Wenn wir daran denken, eine Fertigkeit zu erwerben oder ein neues Fach zu lernen, stellen sich die meisten von uns diesen Prozess so vor, dass ein Lehrer uns sein Wissen weitergibt. Wenn Sie einem Kind beispielsweise beibringen, zwischen verschiedenen Früchten zu unterscheiden, können Sie ihm verschiedene Bilder zeigen und eines als Apfel, ein anderes als Birne usw. identifizieren, sodass das Kind, wenn es diese Früchte im wirklichen Leben sieht, selbst erkennen kann, welche welche ist, aber zunächst anhand der von Ihnen bereitgestellten Beschriftungen. Dies wird als überwachtes Lernen bezeichnet und ist eine Möglichkeit, bei der künstliche Intelligenz maschinelles Lernen nutzt, um bestimmte Ergebnisse vorherzusagen, nachdem Datenpunkte mit bekannten Ergebnissen verwendet wurden. Dies ist jedoch nicht die einzige Art, wie wir oder Computer lernen. Wir möchten Ihnen unüberwachtes Lernen vorstellen.
What we give to a supervised learning algorithm
What we give to an unsupervised learning algorithm.
Einem überwachten Lernalgorithmus werden Beispiele von Früchten gezeigt und mitgeteilt, um welche Früchte es sich handelt. Ein unüberwachter Lernalgorithmus lernt wie ein Kleinkind: Er lernt, dass es grüne, orange, gelbe und rote Früchte gibt und dass diese unterschiedliche Größen und Texturen haben. Schließlich findet er Muster und denkt sich eigene Bezeichnungen dafür aus.
Für viele Projekte, bei denen es um KI in Unternehmen geht, stehen keine klar gekennzeichneten Daten zur Verfügung. Daher müssen wir oft über den Tellerrand hinausblicken und unüberwachte Lerntechniken verwenden.
Was ist unüberwachtes Lernen?
Wir haben nicht alles, was wir wissen, gelernt, weil es uns beigebracht wurde. Manches haben wir uns selbst beigebracht, indem wir Dinge durch Beobachtung herausgefunden und die Zusammenhänge miteinander verbunden haben, ohne Hilfe und ohne Aufsicht. Auch Maschinen und Programme können auf diese Weise lernen. Das nennt man unüberwachtes Lernen .
Sehen wir uns an, wie wir unbeaufsichtigt lernen: An einem schönen Sommersamstag ruft Sie ein Freund an und erzählt Ihnen, dass Trevor wieder mal ein Spinner war (oh Trevor). Aus diesem Grund ist eine Karte für das Spiel der englischen Cricket-Mannschaft gegen Australien übrig. Es ist ein strahlend sonniger Nachmittag, Sie brauchen ein Bier und es scheint, als wären die Plätze ganz gut. Da ist nur eines: Sie haben keine Ahnung von den Cricket-Regeln. Trotzdem gehen Sie hin – schließlich ruft das Bier. Sie nehmen Platz und das Spiel beginnt.
Wenn Sie die Cricket-Regeln nur durch Beobachtung lernen, ist dies eine Analogie zum unüberwachten Lernen.
Hier fangen Sie an, etwas über das Spiel zu lernen: Sie analysieren die Bewegungen zwischen den Spielern, die Signale der Schiedsrichter und die Reaktionen Ihrer Freunde. Es gibt zwei Teams, eines in Weiß, das andere in Gelb. Ihre englischen Freunde jubeln, wenn das weiße Team glücklich und das gelbe Team traurig aussieht – also kommen Sie zu dem Schluss, dass England in Weiß und Australien in Gelb sein muss. Es gibt 15 Leute auf dem Feld: 11 in Weiß, 2 in Gelb und weitere 2 in langen Mänteln und schwarzen Hosen. Diese letztere Gruppe mischt sich nicht in das Spiel ein, sondern leitet das Spiel und setzt die Regeln durch – sie müssen die Schiedsrichter sein. Wenn der Ball von den Feldspielern gefangen wird, verlässt der Schlagmann das Spielfeld – wenn der Ball eindeutig in die Hände eines gegnerischen Spielers schlägt, sind Sie raus. Alle diese Schlussfolgerungen werden durch Ihre Beobachtung abgeleitet, indem Sie die Regeln selbst aus verschiedenen Trends und Ähnlichkeiten ableiten, die Sie zusammengestellt haben, ohne dass Ihnen jemand anderes es gesagt oder ihnen „ Etiketten“ gegeben hätte. Dies ist unüberwachtes Lernen – aber wie funktioniert es im Kontext von KI und maschinellem Lernen?
