
Viele Anwendungen des maschinellen Lernens in Unternehmen sind komplex, aber wir können viel erreichen, wenn wir das Risiko auf einer additiven Skala von 0 bis 10 bewerten. Dies ist ein Mittelweg zwischen der Verwendung komplexer Black-Box-Modelle wie neuronaler Netzwerke und der traditionellen menschlichen Intuition.
Stellen Sie sich vor, Sie hätten die Aufgabe, die Abschlusschancen eines Gymnasiasten vorherzusagen. Wem würden Sie mehr vertrauen: der Vorhersage des Klassenlehrers des Schülers oder einem Bewertungsrezept wie dem folgenden?

Hypothetischer Bewertungsalgorithmus für einen High-School-Schüler zur Vorhersage des Risikos, seinen Abschluss nicht zu machen.
Im Jahr 1954 schrieb der Psychologe Paul Meehl ein bahnbrechendes Buch mit dem Titel „Clinical Versus Statistical Prediction: A Theoretical Analysis and a Review of the Evidence“. Darin verglich er die Genauigkeit klinischer Vorhersagen von medizinischem Fachpersonal mit der Genauigkeit statistischer Vorhersagen, die auf Bewertungen und Algorithmen basieren. Dabei stellte er fest, dass die numerischen Bewertungsmethoden die von menschlichem Fachpersonal übertrafen.
In den Jahren seit Meehls Veröffentlichung haben sich Algorithmen für viele Probleme weit verbreitet, bei denen professionelle Intuition zwar wertvoll ist, aber auch ein hohes Maß an Unsicherheit und Unvorhersehbarkeit besteht.
Es hat sich gezeigt, dass Algorithmen der Intuition von Experten überlegen sind, wenn es um die Vorhersage der Dauer von Krankenhausaufenthalten, die Diagnose von Herzkrankheiten, das Risiko von Rückfällen in die Kriminalität und die Anfälligkeit von Babys für den plötzlichen Kindstod geht, um nur einige zu nennen.
Tatsächlich sind Checklisten, Bewertungen und Algorithmen in etwa 60 Prozent der Fälle der menschlichen Intuition durchaus überlegen (siehe das hervorragende Buch „Schnelles Denken, langsames Denken“ von Daniel Kahneman, der 2002 für seine Arbeit über die Anwendung psychologischer Erkenntnisse auf die Wirtschaftstheorie den Nobelpreis für Wirtschaftswissenschaften erhielt. Es enthält ein interessantes Kapitel mit dem Titel „Algorithmen vs. Intuition“ ).
Eine Universität kontaktierte uns, weil sie mehr über die Abbruchquote ihrer Studenten wissen wollte. Ich fragte den Studentenbeauftragten der Universität, was seiner Meinung nach die Hauptfaktoren für das Abbrechen von Studenten seien, und er sagte mir, dass das Haushaltseinkommen , Alleinerziehende und die Noten der Studenten die Hauptfaktoren seien.
Wir erhielten eine anonymisierte Datenbank mit den Studentenlisten über mehrere Jahre hinweg, zusammen mit Informationen zu den Noten der Studenten, Bewerbungsdaten und Daten zum sozioökonomischen Hintergrund der Studenten. Die Organisation verfügte über ein System, bei dem Studenten, bei denen das Risiko eines Studienabbruchs festgestellt wurde, von einem Studienberater kontaktiert wurden, der ihnen Unterstützung anbot und versuchte, sie wieder auf den richtigen Weg zu bringen. Es war nicht möglich, jedem Studenten eine Einzelintervention zu geben, daher mussten diese Interventionen gezielt erfolgen.
Für den Bildungsanbieter war auch die Tatsache wichtig, dass staatliche Fördermittel auf Grundlage der Gesamtzahl der Studenteneinschreibungen bis zu einem bestimmten Stichtag zugeteilt werden. Ziel der Studie war es daher, die Ursachen für die Studentenabwanderung zu verstehen und die Studentenabwanderung sowohl insgesamt als auch zu bestimmten Stichtagen zu reduzieren.
