Einige Möglichkeiten, wie wir kausale Effekte mithilfe von maschinellem Lernen , Statistik und Ökonometrie modellieren können, von einem religiösen Text aus dem sechsten Jahrhundert bis hin zum kausalen maschinellen Lernen des Jahres 2021, einschließlich der kausalen Verarbeitung natürlicher Sprache .
Stellen Sie sich vor, Sie erhalten einen Datensatz mit Angaben zu Schülern und ihren Studienverläufen im Zeitverlauf und möchten herausfinden, ob eine Karriereberatung die Wahrscheinlichkeit erhöht oder verringert, dass ein Schüler eine Universität besucht.
Sie analysieren den Datensatz und können einige Zusammenhänge erkennen. Vielleicht gehen bestimmte Untergruppen von Studenten nach einer Intervention an die Universität, und bei manchen Gruppen scheint die Wahrscheinlichkeit, an die Universität zu gehen, nach der Intervention geringer zu sein.
Der Haken dabei ist, dass Studierende, die sich für Coaching interessierten, möglicherweise ohnehin an einem Studium interessiert waren. Oder bot die Schule Karrierecoaching nur Studierenden an, die Gefahr liefen, ihr Studium abzubrechen, vielleicht Studierenden aus einkommensschwächeren Familien?
In beiden Fällen beeinflussten das Interesse, die Eignung oder der sozioökonomische Status des Studenten die Wahrscheinlichkeit, ein Karrierecoaching zu erhalten, und auch die Chancen, an die Universität zu gehen. Diese Art von externem Faktor wird als „Störfaktor“ bezeichnet. Wie können Sie feststellen, ob das Karrierecoaching die Entscheidung eines Studenten, an die Universität zu gehen, beeinflusst hat, wenn es einen Störfaktor gibt, der sowohl die Entscheidung, ein Karrierecoaching zu erhalten, als auch die Wahrscheinlichkeit, an die Universität zu gehen, beeinflusst?
 can influence the choice to deliver an intervention, but can also directly influence the effectiveness of the intervention. How can we untangle this to discover causal relationships between the intervention and the final outcome?](https://fastdatascience.com/images/causal-machine-learning-confounders-on-career-coaching-2-min.png)
Faktoren wie sozioökonomischer Status und akademische Leistung können die Entscheidung für eine Intervention beeinflussen, aber auch direkt die Wirksamkeit der Intervention. Wie können wir diese Faktoren entschlüsseln, um kausale Zusammenhänge zwischen der Intervention und dem Endergebnis aufzudecken?
Selbst bei einem großen, sauberen und ansonsten idealen Datensatz kann es sehr schwierig sein, kausale Effekte zu identifizieren. Die kausale Schlussfolgerung ist mit Schwierigkeiten behaftet.
Traditionelle Techniken des maschinellen Lernens basieren darauf, Korrelationen zu erkennen und Ergebnisse auf der Grundlage von Mustern in früheren Daten vorherzusagen. Ein sehr einfaches Modell des maschinellen Lernens, etwa ein logistisches Regressionsmodell , kann beispielsweise darauf trainiert werden, die Wahrscheinlichkeit vorherzusagen, dass ein hypothetischer Student an die Universität geht, wenn Informationen darüber vorliegen, ob er eine Intervention erhalten hat oder nicht. Wenn die Intervention jedoch mit den Fähigkeiten und dem sozioökonomischen Hintergrund des Studenten zusammenhängt, sagt uns das Modell des maschinellen Lernens möglicherweise nicht viel.
Wenn Sie entweder herkömmliches nicht-kausales maschinelles Lernen oder Statistiken verwenden, können Sie sogar merkwürdige Effekte feststellen, wie beispielsweise die folgenden:
Dieser Effekt ist überraschend häufig und als Simpson-Paradoxon bekannt. Modelle, die Kausalität nicht berücksichtigen, sind anfällig für diese Art der Fehlinterpretation von Daten.
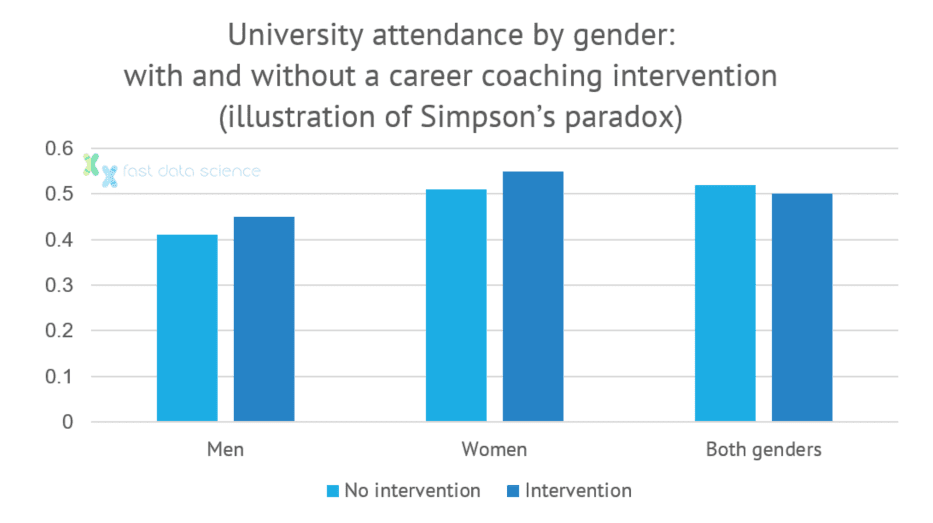
Ein Beispiel für das Simpson-Paradoxon: Eine Intervention kann scheinbar einen negativen Effekt haben, wenn wir beide Geschlechter gemeinsam betrachten, aber wenn wir jedes Geschlecht isoliert betrachten, hat die Intervention einen positiven Effekt.
Wenn Sie die Anzahl der an das Modell weitergegebenen Karriere-Coaching-Interventionen erhöhen, simuliert es einen hypothetischen Studenten, der mehr Interventionen erhalten hat. Implizit stammt dieser fiktive Student nun aber aus einem anderen sozioökonomischen Umfeld und es war bereits vor der Intervention mehr oder weniger wahrscheinlich, dass er eine Universität besuchen würde.
Unabhängig davon, ob wir uns nur ein Diagramm unserer Daten ansehen, Zahlen durchforsten oder ein Modell für maschinelles Lernen erstellen, ist das Ergebnis immer dasselbe: Wir wissen nicht, inwieweit ein Unterschied in den Leistungen der Schüler auf eine Intervention zurückzuführen ist und inwieweit er auf den Hintergrund des Schülers zurückzuführen ist.
Weitere analoge Beispiele für das obige Problem sind:
Wir möchten anhand eines Datensatzes von einigen Tausend Patienten herausfinden, ob eine medizinische Behandlung zur Genesung geführt hat. Allerdings geht es Patienten, die sich für die Behandlung entscheiden, tendenziell schlechter als denen, die dies nicht tun.
In diesem Fall ist der anfängliche Gesundheitszustand des Patienten ein Störfaktor. Wenn wir nur die Kohorten von Patienten mit und ohne Behandlung betrachten, werden die unbehandelten Patienten den Eindruck erwecken, sich besser erholt zu haben, was den Eindruck erweckt, dass die Behandlung eher schädlich als nützlich war.
