Wir haben ein Tool entwickelt, das auf der Verarbeitung natürlicher Sprache basiert und Forschern in den Sozialwissenschaften dabei helfen soll, Datensätze aus unterschiedlichen Kontexten zu harmonisieren . Dies ist Teil eines umfassenderen Projekts namens Harmony , das Teil eines Beitrags ist, den wir gemeinsam mit dem Centre for Longitudinal Studies am UCL , der Ulster University und der Universidade Federal de Santa Maria in Brasilien für den Wellcome Mental Health Data Prize einreichen.
Im Mittelpunkt des Harmony-Projekts steht eine Forschungsfrage:
Welchen Einfluss haben soziale Kontakte auf Ängste und Depressionen bei jungen Menschen in verschiedenen Ländern?
Wir haben uns auf zwei sehr unterschiedliche Kontexte konzentriert: Großbritannien und Brasilien. Wir haben numerische Messungen der sozialen Verbundenheit untersucht, die in Umfragen und Fragebögen gemessen werden können.
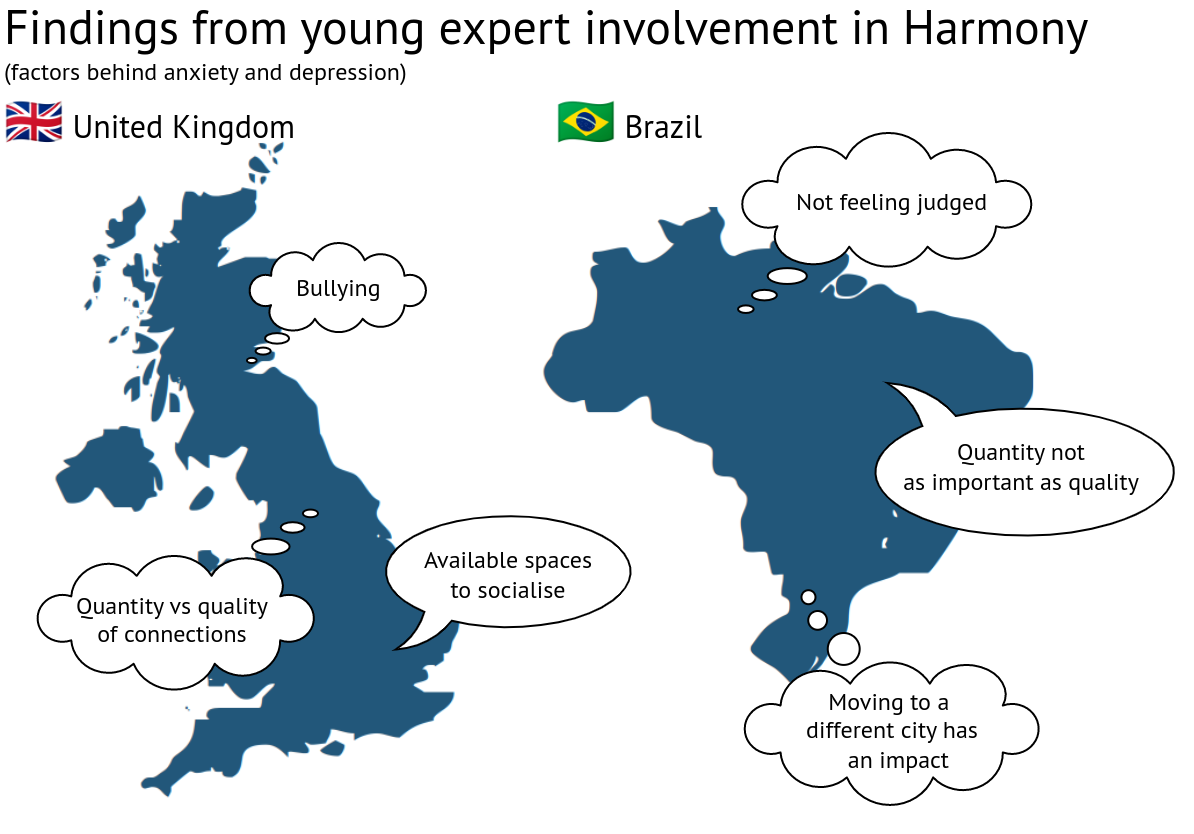
Die Harmony-Forscher führten eine Reihe von Sitzungen mit jungen Menschen in beiden Ländern durch, um qualitative Daten zu individuellen Erfahrungen zu sammeln.