Wie funktioniert unüberwachtes Lernen?
Maschinelles Lernen kann grob in drei Kategorien eingeteilt werden: unüberwachtes Lernen , überwachtes Lernen und bestärkendes Lernen .
Wie bereits erwähnt, besteht der größte Unterschied zwischen unüberwachtem und überwachtem Lernen in der Existenz von Beschriftungen (oder nicht) innerhalb des Datensatzes. Angenommen, Sie haben eine Reihe von Blumenfotos gespeichert und möchten, dass Ihr Programm oder Algorithmus zwischen Bildern von Tulpen und Gänseblümchen unterscheidet. Ihre erste Möglichkeit besteht darin, selbst Kennungen hinzuzufügen, die angeben, ob es sich bei einer Blume um eine Tulpe oder ein Gänseblümchen handelt (dies wird als Beschriftung bezeichnet) . Anschließend können Sie Ihre beschrifteten Bilder einem KI-Algorithmus übergeben, der versucht, die wichtigsten Merkmale von Tulpen und Gänseblümchen zu erlernen.
Fast Data Science - London
Need a business solution?
Führend in den Bereichen NLP, ML und Data Science seit 2016 – kontaktieren Sie uns für eine NLP-Beratungssitzung.
Andererseits könnten Sie versuchen, alle diese Bilder einfach in ein Modell einzuspeisen, das versucht, zwei allgemeine Blumenarten im Datensatz explizit zu identifizieren, ohne sie zu beschriften.
Das erste (beschriftete) Beispiel ist überwachtes Lernen. Das zweite (unbeschriftete) Beispiel ist unüberwachtes Lernen.
Warum sollten Sie unüberwachtes Lernen nutzen?
Die Verwendung von nicht gekennzeichneten Daten gegenüber gekennzeichneten Daten bietet mehrere Vorteile. Erstens erfordert die Kennzeichnung von Daten viele Ressourcen, und Sie haben möglicherweise einfach nicht die erforderliche Zeit oder das erforderliche Team. Zweitens kann der Prozess der Datenkennzeichnung fehleranfällig und „verrauscht“ sein, da diejenigen, die die Daten kennzeichnen, Fehler oder implizite Vorurteile haben können (wir sind schließlich auch nur Menschen). Schließlich sind Kennzeichnungen sinnvoll, wenn Sie genau wissen, was Sie vorhersagen möchten, aber in vielen Fällen möchten Sie vielleicht tatsächlich neue Muster in Ihren Daten entdecken, Schlussfolgerungen, die möglicherweise über die menschliche Fähigkeit hinausgehen, herauszufinden (oder zumindest nicht ohne enormen Zeit- und Arbeitsaufwand), die aber durch unüberwachtes Lernen durchaus mit KI möglich sind.
Nehmen wir also an, Sie betreiben ein Blumengeschäft, in dem Ihre Blumen derzeit nach Farben sortiert sind. Jetzt möchten Sie jedoch Ihre Präsentation ändern und Ihre Blumen anders anordnen. In diesem Fall möchten Sie Blumengruppen entdecken, die sich auf eine Weise ähneln, an die Sie bisher nicht gedacht haben. Unüberwachtes Lernen kann hier Abhilfe schaffen!
Es gibt verschiedene Möglichkeiten, wie unüberwachte Lernalgorithmen ihre Daten analysieren, aber die häufigste Art ist das Clustering . Dabei werden Daten auf Grundlage der Ähnlichkeit zwischen Dateninstanzen getrennt. Für unseren Zweck werden dabei zugrunde liegende Merkmale der Blumen gefunden, die dann in verschiedene Gruppen eingeteilt werden können, die Sie selbst noch nie zuvor gesehen haben.
Ein weiteres häufiges Beispiel sind Fabrikfehlerberichte. Stellen Sie sich vor, ein großes Fertigungsunternehmen verfügt über ein Fehlerprotokollierungssystem. Jede Art von Unfall oder Vorfall wird von den Mitarbeitern im Klartext in eine Datenbank protokolliert. Manche sind einfach, wie „Förderband blockiert“, andere können komplexer sein, wie „die Verpackung ist während des Transports aufgrund unsachgemäßer Handhabung beschädigt worden“. Wenn Sie als Datenwissenschaftler vor Ort eintreffen und der Fabrikbesitzer Sie bittet, die zehn häufigsten Fehler in der Fabrik zu identifizieren, wie würden Sie vorgehen?
