die die Belohnung darstellt, die der Roboter für eine bestimmte Aktion erwartet.
Wenn ein Roboter beispielsweise Schachspielen lernt, hat ein Zug vielleicht Q = 0,8 und der andere Zug Q = 0,2, basierend auf früheren Spielen gegen Menschen. Der Roboter würde nicht immer unbedingt den höchsten Q wählen, da es manchmal notwendig ist, andere Möglichkeiten zu erkunden. Dies wird als Kompromiss zwischen Erkundung und Nutzung bezeichnet.

Eine Schach spielende KI würde für jeden möglichen Zug einen Q-Score berechnen, würde aber nicht unbedingt immer den Zug mit der höchsten Punktzahl wählen, da sowohl „Erkundung“ als auch „Ausbeutung“ wertvoll sind.
Q-Learning lässt sich wie folgt zusammenfassen:
Ein Random Forest ist ein maschineller Lernalgorithmus, der für nahezu jede Aufgabe verwendet werden kann. Random Forests sind äußerst robust und eignen sich gut für die Anpassung nicht homogener Daten, wie z. B. Tabellen mit Kundeninformationen unterschiedlicher Datentypen (Alter, Geschlecht, Kreditwürdigkeit, bisherige Ausgaben).
Aus diesem Grund werden Random Forests häufig für geschäftliche KI-Anwendungen verwendet. Eine Alternative zu Random Forests ist ein Gradient Boosted Tree.
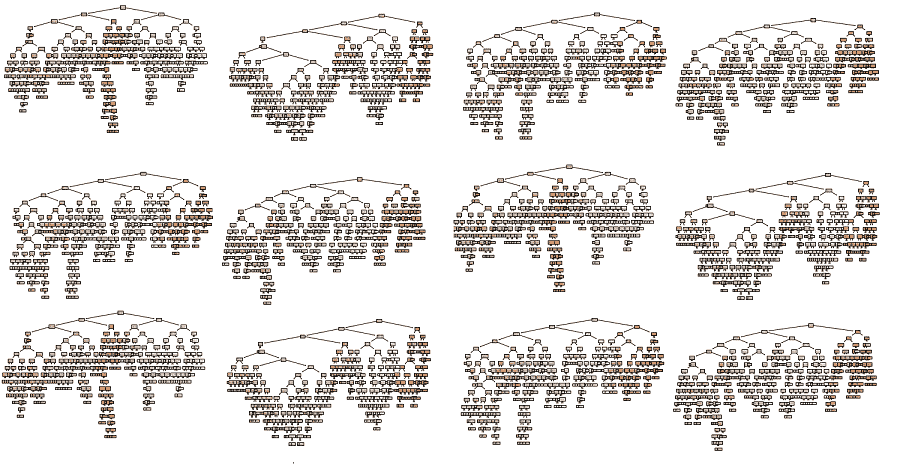
Ein einzelnes Random-Forest-Modell kann aus Tausenden komplexer und ungenauen Entscheidungsbäume bestehen. Diese Bäume stimmen alle gemeinsam ab, um die beste Antwort zu erzielen.
Ein Random-Forest-Modell besteht aus vielen Entscheidungsbäumen, die alle anhand einer Momentaufnahme der Daten trainiert wurden. Jeder Entscheidungsbaum für sich ist nicht sehr genau (es handelt sich um „schwache Lerner“), aber die Kombination ihrer Ergebnisse kann sehr genau sein. Dies ist ein bisschen wie das klassische Jahrmarktspiel „Rate das Gewicht des Schweins“, bei dem die durchschnittliche Schätzung aller Teilnehmer überraschend genau sein kann.
Die Sigmoidfunktion ist eine mathematische Funktion mit einer S-förmigen Kurve. Die Sigmoidfunktion wird in vielen Bereichen des maschinellen Lernens verwendet, beispielsweise in der logistischen Regression, wo sie eine Zahl in eine Wahrscheinlichkeit zwischen 0 und 1 umwandelt. Die bekannteste Sigmoidfunktion ist die logistische Sigmoidfunktion, die wie folgt aussieht:
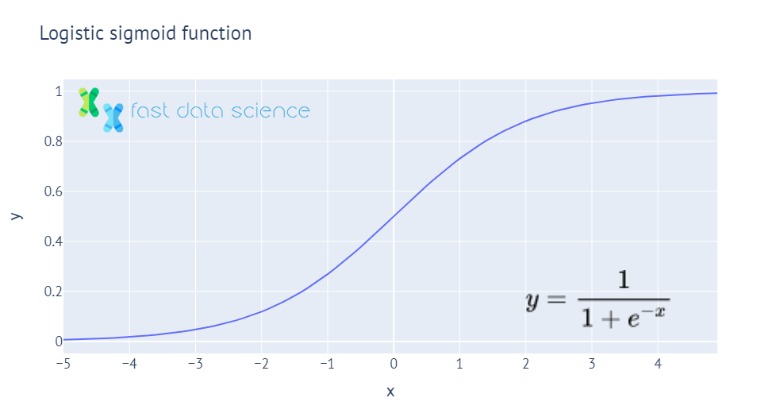
Die Softmax-Funktion ist eine Verallgemeinerung der Sigmoid-Funktion auf viele Dimensionen. Wenn Sie beispielsweise ein Convolutional Neural Network trainieren, um Bilder in „Katze“, „Hund“ oder „Frettchen“ zu klassifizieren, wäre die letzte Schicht eine „Softmax“-Schicht, die drei Wahrscheinlichkeiten ausgibt, die sich zu eins summieren.
