
Natural Language Processing ( NLP ) ist der Bereich der künstlichen Intelligenz, der sich mit menschlicher Sprache und Sprechen beschäftigt. Er liegt an der Schnittstelle zwischen einer Vielzahl von Disziplinen, von der Linguistik über die Informatik und Ingenieurwissenschaften bis hin zur KI.
Bei NLP geht es darum, Computern beizubringen, wie man menschliche Sprache spricht, schreibt, hört und interpretiert. Wenn Sie heute eine Suchmaschine, ein GPS-Navigationssystem oder Amazon Echo verwendet haben, haben Sie bereits mit einem NLP- System interagiert. NLP gibt es schon seit Jahrzehnten, und NLP-Modelle sind in letzter Zeit dank des Aufkommens von Deep Learning und neuronalen Netzwerken viel leistungsfähiger geworden. NLP ist ein faszinierender Bereich der KI und hat ein enormes Potenzial, unsere Lebens-, Freizeit- und Arbeitsweise zu verändern.
Hier sind einige der Bereiche, die durch die Verarbeitung natürlicher Sprache verändert werden könnten.


In vielen Ländern gehen die Gesundheitssysteme von Papierakten zu elektronischen Patientenakten über. Dadurch sind zahlreiche analytische Möglichkeiten entstanden, die die Gesundheitsversorgung und -ergebnisse verbessern.
Eine große Herausforderung für Gesundheitssysteme besteht jedoch darin, das volle Potenzial dieser Daten auszuschöpfen. Elektronische Patientenakten enthalten viele unstrukturierte Daten im Textformat. Es ist viel schwieriger, Analysen für Textdaten durchzuführen als für strukturierte Daten, die in anderen Branchen üblich sind.
Aus diesem Grund beginnen Gesundheitsorganisationen, NLP einzusetzen, um Einblicke in Gesundheitsakten und andere Textdaten zu erhalten.
NLP kann elektronische Patientenakten analysieren und die Schlaganfallprävention und -behandlung verbessern, indem es Ärzten hilft, zu entscheiden, wann eine intravenöse Thrombolyse (eine Infusion) angewendet werden soll.
Die Wahrscheinlichkeit bestimmter unerwünschter Ereignisse wie Herzinfarkte und Schlaganfälle sowie den weiteren Verlauf dieser Krankheiten lassen sich nur schwer genau vorhersagen. Die wichtigsten Informationen zur Krankengeschichte eines Patienten liegen häufig im Textformat vor und lassen sich nur schwer in Vorhersagemodelle integrieren.
Im Jahr 2018 entwickelte ein Forscherteam einer neurologischen Abteilung in Taiwan ein NLP-System, das elektronische Krankenakten verarbeiten und Ärzten dabei helfen kann, zu entscheiden, welche Schlaganfallpatienten eine intravenöse Thrombolyse (ein Medikament zur Verhinderung der Blutgerinnung) erhalten sollten.
Sie stellten fest, dass ihr Modell die Entscheidungsfindung deutlich verbessern und die Qualität der Versorgung steigern konnte.
Nach Schätzungen der Weltgesundheitsorganisation gehört Selbstmord zu den zehn häufigsten Todesursachen weltweit, und jeder Selbstmord betrifft wahrscheinlich das Leben von 138 Menschen. Oft hat eine Person nicht häufig genug Kontakt zu medizinischem Fachpersonal, um Anzeichen für ein Selbstmordrisiko rechtzeitig zu erkennen. Darüber hinaus erfordern die meisten Standardmethoden zur Risikobewertung, dass die Person einem Fachmann ihr Selbstverletzungsrisiko mitteilt.
Die Verfügbarkeit sozialer Medien bietet neue Möglichkeiten, das Risiko einer Person zu analysieren und zu verstehen. Ein Team in Boston, USA, hat ein Deep-Learning -Modell zur Verarbeitung natürlicher Sprache entwickelt, um Signale in der Social-Media-Nutzung einer Person zu erkennen, die auf ein hohes Risiko hinweisen. Darüber hinaus verfügt Facebook über eine KI zur Suizidprävention, die Beiträge auf der Plattform scannt, um das Risiko einzuschätzen.