Es gibt den mühsamen manuellen Ansatz, bei dem alle Berichte durchgelesen und versucht werden, sie einer willkürlichen Kategorie zuzuordnen. Alternativ können Sie die Verarbeitung natürlicher Sprache und unüberwachte Lerntechniken wie Clustering verwenden, um Themen und Cluster zu identifizieren.
Was ist Clustering?
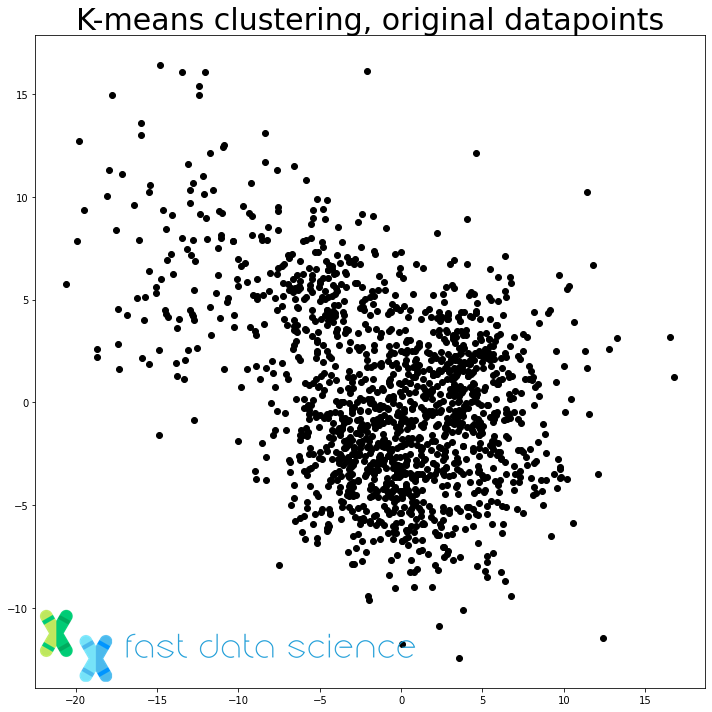
Clustering, eine der gebräuchlichsten unüberwachten Lerntechniken, beginnt mit einem Satz unbeschrifteter Daten und entdeckt Gruppen und Muster im Rauschen.
Die Clusteranalyse ist ein wichtiger Ansatz im Bereich des unüberwachten Lernens. Da unüberwachtes Lernen nicht mit Beschriftungen beginnt, wäre die Ausgabe eines Clusteralgorithmus die Zuordnung jeder Blume zu einer Gruppe. Er stellt Ähnlichkeiten und gemeinsame Merkmale in Gruppen zusammen. Diese Gruppen haben keine vordefinierte Bedeutung, sondern werden durch Clustering entdeckt. An diesem Punkt würden Sie die Elemente in jeder Gruppe durchgehen, um zu sehen, welche Gemeinsamkeiten die KI gefunden hat. Beispielsweise könnten Sie feststellen, dass die Gruppen Blumen mit unterschiedlichen Texturen oder Höhen, Blütenblattlängen oder Stielbreiten entsprechen. Das Ergebnis ist eine Reihe von Mustern, die in Ihren Blumen vorhanden sind und an die Sie vorher vielleicht nicht gedacht haben. Oder Sie können einfach nicht herausfinden, was in den Gruppen vor sich geht, die Ihr Algorithmus entdeckt hat.
Diagramm der Kelchlänge im Vergleich zur Kelchbreite für drei Schwertlilienarten (unter Verwendung des bekannten Iris-Datensatzes ). Diese Daten sind beschriftet, aber wenn die Beschriftungen entfernt würden, könnte ein Clusteralgorithmus wahrscheinlich zwischen setosa und den beiden anderen Arten unterscheiden.