Wir haben versucht, eine Reihe verschiedener prädiktiver Modelle für maschinelles Lernen zu erstellen, darunter einen vollständigen Blackbox-Ansatz wie Microsoft Azure Machine Learning (eine Drag-and-Drop-Schnittstelle für maschinelles Lernen), Random Forest und ein einfaches lineares Regressionsmodell .
Das lineare Regressionsmodell ergab das folgende Bewertungsrezept:

Dieses lineare Bewertungsmodell ist eine effektive geschäftliche Anwendung des maschinellen Lernens .
Diese Punktzahl ergibt einen Minimalwert von 0 und einen Maximalwert von 100.
Überraschenderweise übertraf dieser Wert, der von der Schulverwaltung mit Stift und Papier oder in Excel ermittelt werden kann, die ausgefeilteren Modelle des maschinellen Lernens. Er erwies sich auch als präziser als das derzeitige System der Einrichtung, das Interventionen auf der Grundlage der Intuition der Lehrer ausrichtet.
Schön ist auch, dass die Punktzahl in eine Sigmoidfunktionsformel eingespeist und in eine Wahrscheinlichkeit (zwischen 0 und 1) umgerechnet werden kann, mit der der Student seinen Kurs abschließt.
Sie können mit einigen Werten in der folgenden Tabelle experimentieren. Können Sie einen Studenten simulieren, der den Kurs mit hoher Wahrscheinlichkeit abschließen oder abbrechen wird?
| Attribute | Weight (B) | Input for this student (C) | Score (D) | Formula for column D |
|---|---|---|---|---|
| start at score | 40 | 1 | 40 | =B2*C2 |
| good grades | 5 | 5 | =B3*C3 | |
| low household income | -10 | 0 | =B4*C4 | |
| single parent family | -10 | 0 | =B5*C5 | |
| age above 18 at start of course | 5 | 20 | =B6*C6 | |
| student applied early | 35 | 35 | =B7*C7 | |
| student applied late | -10 | 0 | =B8*C8 | |
| student had poor attendance | -10 | 0 | =B9*C9 | |
| TOTAL SCORE | =SUM(D2:D9) | =SUM(D2:D9) | ||
| probability of dropping out of course | =1/(1+EXP(D10*0.04-0.3)) | =1/(1+EXP(D10*0.04-0.3)) |
Wenn Sie einen Studenten mit guten Noten, hohem Haushaltseinkommen usw. erstellen, sollten Sie in der Lage sein, einen Studenten mit der Punktzahl 100 zu erstellen. Wenn Sie hingegen alle Werte außer denen mit negativer Gewichtung ( niedriges Haushaltseinkommen, Alleinerziehende, Student hat sich spät beworben, Student hatte schlechte Anwesenheit ) auf 0 setzen, können Sie eine Punktzahl von 0 ausgeben, was einen Hochrisikostudenten darstellt.
Unseren Berechnungen zufolge könnte die Bildungseinrichtung ihre Abschlussquote deutlich steigern, wenn bei den 15 % der Studierenden mit den schlechtesten Leistungen eine gezielte Intervention durchgeführt würde.
Ich kann mir vorstellen, dass ein ähnliches Modell zur Vorhersage der Mitarbeiterfluktuation entwickelt werden könnte.
Ein wichtiger Bestandteil des Lead-Managements für Unternehmen ist ein Lead-Scoring-Modell. Insbesondere B2B-Unternehmen müssen in der Lage sein, eingehende Leads zu bewerten und zu klassifizieren, und zwar auf der Grundlage der Wahrscheinlichkeit, dass sie zu Kunden werden und wie viel Umsatz sie wahrscheinlich generieren, wenn sie konvertieren.
Ich habe einen Datensatz eingehender Verkaufsanfragen genommen, den Fast Data Science erhalten hat, und konnte das folgende logistische Regressionsmodell trainieren:

Scoring-Modell für eingehende Verkaufskontakte. Dies generiert einen Score zwischen 0 und 100.
Ich habe festgestellt, dass diese einfache Bewertungsmethode Leads mit einer Genauigkeit von 75 % und einem AUC von 82 % klassifizieren kann. Dies ist genauso gut wie ein textbasierter Klassifikator für dieselben Daten , aber für den Benutzer weitaus verständlicher.