In Brasilien interviewte unser Psychologe sechs Personen zwischen 13 und 18 Jahren, die wegen Angstzuständen und Depressionen in Behandlung waren, und befragte sie zu ihrem Konzept sozialer Kontakte und deren Zusammenhang mit Angstzuständen und Depressionen.
Fast Data Science - London
Bei diesen Initiativen zeigten sich einige Unterschiede. So nannten britische Jugendliche beispielsweise Mobbing als einen der Hauptfaktoren, während brasilianische Teilnehmer angaben, sich nicht verurteilt zu fühlen.
Für Großbritannien und Brasilien stehen Datensätze zur Verfügung, mit denen wir arbeiten konnten:
UK Millennium Cohort Study , auch bekannt als „Kind des neuen Jahrhunderts“. Dies ist eine Studie des Centre for Longitudinal Studies des UCL, die das Leben von rund 19.000 jungen Menschen untersucht, die zwischen 2000 und 2002 in Großbritannien geboren wurden.
Die brasilianische Hochrisiko-Kohortenstudie für psychiatrische Störungen im Kindesalter (BHRC) ist eine Studie, die seit 2010 2.511 brasilianische Kinder begleitet und dabei psychologische, genetische und bildgebende Daten erfasst. Ziel der Studie ist es, typische und atypische Verläufe von Psychopathologie und kognitiven Fähigkeiten im Laufe der Entwicklung zu untersuchen.
Diese Datensätze enthalten Variablen und Datenpunkte, die auf unterschiedliche Weise dargestellt werden können. Wenn wir eine Metaanalyse durchführen möchten (den Zusammenhang zwischen sozialer Bindung, Angst und Depression in beiden Ländern vergleichen), müssen wir zunächst feststellen, welche Variablen in beiden Datensätzen verfügbar sind, welche Variablen sie gemeinsam haben und wie wir die Informationen in diesen Variablen vergleichen können.
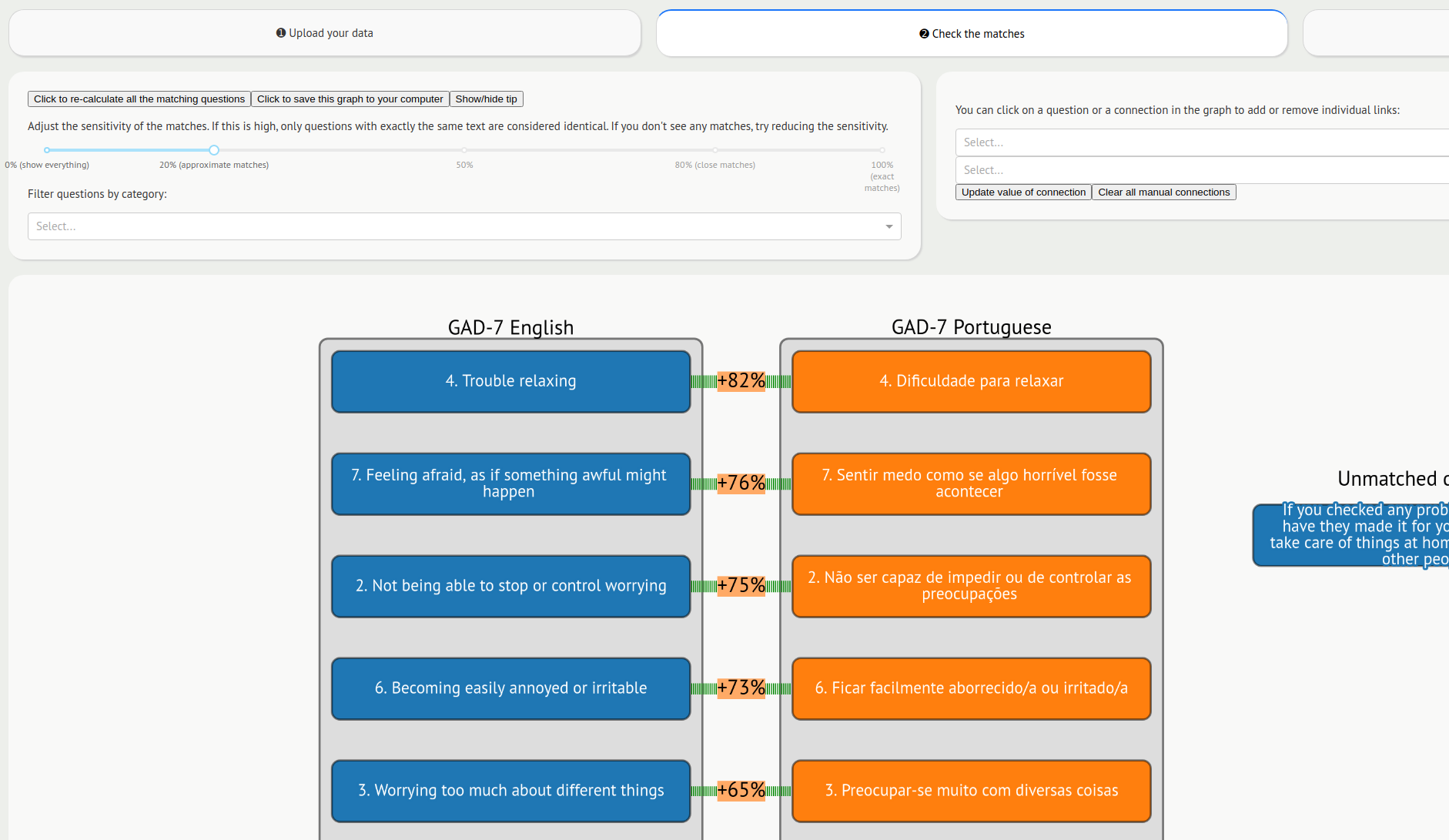