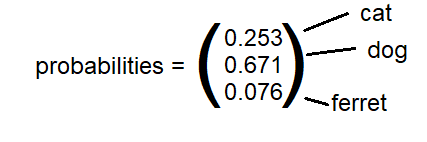
Ein Transformer ist ein hochmodernes neuronales Netzwerkdesign, das sehr nützlich für die Verarbeitung sequentieller Daten ist, wie z. B. Textklassifizierung, maschinelle Übersetzungen, Audioaufnahmen, Genomsequenzen und Musik. Ein Transformer-neuronales Netzwerk verfügt über eine Komponente namens Aufmerksamkeitsmechanismus, die es dem Transformer ermöglicht, bei der Verarbeitung bestimmten Wörtern links und rechts von einem bestimmten Wort besondere Aufmerksamkeit zu schenken. Der Aufmerksamkeitsmechanismus ermöglicht es beispielsweise, das Wort „es“ in das französische oder spanische Wort des entsprechenden Geschlechts zu übersetzen, indem auf den gesamten Satz geachtet wird.
Das bekannteste auf Transformatoren basierende Modell ist BERT (Bidirectional Encoder Representations from Transformers), das 2018 von Google als Open Source veröffentlicht wurde.
Die bekanntesten Algorithmen für maschinelles Lernen sind überwachte Lernalgorithmen, bei denen einem Modell eine Reihe von Trainingsbeispielen, etwa Bilder, und eine Reihe entsprechender Beschriftungen, etwa „Katze“ oder „Hund“, gegeben werden und es lernt, neue, noch nie gesehene Bilder zu beschriften.
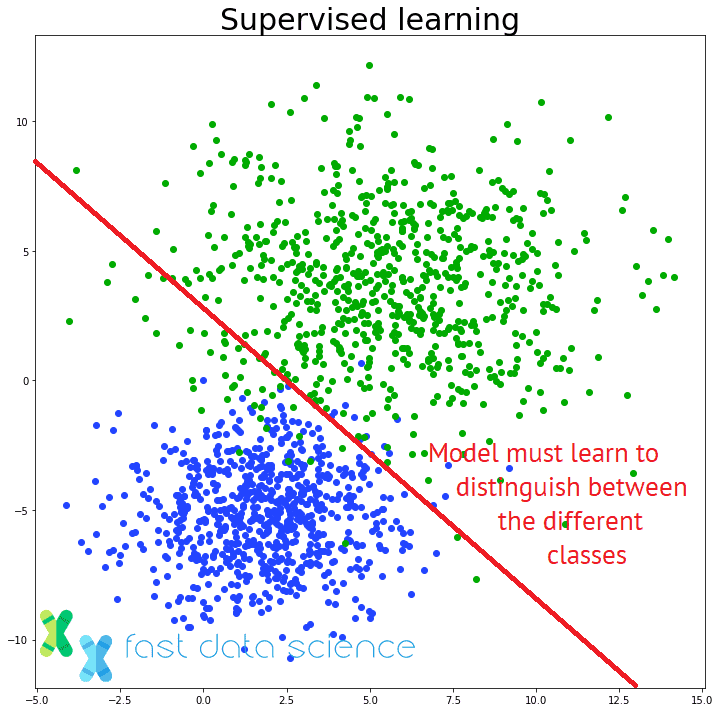
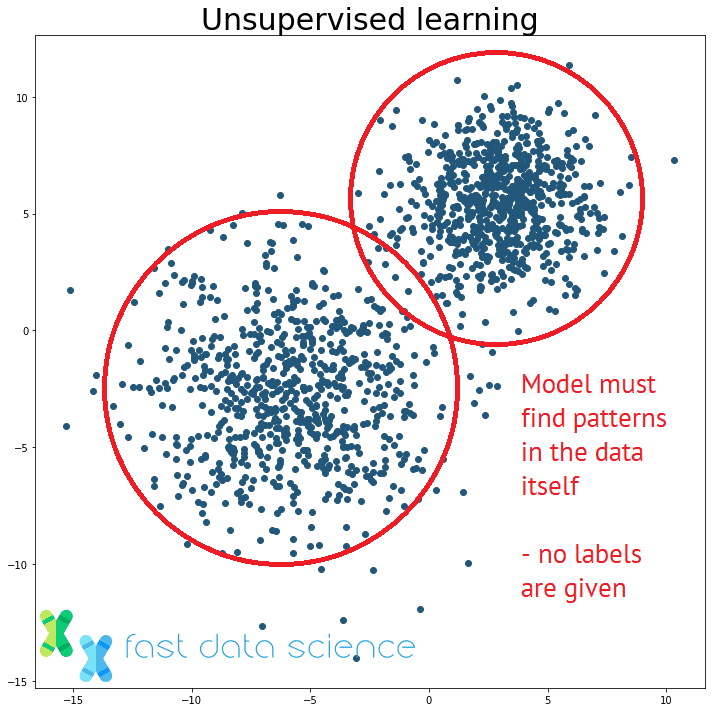
Der Unterschied zwischen überwachtem und unüberwachtem Lernen: Ein unüberwachtes Lernmodell muss Muster in unstrukturierten Daten finden, ohne dass ihm die richtigen Antworten mitgeteilt werden.
