
Können symbolische KI, maschinelles Lernen oder hybride KI (eine Mischung aus beidem) für die juristische Argumentation verwendet werden?
Ich habe mich mit dem Problem des juristischen Denkens mit KI beschäftigt. Juristisches Denken ist der Prozess, bei dem man unter Verwendung von Fakten und Informationen über das Gesetz zu einer rechtlichen Entscheidung kommt, und es ist eines der schwierigsten Probleme innerhalb der juristischen KI . Während ML-Modelle und andere praktische Anwendungen der Datenwissenschaft die einfacheren Teile der KI-Strategieberatung sind, ist juristisches Denken viel kniffliger.
Ein Richter nutzt die juristische Argumentation, um zu einer logischen Schlussfolgerung zu gelangen, beispielsweise um zu entscheiden, ob ein Angeklagter schuldig ist oder nicht.
Um eine juristische Argumentation anwenden zu können, muss ein Richter die Fakten eines Falls, die Frage, die einschlägige Gesetzgebung und etwaige Präzedenzfälle (in Rechtsräumen des Common Law) identifizieren.
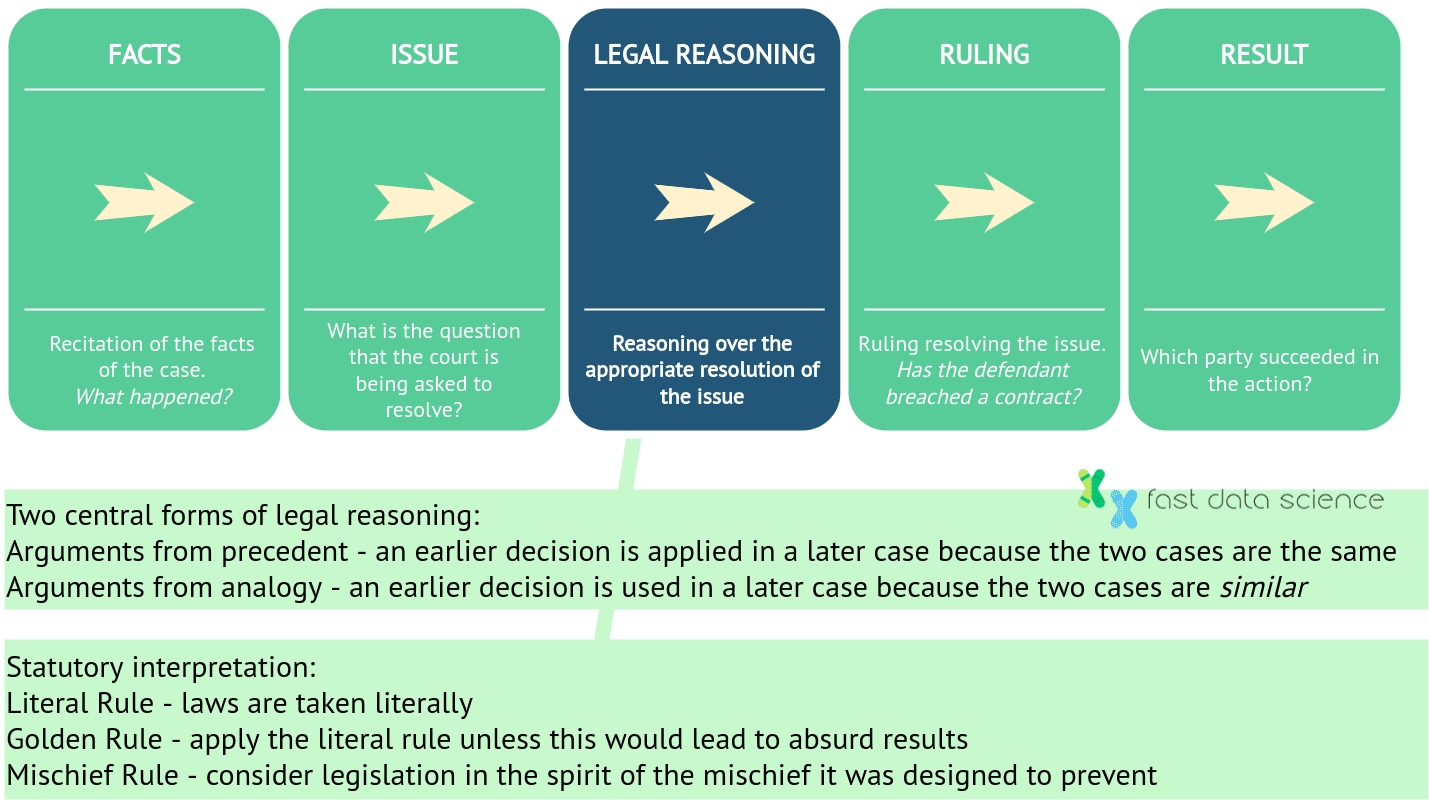
In Common Law-Systemen wie England und den USA besteht ein Urteil aus fünf Schritten: Zunächst müssen die Fakten des Falles festgestellt werden, das rechtliche Problem oder die Frage muss identifiziert werden, und dann wird eine juristische Argumentation auf die Fakten und die Frage angewendet. Schließlich wird ein Urteil gefällt und das Gericht entscheidet über ein Ergebnis. Bei der juristischen Argumentation werden sowohl frühere Fälle als auch das Gesetzesrecht betrachtet. Die Frage ist, ob entweder symbolische KI, maschinelles Lernen oder hybride KI (eine Mischung aus beidem) zur juristischen Argumentation fähig sind.
