Wie erklären wir, wie ein neuronales Netzwerk ein Bild erkennen kann?
Manchmal stoßen wir als Datenwissenschaftler auf Fälle, in denen wir ein maschinelles Lernmodell erstellen müssen, das keine Blackbox sein sollte, sondern transparente Entscheidungen treffen sollte, die Menschen und Unternehmen verstehen können. Dies kann gegen unseren Instinkt als Wissenschaftler und Ingenieure verstoßen, da wir das möglichst genaueste Modell erstellen möchten.
In meinem vorherigen Beitrag über Gesichtserkennungstechnologie habe ich einige ältere, von Hand entwickelte Technologien, die für Menschen leicht verständlich sind, wie z. B. Gesichtsmerkmalpunkte, mit den modernsten Gesichtserkennungstechnologien verglichen, die schwerer zu verstehen sind. Dies ist ein Beispiel für den Kompromiss zwischen Leistung und Interpretierbarkeit oder Erklärbarkeit.
Stellen Sie sich vor, Sie haben einen Kreditantrag gestellt und der Algorithmus der Bank lehnt ihn ohne Begründung ab. Oder eine Versicherungsgesellschaft macht Ihnen bei der Verlängerung ein ungewöhnlich hohes Angebot. Ein medizinischer Algorithmus empfiehlt möglicherweise einen weiteren invasiven Test, entgegen dem besten Instinkt des Arztes, der das Programm verwendet.
Oder vielleicht vertraut der Manager des Unternehmens, für das Sie das Modell erstellen, nichts, was er nicht versteht, und verlangt eine Erklärung, warum Sie für bestimmte Kunden bestimmte Werte vorhergesagt haben.
All die oben genannten Beispiele sind reale Beispiele, bei denen ein Datenwissenschaftler möglicherweise Leistung gegen Erklärbarkeit eintauschen muss. In manchen Fällen ergibt sich die Wahl aus der Gesetzgebung. Beispielsweise gewähren einige Interpretationen der DSGVO einer Person ein „Recht auf Erklärung“ für jede algorithmische Entscheidung, die sie betrifft.
Ein Ansatz besteht darin, sehr undurchsichtige Modelle wie Random Forest oder Deep Neural Networks zu vermeiden und stattdessen linearere Modelle zu verwenden. Durch die Vereinfachung der Architektur erhalten Sie möglicherweise ein weniger leistungsfähiges Modell, der Genauigkeitsverlust ist jedoch möglicherweise vernachlässigbar. Manchmal erhalten Sie durch die Reduzierung der Parameter ein Modell, das robuster und weniger anfällig für Überanpassung ist. Möglicherweise können Sie ein komplexes Modell trainieren und es verwenden, um die Wichtigkeit von Merkmalen zu ermitteln, oder Sie können clevere Vorverarbeitungsschritte durchführen, um Ihr Modell linear zu halten.
Ein Beispiel wäre, wenn Sie ein Modell zur Vorhersage des Verkaufsvolumens auf der Grundlage von Produktpreis, Tag, Uhrzeit, Saison und anderen Faktoren haben. Wenn Ihr Manager oder Kunde ein erklärbares Modell wünschen würde, könnten Sie Wochentage, Stunden und Monate in eine One-Hot-Kodierung umwandeln und diese als Eingaben für ein lineares Regressionsmodell verwenden.
Die besten Modelle für Bilderkennung und -klassifizierung sind derzeit Convolutional Neural Networks (CNNs). Aus Sicht des menschlichen Verständnisses stellen sie jedoch ein Problem dar: Wie würden Sie vorgehen, wenn Sie die 10 Millionen Zahlen in einem CNN für einen Menschen verständlich machen möchten? Wenn Sie eine kurze Einführung in CNNs wünschen, lesen Sie bitte meinen vorherigen Beitrag zur Gesichtserkennung .
Sie können damit beginnen, das Problem aufzuteilen und sich anzusehen, was die verschiedenen Schichten tun. Wir wissen bereits, dass die erste Schicht in einem CNN normalerweise Kanten erkennt, spätere Schichten werden durch Ecken aktiviert und dann nach und nach immer komplexere Formen.
Sie können eine Reihe von Bildern verschiedener Klassen aufnehmen und sich die Aktivierungen an verschiedenen Punkten ansehen. Wenn Sie beispielsweise eine Reihe von Hundebildern durch ein CNN leiten:
Fast Data Science - London

Hundebild, das durch ein erklärbares CNN geleitet werden soll. Bildnachweis: Zeiler & Fergus (2014) [1]
…ab der vierten Schicht können Sie Muster wie dieses erkennen, bei denen das neuronale Netzwerk eindeutig beginnt, eine Art „Hundeverhalten“ zu erkennen.
 models can be explainable. Image credit: Zeiler & Fergus (2014)](https://fastdatascience.com/images/dog_activations.jpg)
Die Aktivierungen eines neuronalen Netzwerks durch die vierte Schicht erklären, wie das neuronale Netzwerk eine Art „Hundeverhalten“ erkannt hat. Bildnachweis: Zeiler & Fergus (2014) [1]
Wenn wir noch einen Schritt weitergehen, können wir verschiedene Teile des Bildes manipulieren und sehen, wie sich dies auf die Aktivierung des neuronalen Netzwerks in verschiedenen Stadien auswirkt. Indem wir verschiedene Teile dieses Pomeranian ausgrauen, können wir die Auswirkung auf Schicht 5 des neuronalen Netzwerks sehen und dann herausfinden, welche Teile des Originalbilds dem neuronalen Netzwerk am lautesten „Pomeranian“ entgegenschreien.