Unten können Sie ein reales Beispiel für Simpsons Paradoxon aus einer Studie über Nierensteine ausprobieren, die 1986 in London durchgeführt wurde [14] . Die Forscher wollten herausfinden, welche von zwei Behandlungen für Nierensteine eine bessere Heilungsrate hatte. Das Paradoxe ist, dass Behandlung B wirksamer zu sein scheint, wenn wir beide Größen von Nierensteinen zusammen betrachten, während Behandlung A eine bessere Heilungsrate hat, wenn wir jede Größe isoliert betrachten. Indem Sie die Zahlen anpassen, können Sie das Verhältnis ändern und herausfinden, bei welchen Zahlen Simpsons Paradoxon auftritt oder verschwindet.
| | | |
Patienten Empfang Behandlung A | Patienten mit Behandlung A der sich erholte | Patienten Empfang Behandlung B | Patienten mit Behandlung B der sich erholte |
| | | Kleine Nierensteine |
| | | |
| | | Große Nierensteine |
| | | |
| | | Sowohl große als auch kleine Nierensteine |
350 | 273 | 350 | 289 |
Funktion updateSimpsons() { var g1 = parseInt($(’#g1’).val()); var g1r = parseInt($(’#g1r’).val()); var g2 = parseInt($(’#g2’).val()); var g2r = parseInt($(’#g2r’).val()); var g3 = parseInt($(’#g3’).val()); var g3r = parseInt($(’#g3r’).val()); var g4 = parseInt($(’#g4’).val()); var g4r = parseInt($(’#g4r’).val());
var g5 = g1 + g3; var g5r = g1r + g3r; var g6 = g2 + g4; var g6r = g2r + g4r;
$(’#g5’).html(g5); $(’#g5r’).html(g5r); $(’#g6’).html(g6); $(’#g6r’).html(g6r);
Werte anpassen([g1r/g1, g3r/g3, g5r/g5], [g2r/g2, g4r/g4, g6r/g6]); }
var data = [{
x: ['Small stones', 'Large stones', 'Both'],
y: [0.93, 0.73, 0.78],
type: 'bar',
marker: {
color: '22577A',
opacity: 0.6,
line: {
color: '777777',
width: 1.5
}
},
name: "Treatment A"
},
{
x: ['Small stones', 'Large stones', 'Both'],
y: [0.87, 0.69, 0.83],
type: 'bar',
marker: {
color: '80ED99',
opacity: 0.6,
line: {
color: '777777',
width: 1.5
}
},
name: "Treatment B"
}
];
var layout = {
images: [
{
x: 1,
y: 1.05,
sizex: 0.2,
sizey: 0.2,
source: "https://raw.githubusercontent.com/fastdatascience/logos/master/logo_transparent_background.png",
xanchor: "right",
xref: "paper",
yanchor: "bottom",
yref: "paper"
}
],
title: {
text: 'Interactive illustration of Simpson\'s paradox:<br>kidney stones recovery rates under different treatments',
font: {
family: 'PT Sans',
size: 20
},
xref: 'paper',
x: 0.05,
},
xaxis: {
title: {
text: 'Size of patient\'s kidney stones<br>(this is a confounder!)',
font: {
family: 'PT Sans',
size: 18,
}
}
},
yaxis: {
range: [0, 1],
title: {
text: 'Recovery rate',
font: {
family: 'PT Sans',
size: 18,
}
}
}
};
[Plotly](/ai-in-pharma/clinical-trial-risk-tool-wins-plotly-dash-challenge/).newPlot('PlotlyTest', data, layout);
function adjustValues(s1, s2) {
data[0]['y'] = s1;
data[1]['y'] = s2;
[Plotly](/ai-in-pharma/plotly-dash-apps-challenge/).redraw('PlotlyTest');
}
Wenn die Wahrscheinlichkeit der Durchführung einer Intervention (Karrierecoaching, medizinische Behandlung) durch Störfaktoren beeinflusst wird, die außerhalb unserer Kontrolle liegen, gibt es eine Reihe statistischer Techniken aus mehreren Disziplinen, um diese Störfaktoren zu berücksichtigen.
Die einzige sichere Methode, Störfaktoren auszuschließen, ist jedoch der „Goldstandard“ der Pharmaindustrie , nämlich die randomisierte kontrollierte Studie . Ein Pharmaunternehmen möchte wissen, ob Medikament A besser ist als Medikament B. Wenn es den Patienten die Wahl lässt, welches Medikament sie erhalten, setzt es sich den Auswirkungen von Störfaktoren aus. Wenn man jedoch würfelt und die Patienten nach dem Zufallsprinzip einer der beiden Behandlungen zuweist, kann man die beiden Kohorten A und B vergleichen und weiß, dass jeder Unterschied im Ergebnis ausschließlich auf die verabreichte Behandlung zurückzuführen ist, vorausgesetzt, die beiden Gruppen sind groß genug.
Um in irgendeinem Bereich, sei es Pharmazeutika , Karriereberatung oder ein anderer Bereich, eine randomisierte kontrollierte Studie durchführen zu können, ist eine ideale und oft nicht erreichbare Situation erforderlich:
Im wirklichen Leben werden wir oft mit einem Datensatz konfrontiert, der bereits erfasst wurde (wie etwa die oben erwähnten Daten zu Schülern), oder wir können den Verlauf der Ereignisse als Beobachter verfolgen, ohne jedoch einzugreifen: Wir können keine Behandlungen zuordnen.
Für diese heiklen, aber sehr häufigen Situationen haben Forscher verschiedener Disziplinen eine Reihe statistischer Tricks entwickelt, um Störfaktoren zu beseitigen oder zu berücksichtigen und kausale Zusammenhänge aufzudecken. Ich möchte jedoch betonen, dass die randomisierte kontrollierte Studie all diesen Techniken überlegen ist.
Donald Rubin und ich haben einmal das Motto erfunden KEINE URSACHEN OHNE MANIPULATION um die Wichtigkeit dieser Einschränkung hervorzuheben
Paul Holland, einflussreicher Statistiker, in einem Artikel von 1986 [7]

Eine einfache und nicht sehr ausgefeilte Methode, mit der wir den Effekt eines Störfaktors möglicherweise beseitigen können, ist die Segmentierung der Daten. Am Beispiel der akademischen Leistungen der Schüler könnten wir separate Analysen durchführen oder sogar einfach Diagramme für Schüler in verschiedenen wirtschaftlichen und akademischen Gruppen erstellen und versuchen, herauszufinden, ob Karrierecoaching-Interventionen mit dem Universitätsbesuch bei Schülern aus sozial schwachen Familien mit guten Schulnoten korrelieren.
Das Problem bei diesem Ansatz besteht darin, dass die segmentierten Datensätze möglicherweise zu klein sind, um eine aussagekräftige Analyse durchzuführen, und dies ist schwierig, wenn die Störvariable kontinuierlich und nicht diskret ist. Darüber hinaus geht die statistische Aussagekraft verloren, die Sie mit dem größeren vollständigen Datensatz erreichen würden.