Seit den 1970er Jahren experimentieren KI-Forscher mit symbolischer KI zur Lösung juristischer Probleme. Bei der symbolischen KI wurde traditionell eine Darstellung der realen Welt mithilfe einer logischen Programmiersprache wie Lisp oder Prolog in einen Computer kodiert.
Logische Programmiersprachen sind Sprachen, die sich gut dazu eignen, Konzepte wie „Eine Katze ist ein Säugetier“ , „Alle Säugetiere produzieren Milch“ darzustellen und daraus zu folgern, dass eine Katze deshalb Milch produziert .
Das obige Beispiel kann in Prolog wie folgt ausgedrückt werden:

Ein Beispiel für ein Logikprogramm in Prolog.
Heutzutage scheint die symbolische KI etwas in Ungnade gefallen zu sein. Ich habe nicht viele Unternehmen gesehen, die symbolische KI für kommerzielle Zwecke nutzen. In der Wissenschaft ist symbolische KI immer noch ein heißes Thema. Datenwissenschaftler in der Industrie verwenden normalerweise maschinelles Lernen und prädiktive Modellierungstechniken, die in Bereichen leistungsstark sind, in denen große Datenmengen verfügbar sind, und datengesteuerte Ansätze wie neuronale Netzwerke dominieren mittlerweile das Feld. Auf der anderen Seite erfordert symbolische KI oft einen enormen manuellen Aufwand, um die reale Welt in eine Wissensbasis zu kodieren, und kann schwer skalierbar sein.
Ich werde einige der Ansätze diskutieren, die im Laufe der Jahre im Bereich der juristischen KI verfolgt wurden. Für einige Aufgaben war handcodierte symbolische KI in Prolog beliebt, während Forscher bei einfacheren Aufgaben und der Verfügbarkeit der entsprechenden Daten maschinelle Lernmodelle trainiert haben. Wenn symbolische KI mit maschinellem Lernen kombiniert wird, wird dies oft als hybride KI bezeichnet. In den nächsten Abschnitten werde ich einen Überblick über die beiden Ansätze geben.
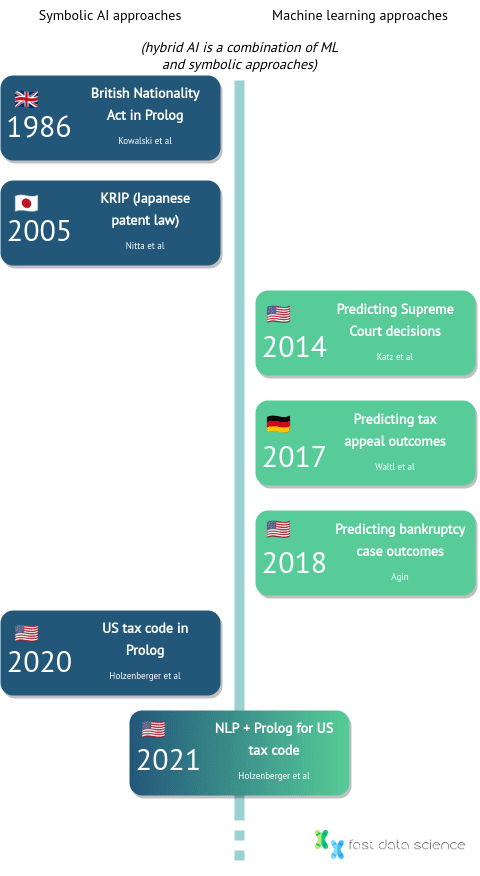
Eine Zeitleiste der Entwicklung einiger wichtiger juristischer KI-Systeme, von Kowalskis British Nationality Act im Jahr 1986 bis zum heutigen Tag.
Zahlreiche Forscher untersuchen die Möglichkeiten symbolischer KI im Rechtswesen. Ein Ansatz einiger Informatiker besteht darin, ein Gesetz, beispielsweise ein Parlamentsgesetz, als Logikprogramm darzustellen, die Fakten eines Falls in dieselbe logische Darstellung umzuwandeln und die juristische Argumentation als Abfrage in dieser Logiksprache durchzuführen.