Fast Data Science - London
Es versteht sich von selbst, dass die Anwendungen in diesem Bereich in einigen Kreisen Unbehagen ausgelöst haben. Viele Beobachter sind besorgt über die Auswirkungen auf die Privatsphäre und den schlimmsten Fall, dass ein böswilliger Akteur sogar an die Daten zum Suizidrisiko gelangt und die Betroffenen zum Selbstmord ermutigt.
Der Einsatz des Facebook- Algorithmus wurde in der EU verhindert, da er nicht den Zustimmungsregeln der DSGVO entspricht. Viele Wissenschaftler und Datenschutzexperten haben jedoch erklärt, dass das Potenzial dieser Technologie für das Gemeinwohl die Datenschutzbedenken überwiegt.
Die Pharmaindustrie hat in den letzten drei Jahrzehnten viele neue Herausforderungen bewältigt. Zwar sind neue Technologien entstanden, die den Prozess der Arzneimittelentdeckung und -entwicklung beschleunigen, aber die Pharmaindustrie bleibt eine Hochrisikobranche . Fast 90 % der Medikamente, die die Phase 1 klinischer Tests erreichen, kommen nie auf den Markt, weil sie unsicher oder unwirksam sind. Der gesamte Prozess der Markteinführung eines Medikaments dauert durchschnittlich 12 Jahre und kostet bis zu 3 Milliarden Dollar.
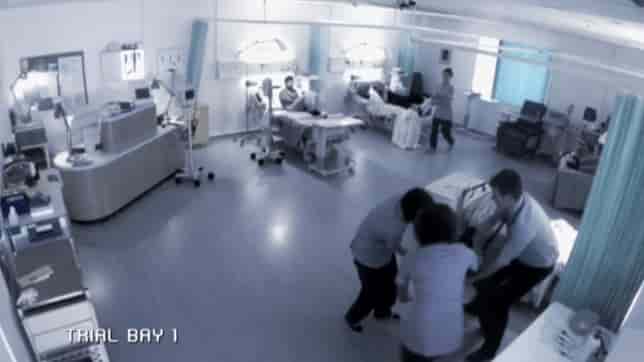
Ärzte kämpfen um das Leben von sechs Studienteilnehmern des berüchtigten „Elephant Man“-Medikamententests, der 2006 von Parexel in London durchgeführt wurde. Unerwartete Nebenwirkungen des getesteten Medikaments TGN1412 verursachten bei einigen Teilnehmern bleibende Verletzungen. Bildquelle: BBC.
In allen Phasen des Arzneimittelentwicklungsprozesses, von der Arzneimittelentdeckung bis hin zu Studien am Menschen, sind in unstrukturiertem Text eine Fülle sicherheitsrelevanter Informationen verborgen. Interne Sicherheitsberichte, medizinische Literatur, elektronische Krankenakten, soziale Medien und Konferenzberichte können alle nach wichtigen Sicherheitsinformationen durchsucht werden, wie etwa Berichte über unerwünschte Ereignisse, Nebenwirkungen, Dosierungsinformationen und andere Daten. NLP-Modelle können diese Informationen in strukturierte Daten umwandeln, die in Analyse- und Entscheidungsprozesse einfließen können.
Dadurch können die Forscher auf der Grundlage der besten verfügbaren Informationen handeln und kritische Sicherheitsprobleme früher erkennen. Auf diese Weise werden die Verluste des Pharmaunternehmens verringert, wenn das Medikament nicht auf den Markt kommt.
Wenn klinische Studien durchgeführt werden, muss die Sponsororganisation ein klinisches Studienprotokoll veröffentlichen, in dem das experimentelle Design und der gesamte Ablauf der Studie beschrieben werden. Diese Dokumente sind in der Regel 200 Seiten lang, werden im PDF-Format verteilt und in technischem, aber unstrukturiertem Englisch verfasst.
