Links: eine gutartige Mammographie, rechts: eine Mammographie, die einen Krebstumor zeigt. Quelle: National Cancer Institute
Möglicherweise haben Sie von der jüngsten Google Health-Studie gelesen, in der die Forscher ein KI-Modell trainiert und evaluiert haben, um Brustkrebs in Mammogrammen zu erkennen.
In den Medien wurde berichtet, dass das Modell des Google-Teams bei der Erkennung von Tumoren in Mammogrammen genauer sei als ein einzelner Radiologe, wenngleich es einem Team aus zwei Radiologen unterlegen sei.
Aber was bedeutet hier „genauer“? Und wie können Wissenschaftler dies einem Laienpublikum mitteilen?
Stellen Sie sich vor, wir hätten ein Modell, um Bilder in zwei Gruppen zu kategorisieren: bösartig und gutartig. Stellen Sie sich vor, Ihr Modell kategorisiert alles als gutartig, während in Wirklichkeit 10 % der Bilder bösartig und 90 % gutartig sind. Dieses Modell wäre nutzlos, hätte aber auch eine Genauigkeit von 90 %.
Dies ist ein einfaches Beispiel dafür, warum Genauigkeit oft irreführend sein kann.
Tatsächlich ist es in einem Fall wie diesem hilfreicher, zwei Zahlen zu melden: wie viele bösartige Bilder fälschlicherweise als gutartig klassifiziert wurden (falsch-negative Ergebnisse) und wie viele gutartige Bilder fälschlicherweise als bösartig klassifiziert wurden (falsch-positive Ergebnisse).
Das Google-Team berichtete in seinem Artikel über beide Fehlerraten:
Wir zeigen eine absolute Reduktion von 5,7 % … bei falsch positiven und 9,4 % … bei falsch negativen Ergebnissen [im Vergleich zu menschlichen Radiologen].
McKinney et al., Internationale Evaluierung eines KI-Systems für das Brustkrebs-Screening, Nature (2020)
Das bedeutet, dass sich das Modell bei beiden Arten von Fehlklassifizierungen verbessert hat. Hätte sich nur eine Fehlerquote gegenüber den menschlichen Experten verbessert, ließe sich nicht sagen, ob die neue KI besser oder schlechter als der Mensch ist.
Manchmal möchten wir die Leistung unseres Modells sogar noch genauer kontrollieren. Das Mammographiemodell kennt zwei Arten von Fehldiagnosen: falsch positiv und falsch negativ. Aber sie sind nicht gleich. Obwohl keine der beiden Fehlerarten wünschenswert ist, sind die Folgen eines übersehenen Tumors schwerwiegender als die Folgen eines Fehlalarms.
Aus diesem Grund möchten wir möglicherweise die Sensitivität eines Modells kalibrieren. Oftmals beinhaltet die letzte Phase eines maschinellen Lernmodells die Ausgabe eines Scores: die Wahrscheinlichkeit, dass ein Tumor vorhanden ist.
Fast Data Science - London
Aber letztendlich müssen wir entscheiden, welche Maßnahmen zu ergreifen sind: den Patienten zur Biopsie zu überweisen oder ihn zu entlassen. Sollten wir handeln, wenn der Wert unseres Modells über 50 % liegt? Oder 80 %? Oder 30 %?
Wenn wir unseren Grenzwert auf 50 % festlegen, weisen wir beiden Aktionen das gleiche Gewicht zu.
Wir möchten den Grenzwert jedoch wahrscheinlich niedriger festlegen, beispielsweise 25 %. Dies bedeutet, dass wir auf Nummer Sicher gehen, da es uns nichts ausmacht, einige gutartige Bilder als bösartig zu melden, wir aber wirklich vermeiden möchten, bösartige Bilder als gutartig einzustufen.
Wir können den Grenzwert jedoch nicht auf 0 % setzen – das würde bedeuten, dass unser Modell alle Bilder als bösartig klassifizieren würde, was nutzlos ist!
In der Praxis können wir also den Grenzwert variieren und auf einen Wert einstellen, der unseren Anforderungen entspricht.
Die Wahl des besten Grenzwertes ist mittlerweile ein schwieriger Balanceakt.
Wenn wir unabhängig von seinem Grenzwert beurteilen möchten, wie gut unser Modell ist, können wir einen cleveren Trick ausprobieren: Wir können den Grenzwert auf 0 %, 1 %, 2 % bis hin zu 100 % setzen. Bei jedem Grenzwert prüfen wir, wie viele bösartige → gutartige und gutartige → bösartige Fehler aufgetreten sind.
Anschließend können wir die sich ändernden Fehlerraten als Diagramm darstellen.
Wir nennen dies eine ROC- Kurve (ROC steht für Receiver Operating Characteristic).