Dies erscheint mir einfacher als der Versuch, Rechtsprechung zu modellieren und Argumente aus Präzedenzfällen oder Analogien rechnerisch zu simulieren.
Im Vergleich zu Zivilrechtssystemen wie dem französischen Recht stellt das englische Recht einige besondere Herausforderungen für juristische NLP- und juristische KI-Modelle dar. Die juristische Argumentation im englischen Recht umfasst die Interpretation von Gesetzen und früheren Urteilen sowie die Feststellung, wann Grundsätze wie stare decisis (ein früheres Urteil wird als maßgebend angesehen) anzuwenden sind. Dies mit symbolischer KI zu codieren ist unglaublich komplex.
Englische Verträge sind in der Regel sehr ausführlich. Trotzdem ist das englische Recht wahrscheinlich eines der attraktivsten Rechtssysteme für die Modellierung mit KI, da Vertragsparteien häufig England und Wales als Gerichtsstand ihrer Wahl wählen und Streitigkeiten regelmäßig vor dem Londoner Handelsgericht beigelegt werden, wenn keiner der Prozessbeteiligten in Großbritannien ansässig ist.
Einer der bahnbrechenden Versuche, die Argumentation auf Gesetzesrecht anzuwenden, ist die Modellierung des British Nationality Act als Logikprogramm durch den amerikanisch-britischen Logiker Robert Kowalski und andere, die 1986 veröffentlicht wurde. Das Team konzentrierte sich auf das Gesetzesrecht, da dieses „definitorischer Natur“ ist und sich leichter in Logik übertragen lässt. Sie wählten insbesondere den British Nationality Act von 1981 , da dieser als präzise Reihe von Regeln angelegt und relativ in sich geschlossen war – obwohl er einige vage Formulierungen enthielt, wie z. B. „ ein guter Charakter sein“ , „einen triftigen Grund haben“ und „ über ausreichende Englischkenntnisse verfügen“ .
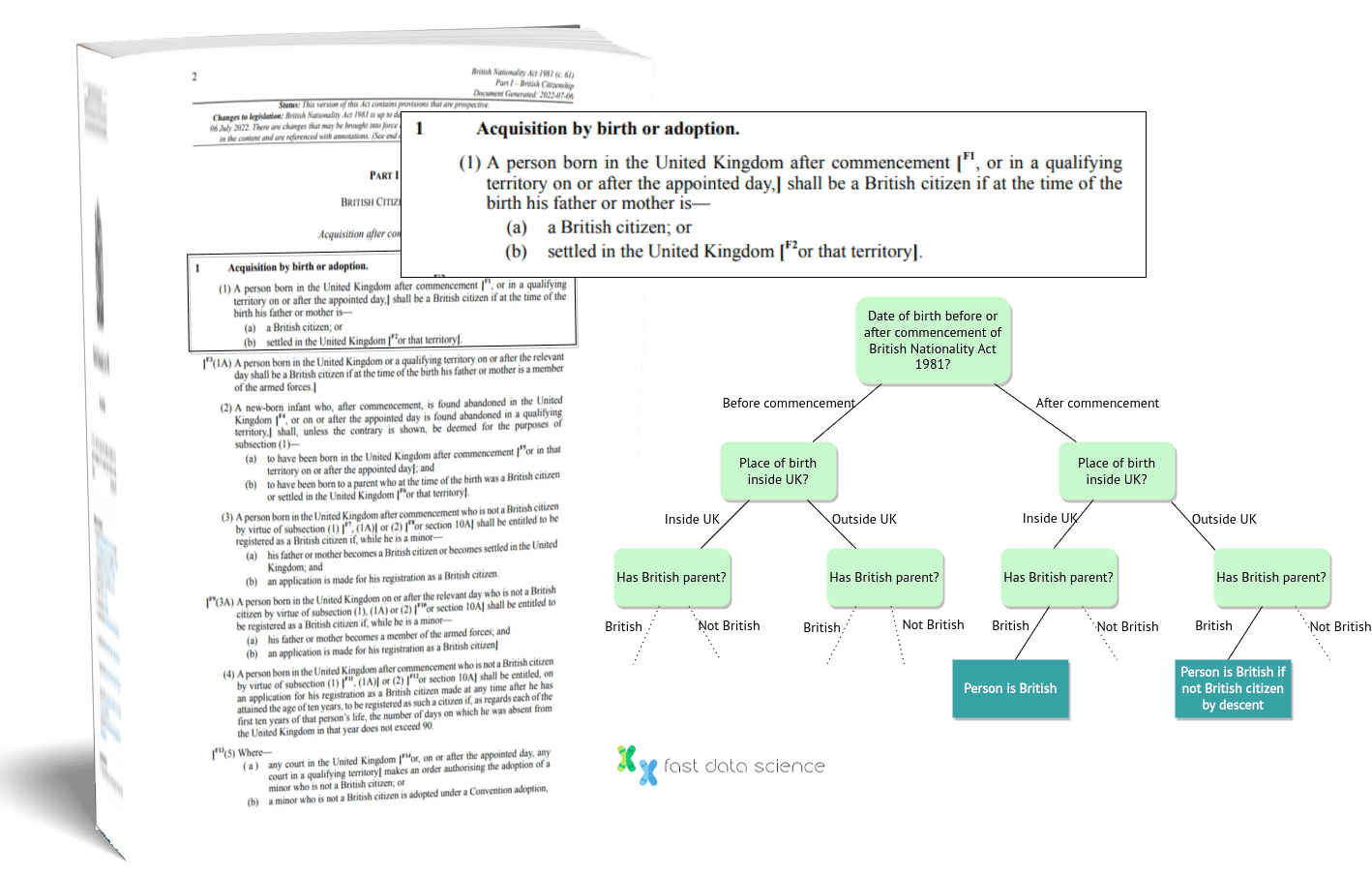
Schematische Darstellung eines Teils von Robert Kowalskis logischer Darstellung des British Nationality Act.