Unüberwachtes Lernen ist ein Sammelbegriff für Algorithmen des maschinellen Lernens, die keine Beschriftungen verwenden, sondern lediglich nach Mustern in den Daten suchen. Einfache Beispiele für Algorithmen des unüberwachten Lernens sind Clustering-Algorithmen wie K-Means-Clustering oder Latent Dirichlet Allocation (LDA).
Ein Beispiel für überwachtes Lernen wäre ein Modell, das eingehende E-Mails für die Weiterleitung an die Beschwerde- oder Verkaufsabteilung klassifiziert, basierend auf der Entscheidung eines Menschen hinsichtlich früherer E-Mails.
Das entsprechende Problem beim unüberwachten Lernen wäre: Wir erhalten ein Paket nicht klassifizierter E-Mails und haben keine Ahnung, ob sie in zwei oder zehn Gruppen gruppiert werden sollen, und wir haben keine Ahnung, um welche Gruppen es sich handelt. Ein Algorithmus für unüberwachtes Lernen müsste Cluster und Themen selbst entdecken.
Wenn Sie ein Machine-Learning-Modell trainieren, ist es wichtig, normalerweise zwischen Trainingsdatensatz, Validierungsdatensatz und Testdatensatz zu unterscheiden. Aber was ist der Unterschied zwischen Validierungsdatensatz und Testdatensatz und warum brauche ich beide?
Stellen Sie es sich wie einen Schüler vor, der in der Schule für eine große Prüfung in Analysis lernt:
Wenn wir ein Machine-Learning-Modell trainieren, nehmen wir normalerweise alle verfügbaren Daten und teilen sie zu Beginn in Trainings-, Validierungs- und Testdatensätze auf, wobei wir häufig Anteile von 80-10-10 Prozent verwenden. Diese Aufteilung sollten wir für alle Experimente beibehalten, die wir anschließend durchführen.
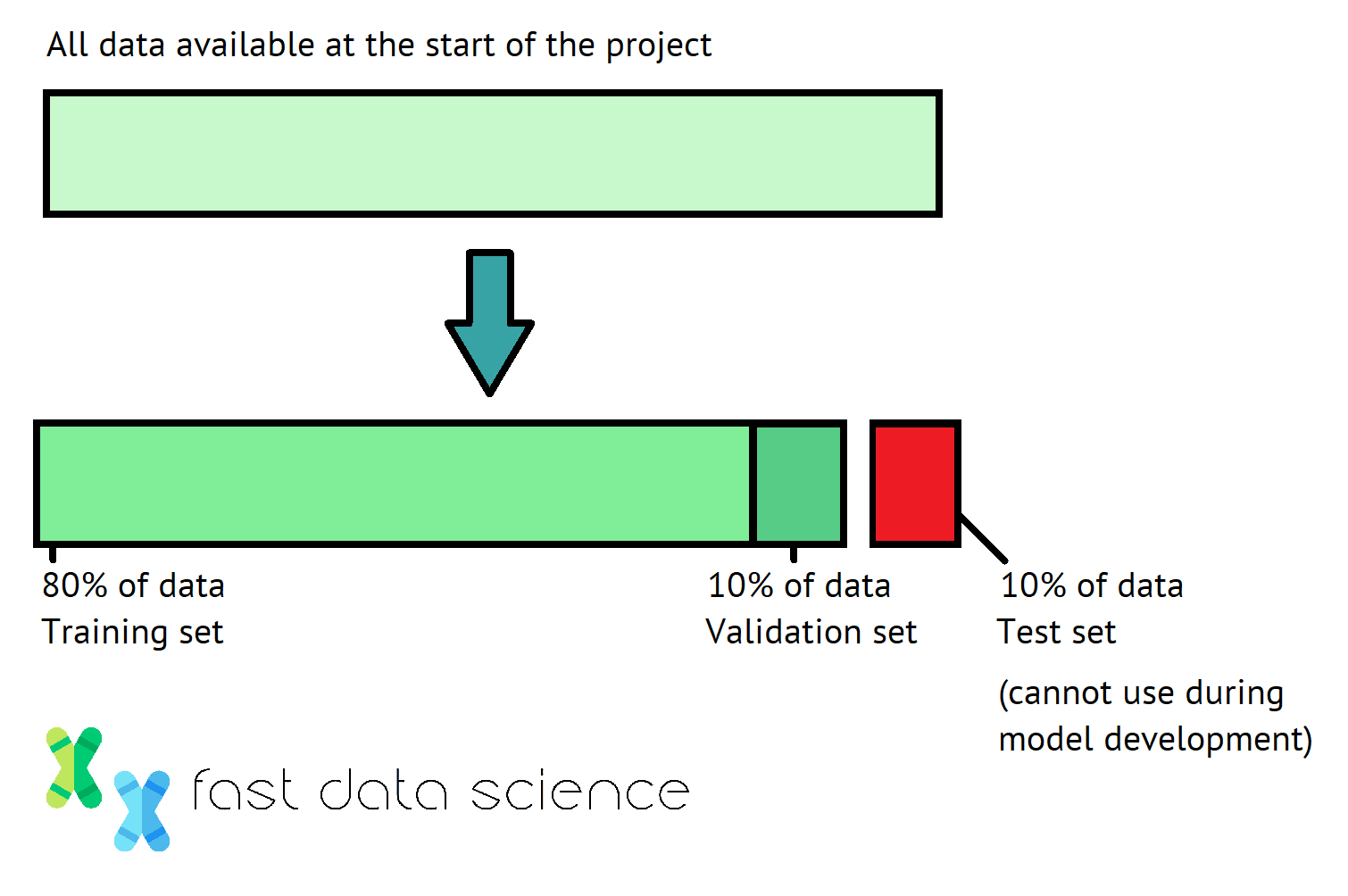
Die 80-10-10-Prozent-Aufteilung wird in der Datenwissenschaft häufig für Trainings-, Validierungs- und Testdaten verwendet.
Wir können den Trainingssatz beliebig verwenden. Sie können beispielsweise mit 1001 verschiedenen Modellen experimentieren, von Convolutional Neural Networks bis zu LSTMs, um zu sehen, welches Design zu funktionieren scheint. Sie können einen Blick auf den Trainingssatz werfen, um herauszufinden, bei welchen Beispielen Ihr Modell Fehler macht – hat es beispielsweise Probleme mit dunklen Bildern oder kopfüber hängenden Hunden und Katzen?
