
Ist es möglich, mithilfe der Verarbeitung natürlicher Sprache (NLP) zwischen unerwünschten Verkaufsansprachen und vielversprechenden Leads für das Kundenbeziehungsmanagement eines Unternehmens zu unterscheiden? Wenn ja, wäre dies eine großartige Anwendung von KI in Unternehmen .
Ich erhalte jede Woche eine Reihe unaufgeforderter Geschäftsanfragen und es fällt mir oft schwer, zu erkennen, wer sich wegen einer Geschäftsbeziehung oder mit einem echten Problem im Bereich maschinelles Lernen an mich wendet, bei dem ich helfen kann, und wer mir etwas verkaufen möchte. Oft verwenden die Verkäufer Ausdrücke wie „Partnerschaft“, anstatt direkt zu sagen, dass sie mir ein Produkt oder eine Dienstleistung verkaufen möchten, und daher ist es nicht immer einfach herauszufinden, wer wer ist.
Manchmal wurde ich überrascht. Ich habe zum Beispiel angenommen, dass eine E-Mail eine Verkaufsanfrage war, und dann hat mich die Person später angerufen und sich als echter Geschäftsinteressent herausgestellt. Bei anderen Gelegenheiten habe ich eine halbe Stunde mit jemandem gesprochen, bevor mir klar wurde, dass er mir ein Produkt verkaufen wollte. Diese Unterscheidung ist also selbst für einen Menschen sehr schwierig.
Ich habe ein maschinelles Lernmodell entwickelt und trainiert, um zwischen potenziellen Geschäftsaussichten und wahrscheinlichen Verkaufsansätzen zu unterscheiden, und ich habe es so eingerichtet, dass es mir eine SMS sendet, wenn eine echte Geschäftsaussicht erkannt wird.
Ich habe versucht, Customer-Relationship-Management-Software (CRM) wie Salesforce , Monday.com und HubSpot zu verwenden. Diese sind sehr gut für die Verwaltung von Leads geeignet, unterscheiden aber nicht zwischen guten und schlechten Interessenten. Mit der Software können Sie Leads erstellen, aber sie bewertet nicht die Chance, dass aus diesen Leads ein Verkauf wird (zumindest habe ich diese Funktion nicht gefunden).
Nachdem ich die Frustration der CRMs erlebt hatte, kam ich auf die Idee, ein maschinelles Lernmodell zu erstellen, um meine eingehenden E-Mails mithilfe von NLP zu klassifizieren.
Ich habe alle neuen Kontaktanfragen in meinem Gmail ausgewählt und dann Google Takeout verwendet, um die Nachrichten auf meinem Computer zu speichern.
Ich habe 149 unerwünschte Nachrichten gespeichert. Auf 31 davon habe ich geantwortet, das heißt, 31 davon waren für mich interessant, und die restlichen 118 waren hauptsächlich Leute, die versuchten, mir Produkte zu verkaufen.
Ein kleiner Datensatz von 149 Dokumenten reicht für ein neuronales Netzwerk oder einen Deep-Learning-Ansatz nicht aus. Daher habe ich einen Naive-Bayes-Klassifikator verwendet, der zur Entscheidungsfindung einfach das Vorhandensein oder Fehlen von Wörtern in Dokumenten verwendet. Dieses Modell ignoriert Wortreihenfolge und Syntax, weshalb es manchmal auch als „Bag of Words“-Modell bezeichnet wird, da jedes Dokument auf einen Sack ungeordneter Wörter ohne Kontext reduziert wird.
Ich habe festgestellt, dass die Topthemen bei den echten Leads (also den Personen, die als potenzielle Kunden erscheinen) oft Formulierungen wie „wir suchen“ oder „wir haben ein Projekt“ sind – Personen, die daran interessiert sind, eine Dienstleistung von mir zu kaufen, beschreiben also sehr direkt und prägnant, was sie benötigen und wie schnell sie es brauchen.