Obwohl Kowalskis Darstellung des British Nationality Act bahnbrechend war, war es nicht als voll funktionsfähiges System gedacht und seine Grenzen sind offensichtlich.
Im Jahr 2005 entwickelte Katsumi Nitta ein System namens KRIP , ein Expertensystem für das japanische Patentrecht. Er verwendete symbolische KI (Prädikatenlogik), um einen begrenzten Rechtsabschnitt für einen engen Bereich (Patentrecht) zu kodifizieren, dessen Regeln relativ einfach in eine Wissensbasis einzutragen sind.
Im Jahr 2021 kodierte Nils Holzenberger von der Johns Hopkins University zusammen mit einer größeren Forschungsgruppe einen Abschnitt des US-Steuergesetzes in Prolog . Sie erstellten ein System, bei dem der Benutzer Fragen stellen kann wie: „Wenn Mary 2018 geheiratet hat und letztes Jahr 40.000 Dollar verdient hat, wie viel Steuern muss sie zahlen ?“
Das Steuerrecht ist ein interessanter Fall, da es für die meisten Probleme eine einfache, eindeutige Antwort gibt ( wie viel Steuern müssen gezahlt werden? ) und die Regeln meist im Gesetz festgelegt sind (auch wenn sich Juristen über die Bedeutung einzelner Wörter streiten können).
Natural language processing
Das Team ging das Problem so an, dass es zunächst Gesetze und die Fakten eines Falles manuell in eine logische Darstellung in Prolog übersetzte. Sie können den Schieberegler unten bewegen, um zu sehen, wie ein Absatz des Steuergesetzes aussieht, nachdem er in Prolog übersetzt wurde:

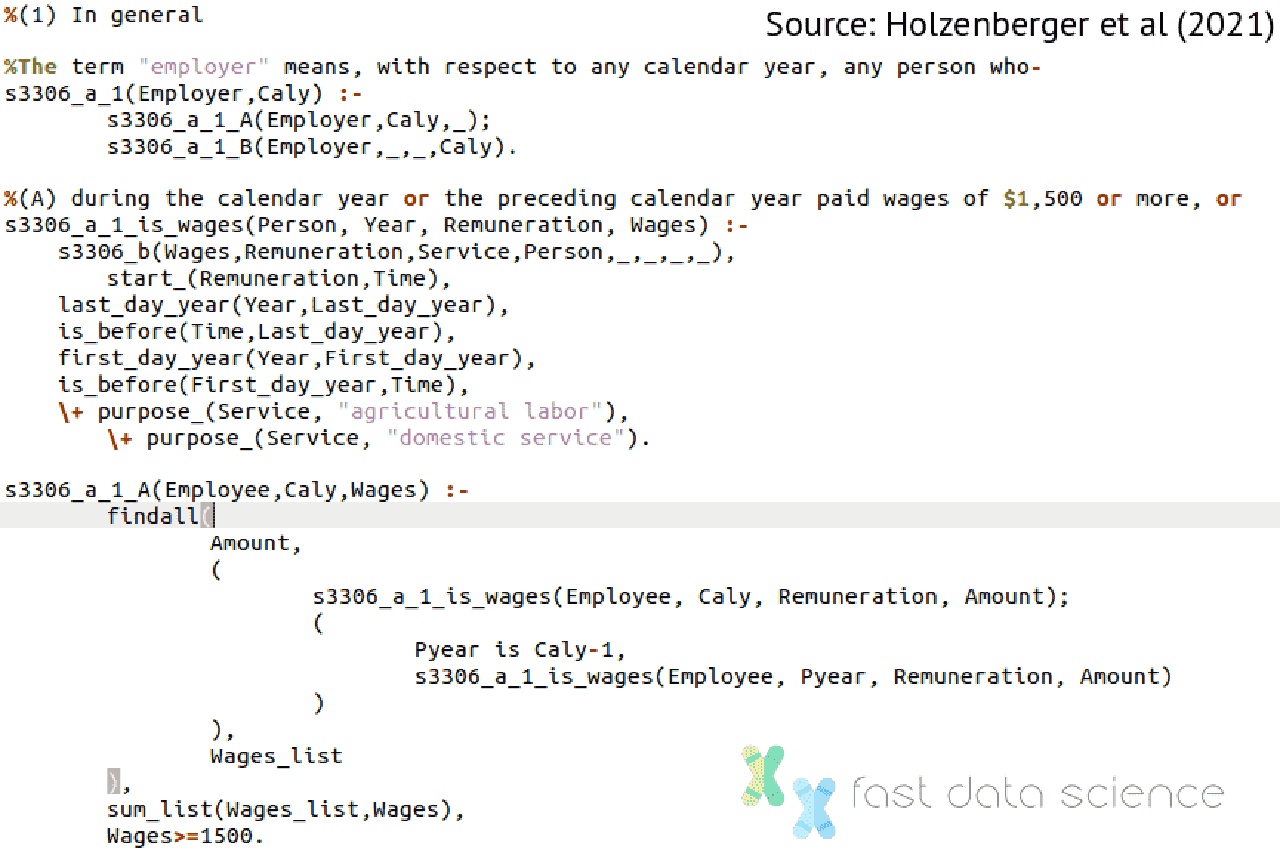
Da der Prolog-Code in diesem Fall manuell generiert wurde, hatte das Modell per Definition eine Genauigkeit von 100 % – vorausgesetzt natürlich, dass der Prolog-Code keine Fehler enthält.
Das Problem besteht jedoch darin, dass Rechtstexte nicht im Prolog-Format verfügbar sind und es schwierig ist, alles in Prolog zu übersetzen.
Anschließend experimentierte das Team mit NLP- Tools wie Transformatoren , um Gesetze und Fakten zu analysieren und die geschuldete Steuer als Regressionsproblem vorherzusagen und dabei die Prolog-Darstellung zu umgehen.