Der Validierungssatz sollte strenger verwendet werden. Während wir jedes Modell trainieren, sollten wir die Leistung des Validierungssatzes überwachen. Wir können Hyperparameter wie die Lernrate anpassen, um zu sehen, ob dies die Modellleistung des Validierungssatzes verbessert. Aber wir sollten nicht im Detail untersuchen, wo das Modell falsch liegt.
Beachten Sie, dass ohne Validierungssatz die Gefahr besteht, dass das Modell zu stark an den Trainingssatz angepasst wird. Tatsächlich ist es auch möglich, dass Ihr Modell zu stark an den Validierungssatz angepasst wird, wenn Sie den Validierungssatz zu oft verwenden. Daher halten einige Forscher eine Reserve an zusätzlichen Validierungssätzen vor, um dieses Problem zu vermeiden. Dies ist natürlich nur eine Option, wenn Sie sehr viele Daten haben.
Schließlich sollte der Testsatz nur einmal verwendet werden: wenn wir mit dem gesamten Training fertig sind und bereit sind, das Modell bereitzustellen oder zu übermitteln. Wenn Ihr Modell in der Praxis eingesetzt wird, beispielsweise um Kundenverhalten vorherzusagen, dann ist Ihr Testsatz das zukünftige Verhalten realer Kunden.
Eine nützliche Technik ist die Kreuzvalidierung , bei der Trainingsdaten und Validierungsdaten abwechselnd verwendet werden und jede Instanz mindestens einmal sowohl als Trainings- als auch als Testdaten verwendet wird. Die Kreuzvalidierung ist nützlich, weil sie uns zeigt, wie gut sich ein Modell auf neue Daten verallgemeinern lässt.
Wortvektoreinbettungen sind eine Technik, die in der Verarbeitung natürlicher Sprache verwendet wird. Dabei werden Wörter auf Vektoren reeller Zahlen abgebildet. Beispiel:
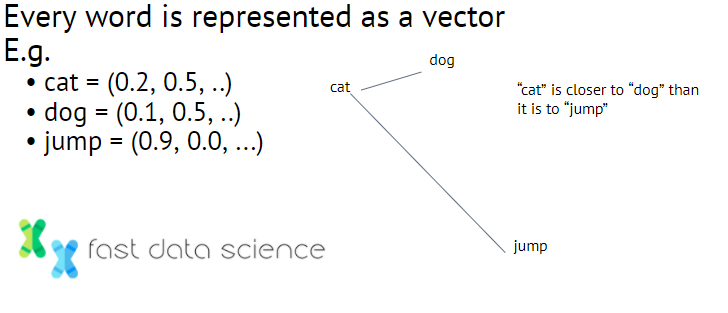
Einige Beispiele, wie Wortvektoreinbettungen aussehen könnten. Ein weiteres klassisches Beispiel ist „Mann“ in der Nähe von „Frau“ und „König“ in der Nähe von „Königin“. Sie können also sogar Vektoren subtrahieren, um „König“ + „Frau“ – „Mann“ = „Königin“ zu erhalten.