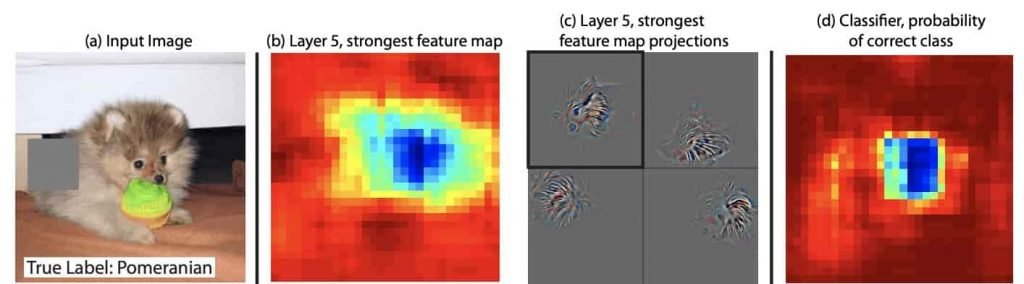
Wenn man verschiedene Segmente eines Eingabebildes ausgraut, kann man sehen, welcher Teil des neuronalen Netzwerks von Schicht 5 betroffen ist. Dadurch wird das Modell allmählich verständlicher. Bildnachweis: Zeiler & Fergus (2014) [1]
Wenn Ihre Gesichtserkennung mit diesen Techniken fehlschlägt und ein Eindringling in Ihr Haus gelangt, können Sie, wenn Sie die Eingabebilder haben, das CNN aufschlüsseln und herausfinden, wo der Fehler lag. Leider würde es sehr viel Zeit in Anspruch nehmen, so tief in ein neuronales Netzwerk einzudringen, daher bleibt noch viel Arbeit zu tun, um neuronale Netzwerke besser erklärbar zu machen.
 explainability by masking parts of a dog image](https://fastdatascience.com/images/Convolutional-neural-network-explainability-by-masking-parts-of-a-dog-image-min-2-1024x464.jpg)
Erklärbarkeit eines Convolutional Neural Network durch Maskierung von Teilen eines Hundebildes
Stellen Sie sich vor, Sie haben ein Preiselastizitätsmodell trainiert, das eine polynomische Regression 3. Ordnung verwendet. Ihr Kunde benötigt jedoch etwas, das einfacher zu verstehen ist. Er möchte wissen, wie hoch die Verkaufszahlen mit jedem Cent, der vom Produktpreis abgezogen wird, steigen werden. Oder wie hoch die Preisminderung mit jedem Jahr ist, das ein Fahrzeug älter wird?
Sie können ein paar Tricks ausprobieren, um dies verständlicher zu machen. Sie können beispielsweise Ihr Polynommodell in eine Reihe verbundener linearer Regressionsmodelle umwandeln. Dies sollte fast die gleiche Aussagekraft haben, könnte aber leichter interpretierbar sein.
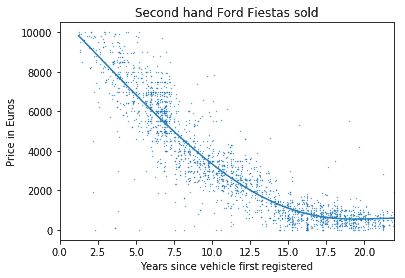
Traditionelle polynomische Regression zur Anpassung einer Kurve, die die Wertminderung eines Autos in Abhängigkeit vom Alter des Fahrzeugs zeigt
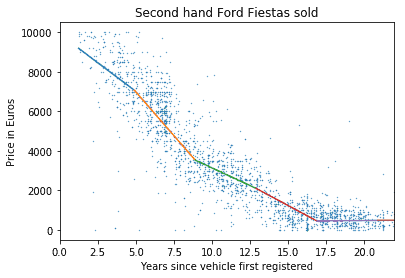
Teilen Sie die Daten in Segmente auf und wenden Sie auf jedes Segment eine lineare Regression an. Dies ist nützlich, da es eine ungefähre Abschreibungsrate in verschiedenen Stadien zeigt, die für Vertriebsmitarbeiter für schnelle Berechnungen hilfreich sein kann.
Empfehlungssysteme wie die Filmempfehlungen von Netflix sind bekanntermaßen schwer richtig umzusetzen und Benutzer sind oft verwirrt über die aus ihrer Sicht seltsamen Empfehlungen. Die Empfehlungen wurden normalerweise direkt oder indirekt aufgrund der vorherigen Sendungen berechnet, die der Benutzer gesehen hat. Die einfachste Art, ein Empfehlungssystem zu erklären, besteht darin, eine Nachricht wie „Wir empfehlen Ihnen The Wire , weil Sie Breaking Bad gesehen haben“ anzuzeigen – das ist der Ansatz von Netflix.