Anhand des Bewertungsalgorithmus lässt sich auf den ersten Blick erkennen, dass Nachrichten, die Links enthalten oder von Hotmail-Konten und nicht von Unternehmenskonten stammen, (wie zu erwarten) am stärksten bestraft werden.
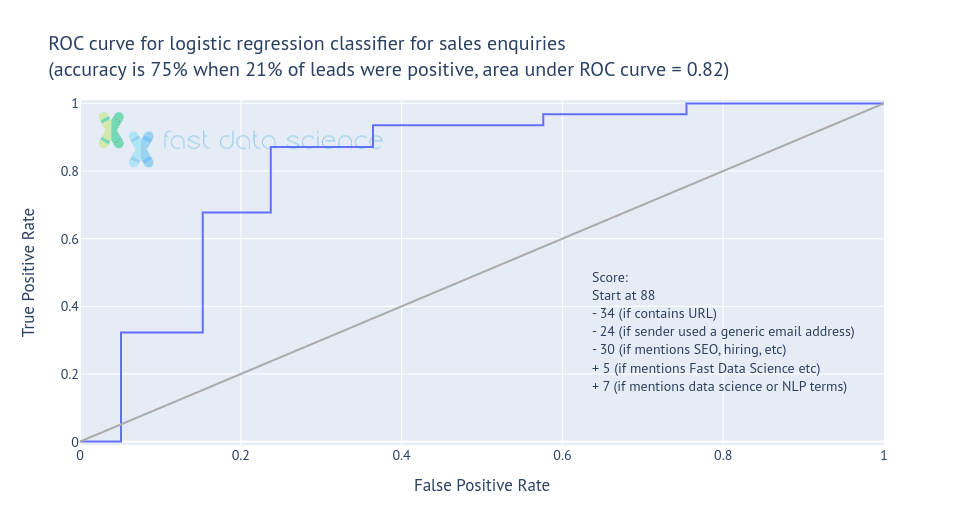
Maschinelles Lernen für Unternehmen: Das Scoring-Modell konnte den Lead-Wert in 75 % der Fälle vorhersagen.
Sie können dieses Lead-Scoring-Modell testen, indem Sie das untenstehende Kontaktformular ausfüllen. Versuchen Sie, eine Nachricht mit vielen Hyperlinks zu verfassen, um zu sehen, wie sich dies auf den Score auswirkt!
Name:| start at score | 88 |
| message text contains URL | 0 |
| sender used generic email | 0 |
| message text contained negative keywords | 0 |
| message text mentions [Fast Data Science](/fast-data-science-company) or relevant people by name | 0 |
| message text contains industry-relevant keywords | 0 |
| TOTAL SCORE | 88 |
| probability of lead | 33.3% |
(So funktioniert es: Ich habe einige reguläre Ausdrücke in Javascript geschrieben, um den Nachrichteninhalt nach Schlüsselwörtern zu durchsuchen, die sich auf die Punktzahl auswirken.)
Ein solches Bewertungsrezept ist für Unternehmen äußerst hilfreich, da das Modell erklärbar ist. Die den Risikofaktoren zugewiesenen Gewichtungen ermöglichen einen transparenten Einblick in die Faktoren, die das Risiko bestimmen.
Insbesondere war nicht sofort ersichtlich, dass das Datum der Kursbewerbung eines Studenten ein Risikofaktor sein könnte, obwohl wir intuitiv verstehen können, dass ein Student, der sich erst spät im Jahr für einen Kurs bewirbt, seine Studienoptionen vielleicht nicht gründlich durchdacht hat oder sich an dieser Institution als zweite Wahl beworben hat, nachdem er woanders abgelehnt wurde, was mit einem Risiko korrelieren könnte.
Neben Transparenz und Erklärbarkeit bestehen die anderen klaren Vorteile darin, dass Sie zur Berechnung des Risikos kein maschinelles Lernmodell einsetzen müssen und dies auf Papier erfolgen kann.
Wenn Sie sich für ein einfaches lineares Bewertungsmodell wie das Studentenrisikomodell oder das B2B-Lead-Bewertungsmodell oben entscheiden, gibt es ein paar Fallstricke, auf die Sie achten sollten:
Wenn die Beziehung zwischen den Daten nicht linear ist, kann das Modell damit nicht umgehen.