Häufig wird ein großer Raum verwendet, wie beispielsweise der 300-dimensionale Vektorraum, der in word2vec verwendet wird.
Es besteht eine semantische Ähnlichkeit zwischen Wörtern, die im Vektorraum nahe beieinander liegen. Unten sehen Sie eine Word2Vec-Einbettung, die ich anhand einer Reihe von Stellenbeschreibungen trainiert habe.

Ein Wortvektor-Embedding, das anhand eines Datensatzes mit Stellenbeschreibungen trainiert wurde. Beachten Sie, wie nahe Markt, Branche und Sektor beieinander liegen. Dies ist eine Form des unüberwachten Lernens.
Der Vorteil der Verwendung von Wortvektoreinbettungen besteht darin, dass Wörter in natürlicher Sprache in ein neuronales Netzwerk eingespeist werden können, sodass wir mithilfe von Deep Learning grundsätzlich diskrete Daten verarbeiten können.
Erklärbare KI ist eine Reihe von Techniken zum Analysieren und Auseinandernehmen von Modellen des maschinellen Lernens. Einige Deep-Learning-Modelle haben Millionen von Parametern und es ist für einen Menschen unmöglich zu verstehen, was sie alle tun. Mit erklärbarer KI führen wir kleine Störungen in die Eingabe eines Modells ein und beobachten, wie sie sich auf die Ausgabe des Modells auswirken. Indem wir dies viele Male tun, können wir verstehen, warum ein Modell bestimmte Entscheidungen trifft.
Erklärbare KI wird wahrscheinlich an Bedeutung gewinnen, da die KI-Regulierung zunehmend Erklärungen für algorithmische Entscheidungen verlangt.
Hier ist ein kurzes Video, das wir bei Fast Data Science über erklärbare KI gemacht haben.
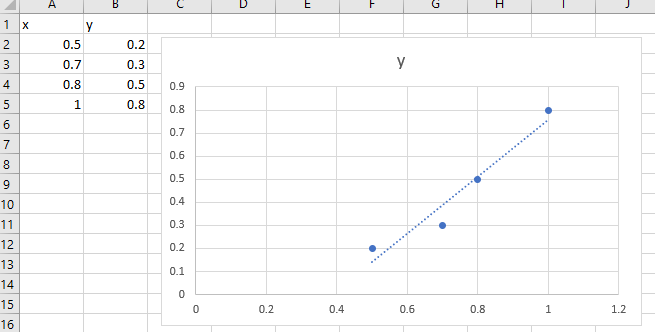
Diese Formel ist die Grundlage der linearen Regression und damit auch der neuronalen Netzwerke und eines Großteils der Datenwissenschaft. Haben Sie sich schon einmal gefragt, wie Microsoft Excel es schafft, eine gerade Linie an eine Reihe verstreuter Punkte anzupassen?
Die Antwort lautet: Durch Minimierung der Gesamtverlustfunktion ½( y - ŷ )² für alle Datenpunkte:
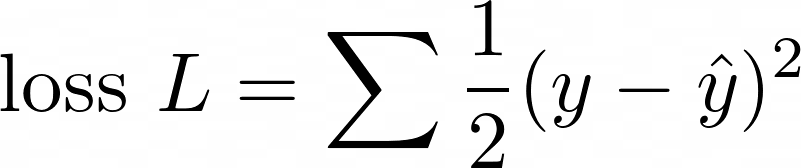
Stellen wir uns vor, unser Datensatz ist eine Reihe von Punkten x und y :
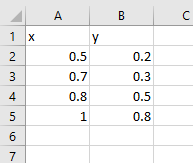
Wir wollen ein Modell trainieren, das eine Linie anpasst
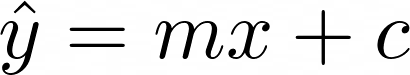
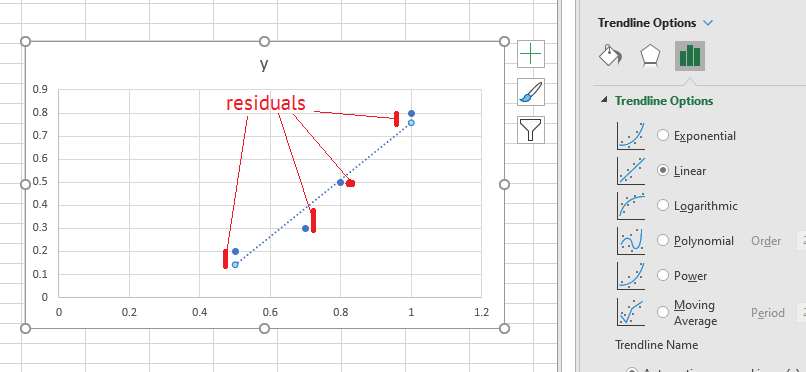
Wenn die Punkte nicht genau auf einer geraden Linie liegen, dann beträgt der Fehler an jedem Punkt
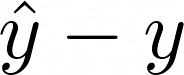
Dies wird als Residuum bezeichnet.