Holzenbergers Team versuchte dann, das Problem in mehrere Schritte des Sprachverständnisses aufzuteilen, gefolgt von einer Slot-Füllphase, in der Variablen (wie Gehalt, Ehepartner, Wohnsitz) mit Informationen für den jeweiligen Fall gefüllt werden. Dies funktionierte etwas besser als der vorherige Ansatz. Sie stellten jedoch fest, dass es sehr schwierig war, die Struktur eines Satzes zu analysieren, da die Formulierung so variabel sein kann.
Andere Forscher wenden sich von der logischen Programmierung ab und nutzen maschinelle Lernverfahren in der Rechtswissenschaft. 2014 trainierten Daniel Katz und sein Team am Illinois Tech ein maschinelles Lernmodell, um die Entscheidungen der Richter des Obersten Gerichtshofs vorherzusagen.
In Deutschland trainierten Bernhard Waltl und andere Forscher an der Technischen Universität München im Jahr 2017 anhand von 5.990 Steuerrechtsberufungen einen Klassifikator für maschinelles Lernen, um anhand von 11 Merkmalen den Ausgang einer neuen Steuerrechtsberufung vorherzusagen.
Im Jahr 2018 trainierte Warren Agin ein maschinelles Lernmodell, um den Erfolg oder Misserfolg von Konkursverfahren nach Chapter 13 vorherzusagen. Dabei verwendete er Merkmale wie die District Success Ratio (die Erfolgsquote bei Konkursen nach Standort), die gesamten unbesicherten nicht vorrangigen Schulden, die Lücke zwischen Einnahmen und Ausgaben und andere. Das Modell war in der Lage, den Ausgang eines Konkursantrags mit einer Genauigkeit von 70 % und einem AUC von 71 % vorherzusagen.
Ich bin überzeugt, dass maschinelles Lernen im Rechtsbereich funktionieren kann, wo es viele ähnliche Fälle gibt, wie etwa Steuerurteile, Konkursanträge und Entscheidungen im Familienrecht. Allgemeinere juristische Arbeiten, die eine komplexe Analyse von Gesetzen und Präzedenzfällen erfordern können, wären mit maschinellem Lernen jedoch nur sehr schwer zu bewältigen.
Obwohl das US-Steuerrecht unglaublich komplex ist, handelt es sich dennoch um eine Frage der Gesetzesauslegung und kann mit genügend Geduld in Prolog codiert werden.
Was können wir tun, wenn wir ein Rechtsproblem haben, das sowohl Gesetze als auch Präzedenzfälle betrifft, wie es in Common-Law-Rechtsräumen wie England und den USA häufig vorkommt?