Es gab einige Bemühungen, eine Technik zu entwickeln, mit der ein maschinelles Lernmodell jeder Art, egal wie komplex es ist, entmystifiziert und erklärt werden kann.
Die Technik, die ich zur Untersuchung eines Convolutional Neural Network beschrieben habe, lässt sich im Großen und Ganzen auf jede Art von Modell erweitern. Sie können versuchen, die Eingabe eines maschinellen Lernmodells zu stören und seine Reaktion auf Störungen in der Eingabe zu überwachen. Wenn Sie beispielsweise ein Textklassifizierungsmodell haben, können Sie verschiedene Wörter im Dokument ändern oder entfernen und beobachten, was passiert.
Eine Implementierung dieser Technik heißt LIME oder Local Interpretable Model-Agnostic Explanations [2]. LIME funktioniert, indem es aus einer Eingabe Tausende von Duplikaten mit leichtem Rauschen erstellt und diese doppelten Eingaben an das ML-Modell weiterleitet und die Ausgabewahrscheinlichkeiten vergleicht. Auf diese Weise ist es möglich, ein Modell zu untersuchen, das sonst eine Blackbox wäre.
Ich habe LIME an meinem Autorenidentifikationsmodell ausprobiert. Ich gab dem Modell einen Auszug aus einem von JK Rowlings Romanen, die nicht Harry Potter sind, und bat LIME um eine Erklärung für die Entscheidung. Also versuchte LIME, Wörter im Text zu ändern und überprüfte, welche Änderungen die Wahrscheinlichkeit erhöhen oder verringern, dass JK Rowling den Text geschrieben hat.

LIME-Erklärung für einen Auszug aus „Der Ruf des Kuckucks“ von JK Rowling , für Vorhersagen eines Stilometriemodells , das anhand einiger ihrer früheren Harry-Potter-Romane trainiert wurde
Die Erklärung des Stilometriemodells durch LIME ist interessant, da sie zeigt, wie das Modell den Autor anhand von Teilfolgen von Funktionswörtern wie „ und ich nicht … “ (grün hervorgehoben) und nicht anhand von Wörtern mit starkem Inhalt wie „ Polizei “ erkannt hat.
Allerdings sind die von LIME bereitgestellten Erkenntnisse begrenzt, da LIME im Hintergrund einzelne Wörter stört, während ein auf neuronalen Netzwerken basierender Textklassifizierer Muster im Dokument im größeren Maßstab betrachtet.
Ich denke, dass für ausgefeiltere Textklassifizierungsmodelle noch einiges an Arbeit an LIME geleistet werden muss, damit es präziser erklären kann, welche Teilfolgen von Wörtern am informativsten sind und nicht einzelne Wörter.
Bei Bildern liefert LIME noch spannendere Ergebnisse. Sie können es so einstellen, dass die Pixel in einem Bild hervorgehoben werden, die zu einer bestimmten Entscheidung geführt haben.

LIME hebt in rosa die Teile von Gesichtsbildern hervor, die „wie“ bestimmte Personen aussehen. Bildnachweis: Ribeiro, Singh, Guestrin (2016) [2]
Es gibt eine große Vielfalt an Machine-Learning-Modellen, die für die unterschiedlichsten Zwecke eingesetzt werden, und ihre Komplexität nimmt zu. Leider werden viele von ihnen immer noch als Black Boxes verwendet, was ein Problem darstellen kann, wenn es um Verantwortlichkeit, Branchenregulierung und das Vertrauen der Benutzer geht, wichtige Entscheidungen den Algorithmen als Ganzes anzuvertrauen.
Die einfachste Lösung besteht manchmal darin, Kompromisse einzugehen, z. B. Leistung gegen Interpretierbarkeit einzutauschen. Die Vereinfachung von Machine-Learning-Modellen zugunsten des menschlichen Verständnisses kann den Vorteil haben, dass die Modelle robuster werden.
Glücklicherweise gab es einige Bemühungen, Erklärbarkeitsplattformen zu entwickeln, um Black-Box-Maschinenlernen transparenter zu machen. Ich habe in diesem Artikel mit LIME experimentiert, das modellunabhängig sein soll, aber es gibt auch andere Alternativen.
Wir hoffen, dass die Regulierung mit der Zeit mit der Entwicklung der Technologie Schritt halten wird und wir bessere Möglichkeiten zur Erstellung interpretierbarer Modelle finden werden, die die Leistung nicht beeinträchtigen.
Verweise
Bereit für den nächsten Schritt in Ihrer NLP-Reise? Vernetzen Sie sich mit Top-Arbeitgebern, die Talente in der natürlichen Sprachverarbeitung suchen. Entdecken Sie Ihren Traumjob!
Finden Sie Ihren Traumjob
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you
{kind=link}