Wie kann man den Rest so klein wie möglich machen? Die Mathematik ist einfacher, wenn wir versuchen, das Quadrat des Restes zu minimieren:
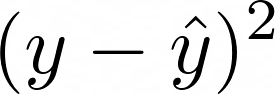
Dazu fügen wir ½ vor, um das Ergebnis schöner zu machen, und nehmen die Summe der Residuen aller Datenpunkte. Wir nennen das die Verlustfunktion:
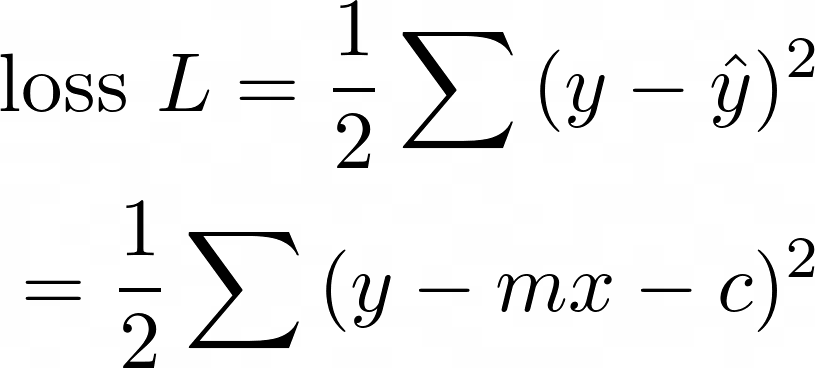
Wenn Excel nun eine gute Anpassung gefunden hat, ist die Verlustfunktion klein. Dies ist der Fall, wenn der Gradient der Verlustfunktion gleich Null ist. Es ist möglich, die richtigen Werte für m und c zu wählen, um die Verlustfunktion auf den niedrigstmöglichen Wert zu bringen. Und genau das macht Excel im Verborgenen: Es minimiert den Abstand von jedem Punkt in den Daten zur Linie der besten Anpassung.
Jetzt können wir KI und Datenwissenschaft entmystifizieren.
Was ist ein tiefes neuronales Netzwerk? Es ist lediglich eine Reihe von Excel-ähnlichen linearen Regressionsmodellen, die mit Aktivierungsschichten (wie der Sigmoidkurve ) zusammengefügt sind. Um den niedrigsten Wert der Verlustfunktion zu erhalten, wird noch ein weiteres Geheimrezept benötigt: der Backpropagation-Algorithmus . Lesen Sie mehr darüber in meinem Beitrag darüber, wie neuronale Netzwerke lernen .
Wenn also Unternehmen, die KI-Lösungen verkaufen, davon reden, wie „intelligent“ ihre neuronalen Netzwerke seien und wie sie eine KI entwickelt hätten, die Drehbücher besser schreiben könne als ein Mensch oder besser malen könne als Picasso, dann ist das bloß Marketing-Hype. In Wirklichkeit haben diese Unternehmen Folgendes:
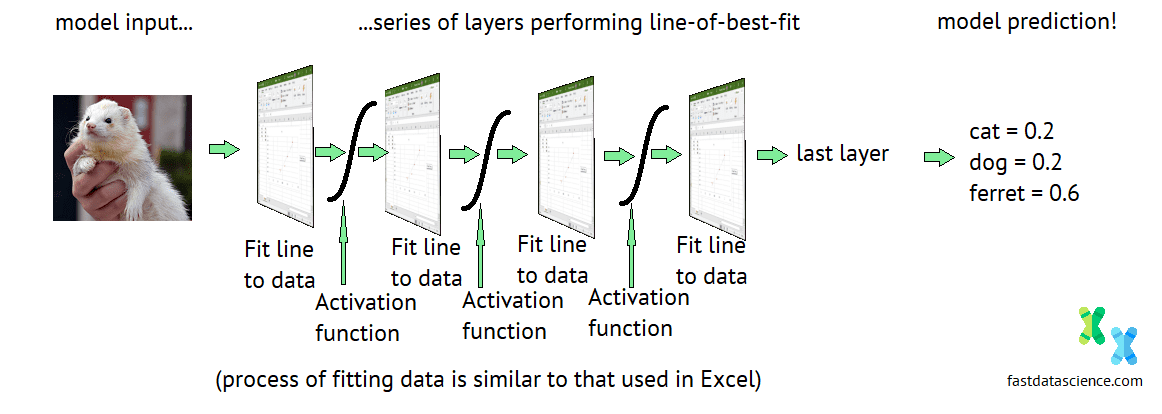
Pseudodiagramm eines neuronalen Netzwerks aus Excel, das die Aktion „Eine Linie an Daten anpassen“ darstellt.