Im englischen Recht gibt es eine Reihe von Grundsätzen, die Richter zur Auslegung von Gesetzen heranziehen können. Es gibt eine Literalregel , die besagt, dass Gesetze wörtlich im üblichen Sinne des Wortes ausgelegt werden müssen. Richter kennen außerdem die Goldene Regel , die besagt, dass der Wortlaut von Gesetzen wörtlich auszulegen ist, sofern dies nicht zu absurden Schlussfolgerungen führen würde. Schließlich gibt es noch die Mischief-Regel , die besagt, dass ein Richter berücksichtigen muss, welchen Unfug ein Gesetz eigentlich verhindern soll. Diese Grundsätze wurden zu unterschiedlichen Zeitpunkten in der Geschichte entwickelt und führten zu dem angemessenen Ermessensspielraum, über den Richter heute verfügen.
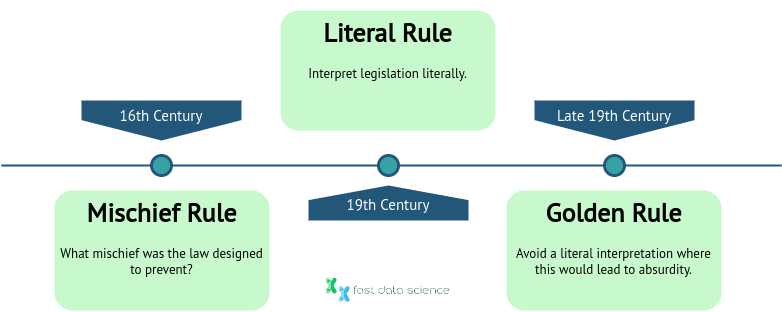
Zeitleiste der Entwicklung der drei wichtigsten Regeln zur Gesetzesauslegung: Im 16. Jahrhundert gewährte die ursprüngliche „Mischief Rule“ den Richtern einen beträchtlichen Spielraum, im Viktorianischen Zeitalter ging der Trend dann in Richtung einer wörtlichen Gesetzesauslegung und schließlich bewegten wir uns mit der „Goldenen Regel“ wieder zurück zu einer vernünftigen Interpretation des Gesetzeszwecks.
Ein Beispiel für die Anwendung der „Mischief Rule“ ist Corkery v Carpenter (1951), wo der Angeklagte betrunken Fahrrad fuhr und aufgrund eines Gesetzes aus der viktorianischen Zeit ( Licensing Act 1872 ) verhaftet wurde, in dem „Kutschen“ erwähnt wurden. Der Richter entschied, dass der fragliche „Mischief“ derselbe sei, egal ob eine Person Fahrrad oder Pferdekutsche fährt.

Der einleitende Absatz des Urteils R. gegen Bentham (2005), in dem der Sachverhalt dargelegt wird.
Ein interessanter Fall, in dem AI aufgrund unterschiedlicher Gesetzesauslegungen in Schwierigkeiten geraten könnte, ist R v Bentham . Dabei handelte es sich um ein Berufungsverfahren, das 2005 an das House of Lords in England ging.
Der Angeklagte, Peter Bentham, beging einen Raubüberfall und versteckte seinen ausgestreckten Finger unter den Falten seiner Jacke, um absichtlich den Eindruck zu erwecken, er hätte eine Waffe. Sein Opfer, das glaubte, er hätte eine Waffe, übergab ihm Wertgegenstände.
Im Berufungsgericht wurde Bentham nach dem Firearms Act von 1968 verurteilt, der Bestimmungen zu „Imitationsfeuerwaffen“ enthält.

Kann ein Finger als eine Nachahmung einer Feuerwaffe angesehen werden?
Bentham legte später Berufung ein und der Fall ging an das House of Lords, das seiner Berufung stattgab, weil ein menschlicher Finger nach Ansicht der Richter nicht als Nachahmung einer Feuerwaffe angesehen werden könne, da es sich bei ihm um einen Körperteil handele.
Das untere Gericht (das Berufungsgericht) wandte die „Mischief Rule“ an, das House of Lords interpretierte das Waffengesetz jedoch wörtlicher und hob das Urteil aus formalen Gründen auf.
Angesichts der enormen Fortschritte, die in den letzten Jahren bei Transformatoren erzielt wurden, war mein erster Instinkt, dass ein Transformatormodell wie BERT oder GPT-2 in der Lage sein sollte, Fragen zu dem Fall zu beantworten.
Ich habe versucht, die Fakten des Falls in BERT einzugeben und Fragen zu stellen wie: „Wer ist der Angeklagte?“ , „Welcher Tat wird der Angeklagte beschuldigt?“ und „Wann hat das Verbrechen stattgefunden ?“ Obwohl BERT manchmal in der Lage war, die Antworten im Text zu finden und Teilstrings des Textes zu lokalisieren, ist dies weit davon entfernt, Informationen wirklich zu verstehen und abzurufen. Im Wesentlichen stellte ich fest, dass dies ein sehr ausgeklügeltes Informationsabrufsystem war, das jedoch nicht annähernd die Komplexität erreichte, die zur Modellierung der realen Welt erforderlich ist.