Interessanterweise verwenden diese Personen auch eher meinen Namen oder erwähnen Fast Data Science namentlich. Beispiel: „Lieber Thomas, wir haben ein dringendes Projekt zur Verarbeitung natürlicher Sprache, für das wir X benötigen – hätten Sie diese Woche Zeit für ein Gespräch?“
Fast Data Science - London
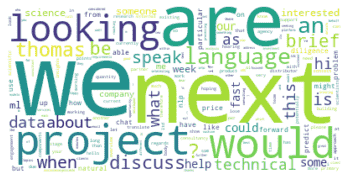
Wortwolke der wichtigsten Wörter, die darauf hinweisen, dass eine Nachricht ein vielversprechender Hinweis für eine Folgenachricht ist
Auf der anderen Seite verwenden die Nicht-Leads, bei denen es sich meist um Verkäufer und Arbeitssuchende handelt, häufig Ausdrücke wie „meine Dienste“ und „unser SEO-Geschäft“ und fügen viele Links ein. Beispiel: Sehr geehrte Damen und Herren, ich bin SEO-Experte und möchte einen Artikel für Ihre Website schreiben .
Diese Leute neigen dazu, allgemeinere Begrüßungen zu verwenden, anstatt meinen Namen oder den Namen meiner Firma explizit zu verwenden, und sprechen mehr über sich selbst und die Dienstleistungen, die sie anbieten.
Für eine Person ist ihr Name der schönste und wichtigste Klang in jeder Sprache.
Dale Carnegie, „Wie man Freunde gewinnt und Menschen beeinflusst“ (ein Bestseller-Selbsthilfebuch, das erstmals 1939 veröffentlicht wurde und häufig zur Schulung von Verkäufern verwendet wird)
Die folgende Wortwolke fasst die wichtigsten Begriffe der nicht-lead-Ansätze zusammen:

Wortwolke der wichtigsten Begriffe, die darauf hinweisen, dass es sich bei einer Nachricht eher um eine Verkaufsansprache als um einen Lead handelt. Sie können sehen, dass Pronomen der ersten Person und Links bei Verkaufsansprachen häufiger vorkommen als bei echten Leads.
Als ich meinen Klassifikator anhand von 80 % der Daten trainierte und an den verbleibenden 20 % testete, erreichte er eine Genauigkeit von 61 % bei der Identifizierung vielversprechender Hinweise – die ROC-Kurve ist unten dargestellt.
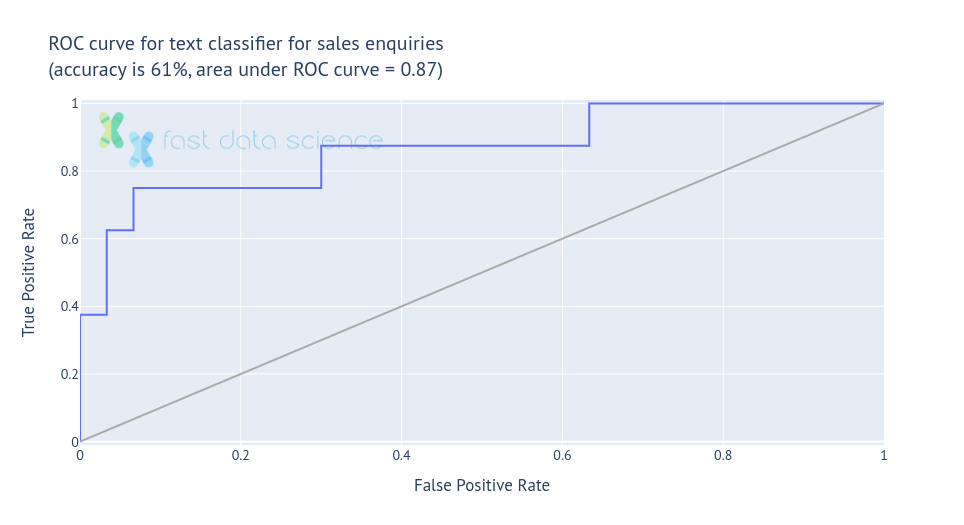
Ich habe festgestellt, dass ich, wenn ich nur 149 E-Mails ohne jegliche Anpassung verwendete, einen Textklassifizierer erhielt, der die meisten Leads als nutzlos klassifizierte. Da die meisten Beispiele, die der Klassifizierer während des Trainings sieht, keine Leads sind, ist der Klassifizierer am Ende etwas konservativ und neigt dazu, fast alles als „uninteressant“ zu klassifizieren.