Auch wenn ich die Untergangsängste mancher Leute, eine bösartige KI könnte die Weltherrschaft an sich reißen, nicht herunterspielen möchte, scheint es mir doch so, dass die modernsten KIs heutzutage im selben Boot sitzen wie die einfache Linienanpassungsfunktion von Excel – nur eben mit ein paar cleveren Tricks ausgestattet.
Allerdings hat uns allein dieses Jahr gezeigt, wie plötzlich Katastrophen auftreten können, sodass ich meine Worte im Jahr 2021 vielleicht zurücknehmen muss!
Der Z-Score oder Standardwert ist ein Wert, der angibt, wie viele Standardabweichungen ein Messwert über oder unter dem Mittelwert liegt. Wenn beispielsweise die Bevölkerung eines Landes eine durchschnittliche Körpergröße von 150 cm und eine Standardabweichung von 10 cm hat, dann hätte eine Person mit einer Körpergröße von 150 cm einen Z-Score von 0 und eine Person mit einer Körpergröße von 160 cm einen Z-Score von 1.
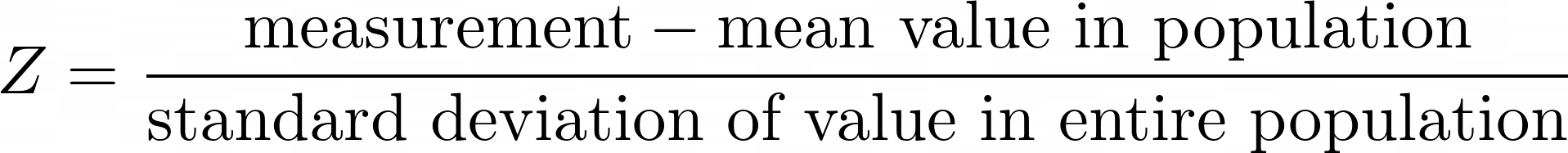
Hier sehen Sie eine interaktive Illustration, wie die Körpergröße einer Bevölkerung auf Z-Scores abgebildet werden kann. Sie zeigt, wie wir den Z-Score für eine Person berechnen, deren Körpergröße eine Standardabweichung über der durchschnittlichen Körpergröße der Bevölkerung liegt:
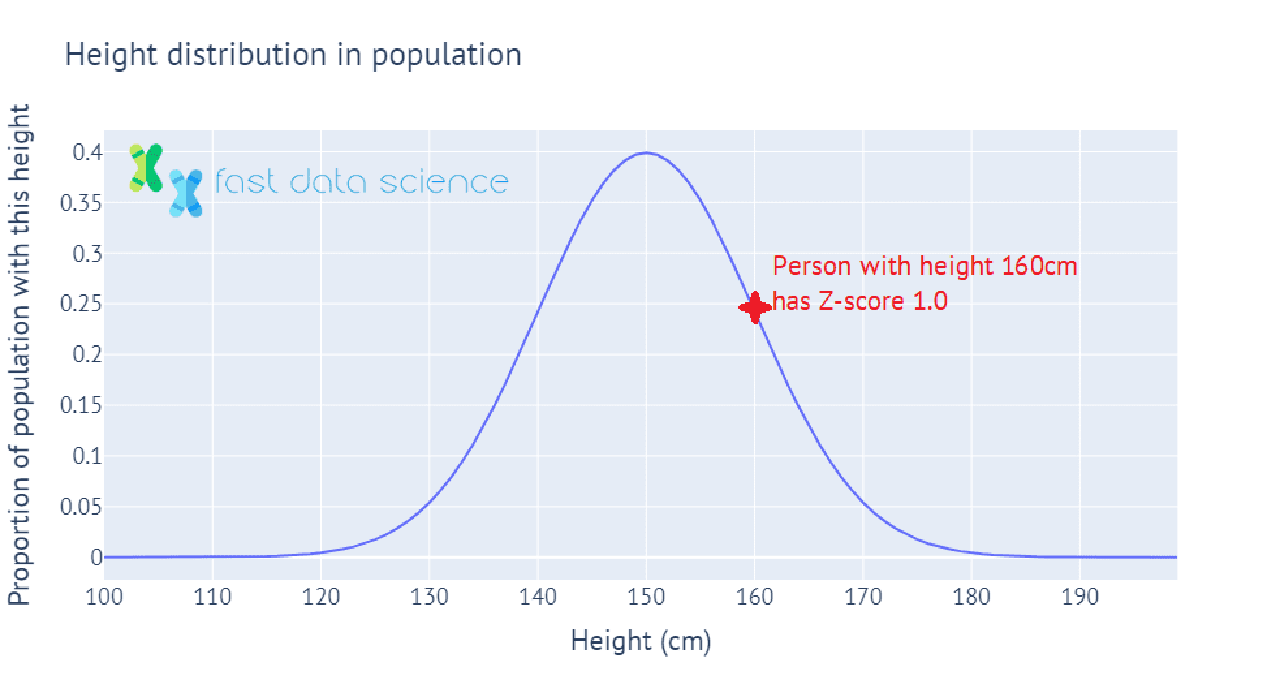
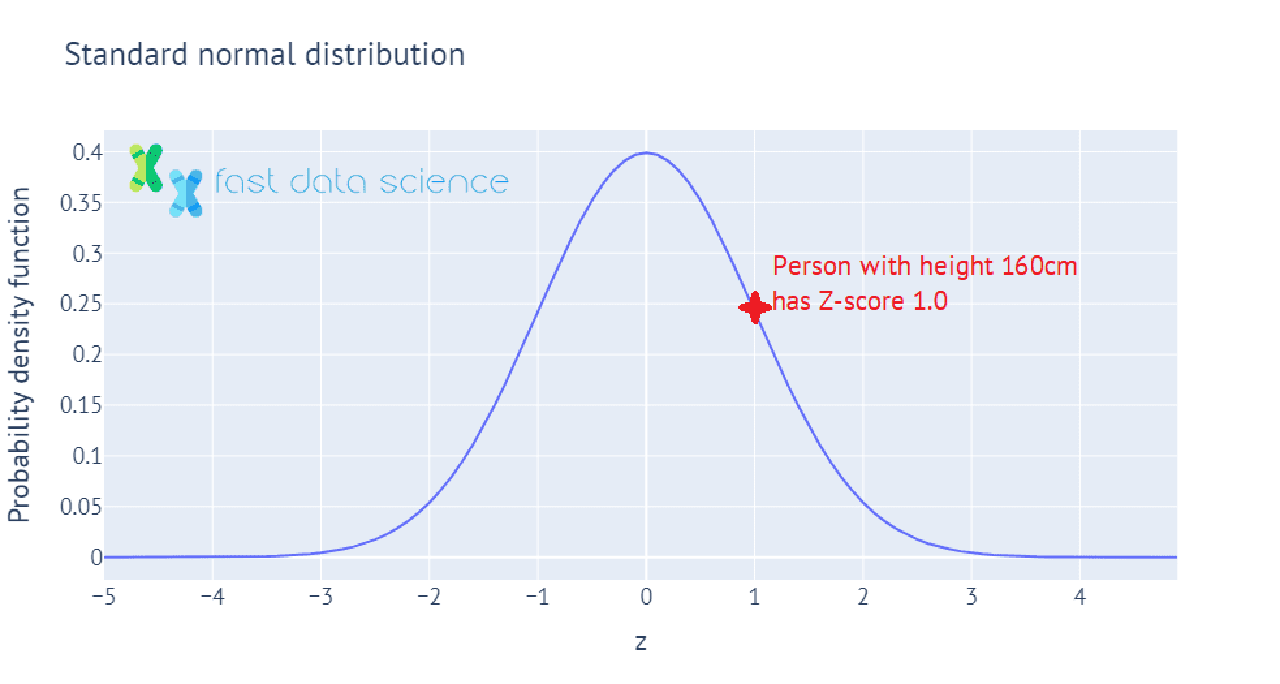