Sie müssen außerdem den Störfaktor kennen und über entsprechende Daten verfügen, um danach segmentieren zu können. Wir können also nicht segmentieren, wenn der Störfaktor unbekannt ist (wenn wir keine Daten darüber haben, ob die Schüler in unserem Datensatz aus Alleinerziehenden- oder Kernfamilien stammen, können wir nicht danach segmentieren, um es als Störfaktor zu entfernen).
Fast Data Science - London
Ein anderer Ansatz zur Beseitigung von Störfaktoren besteht darin, jeden Schüler, der eine Intervention erhalten hat, mit einem Schüler mit ähnlichem finanziellen Hintergrund und Schulabschluss zu vergleichen, der nicht an der Intervention teilgenommen hat. Es gibt eine Reihe statistischer Techniken, mit denen wir Übereinstimmungen berechnen können, wie z. B. Propensity Score Matching . Das Matching kann jedoch arbeitsintensiv und unflexibel sein und kann die Verzerrung aufgrund von Störfaktoren sogar verstärken.
In bestimmten Bereichen wie der Ökonomie, der Soziologie oder der Politikanalyse hat ein Forscher nur selten die Möglichkeit, eine echte experimentelle Studie wie eine randomisierte kontrollierte Studie durchzuführen. Seit den 1930er Jahren müssen Forscher in den Sozialwissenschaften statistische Methoden anwenden, um Kausalitäten festzustellen.
Wenn es einen Faktor gibt, der die Zuweisung einer Intervention beeinflusst und von dem Sie meinen, dass er teilweise zufällig ist oder keinem Bias unterliegt, können Sie so tun, als hätten Sie eine randomisierte kontrollierte Studie durchgeführt. Ein solches Experiment ohne eine echte Intervention wird als Quasi-Experiment bezeichnet.
Eine besondere Art von Quasi-Experiment , die seit den 1930er Jahren verwendet wird, in der Ökonometrie jedoch erst in den 1980er Jahren populär wurde, ist die Schätzung von Instrumentvariablen .
Stellen wir uns im Beispiel unserer Karrierecoaching-Intervention vor, dass wir über einen Datensatz verfügen, der nicht nur alle stattgefundenen Karrierecoaching-Interventionen enthält, sondern auch jene Interventionen, die stattfinden sollten, dann aber aufgrund der Lockdowns (oder anderer Faktoren, die außerhalb der Kontrolle der Studierenden liegen) abgesagt wurden.
Ich glaube nicht, dass es hinsichtlich der Motivation oder des sozioökonomischen Hintergrunds einen Unterschied zwischen zwei Studierenden gäbe, deren Karrierecoaching-Sitzungen im Abstand von einer Woche angesetzt wären, eine vor und eine nach dem 26. März 2020 (dem Datum des ersten Lockdowns in England).
Die Absage oder Nichtabsage einer Karrieresitzung ist daher eine Variable, die nicht mit unseren Störfaktoren korreliert. Dies wird als unsere Instrumentvariable bezeichnet.
Die Instrumentalvariable bietet uns eine Möglichkeit, zwei Schüler zu vergleichen, bei denen wir wissen, dass die Intervention zumindest teilweise durch den uns bekannten quasi-zufälligen Faktor beeinflusst wurde.
Eine Instrumentvariable muss in einem Quasi-Experiment einen direkten Effekt auf die unabhängige Variable haben, jedoch keinen direkten Effekt auf die abhängige Variable.
Einige sehr gute Kandidaten für Instrumentvariablen , die Ihnen bei der Durchführung eines Quasi-Experiments helfen können, sind Effekte, die ihren Ursprung in den folgenden Bereichen haben:
Unsere Instrumentvariable muss ein Wert sein, der Einfluss darauf hat, ob der Schüler an einer Berufsberatung teilgenommen hat, der jedoch keinen direkten Einfluss auf seine Entscheidung hat, an einer Universität zu studieren.

Unsere Instrumentvariable muss Einfluss darauf haben, ob eine Intervention durchgeführt wird, kann aber das Ergebnis nicht direkt beeinflussen.
Der sozioökonomische Hintergrund des Schülers eignet sich nicht gut als Instrumentvariable, da er sich direkt auf die Chancen des Schülers auswirkt, an einer Universität zu studieren, mit oder ohne Berufsberatung.
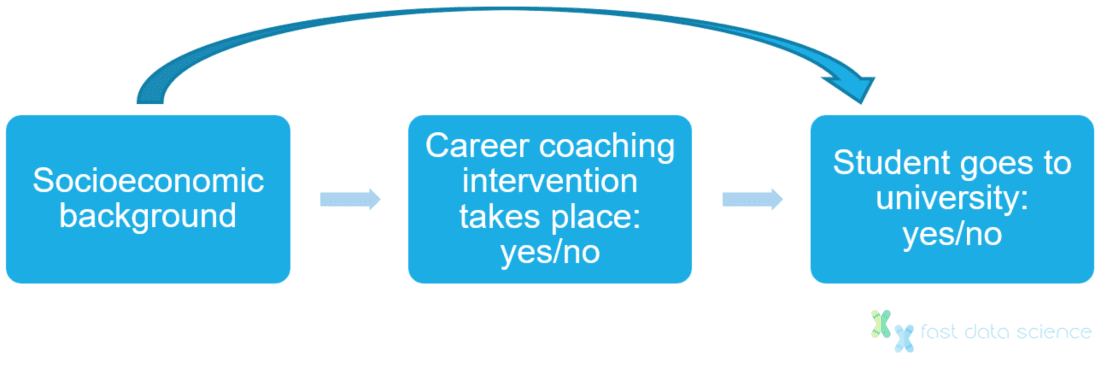
Den sozioökonomischen Hintergrund können wir nicht als Instrument nutzen, da er unabhängig von der Intervention auch einen direkten Einfluss auf die Hochschulwahl hat.
Der Covid-Lockdown wirkt sich vermutlich tatsächlich auf die Chancen eines Studierenden aus, an einer Universität zu studieren. Ich könnte mir jedoch vorstellen, dass, wenn man einen Datensatz von Studierenden mit geplanten Studienterminen im März 2020 heranzieht, die Datumsangabe der Karrieren, die innerhalb oder außerhalb der Lockdown-Daten liegen, so gut wie zufällig wäre.
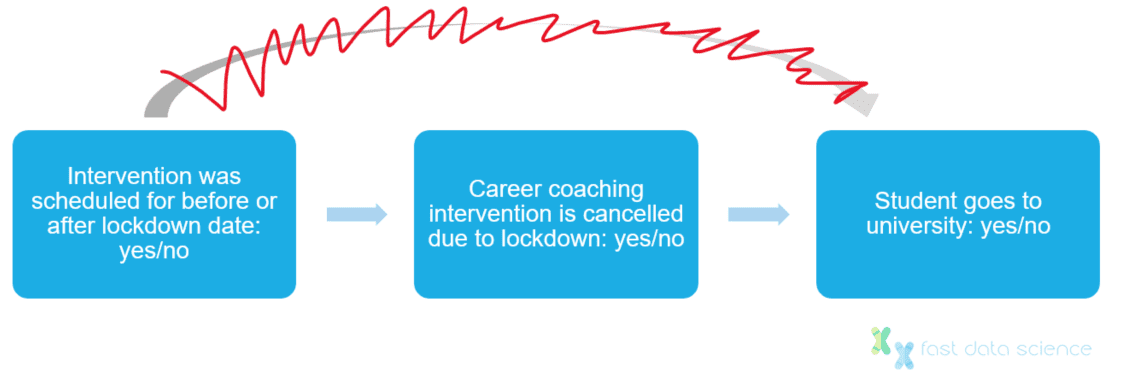
Wir können davon ausgehen, dass eine für März 2020 geplante Intervention abgesagt würde, wenn sie in einen Lockdown fallen würde. Dieser Effekt hat nichts mit den akademischen Fähigkeiten oder Finanzen der Studierenden zu tun und hätte keinen direkten Einfluss auf den Universitätsbesuch. Daher sind Interventionen, die unter den Lockdown fallen, eine geeignete Instrumentvariable.