Um dem entgegenzuwirken, habe ich den Trainingsdaten einige zusätzliche Kopien der „interessanten“ E-Mails hinzugefügt, was zu einem ausgewogeneren Datensatz führte. Diese Technik wird Upsampling genannt und ist eine der vielen Möglichkeiten, mit denen wir Klassenungleichgewichte beim maschinellen Lernen bekämpfen können.
Als ich die Daten hochskalierte, ging die Leistung meines Modells etwas zurück, aber ich stellte fest, dass das Modell als Klassifikator praktischer zu verwenden war, da es nicht dazu neigte, so viele vielversprechende Verkaufskontakte zu übersehen.
Die naheliegende Frage, die sich anschließend stellte, war: Ist es möglich, mithilfe eines Textklassifikators das endgültige Ergebnis einer Geschäftsbeziehung vorherzusagen, also den Gesamtrechnungsbetrag?
Ich habe versucht, meine Leads über mein CRM mit meinen Rechnungsdaten zu verknüpfen. Ich konnte einen Textklassifizierer trainieren, allerdings waren die Daten zu diesem Zeitpunkt sehr spärlich (da die meisten Dialoge nicht zu einem Verkauf führten) und der Klassifizierer funktionierte nicht sehr gut. Ein größeres Unternehmen wäre jedoch definitiv in der Lage, ein Lead-to-Revenue-Prognosemodell zu erstellen.
Neben sprachlichen Merkmalen gibt es eine Reihe weiterer Merkmale, die auf das Potenzial eines Verkaufsinteressenten hinweisen können. Dazu gehören
Ich habe versucht, mein Textklassifizierungsmodell mithilfe von Azure Functions live im Web statt auf meinem Laptop laufen zu lassen (bereitzustellen). Azure Functions ist eine schöne, einfache Lösung, da ich bei jeder Verwendung des Modells nur ein paar Cent zahle – ich muss nicht für die Zeit zahlen, in der es nicht verwendet wird.
Ich habe das Tool Zapier so eingerichtet, dass es eingehende E-Mails auf Verkaufskontakte überwacht und mir eine SMS sendet, wenn eine Nachricht mit einer Wahrscheinlichkeit von über 20 % einen potenziellen Geschäftskontakt darstellt. Mal sehen, was daraus wird.
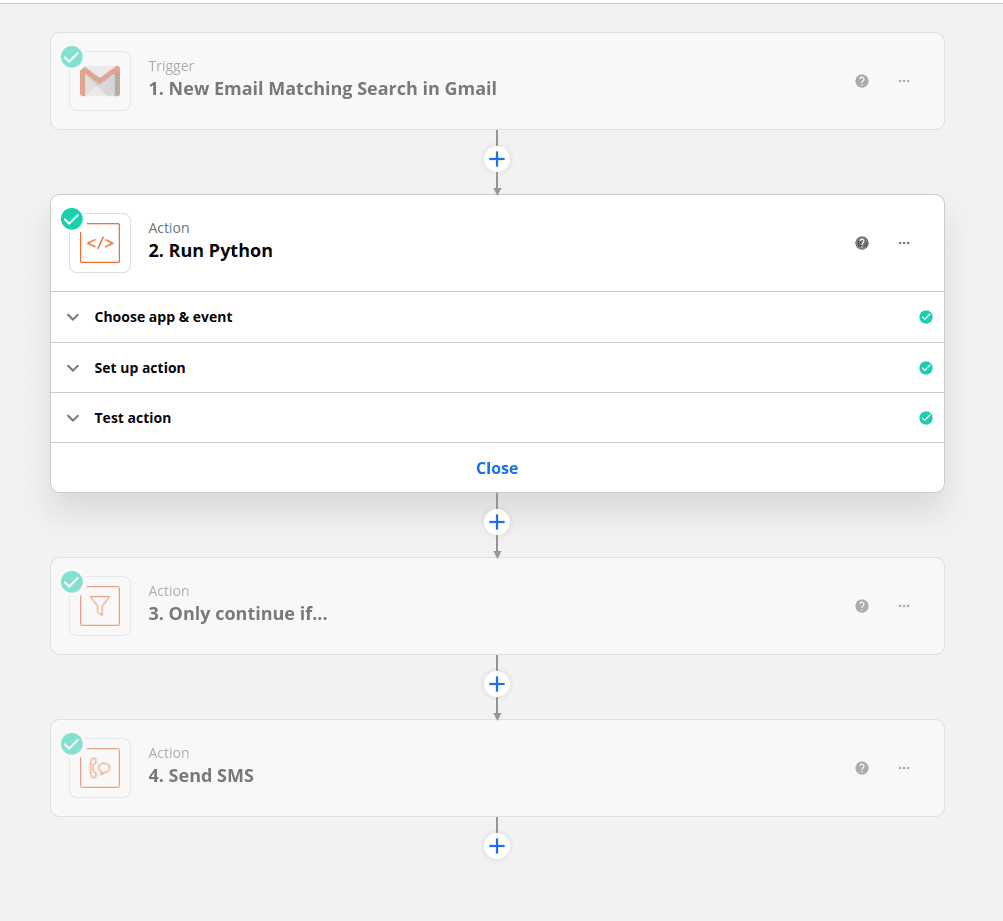
Zapier ist eine Website, die es Ihnen ermöglicht, mithilfe einer No-Code-Schnittstelle Aktionen wie das Senden einer SMS unter bestimmten Bedingungen einzurichten. Hier ist mein Ablauf, um mir selbst eine Benachrichtigung zu senden, wenn ein vielversprechender Lead eingeht.