Es ist möglich, ein Modell zur Verarbeitung natürlicher Sprache zu entwickeln, um relevante Daten aus einem Studienprotokoll zu extrahieren, wie etwa die Anzahl und das Alter der Studienteilnehmer, das experimentelle Design, die Art der Behandlung oder mögliche Toxizitäten. Bei Fast Data Science haben wir für das deutsche Pharmaunternehmen Boehringer Ingelheim ein Modell entwickelt , das ein klinisches Studienprotokoll analysiert und verschiedene Maße der Studienkomplexität vorhersagt, die in ein Kostenmodell einfließen können. Dies ermöglicht es dem Unternehmen, zu analysieren und zu verstehen, was die Durchführung einer Studie mit sich bringt, ohne viel Zeit mit dem Durchlesen von Protokollen zu verbringen.
Einem aktuellen Bericht des Economist zufolge nutzen Investmentbanken und andere Finanzinstitute KI und maschinelles Lernen vor allem für Analysen und nutzen strukturierte Daten, um geschäftliche Fragen wie die Kundenabwanderung zu beantworten. Die Verarbeitung natürlicher Sprache ist jedoch nicht weit davon entfernt.
Der Online- Chatbot auf der Website von HSBC kann häufige Fragen beantworten und Anfragen an die Callcenter vermeiden. Bildquelle: HSBC
Die meisten großen Banken mit Online-Präsenz haben mittlerweile einen virtuellen Assistenten oder Chatbot auf ihrer Homepage und sparen so Geld für Callcenter. Diese können grundlegende Aufgaben wie Kontostandsabfragen, Kontodetails und Kreditanfragen übernehmen. Sie werden häufig in die Telefonsysteme der Banken integriert und ermöglichen eine effiziente Triage von Anfragen an die richtige Abteilung, wenn tatsächlich ein Mensch eingeschaltet werden muss.

Ein Beispiel für einen anonymisierten Vertrag zum Verkauf eines Hauses. NLP kann die Namen der Vertragsparteien sowie wichtige Daten wie Kosten oder Vertragsbedingungen extrahieren und ein Dokument sogar zu Compliance-Zwecken anonymisieren.
Viele Finanzinstitute befassen sich täglich mit einer großen Anzahl juristischer Dokumente wie Verträgen, Geheimhaltungsvereinbarungen und Treuhandurkunden.
Lösungen zur Verarbeitung natürlicher Sprache werden verwendet, um wichtige Informationen aus unstrukturierten Dokumenten zu extrahieren und das Dokument entsprechend den Geschäftsanforderungen zu klassifizieren. Dies ist mit herkömmlichen Programmiertechniken ohne KI schwierig, da keine zwei Rechtsdokumente gleich sind, die Formatierung sehr unterschiedlich sein kann und Dokumente häufig in Papierform empfangen und gescannt werden, da in vielen Rechtsgebieten eine physische Unterschrift erforderlich ist.
NLP wird auch verwendet, um juristische Dokumente zu anonymisieren. Für viele geschäftliche oder behördliche Zwecke ist es notwendig, Namen, Daten, Orte oder Preise aus juristischen Dokumenten zu entfernen oder zu bereinigen. Die Notwendigkeit, Daten aus Compliance-Gründen zu anonymisieren, ist mit zunehmender Regulierung explosionsartig gestiegen, und insbesondere seit dem Inkrafttreten der DSGVO sind eine Reihe von Produkten auf den Markt gekommen.
Viele Investmentfirmen verwenden NLP bereits zur Analyse von Geschäftsberichten und Zeitungsartikeln von Unternehmen. Oftmals kann ein Schlüsselereignis wie die Freistellung eines CEOs durch den Vorstand eine marktbewegende Information sein, und es ist teuer, Leute zu bezahlen, die alle für ein Unternehmen relevanten Dokumente durchlesen.
In jüngster Zeit gab es eine Welle technologischer Innovationen zur Verbesserung der Effizienz in der Versicherungsbranche, die als InsurTech bezeichnet werden, angelehnt an den Begriff FinTech. Dies ist teilweise auf die zunehmende Verbreitung der Verarbeitung natürlicher Sprache zurückzuführen, die in der Branche große Effizienzgewinne bringen kann.