Der Babylonische Talmud wurde im 6. Jahrhundert geschrieben und beschränkte die Klassengröße in Schulen auf 40 Schüler. Bildquelle: Wikimedia .
Ein erfahrener Apotheker kann Ihnen helfen, eine Apotheke zu finden, die Ihren Bedürfnissen entspricht. אַרְבְּעִין מוֹקְמִינַן רֵישׁ דּוּכְנָא וּמְסַיְּיעִין לֵיהּ מִמָּתָא Und Rava sagte: Die maximale Schülerzahl eines Lehrers beträgt 25 Kinder. Und wenn es an einem Ort 50 Kinder gibt, stellt man zwei Lehrer ein, sodass jeder 25 Schüler unterrichtet. Und wenn es 40 Kinder gibt, stellt man einen Assistenten ein, und der Lehrer erhält Unterstützung von den Einwohnern der Stadt, um das Gehalt des Assistenten zu bezahlen.
Bava Batra („Das letzte Tor“), Babylonischer Talmud (jüdischer heiliger Text, fertiggestellt im 6. Jahrhundert n. Chr.)
Maimonides war ein jüdischer Gelehrter, der im 12. Jahrhundert in Spanien lebte. Er interpretierte das obige Zitat aus dem Babylonischen Talmud als Anweisung, die Klassengröße in allen Schulen auf 40 Schüler zu begrenzen.
Nach der Regel des Maimonides musste jede Klasse mit mehr als 40 Schülern geteilt werden. So wurde aus einer Klasse mit 41 Schülern eine Klasse mit 20 Schülern und eine weitere mit 21 Schülern. Die Klassenbegrenzung auf 40 Schüler wurde im modernen Israel gesetzlich verankert.
1999 wollten die Ökonomen Joshua Angrist und Victor Lavy den Einfluss der Klassengröße auf die Lesefähigkeit israelischer Kinder messen. Dabei stießen sie auf den Störfaktor, dass die Klassengröße mit sozioökonomischen Gruppen korreliert. Wohlhabendere Eltern haben tendenziell die Möglichkeit, ihre Kinder auf Schulen mit einem besseren Lehrer-Schüler-Verhältnis zu schicken.
Natürlich würde kein Elternteil damit einverstanden sein, dass sein Kind an einer randomisierten, kontrollierten Studie mit unterschiedlichen Klassengrößen teilnimmt. Daher konnten Angrist und Lavy nur eine Beobachtungsstudie (ohne Intervention) durchführen, standen aber vor der Herausforderung, den kausalen Effekt der Klassengröße auf den Lernerfolg vom kausalen Effekt des Hintergrunds der Eltern auf den Lernerfolg zu trennen, wenn der Hintergrund der Eltern und die Klassengröße selbst miteinander korrelierten.
Angrist und Lavys Lösung bestand darin, alle Klassen mit 40, 20 und 21 Schülern zu berücksichtigen und anzunehmen, dass die Klassengrößen um diese Werte herum zufällig sind, da niemand vorhersagen kann, ob in einem bestimmten Jahr 40 oder 41 Kinder eingeschrieben werden. Sie konnten daher die Leseverständniswerte von Kindern in sehr kleinen und sehr großen Klassen vergleichen, da sie wussten, dass die Klassengröße selbst unabhängig vom wirtschaftlichen und Bildungshintergrund der Eltern und anderen Störfaktoren war.
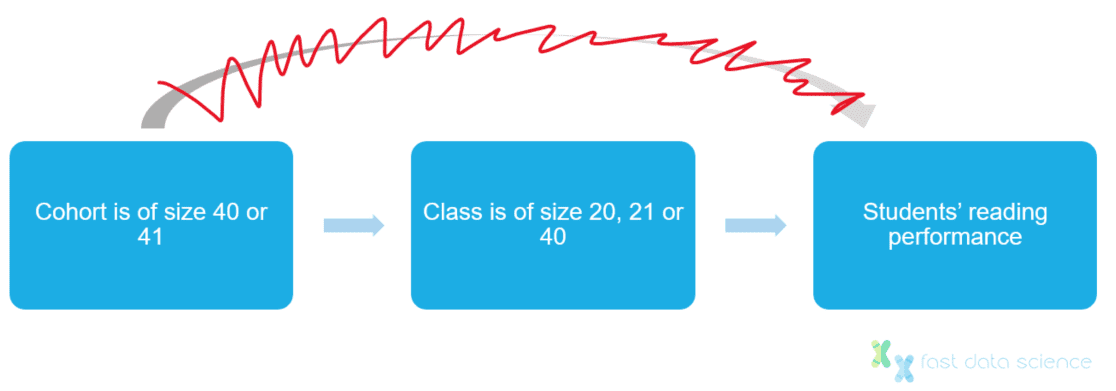
Kohortengrößen um die gesetzliche Schwelle von 40 stehen in keinem Zusammenhang mit dem sozioökonomischen Hintergrund der Eltern, beeinflussen die Lernergebnisse nicht direkt und können daher als Instrumentvariable verwendet werden.
Mit diesem cleveren Trick konnten Angrist und Lavy die Nebenwirkungen einer Verwaltungsregel ausnutzen und eine Analyse durchführen, die fast so aussah, als hätten sie eine randomisierte kontrollierte Studie durchgeführt. Dies ist ein elegantes Beispiel dafür, wie Kausalität manchmal abgeleitet werden kann, selbst wenn der Forscher kein Experiment durchführen kann.
Joshua Angrist arbeitete an einer weiteren Arbeit, in der er die Auswirkungen des Militärdienstes im Vietnamkrieg auf das Lebenseinkommen untersuchte. Dabei stieß er auf ein ähnliches Problem: Menschen mit höherem Bildungsniveau melden sich seltener freiwillig zum Militär und haben tendenziell ein höheres Durchschnittseinkommen, unabhängig davon, ob sie Militärdienst leisten oder nicht.
Glücklicherweise führte die US-Regierung eine Reihe von Wehrpflichtlotterien durch, bei denen Männer nach dem Zufallsprinzip für den Krieg rekrutiert wurden: ein idealer Kandidat für eine Instrumentvariable. Anhand des Anteils der freiwilligen Rekruten, Kriegsdienstverweigerer und aus medizinischen Gründen abgelehnten Personen konnte Angrist abschätzen, dass das Einkommen weißer Veteranen im Vergleich zu Nicht-Veteranen um 15 % zurückging.