Beispiel für unüberwachtes Lernen zur Themenfindung (LDA)
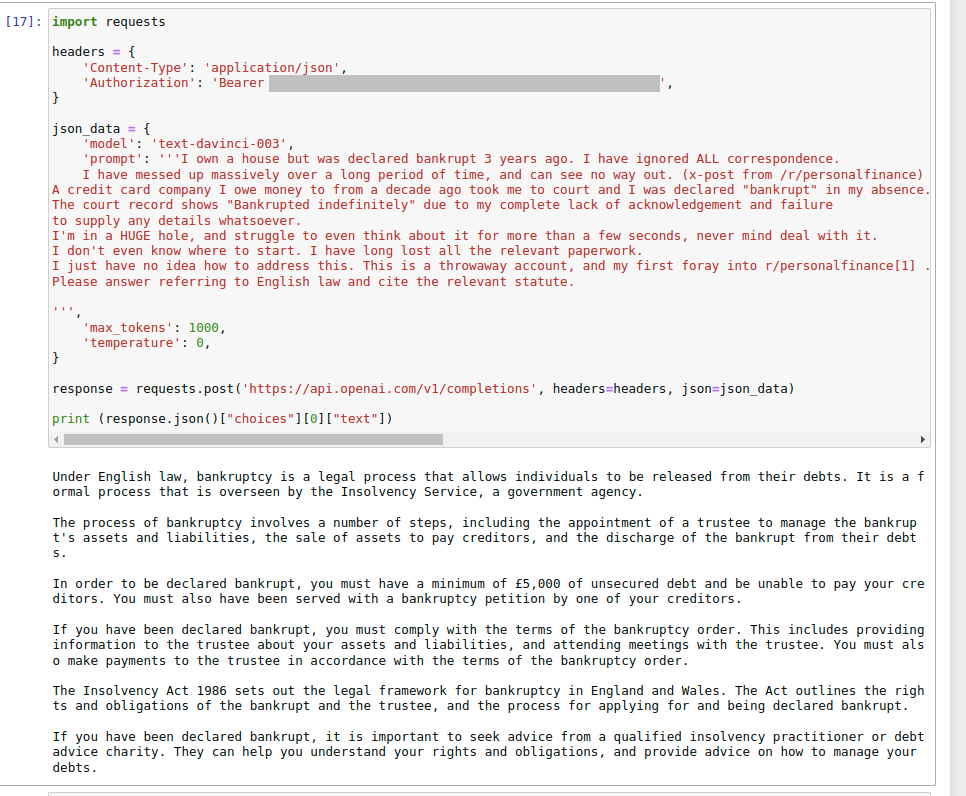
Die DVLA ist die Organisation in Großbritannien, die Fahrzeuge auf Verkehrssicherheit prüft. Sie entspricht der DMV in den USA. Auf der Website der DVLA können Sie alle Fahrzeugprüfberichte des Landes herunterladen. Ein Prüfbericht enthält häufig eine Beschreibung des Fehlers im Klartext.
Ein Beispiel für Fahrzeuginspektionsberichte, die von der Website der DVLA heruntergeladen wurden
Wenn uns jedoch nur diese Texte und keine anderen strukturierten Daten zur Verfügung stehen, wäre es ziemlich schwierig, häufige Arten von Fahrzeugfehlern zu identifizieren.
Wenn wir schnell gemeinsame Themen in den Berichten entdecken möchten, können wir eine Wortwolke der Texte generieren, in der häufig vorkommende Wörter in großer Schrift erscheinen. So können wir auf einen Blick die häufigsten Ausdrücke erkennen, erhalten aber keine Themenliste .
Eine Wortwolke für die Fahrzeuginspektionsberichte. Wir haben den Berichten keine Beschriftungen beigefügt, daher können wir sie nur mithilfe von unüberwachtem Lernen verarbeiten.
Wir können einen unüberwachten Lernalgorithmus namens LDA oder Latent Dirichlet Allocation verwenden, um die Berichte in fünf Themen aufzuteilen:
Ausgabe des LDA-Algorithmus in Fahrzeuginspektionsberichten. Sie können sehen, dass die entdeckten Themen anscheinend mit Bremsen, Lichtern, Fahrzeugheck, Achsen und Aufhängung zu tun haben. LDA (Latent Dirichlet Allocation) ist eine gängige unüberwachte Lerntechnik, die bei Textdaten verwendet wird.