In der Praxis haben wir in der Statistik oft nur eine Stichprobe von Daten, beispielsweise 100 Personen, deren Körpergröße wir gemessen haben. In diesem Fall kennen wir den Mittelwert und die Standardabweichung der Körpergröße der Bevölkerung nicht, also verwenden wir stattdessen den Mittelwert und die Standardabweichung der Stichprobe von 100 Personen. Dieser Wert wird als t -Statistik bezeichnet und wir können ihn verwenden, um viele statistische Tests durchzuführen, beispielsweise um die Hypothese zu testen, dass die durchschnittliche Körpergröße der Männer in der Bevölkerung signifikant von der durchschnittlichen Körpergröße der Frauen in der Bevölkerung abweicht.
Werte wie der Z-Score und die T- Statistik werden von Statistikern häufig verwendet, kommen aber bei Problemen des maschinellen Lernens und der Datenwissenschaft selten vor, da sich viele Anwendungen des maschinellen Lernens und der Datenwissenschaft in der Industrie eher mit der Vorhersage von z. B. Kundenverhalten, Maschinenausfällen, Fahrzeugbeladung und dergleichen befassen als mit c. Hypothesentests werden jedoch häufig in Bereichen wie der Pharmaindustrie verwendet, wo ein Unternehmen beispielsweise verlangen könnte, dass die Wirksamkeit eines neuen Medikaments auf ein Konfidenzniveau von 5 % begrenzt ist.
Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdecken
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you