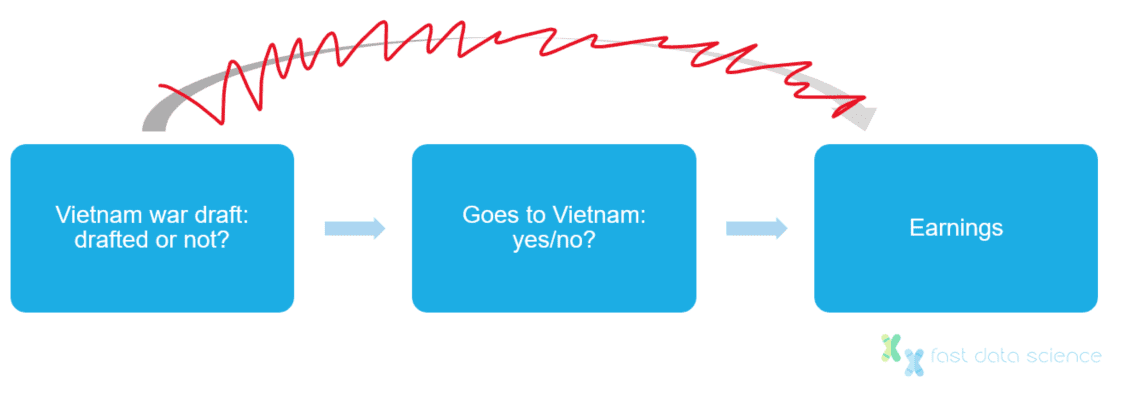
Die Einberufung erfolgt nach dem Zufallsprinzip und hat nur einen direkten Einfluss darauf, ob eine Person nach Vietnam geht oder nicht, hat aber keinen direkten Einfluss auf das Einkommen. Daher könnte die Einberufung als Instrumentvariable verwendet werden, um den Störfaktor zu beseitigen, dass hochgebildete Menschen nicht dazu neigen, sich beim Militär zu melden.
Die oben beschriebenen Ansätze stammen größtenteils aus den Bereichen Statistik und Wirtschaft. Das maschinelle Lernen als Fachgebiet ist jedoch im Allgemeinen nicht-kausal und beschäftigt sich mit intelligenteren und intelligenteren Assoziationen oder Korrelationen zwischen Dingen. Ein modernes neuronales Netzwerk kann beispielsweise Bilder verschiedenen Hunderassen zuordnen oder vorhersagen, wie viel ein Kunde ausgeben wird, versucht aber nicht, das „Warum“ zu klären: Was veranlasst einen Kunden, mehr oder weniger auszugeben?
Im Laufe der Jahre gab es zahlreiche Versuche, kausale Modelle für maschinelles Lernen zu entwickeln oder Kausalität in bestehende Frameworks einzuführen. Viele kausale KI-Mechanismen beinhalten die Erstellung eines Diagramms, das zeigt, wie sich Ereignisse gegenseitig bedingen. Eines der bekanntesten Frameworks sind Bayes-Netze:
Der Informatiker Judea Pearl entwickelte eine ausgeklügelte Methode zur Darstellung kausaler Beziehungen in einem gerichteten Graphen, ein sogenanntes Bayes-Netz. [11] Pfeile werden gezeichnet, wenn zwischen zwei Knoten des Graphen eine kausale Beziehung besteht, obwohl die beobachtete statistische Korrelation nicht von der Richtung des Pfeils abhängt. Bayes-Netze können Konzepte aus der Ökonometrie wie Instrumentvariablen darstellen.
Pearl entwickelte außerdem den „Do-Kalkül“, bei dem zwischen der Wahrscheinlichkeit unterschieden wird, dass ein Student eine Universität besucht, wenn ihm ein Karriere-Coaching angeboten wird:
P(Student besucht Universität | Student erhielt eine Intervention)
und die Wahrscheinlichkeit, dass der Student eine Universität besuchte, vorausgesetzt, dass wir (der Experimentator) eine Intervention erzwungen haben:
P(Student besucht Universität | (Student erhielt eine Intervention))
Bayessche Netze sind leistungsstark, weil sie sehr komplexe Beziehungsnetzwerke darstellen können. Sie werden beispielsweise in der Medizin verwendet, um die Zusammenhänge zwischen Symptomen und Krankheiten darzustellen. Das folgende Netz zeigt beispielsweise ein Bayessches Modell zur Vorhersage der Alzheimer -Krankheit.
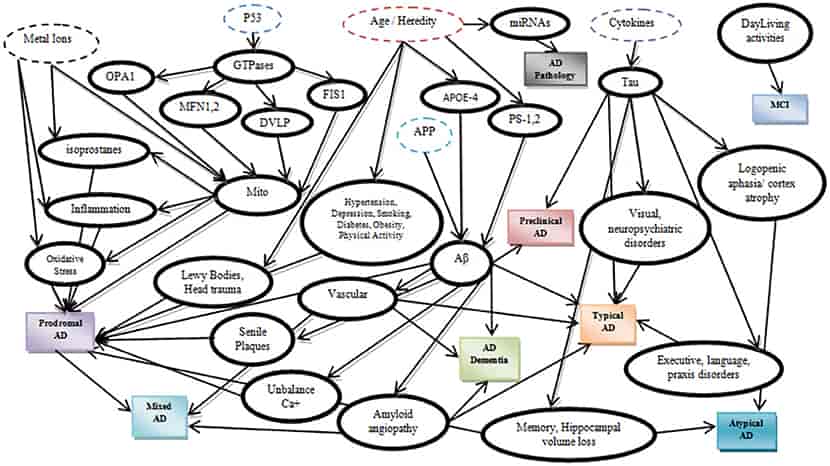
Ein gelerntes Bayes-Netzwerk, das die kausalen Zusammenhänge im Zusammenhang mit der Alzheimer-Krankheit aufzeigt. Bildquelle: [1]
Es ist auch möglich, die Struktur eines Bayesschen Netzwerks zu erlernen. Beispielsweise kommen im Körper Tausende von Proteinen und Genen gleichzeitig vor. Es ist schwierig, die Ursachen- und Wirkungsketten zu erraten, aber mithilfe statistischer Methoden konnten wir die Struktur von Bayesschen Netzwerken erlernen und kausale Zusammenhänge erraten.
Im Jahr 2012 führten einige Epidemiologen eine Studie durch, in der sie die Ursachen von Durchfallerkrankungen bei Kindern in Pakistan untersuchten [8] . Traditionelle Statistiken deckten 12 Variablen auf, die mit Durchfallerkrankungen in Zusammenhang standen, darunter die Anzahl der Zimmer im Haushalt. Diese waren schwer zu interpretieren. Eine Analyse mit einem kausalen Bayes-Netzwerk konnte jedoch eine Netzwerkkarte mit drei Variablen erstellen, die das Auftreten von Durchfallerkrankungen direkt beeinflussten: keine formelle Müllabfuhr, Zugang zu einer Trockengrubenlatrine und Zugang zu einer atypischen anderen Wasserquelle. Die Erkenntnisse aus der Studie könnten einen enormen sozialen Nutzen bringen, wenn sie in die Politik einfließen.