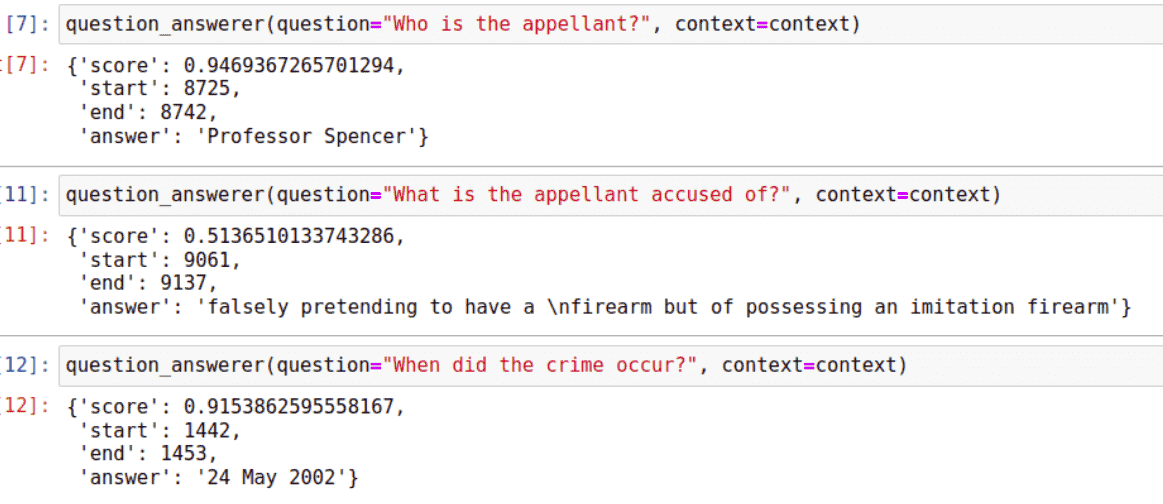
So reagierte BERT auf Fragen zu R v Bentham
Es gibt eine Reihe von Möglichkeiten, reale Ereignisse und ihre Auswirkungen in logischen Sprachen wie Prolog darzustellen, etwa die Ereignisrechnung , eine logische Methode zur Darstellung von Ereignissen und ihren Auswirkungen, die 1986 von Robert Kowalski und Marek Sergot entwickelt wurde.
Ich habe eine relativ einfache Methode zur Modellierung natürlichsprachlicher Texte gewählt, bei der alle Verben oder Präpositionen in einen Prolog-Ausdruck der Form übersetzt werden:
Aktion (Subjekt, Objekt, Zeit)
Die Sätze „Der Angeklagte ist am 9. Juli 2001 in das Haus eingebrochen“ oder „Das Haus wurde am 9. Juli 2001 vom Angeklagten eingebrochen“ lauten also beide:
Einbruch (Angeklagter, Haus, Datum\_20010709)
Wenn alle Informationen eines Textes in dieses Format übersetzt werden, ist die Abfrage einfacher, es weist jedoch einige Mängel auf, beispielsweise bei der Darstellung von Unterabschnitten.
Auf diese Weise kann eine Ereignisfolge in eine Reihe unabhängiger Prädikate zerlegt werden. Der große Vorteil von Prolog besteht darin, dass es fehlertolerant ist und normalerweise Fehler in einer Zeile ignoriert und mit der nächsten Zeile fortfährt.
Urteile des House of Lords können im PDF-Format vom Webportal des britischen Parlaments heruntergeladen werden.
Ich habe eine einfache Weboberfläche entwickelt, die in einem sehr engen Rahmen ein Urteil im PDF-Format verarbeiten, den Sachverhalt ermitteln und die entsprechende Gesetzesbegründung anwenden kann.
Der Ablauf funktioniert folgendermaßen:
Um das Prolog-Rechtsbegründungsmodell zu R v Bentham zu testen, habe ich die relevanten Abschnitte des Firearms Act 1968 manuell in Prolog übersetzt. Der relevante Abschnitt des Firearms Act besagt lediglich, dass eine Person schuldig ist, wenn sie eine Straftat wie Raub begeht und im Besitz einer Feuerwaffe oder einer Nachahmung einer Feuerwaffe ist – es wird jedoch nicht explizit angegeben, ob ein Finger als Nachahmung einer Feuerwaffe gelten könnte.
Ich habe in meinen Prolog-Code eine Option zum Anwenden oder Ignorieren der Unfugregel aufgenommen, um eine strenge oder lockere Auslegung des Gesetzes zu ermöglichen.
Ich habe den Prolog-Code für die Gesetzgebung mit dem Prolog-Code, der die Fakten des Falls R. v. Bentham beschreibt, verknüpft und konnte eine Abfrage durchführen, um herauszufinden, ob jemand nach dem Waffengesetz von 1968 schuldig war.