Ich begann, SMS-Benachrichtigungen für vielversprechende Verkaufskontakte zu erhalten, einschließlich Wahrscheinlichkeiten. Dies ist ein Screenshot einiger meiner SMS-Benachrichtigungen für die potenziellen Kontakte.
Ich habe etwa eine Stunde gebraucht, um einen Textklassifizierer zu bauen, der zwischen unerwünschten Verkaufsansprachen und vielversprechenden Leads unterscheidet, und noch einmal etwa eine Stunde, um ihn so zu verbinden, dass ich per SMS auf vielversprechende Verkaufsleads aufmerksam gemacht werde.
Viele der textbasierten Merkmale, die sich aus dem Training dieses Modells ergeben haben, lassen sich gut verallgemeinern und sind nicht spezifisch für Fast Data Science oder die Beratungs- und Technologiebranche.
Korrespondenten, die über sich selbst oder ihr Unternehmen sprechen, verkaufen wahrscheinlich etwas, während diejenigen, die über mich, meine Arbeit oder mein Unternehmen sprechen, eher etwas von mir kaufen möchten. Ich könnte mir vorstellen, dass Geschäftsleute in anderen Branchen ähnliche Beobachtungen gemacht haben.
Korrespondenten, die „Partnerschaften“ erwähnen, sind besonders schwierig einzuordnen, da diese Formulierung von einigen echten Kunden verwendet wird, aber auch von Verkäufern genutzt zu werden scheint, um einen Verkaufsansatz zu verschleiern.
Da Software für das Kundenbeziehungsmanagement immer ausgefeilter wird, könnten wir einen Trend hin zu einer Nutzung künstlicher Intelligenz in der gesamten Vertriebspipeline und einer Verfügbarkeit als Standardbestandteil der CRM-Software erleben.
Es wäre wunderbar, wenn ein CRM eingehende Leads anhand linguistischer Merkmale als hohe oder niedrige Konvertierungswahrscheinlichkeit kennzeichnen könnte, sodass sich die Vertriebsteams auf potenzielle Kunden mit einer höheren Konvertierungswahrscheinlichkeit oder einem höheren erwarteten Umsatz konzentrieren oder den Umsatz pro Arbeitsstunde maximieren könnten.
Mir ist kein CRM-Paket bekannt, das diese Analyseebene standardmäßig bietet, aber ich würde gerne mehr darüber erfahren, falls Sie jemanden kennen, der diesen Ansatz verfolgt. Bitte kontaktieren Sie mich , ich würde mich freuen, von Ihnen zu hören.
Bereit für den nächsten Schritt in Ihrer NLP-Reise? Vernetzen Sie sich mit Top-Arbeitgebern, die Talente in der natürlichen Sprachverarbeitung suchen. Entdecken Sie Ihren Traumjob!
Finden Sie Ihren Traumjob
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you