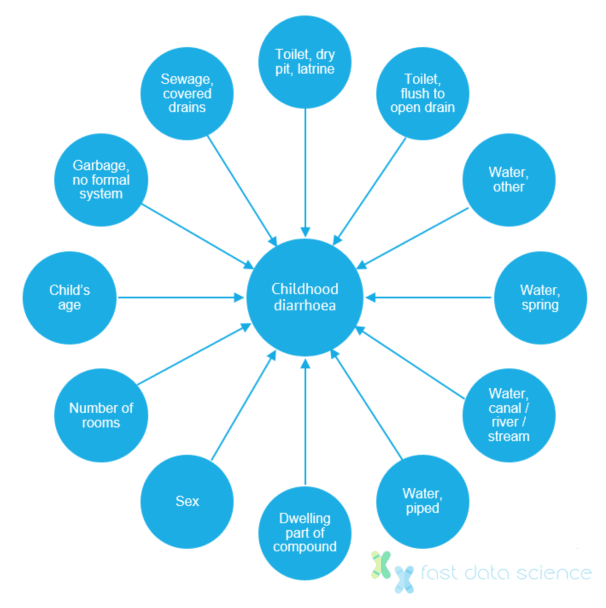
Grafik, die die Zusammenhänge zwischen anderen Faktoren und dem Auftreten von Durchfallerkrankungen bei Kindern zeigt. Mithilfe des Bayesschen Netzwerkansatzes konnten die Epidemiologen drei wahrscheinliche Ursachen für Durchfallerkrankungen identifizieren: keine formelle Müllabfuhr, Zugang zu einer Trockengrubenlatrine und Zugang zu einer atypischen anderen Wasserquelle. Bild adaptiert aus [8] .
Die riesigen Datenmengen, die von Technologiegiganten wie Facebook und Google gesammelt wurden, ebneten den Weg für die Nutzung tiefer neuronaler Netzwerke für Zwecke in allen Branchen , und in der Wissenschaft haben Projekte wie das 1000 Genomes Project über zweihundert Terabyte an Informationen zusammengetragen [12] . Wenn wir fragen möchten, mit wem wir jemandem in einem sozialen Netzwerk Kontakt empfehlen sollen, oder herausfinden möchten, welches Gen mit einer bestimmten Krebsart in Verbindung steht, können wir modernste Modelle maschinellen Lernens wie neuronale Netzwerke einsetzen, um in den Daten nach Assoziationen zu suchen.
Der Zusammenhang zwischen einem Gen und Krebs ist jedoch keine kausale, sondern eine statistische Frage. Tiefe neuronale Netzwerke sind ausgefeilt und leistungsstark, aber der Hype um sie lässt die Tatsache außer Acht, dass sie sich normalerweise nicht mit kausalen Fragen befassen. Kausale Fragen können nicht allein durch Daten beantwortet werden, sondern erfordern ein Modell der Prozesse, die Daten erzeugen.
Wir können beispielsweise ein Modell konstruieren, das angibt, dass ein Gen die Anfälligkeit einer Person für Krebs beeinflussen kann, aber nicht umgekehrt. Dabei müssten wir jedoch die Möglichkeit von Störfaktoren wie einem Mediator berücksichtigen (das Gen beeinflusst ein Verhalten wie Rauchen, das wiederum das Krebsrisiko erhöht). Die Werkzeuge aus der Ökonometrie oder Bayes-Netze können an diese Art von Modell angepasst werden, was ein reales Verständnis davon erfordert, was was beeinflussen kann.
In manchen Fällen ist es möglich, die zeitliche Abfolge von Ereignissen zu nutzen, um kausale Zusammenhänge zu erkennen. Wenn ein Schüler beispielsweise eine Karriereintervention erhält und ein Jahr später eine Universität besucht, kann der Universitätsbesuch die Karriereintervention nicht beeinflussen. Eine beliebte Methode zur Nutzung von Zeitreihen ist die sogenannte Granger-Kausalität. Dabei wird die Zeit verschiedener Ereignisse genutzt, um zu bestimmen, welches Ereignis das andere Ereignis besser erklärt.
Bestärkendes Lernen ist ein Bereich der KI, der zum Erlernen der Interaktion mit einer Umgebung verwendet wird, wie etwa eine Schach spielende KI oder ein selbstfahrendes Auto. Eine KI wird als „Agent“ betrachtet, der Aktionen ausführen kann, die zu einer Belohnung führen. Der Algorithmus des bestärkenden Lernens ermöglicht es dem Agenten, manchmal die optimale Aktion auszuführen (den Springer zu nehmen), manchmal aber auch zu „erkunden“ (eine Figur mit geringerem Wert zu nehmen), um eine bessere Strategie für die Zukunft zu erlernen. Obwohl bestärkendes Lernen in gewissem Sinne von Natur aus kausal ist, wurden die Algorithmen des bestärkenden Lernens in jüngster Zeit modifiziert, um die Komplexität bayesscher Netze zur Handhabung von Störfaktoren und anderen Effekten zu integrieren.
Mein besonderes Interessengebiet ist die Verarbeitung natürlicher Sprache ( NLP ) und ich werde ein wenig darüber schreiben, wie wir NLP in der Kausalität verwenden können.
Die meisten NLP- Anwendungen in der Industrie werden für Vorhersagen verwendet. Wenn Sie beispielsweise den Lebenslauf eines Arbeitssuchenden kennen, wie hoch ist dessen wahrscheinlichstes Gehalt? An welche Abteilung soll eine eingehende E-Mail weitergeleitet werden?
Es gibt jedoch keinen Grund, warum die Variablen in einem Ursache-Wirkungs-Szenario numerisch sein müssen. Ein Textfeld könnte als Ursache eines numerischen Felds auftreten, sich als Wirkung manifestieren oder sogar als Instrumentvariable verwendet werden.
Ein Vorhersagemodell zur Einstufung von Arbeitssuchenden in Gehaltsgruppen würde einen Zusammenhang zwischen beiden entdecken. Aber ist der Wortlaut Ihres Lebenslaufs für Ihr Gehalt verantwortlich, oder sind Inhalt und Gehaltswert beide das Ergebnis einer gemeinsamen Ursache wie z. B. Berufsjahre? In diesem Bereich ist ein gewisses Maß an Experimenten möglich. Im Jahr 2004 schickten Marianne Bertrand und Sendhil Mullainathan gefälschte Lebensläufe an Arbeitgeber in Boston und Chicago und wiesen ihnen nach dem Zufallsprinzip Namen zu, die afroamerikanisch oder weiß klangen. Sie fanden heraus, dass die weißen „Kandidaten“ 50 % häufiger zu Vorstellungsgesprächen eingeladen wurden. [5] Wenn sich jedoch ein kausales Modell auf Textfelder übertragen lässt, können wir aus Beobachtungsdaten lernen, anstatt Interventionen durchführen zu müssen.