Wenn es große Ausreißer gibt (beispielsweise einen Arbeitnehmer, der das Zehnfache aller anderen verdient), kann die lineare Regression diese Fälle nicht bewältigen.
Die Komplexität der Interaktion zwischen den Merkmalen geht dabei verloren. So können Noten für Schüler mit höherem Einkommen beispielsweise ohne Bedeutung sein, für Schüler mit niedrigerem Einkommen jedoch einen großen Unterschied machen.
Die lineare Regression funktioniert nicht so gut, wenn einige der Eingaben des Modells miteinander korreliert sind oder sich gegenseitig beeinflussen.
Aufgrund seiner Einfachheit müssen Sie bei der Auswahl der in einem solchen Modell verwendeten Funktionen sehr sorgfältig vorgehen. Die am einfachsten zu handhabenden Funktionen sind häufig binäre Werte.
Es ist mittlerweile keine Überraschung mehr, dass Formeln und maschinelles Lernen in vielen Bereichen die Intuition von Experten übertreffen. Kahneman und Meehl meinen beide, das Problem könnte darin liegen, dass menschliche Entscheidungsträger anfällig für Informationsüberflutung sind: Sie überschätzen den Einfluss unbedeutender Faktoren auf das Ergebnis.
So betrachtete die oben erwähnte Bildungseinrichtung beispielsweise Schüler, die in Pflegefamilien untergebracht waren, als Hochrisikoschüler. Das lineare Regressionsmodell zeigt jedoch, dass Informationen über die Vorgeschichte der Pflegefamilien keinen Mehrwert für die Vorhersage boten, sobald die bisherigen Noten, das Bewerbungsdatum und der Grad der sozialen Benachteiligung an ihrer Wohnadresse bekannt waren.
Wann also sollte ein Experte auf sein Bauchgefühl hören und seiner Intuition erlauben, die Vorhersage eines Algorithmus zu überstimmen?
Paul Meehl behauptete, dass Kliniker nur selten von algorithmischen Schlussfolgerungen abweichen sollten. Als Beispiel nannte er das berühmte „Beinbruch“-Szenario: Ein Algorithmus sagt voraus, dass ein Professor mit 90-prozentiger Wahrscheinlichkeit ins Kino gehen wird. Aber wir haben eine zusätzliche Information: Der Patient hat sich vor Kurzem das Bein gebrochen. Dies ist ein objektiver Beweis, der die 90-prozentige Vorhersage des Algorithmus außer Kraft setzen sollte. Meehl argumentierte jedoch, dass Kliniker selten Zugang zu dieser Art von Informationen haben und es sich daher selten leisten können, algorithmische Vorhersagen völlig zu ignorieren.

Es stehen nicht immer Daten zur Verfügung, um eine Formel mithilfe einer linearen Regression zu trainieren, wie in den beiden oben genannten Beispielen. Additive Scoring-Modelle können jedoch auch aus der menschlichen Intuition abgeleitet und bei Bedarf anschließend mit Daten untermauert werden.
Wir arbeiten an einem ähnlichen Projekt, bei dem klinische Studien nach ihrem Risiko bewertet werden . Der Kunde hat uns geholfen, ein Rezept zu entwickeln, um klinische Studien auf einer Skala zwischen 0 und 100 zu bewerten, wobei 0 einem hohen und 100 einem niedrigen Risiko entspricht. Da keine quantitativen Risikodaten verfügbar waren, mussten wir uns auf unsere Intuition und ein Abstimmungssystem unter Fachexperten verlassen, um die den Eingaben zugewiesenen Gewichtungen zu bestimmen. Die Struktur des endgültigen Modells ist jedoch identisch mit der der Regressionsmodelle, die in meinen Fallstudien oben beschrieben wurden.