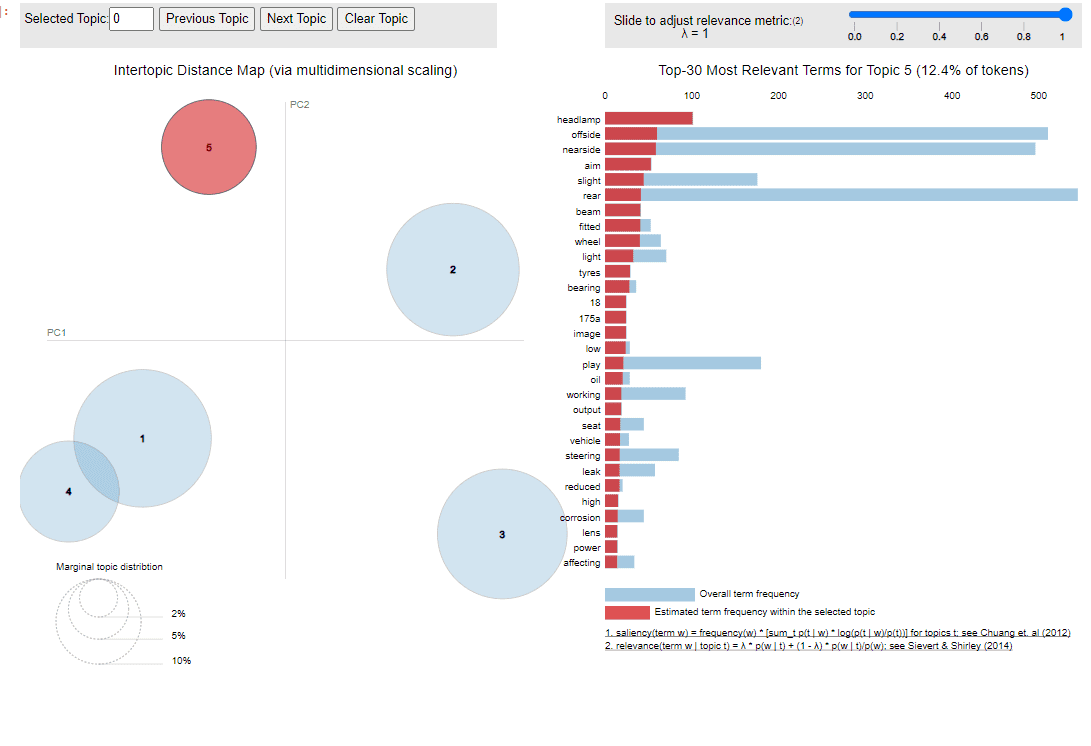
Und schließlich ist es möglich, die Themen in einem Graphenraum darzustellen. Diese Visualisierung lässt uns beispielsweise erkennen, dass die Themen 1 und 4 recht nah beieinander liegen.
Visualisierung der LDA-Ausgabe in Fahrzeuginspektionsberichten.
Die obige LDA-Analyse ist ein einfaches Beispiel, für das ich weniger als eine halbe Stunde gebraucht habe. Wir können uns nur vorstellen, wie leistungsfähig sie wäre, um Themen in Fabrikfehlerberichten, Umfragedaten und anderen Arten unstrukturierter Textdaten zu entdecken.
Abschließende Gedanken
Dies ist das zweischneidige Schwert des unüberwachten Lernens: Da Sie keine vordefinierten Bezeichnungen haben, kann Ihr KI-Programm neue, innovative Entdeckungen und Muster in Ihren Daten finden. Gleichzeitig ist es, da Ihre KI nicht aus Bezeichnungen lernt, schwieriger vorherzusagen, was der Algorithmus lernen wird – Sie haben also keine Garantie, dass die Ausgabe nützlich oder sinnvoll sein wird. Yan LeCun, der Direktor von Facebook AI Research, sagte:
„Wenn Intelligenz ein Kuchen ist, dann besteht der Großteil des Kuchens aus unüberwachtem Lernen, das Sahnehäubchen auf dem Kuchen ist überwachtes Lernen und die Kirsche auf dem Kuchen ist bestärkendes Lernen (RL).“
Yann LeCun
Unüberwachtes Lernen ist nur ein, aber dennoch wichtiges Element des maschinellen Lernens, das dazu beitragen wird, die KI in Richtung einer verlässlichen und dynamischen Zukunft voranzubringen.
Ihre NLP-Karriere wartet!
Bereit für den nächsten Schritt in Ihrer NLP-Reise? Vernetzen Sie sich mit Top-Arbeitgebern, die Talente in der natürlichen Sprachverarbeitung suchen. Entdecken Sie Ihren Traumjob!
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.
Große daten
Große Daten
Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
Ki im finanzwesen
KI im Finanzwesen
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you
Transform Unstructured Data into Actionable Insights