Ein Beispielfall, in dem wir die Kausalität verstehen möchten, wobei die Ursache ein Textfeld ist, ohne ein Experiment durchzuführen, ist wie folgt:
Benutzer veröffentlichen Kommentare in einem Online-Forum. Jeder Benutzer hat in seinem Profil ein Geschlechtssymbol: ♂ oder ♀. Benutzer mit der Kennzeichnung ♀ erhalten tendenziell weniger Likes. Sind die geringeren Likes auf das Symbol oder auf den Inhalt des Textes zurückzuführen? [6]
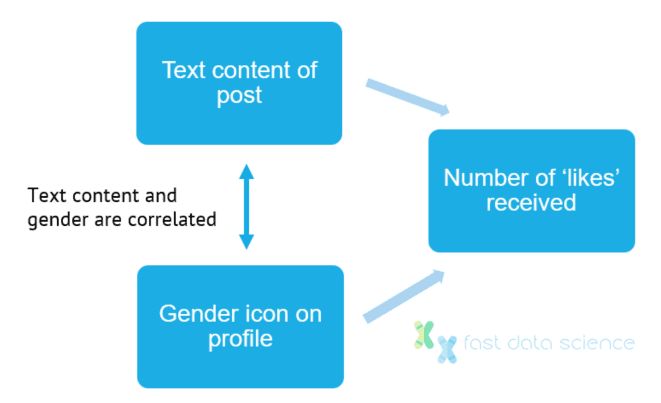
Es ist schwierig, die Auswirkungen des Profilsymbols von den Eigenschaften des Textinhalts zu trennen, da beide vom Geschlecht des Benutzers beeinflusst werden. Kausale maschinelle Lerntechniken können die Ideen hinter den Instrumentvariablen verallgemeinern, um die Störfaktoren zu beseitigen.
Für diese Art von Problemen gibt es eine Reihe von Lösungen.
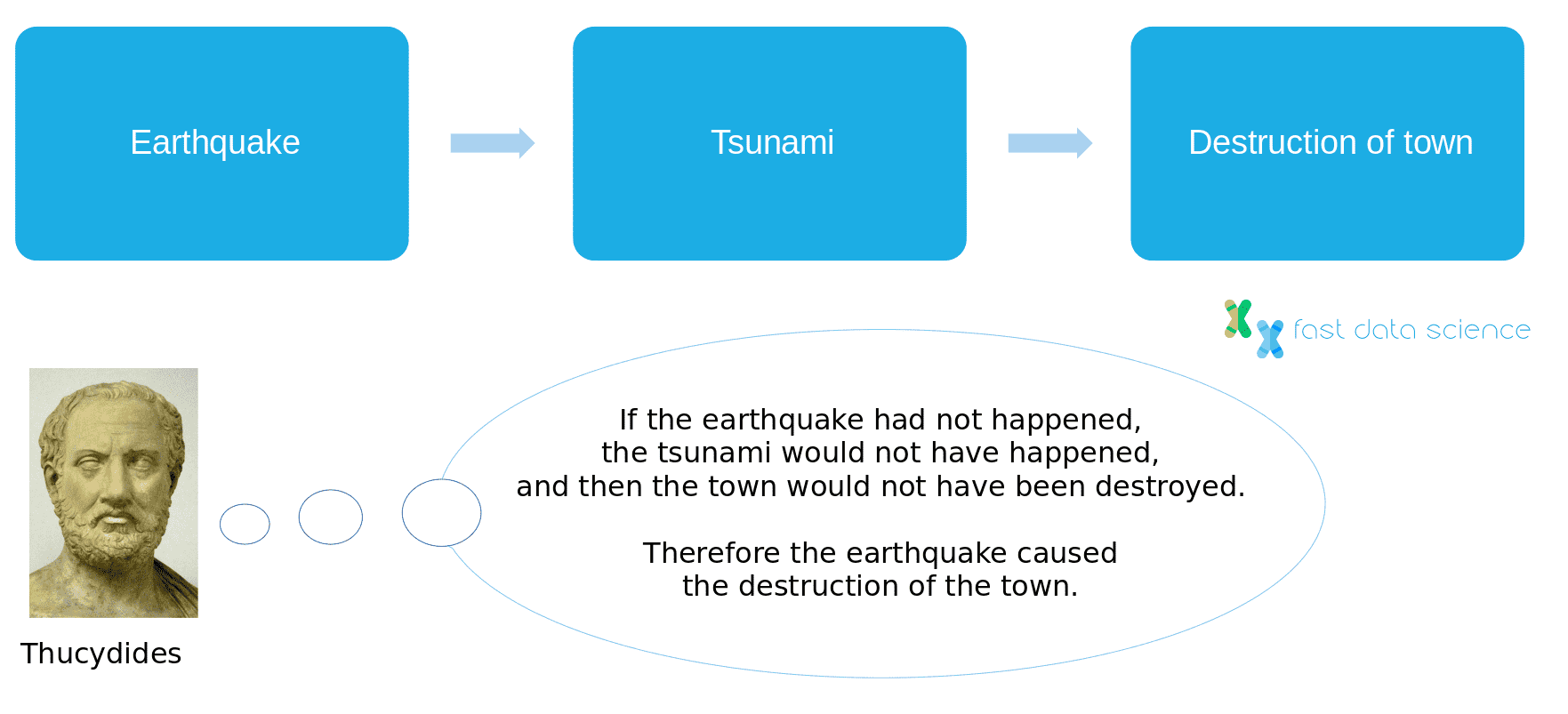
Ich empfehle die Lektüre von The Book of Why [ [12]](#references) von Judea Pearl, das sich aus vielen Blickwinkeln mit der Kausalität befasst. Einer der interessanten Punkte, die Pearl anführt, ist, dass wir im Laufe der Geschichte nicht immer eine eindeutige Definition von Kausalität hatten. So beschrieb der griechische Historiker Thukydides beispielsweise einen Vorfall, bei dem ein Erdbeben einen Tsunami verursachte, der 426 v. Chr. eine Stadt zerstörte. Thukydides kam zu dem Schluss, dass das Erdbeben die eigentliche Ursache für die Zerstörung der Stadt gewesen sei, weil
ἄνευ δὲ σεισμοῦ οὐκ ἄν μοι δοκεῖ τὸ τοιοῦτο ξυμβῆναι γενέσθαι….
Ohne Erdbeben kann ich mir nicht vorstellen, dass so ein Unglück passieren könnte.
Geschichte des Peloponnesischen Krieges, Thukydides, frühes viertes Jahrhundert v. Chr. [14]
Dies ist eine Definition einer Ursache: Wir stellen uns ein Paralleluniversum vor, in dem das erste Ereignis nicht stattgefunden hat, und stellen uns vor, was die Folge gewesen wäre. Das imaginäre „Was-wäre-wenn“-Szenario wird als kontrafaktisches Szenario bezeichnet.
Interessanterweise definierte der schottische Philosoph David Hume viele Jahrhunderte später Kausalität als die Verbindung zwischen zwei Ereignissen, die regelmäßig hintereinander auftreten. Daraus schließen wir, dass eine Flamme Hitze erzeugt, weil wir jedes Mal, wenn wir eine Flamme sehen, Hitze spüren, wenn wir sie berühren. Dies nennt man die Regelmäßigkeitsdefinition von Kausalität.