Eine klinische Studie, die einen statistischen Analyseplan enthält oder bei der zur Ermittlung der Stichprobengröße eine Simulation verwendet wurde, ist eine gut geplante klinische Studie und würde auf der Skala einen hohen Wert erzielen, während klinische Studien , bei denen eine kleine oder unzureichende Teilnehmerzahl rekrutiert werden soll, einen niedrigen Wert erzielen würden. Weitere Informationen zu den Faktoren, die das Risiko erhöhen, dass eine klinische Studie ohne informative Ergebnisse endet, finden Sie auf der Projektwebsite .

In der Vergangenheit wussten Geburtshelfer und Hebammen immer, dass Säuglinge, die nicht sofort nach der Geburt zu atmen begannen, einem hohen Risiko für negative Folgen wie Hirnschäden oder Tod ausgesetzt waren. Normalerweise verlassen sie sich auf ihr klinisches Urteilsvermögen und ihre Erfahrung, um zu bestimmen, ob das Baby gefährdet war oder nicht.
Im Jahr 1953 wurde die Anästhesistin Virginia Apgar von einem Assistenzarzt gefragt, wie sie eine systematische Beurteilung eines Neugeborenen vornehmen würde. Aus dem Stegreif fielen ihr fünf Variablen ein: Herzfrequenz, Atmung, Reflexe, Muskeltonus und Farbe , die jeweils als niedrig, mittel oder hoch bewertet werden konnten. Daraus entwickelte sie eine Regressionsformel, die heute als APGAR-Score bekannt ist:
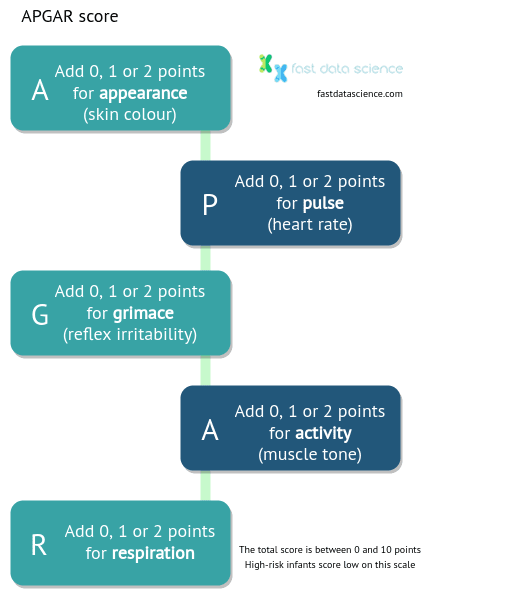
Der APGAR-Score war eine der ersten Checklisten, die in der Medizin weit verbreitet war. Er drückt das Risiko eines Neugeborenen auf einer Skala von 0 bis 10 aus.
Im Jahr 1955 analysierte Dr. Apgar die APGAR-Werte von 15.348 Säuglingen und konnte einen Zusammenhang zwischen niedrigen APGAR-Werten und Asphyxie feststellen.
Dem APGAR-Score wird zugeschrieben, dass er weltweit Tausenden von Säuglingen das Leben gerettet hat, obwohl er aufgrund medizinischer Fortschritte mittlerweile durch andere Bewertungsmethoden abgelöst wurde.
Obwohl das APGAR-Modell an sich einfach ist, liegt die Genialität seines Designs in der Auswahl der Funktionen.
Ein weiteres lineares Wertungsmodell, das ich gefunden habe, gibt es beim Schach. Spieler berechnen die Stärke ihrer Figuren auf dem Brett oft anhand des folgenden Wertungsmodells:
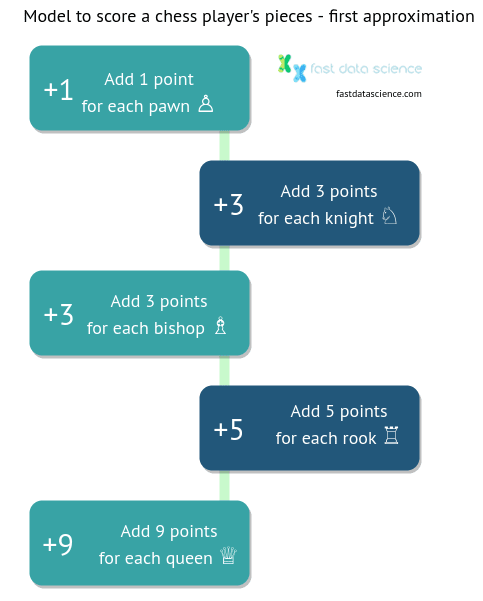
Obwohl die Punktzahl nicht Teil der Regeln ist und keinen direkten Einfluss auf das Spiel hat, hilft sie den Lernenden, die relativen Werte einer Schachfigur schnell zu verstehen und den Wert von Schlagzügen und Tauschgeschäften einzuschätzen.