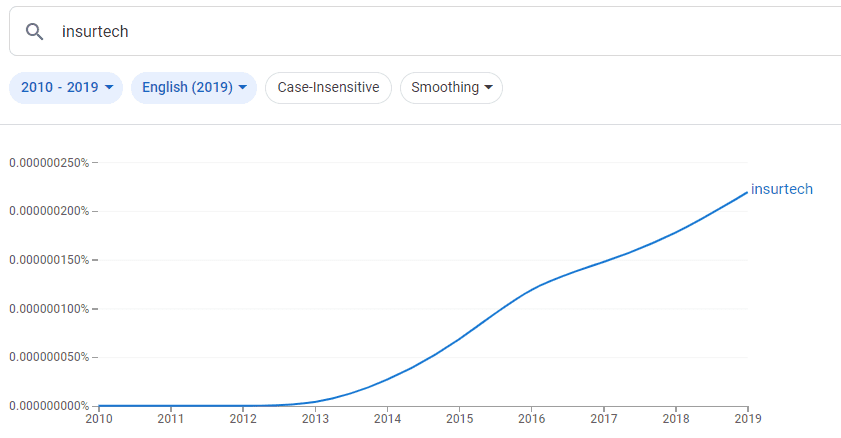
Google NGrams Viewer zeigt die Entstehung des Begriffs InsurTech, der viel KI und NLP in der Versicherungsbranche umfasst
Versicherungsunternehmen müssen bei der Bearbeitung von Versicherungsansprüchen große Mengen unstrukturierter Dokumente verarbeiten. Wenn ein Kunde beispielsweise einen Anspruch bei seiner Reiseversicherung geltend macht, weil er im Urlaub krank geworden ist, muss der Versicherer möglicherweise zehn Dokumente durchgehen, die alle in gescannter Form hochgeladen wurden, bevor er entscheiden kann, ob der Anspruch den Kriterien der Police entspricht.
Versicherer und Versicherungsträger beginnen, die Verarbeitung natürlicher Sprache als natürliche Lösung zur Rationalisierung dieses Prozesses zu betrachten. Anhand eines Datensatzes der in den letzten drei Jahren eingereichten Ansprüche und getroffenen Entscheidungen kann ein einfacher überwachter Lernalgorithmus Dokumente verarbeiten und eine Wahrscheinlichkeit für die Bewilligung des Anspruchs angeben. Diese Algorithmen können sogar in Echtzeit auf der Weboberfläche des Unternehmens ausgeführt werden und den Kunden darauf hinweisen, dass er weitere Belege hochladen muss. Dadurch wird die Einschaltung eines Kundendienstmitarbeiters überflüssig.
Die Verarbeitung natürlicher Sprache hat bereits eine Reihe von Branchen verändert. Bestimmte Bereiche wie das Gesundheitswesen und das Finanzwesen wurden in der Vergangenheit jedoch durch regulatorische oder ethische Bedenken sowie die schiere praktische Schwierigkeit, ihre Big-Data-Probleme mit KI zu lösen, zurückgehalten, obwohl sie über Goldgruben an unstrukturierten Textdaten verfügen. Wir haben bereits gesehen, wie maschinelles Lernen die strukturierten Daten in diesen Branchen verändert hat, während die Verarbeitung natürlicher Sprache dicht dahinter liegt.
Da Regulierung, Technologie und Geschäftspraktiken aufholen, wird NLP in den 2020er Jahren das ungenutzte Potenzial dieser Branchen beeinflussen , und die Regulierung in diesen Bereichen muss aufholen. Wir können uns auf enorme und lang erwartete Verbesserungen im Gesundheitswesen, in der Pharmaindustrie, im Rechtswesen, im Versicherungswesen und im Finanzwesen freuen.
Suchen Sie Experten in Natürlicher Sprachverarbeitung? Veröffentlichen Sie Ihre Stellenangebote bei uns und finden Sie heute Ihren idealen Kandidaten!
Veröffentlichen Sie einen Job
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you