Neun Jahre später überarbeitete Hume seine Definition der Kausalität von der Regularitätsdefinition zurück zur kontrafaktischen Definition und stellte fest, dass wir Kausalität dort folgern können, wo
wenn das erste Objekt nicht gewesen wäre, hätte das zweite nie existiert
David Hume, Untersuchung über den menschlichen Verstand [16]
Nach weiteren Überlegungen entschied sich Hume für Thukydides’ Definition der Kausalität. Heute ist die am weitesten verbreitete Definition der Kausalität die kontrafaktische Definition, obwohl sie viele andere Fragen aufwirft (stellen wir uns ein Universum vor, in dem ein Ereignis nicht stattgefunden hat, aber alles andere identisch ist? Welches Universum wählen wir, wenn es mehrere Kandidaten gibt?).
Nachdem ich über die kontrafaktische Definition von Kausalität gelesen hatte, fragte ich mich, warum viele europäische Sprachen unterschiedliche Verbformen verwenden, um Ereignisse, die definitiv nicht eingetreten sind, von Ereignissen zu unterscheiden, die tatsächlich eingetreten sind oder eingetreten sein könnten. Im Spanischen wird beispielsweise eine „Was-wäre-wenn“-Bedingungsaussage für ein kontrafaktisches Szenario mit der Formel gebildet
si (‘wenn’) + Verb im Konjunktiv im Perfekt + Konditional
zum Beispiel si no hubiera llovido, no me habría mojado („wenn es nicht geregnet hätte, wäre ich nicht nass geworden“), wobei hubiera die imperfekte Konjunktivform des Verbs ist und ein Szenario bezeichnet, das nicht stattgefunden hat. Wenn der Sprecher es für wahrscheinlich oder möglich hält, dass es geregnet hat, sagt er si ha llovido und verwendet ha anstelle von hubiera .
Im Englischen verwenden wir die Vergangenheitsform mit „ had“ eher für Ereignisse, die nicht stattgefunden haben (kontrafaktische Aussagen), und andere Formen wie die Vergangenheitsform mit „have“ für Ereignisse, die stattgefunden haben:
‘if’ + Präteritum mit had + Konditional mit would have
Wir haben also „wenn es nicht geregnet hätte, wäre ich nicht nass geworden“ (es hat nicht geregnet), im Gegensatz zu „wenn es nicht geregnet hat, werde ich nicht nass“ (es hätte regnen können). Ein weiteres Beispiel für diese Unterscheidung ist die Verwendung von „were“ in Ausdrücken wie „wenn ich du wäre “ oder „wenn er reich wäre “ – die Wahl von „were“ statt „ was“ in diesen Sätzen zeigt dem Zuhörer an, dass wir uns eine Welt vorstellen, in der jemand reich ist, der in unserer Welt nicht reich ist.
Auch im Deutschen, Französischen und Italienischen gibt es Konjunktiv-Verbformen, während im Chinesischen verschiedene Partikel im Satz verwendet werden, um zwischen kontrafaktischen und nicht-kontrafaktischen Bedingungen zu unterscheiden [15] . Allerdings variiert die Definition, welche hypothetischen Szenarien spezielle Verbformen erfordern, geringfügig zwischen den Sprachen - nicht alle spanischen Konjunktivsätze erfordern im Italienischen einen Konjunktiv und umgekehrt. Im Chinesischen sind die kontrafaktischen grammatischen Partikel meist optional.
Die Tatsache, dass kontrafaktische Aussagen in die Grammatik unserer Sprachen eingebrannt sind, ist interessant, denn sie zeigt, dass Kausalität für uns zwar schwer zu verstehen sein kann (wenn Kausalität leicht zu verstehen wäre, wäre das Simpson-Paradoxon kein Paradoxon!), sie aber ein wesentlicher Teil unserer Denk- und Kommunikationsweise ist.
Kinder im Alter von 6 bis 8 Jahren beherrschen normalerweise die Zeitformen ihrer Muttersprache. Für mich bedeutet das, dass selbst kleine Kinder in der Lage sind, Kontrafaktuale intuitiv zu verstehen und zu begreifen. 2019 führte Keito Nakamichi ein Experiment durch, um genau dies zu untersuchen, und fand heraus, dass Vier- bis Sechsjährige in der Lage sind, über Kontrafaktuale nachzudenken, die mit emotionalen Ereignissen verbunden sind, nicht aber mit physischen Ereignissen. [17]
Ich habe mit meinen Sechsjährigen ein sehr unwissenschaftliches Experiment durchgeführt und dabei festgestellt, dass sie kontrafaktische Sätze zwar richtig beantworten konnten, die Syntax von were / would jedoch nicht richtig verwendeten und stattdessen manchmal will verwendeten. Sie bildeten ungrammatische Sätze wie * if James’s parents didn’t die, he will live with them by the seaside , was zeigt, dass sie die kontrafaktischen Sätze verstanden, aber die Verbformen des Konditionals und Konjunktivs nicht beherrschten.
Kausalitätsmodelle werden immer häufiger und Datenwissenschaftler benötigen zunehmend ein grundlegendes Verständnis der Kausalitätstheorie. Traditionelle Modelle des maschinellen Lernens konzentrieren sich auf Korrelation, aber in Fällen wie dem Beispiel der Schüler, die eine Berufsberatungsintervention erhalten, wird ein maschineller Lern- oder Statistikansatz, der die Kausalität ignoriert, irreführende Ergebnisse liefern, beispielsweise den Eindruck, dass eine Berufsberatungsintervention sich nachteilig auf einen Schüler auswirkt, der an einer Universität studiert. Wenn die Interventionen selbst auf Schüler abzielen würden, die Gefahr laufen, ihr Studium abzubrechen, wäre diese Schlussfolgerung eindeutig unsinnig.
Es gibt zwei Denkschulen für kausale Modelle: die älteren Methoden aus der Ökonometrie und den Sozialwissenschaften und die neueren Modelle aus der Informatik wie Bayessche Netze. Ein kausales Modell kann jedoch nicht rein datengesteuert sein, sondern muss so konzipiert sein, dass es das Verständnis seines Erstellers für die vorhandenen kausalen Mechanismen berücksichtigt, wie z. B. Einberufung in den Vietnamkrieg ➜ Einberufung in die Armee ➜ Lebenseinkommen .
Kausalitätsmodelle werden in den Sozialwissenschaften seit mindestens den 1930er Jahren verwendet, während die Verarbeitung natürlicher Sprache in der Industrie vor allem im letzten Jahrzehnt aufgrund von Fortschritten bei der Datenmengengröße und der Rechenleistung weit verbreitet ist. Forscher und Branchenführer fragen sich erst seit kurzem, wie Kausalität und NLP kombiniert werden können. Die jüngsten Durchbrüche bei immer ausgefeilteren Vektordarstellungen von Text und die Verbreitung leicht zugänglicher Textdatensätze lassen darauf schließen, dass wir in naher Zukunft mehr Diskussionen über NLP und Kausalität erwarten können.
Entfesseln Sie das Potenzial Ihrer NLP-Projekte mit dem richtigen Talent. Veröffentlichen Sie Ihre Stelle bei uns und ziehen Sie Kandidaten an, die genauso leidenschaftlich über natürliche Sprachverarbeitung sind.
NLP-Experten einstellen
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you
{kind=link}