Als erste Annäherung ist das lineare Punktemodell sehr nützlich und kommt deshalb in den meisten Einführungen in das Spiel vor.
Das obige Wertungsmodell wird seit dem 18. Jahrhundert verwendet. Es wurde für Computeralgorithmen wie Stockfish angepasst, das Brettkonfigurationen in „Centipawns“ wertet, wobei ein Springer ungefähr 300 Centipawns wert ist usw.
In Schachwertungsmodellen wie Stockfish variieren die Werte der Figuren je nach Brettkonfiguration und Spielstadium. Figuren mit großer Reichweite wie Türme, Damen und Läufer werden gegen Ende einer Schachpartie mächtiger, da das Brett weniger überladen ist. Die Werte werden auch davon beeinflusst, welche anderen Figuren ein Spieler und der Gegner besitzen.
Bei Fast Data Science haben wir den in der Pharmaindustrie verwendeten Risiko- und Komplexitätsmodellansatz für Data Science ( NLP )-Projekte angepasst. Im Abschnitt „Ressourcen“ unserer Website finden Sie eine Risikocheckliste zur Identifizierung von NLP-Projekten mit hohem Risiko sowie ein Excel-Kostenmodellierungstool für NLP-Projekte . Die Parameter dieser Tools wurden durch Ausführen eines Regressionsmodells für einige unserer früheren Projekte abgeleitet, um Schlüsselfaktoren zu identifizieren, die zu Kosten, Komplexität und Risiko beitragen.
Ein einfaches Modell wie die lineare Regression hat nur sehr wenige Parameter, da es sich um einen additiven Prozess handelt, bei dem Eingaben mit unterschiedlicher Gewichtung addiert werden. Vorausgesetzt, dass sinnvolle Eingaben verwendet werden, kann nicht viel schiefgehen.
Mir gefällt die Transparenz, die eine einfache Bewertung auf einer Skala von 0 bis 10 oder 0 bis 100 bietet. Menschen finden es schwierig, Wahrscheinlichkeiten zu interpretieren. Wir beschäftigen uns mit Konzepten wie Wahrscheinlichkeiten in einem sehr kurzen evolutionären Zeitrahmen und ich glaube nicht, dass das menschliche Gehirn intuitiv damit umgeht.
Daniel Kahneman führte eine Reihe von Verhaltensexperimenten durch, bei denen er Freiwilligen Wetten (Geldwetten) anbot. Dabei konnte er nachweisen, dass die Teilnehmer kleine Wahrscheinlichkeiten, wie etwa eine 1%ige Chance, 100 Dollar zu gewinnen, durchweg überschätzten und große Wahrscheinlichkeiten, wie etwa 99 %, unterschätzten, was dazu führte, dass sie Wetten mit derartigen Quoten irrational annahmen oder ablehnten.
Ein Scoring-Modell umgeht unsere Wahrscheinlichkeitsblindheit und kann von Stakeholdern verstanden werden. Wie ich jedoch oben am Beispiel des Studentenabbruchrisikomodells und des Lead-Classifier-Modells gezeigt habe, kann ein Score auf einer Skala von 0 bis 100 mithilfe der Sigmoid-Funktion oder einer Alternative immer noch in eine Wahrscheinlichkeit (oder etwas Ähnliches) umgewandelt werden und bietet daher das Beste aus beiden Welten.
Manchmal stehen Daten zur Verfügung, um ein Bewertungsmodell mithilfe einer logistischen Regression oder eines ähnlichen statistischen Algorithmus zu trainieren. Doch selbst wenn man sich, wie im Fall des APGAR-Scores, auf menschliche Intuition verlässt, um ein solches Modell von Grund auf neu zu erstellen, ist es dennoch wertvoll, eine Checkliste für die Bewertung zu haben.