Durch die Möglichkeit, die Unfugregel ein- und auszuschalten, kann ein Benutzer beide Interpretationen eines Urteils sehen.
Dank dieser Flexibilität konnte mein Prolog-Code sowohl die Urteile des ursprünglichen Berufungsgerichts, das Bentham verurteilt hatte, als auch die des House of Lords, das ihn freisprach, reproduzieren.
Im folgenden Video können Sie sehen, wie der Prolog-Code schnell aus den Rohdaten des Falls generiert werden kann und wie auf der Grundlage des Prologs juristische Überlegungen angestellt werden können:
Die Konvertierung der Fakten eines Falles und der relevanten Gesetzgebung in Prolog ist ein interessantes Problem, da dabei eine Interpretation realer Ereignisse erforderlich ist, die in Prolog aufgenommen werden müssen. Damit eine KI erkennen kann, dass ein menschlicher Finger keine nachgemachte Feuerwaffe ist, weil er Teil des Körpers ist, muss eine enorme Menge an realem Wissen in diese KI kodiert werden, und ich glaube nicht, dass statistische KI oder maschinelles Lernen zu diesem Verständnisniveau fähig sind.
Für eine KI wäre es ebenfalls äußerst schwierig, Präzedenzfälle anzuwenden. Eine KI bräuchte Wissen aus der realen Welt, um zu entscheiden, ob ein bestimmter Schusswaffenfall einem anderen Fall analog oder ähnlich genug ist.
Im Jahr 2023 präsentierten wir unseren Insolvency Bot auf der JURIX-Konferenz an der Universität Maastricht in den Niederlanden. Der von uns entwickelte Insolvency Bot war ein Proof of Concept dafür, wie LLMs genutzt werden können, um den Zugang zum Recht für Personen zu verbessern, die mit Insolvenzverfahren konfrontiert sind und sich in ihrer Situation wahrscheinlich keine zeitnahe Rechtsberatung leisten können (unseren eingereichten Beitrag können Sie hier im Konferenzbericht lesen: Prompt Engineering and Provision of Context in Domain Specific Use of GPT ).
Wir haben mit Interesse festgestellt, dass es ein großes Interesse an Rechtsbegründungssystemen unter dem Gesichtspunkt der Erweiterung des Zugangs zum Recht gibt. Zu diesem Thema wurden zahlreiche Vorträge gehalten. In vielen Rechtsräumen gibt es ein staatlich finanziertes Rechtshilfesystem, das jedoch häufig sehr restriktiv ist, und Prozessbeteiligte mit geringem Einkommen haben keinen Zugang zu Rechtsberatung.
Meine kurzen Experimente mit Prolog zeigen, dass es möglich ist, mit symbolischer KI im Rechtswesen in einem begrenzten Bereich einige begrenzte Ergebnisse zu erzielen. Die Kombination eines auf Statistiken basierenden Modells wie einem Parser für natürliche Sprache mit einer symbolischen KI in Form eines hybriden KI-Systems ist sehr leistungsfähig, weist jedoch viele Einschränkungen auf und ist weit davon entfernt, die Arbeit eines Anwalts oder Richters ausführen zu können.
Allerdings verändert sich die KI im Rechtswesen rasant und eine vielversprechende Anwendung verbessert den Zugang zum Recht (KI für A2J). Wir haben mit einigen größeren Anwaltskanzleien gesprochen, die an der Möglichkeit interessiert sind, dass KI-Innovationen im Rechtswesen tatsächlich von Bereichen wie Insolvenz und A2J-Initiativen in die besser bezahlten Rechtsbereiche wie Handels- und Vertragsrecht oder Fusionen und Übernahmen vordringen.
Der Grund für die Entscheidung des Oberhauses in R v Bentham lag in der Bedeutung des Wortes „besitzen“ – ein Verweis auf einen Grundsatz des römischen Rechts, wonach eine Person keinen Teil ihres Körpers besitzen darf. Dies lässt sich leider mit KI nur sehr schwer modellieren, da Richter und Anwälte diese allgemeinen Grundsätze kennen, die nicht immer gesetzlich verankert sind.
Möglicherweise erreichen wir das notwendige Verständnis erst, wenn künstliche Intelligenz (AGI) Realität wird. Solange AGI noch Science-Fiction ist, sehe ich keine juristische KI, die wichtige Entscheidungen trifft, obwohl sie derzeit hauptsächlich im Bereich der Informationsbeschaffung eingesetzt wird, um Anwälte zu unterstützen.
Mir hat dieser hervorragende Vortrag von Nils Holzenberger zum Thema NLP und Steuerrecht in den USA gefallen:
Suchen Sie Experten in Natürlicher Sprachverarbeitung? Veröffentlichen Sie Ihre Stellenangebote bei uns und finden Sie heute Ihren idealen Kandidaten!
Veröffentlichen Sie einen Job
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you