Wenn beispielsweise in einer Studie Ängste mithilfe des GAD-7 gemessen wurden und in einer anderen Studie Becks Angstinventar , erfolgte typischerweise ein manueller Harmonisierungsprozess zur Ermittlung gleichwertiger Fragebogenelemente.

Wir hatten die Idee, jedes Fragebogenelement als Vektor auf der Oberfläche einer mehrdimensionalen Kugel darzustellen. Elemente, die semantisch ähnlich sind, würden nah beieinander liegen und eine Kosinusähnlichkeit nahe 1 aufweisen, während Elemente, die völlig unterschiedlich sind, eher eine Ähnlichkeit nahe 0 aufweisen.
Wir haben das Deep-Learning -Modell GPT-2 verwendet, um Texte in verschiedenen Sprachen in ihre Vektordarstellungen umzuwandeln. Wir haben dies in ein Web-Frontend verpackt, um ein webbasiertes Tool namens Harmony zu erstellen. Sie können es online unter https://harmonydata.ac.uk/app ausprobieren.
Wir haben Harmony außerdem in Zusammenarbeit mit DATAMIND und dem Catalogue of Mental Health Measures entwickelt, die in der psychologischen Forschung weit verbreitete Ressourcen sind, und ihr Feedback zur Verbesserung des Tools berücksichtigt.
Im Harmony-Blog können Sie mehr über Harmony und seine Funktionsweise erfahren.
Radford, Alec, et al. „Sprachmodelle sind unüberwachte Multitask-Lerner.“ OpenAI Blog 1.8 (2019): 9.
Salum, Giovanni Abrahão. „Hochrisiko-Kohortenstudie für psychiatrische Störungen im Kindesalter.“
Smith, Kate und Heather Joshi. „Die Millennium-Kohortenstudie.“ POPULATION TRENDS-LONDON- (2002): 30-34.
Entfesseln Sie das Potenzial Ihrer NLP-Projekte mit dem richtigen Talent. Veröffentlichen Sie Ihre Stelle bei uns und ziehen Sie Kandidaten an, die genauso leidenschaftlich über natürliche Sprachverarbeitung sind.
NLP-Experten einstellen
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you