Es ist wichtig zu beachten, dass diese Bewertungsmodelle zwar für Vorhersagen nützlich sind, uns jedoch nichts über Ursache und Wirkung sagen. Wenn wir beispielsweise wissen, dass ein Student, der sich verspätet für ein Studium bewirbt, eher abbricht, können wir damit Hochrisikostudenten identifizieren. Dies bedeutet jedoch nicht, dass eine verspätete Bewerbung den Abbruch des Studiums verursacht hat. Es ist durchaus möglich, dass ein weiterer, unbekannter Faktor (Familienleben, Motivation usw.) den Studenten veranlasst hat , sich verspätet zu bewerben und sich ebenfalls auf seine akademischen Leistungen ausgewirkt hat.
Wenn Sie die Ursachen eines bestimmten Ergebnisses ermitteln möchten, stehen Ihnen andere Tools zur Verfügung. Die einfachste Möglichkeit ist die Intervention, die in den frühen Phasen der Arzneimittelentwicklung in der Pharmaindustrie eingesetzt wird: die randomisierte kontrollierte Studie (RCT), bei der die Teilnehmer nach dem Zufallsprinzip in zwei Gruppen aufgeteilt werden und eine Gruppe eine Intervention erhält, während die andere als Kontrollgruppe dient.
Wenn Interventionen aus praktischen oder ethischen Gründen keine Option sind, verwenden Ökonomen und Statistiker manchmal Pseudoexperimente , wie etwa die Schätzung von Instrumentvariablen . Ich habe einen Blogbeitrag über kausales maschinelles Lernen geschrieben, in dem ich versucht habe, die Kausalität aus der Perspektive des maschinellen Lernens zu untersuchen.
Mit einfachen Modellen des maschinellen Lernens können wir Organisationen und Unternehmen einen großen Mehrwert bieten, vorausgesetzt, die Funktionen werden sorgfältig ausgewählt. Das obige Hauptklassifizierungsmodell beispielsweise hängt von einer intelligenten Auswahl von Schlüsselwörtern ab, und ich habe die Schlüsselwörter ausgewählt, nachdem ich aus den Daten Wortwolken generiert hatte. Ebenso konnte Dr. Apgar aufgrund ihrer klinischen Erfahrung auswählen, welche Kriterien in den APGAR-Score aufgenommen werden sollten.
Aufgrund der Einfachheit von Regressionsmodellen können Benutzer sehr leicht nachvollziehen, wie sich unterschiedliche Faktoren auf ein Ergebnis auswirken, und auf einen Blick erkennen, welcher Faktor dominiert.
Obwohl Regressionsmodelle nicht immer die genauesten sind, sind sie aufgrund ihrer Einfachheit möglicherweise das am besten geeignete Modell für die Implementierung in einem Geschäftsumfeld.
Fachleute in den verschiedensten Bereichen – von der Medizin über das Ingenieurwesen bis hin zum Recht – sind mit der Menge an Informationen und Schulungsinhalten, die sie sich merken müssen, überfordert. Checklisten und Bewertungen helfen uns dabei, den Überblick darüber zu behalten, welche Faktoren wichtig und welche unwichtig sind.
Atul Gawante, Das Checklisten-Manifest: Wie man die Dinge richtig macht (2011)
Daniel Kahneman, Schnelles Denken, langsames Denken (2011)
Paul Meehl, Ursachen und Auswirkungen meines verstörenden kleinen Buches (1986)
Paul Meehl, Klinische versus statistische Vorhersage: Eine theoretische Analyse und eine Überprüfung der Beweise (1954)
Robyn M. Dawes, Die robuste Schönheit ungeeigneter linearer Modelle bei der Entscheidungsfindung (1979)
Virginia Apgar, Ein Vorschlag für eine neue Methode zur Beurteilung von Neugeborenen , Aktuelle Forschungen in Anästhesie und Analgesie (1953)
Suchen Sie Experten in Natürlicher Sprachverarbeitung? Veröffentlichen Sie Ihre Stellenangebote bei uns und finden Sie heute Ihren idealen Kandidaten!
Veröffentlichen Sie einen Job
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you