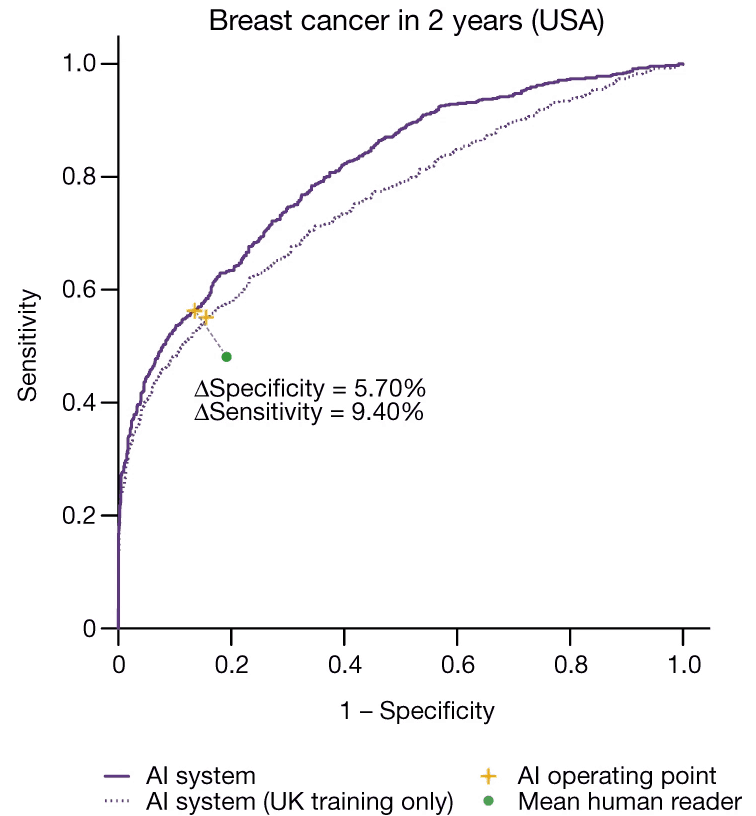
Dies ist die ROC-Kurve des Google-Mammogrammmodells. Die Y- Achse ist die Rate der richtig positiven Ergebnisse und die X- Achse die Rate der falsch positiven Ergebnisse. Quelle: McKinney et al (2020)
Das Schöne an einer ROC-Kurve ist, dass Sie auf einen Blick sehen können, wie ein Modell funktioniert. Wenn Ihr Modell nur ein Münzwurf wäre, wäre Ihre ROC-Kurve eine gerade diagonale Linie von unten links nach oben rechts. Die Tatsache, dass Googles ROC-Kurve nach oben und links abknickt, zeigt, dass sie besser ist als ein Münzwurf.
Wenn wir eine einzelne Zahl benötigen, um zusammenzufassen, wie gut ein Modell ist, können wir den Bereich unter der ROC-Kurve nehmen. Dies wird als AUC ( Bereich unter der Kurve ) bezeichnet und funktioniert beim Vergleich verschiedener Modelle viel besser als die Genauigkeit. Ein Modell mit einem hohen AUC ist besser als eines mit einem niedrigen AUC. Dies bedeutet, dass ROC-Kurven sehr nützlich sind, um verschiedene KI-Modelle zu vergleichen.
Sie können auch menschliche Leser auf eine ROC-Kurve setzen. So enthält Googles ROC-Kurve einen grünen Datenpunkt für die menschlichen Radiologen, die die Mammogramme interpretiert haben. Die Tatsache, dass der grüne Punkt näher an der Diagonale liegt als jeder andere Punkt auf der ROC-Kurve, bestätigt, dass das maschinelle Lernmodell tatsächlich besser war als der durchschnittliche menschliche Leser.
Ob das maschinelle Lernmodell die besten menschlichen Radiologen übertroffen hat, ist natürlich eine andere Frage.
Im Gesundheitswesen können die Kosten eines falsch negativen oder falsch positiven Ergebnisses im Gegensatz zu anderen Bereichen des maschinellen Lernens enorm sein. Aus diesem Grund müssen wir Modelle sorgfältig bewerten und bei der Wahl des Grenzwertes eines Klassifikators für maschinelles Lernen wie dem Mammographie-Klassifikator sehr konservativ vorgehen.
Wichtig ist auch, dass eine Person, die nicht an der Entwicklung des Modells beteiligt ist, das Modell sehr kritisch beurteilt und testet.
Sollte die Mammographie in der allgemeinen Gesundheitsversorgung eingeführt werden, würde ich erwarten, dass ihre Eignung durch die folgenden strengen Kontrollen nachgewiesen wird:
Wenn Sie meinen, ich habe etwas vergessen, lassen Sie es mich bitte wissen. Ich denke, wir sind kurz davor, diese Modelle in unseren Krankenhäusern in Aktion zu sehen, aber es sind noch viele unbekannte Schritte zu unternehmen, bevor die KI-Revolution das Gesundheitswesen erobert.
Danke an Ram Rajamaran für einige interessante Diskussionen zu diesem Problem!
Hamzelou, KI-System kann Brustkrebs besser vorhersagen als menschliche Ärzte , New Scientist (2020).
McKinney et al. , Internationale Evaluierung eines KI-Systems für das Brustkrebs-Screening , Nature (2020).
Suchen Sie Experten in Natürlicher Sprachverarbeitung? Veröffentlichen Sie Ihre Stellenangebote bei uns und finden Sie heute Ihren idealen Kandidaten!
Veröffentlichen Sie einen Job
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you