
Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdeckenWas ist unüberwachtes Lernen?
Wenn wir darüber nachdenken, eine Fertigkeit zu erwerben oder ein neues Fach zu lernen, sehen die meisten von uns, dass ein Lehrer sein Wissen an uns weitergibt. Wenn Sie einem Kind beispielsweise beibringen, zwischen verschiedenen Früchten zu unterscheiden, können Sie ihm verschiedene Bilder zeigen und eines als Apfel, ein anderes als Birne usw. identifizieren, damit das Kind diese Früchte im wirklichen Leben sieht Welches welche ist, können Sie selbst erkennen, allerdings zunächst über die von Ihnen bereitgestellten Etiketten. Dies wird als überwachtes Lernen bezeichnet und ist eine Möglichkeit, wie künstliche Intelligenz maschinelles Lernen nutzt, um bestimmte Ergebnisse vorherzusagen, indem sie Datenpunkte mit bekannten Ergebnissen verwendet. Dies ist jedoch nicht die einzige Art und Weise, wie wir oder Computer lernen. Wir stellen Ihnen Unsupervised Learning vor.

What we give to a supervised learning algorithm

What we give to an unsupervised learning algorithm.
Mithilfe eines überwachten Lernalgorithmus werden Obstbeispiele gezeigt und erklärt, um welche Früchte es sich handelt. Ein unbeaufsichtigter Lernalgorithmus lernt wie ein Kleinkind: Er lernt, dass es grüne Früchte, orangefarbene Früchte, gelbe Früchte und rote Früchte gibt, und dass sie unterschiedliche Größen und Texturen haben, und schließlich findet er Muster und entwickelt eigene Bezeichnungen für sie.
Nicht alles, was wir wissen, kommt daher, dass es uns beigebracht wurde; Einiges davon haben wir selbst gelernt, indem wir die Dinge durch Beobachtung herausgefunden haben und die Punkte miteinander verknüpft haben, ohne Hilfe und ohne Aufsicht. Auch Maschinen und Programme können auf diese Weise lernen, was als unüberwachtes Lernen bezeichnet wird.
Schauen wir uns an, wie wir unbeaufsichtigt lernen: An einem schönen Sommersamstag ruft Sie ein Freund an und erzählt Ihnen, dass Trevor wieder ein Flocken war (oh Trevor). Aus diesem Grund gibt es eine Ersatzkarte, um das englische Cricket-Team gegen Australien spielen zu sehen. Es ist ein strahlend sonniger Nachmittag, Sie brauchen ein Pint und es hört sich so an, als ob die Sitze ziemlich gut sind. Es gibt nur eine Sache: Sie haben keine Ahnung, wie die Cricket-Regeln lauten. Egal, du gehst trotzdem hin – schließlich ruft das Bier. Sie nehmen Ihren Platz ein und das Spiel beginnt.

Wenn Sie die Cricketregeln nur durch Beobachtung lernen, ist dies eine Analogie zum unbeaufsichtigten Lernen.
Hier lernen Sie das Spiel kennen: Sie analysieren die Bewegungen zwischen den Spielern, die Signale der Schiedsrichter und die Reaktionen Ihrer Freunde. Es gibt zwei Teams, eines in Weiß, das andere in Gelb. Ihre englischen Freunde jubeln immer dann, wenn die weiße Mannschaft glücklich und die gelbe Mannschaft traurig aussieht – daraus schließen Sie, dass England in Weiß und Australien in Gelb sein muss. Auf dem Spielfeld sind 15 Personen: 11 in Weiß, 2 in Gelb und weitere 2 in langen Mänteln und schwarzen Hosen. Diese letztere Gruppe mischt sich nicht in das Spiel ein, sondern leitet das Spiel und setzt die Regeln durch – sie müssen die Schiedsrichter sein. Wenn der Ball von den Feldspielern gefangen wird, verlässt der Schlagmann das Spielfeld. Schlagt man den Ball in die Hände eines gegnerischen Spielers, ist man eindeutig draußen. Alle diese Schlussfolgerungen werden durch Ihre Beobachtung abgeleitet, indem Sie die Regeln selbst aus verschiedenen Trends und Ähnlichkeiten heraussuchen, die zusammengestellt wurden, ohne dass Ihnen jemand anderes etwas davon mitteilt oder sie mit „ Etiketten“ versehen. Das ist unüberwachtes Lernen – aber wie funktioniert es im Kontext von KI und maschinellem Lernen?
Maschinelles Lernen kann grob in drei Kategorien eingeteilt werden: unüberwachtes Lernen , überwachtes Lernen und verstärkendes Lernen .
Wie bereits erwähnt, besteht der größte Unterschied zwischen unbeaufsichtigtem Lernen und überwachtem Lernen darin, dass im Datensatz Labels vorhanden sind (oder nicht). Nehmen wir an, Sie haben eine Reihe von Blumenfotos gespeichert und möchten, dass Ihr Programm oder Algorithmus zwischen Bildern von Tulpen und Gänseblümchen unterscheidet. Ihre erste Möglichkeit besteht darin, selbst Kennungen hinzuzufügen, die angeben, ob es sich bei einer Blume um eine Tulpe oder ein Gänseblümchen handelt (dies wird als Etikettierung bezeichnet) . Anschließend können Sie Ihre beschrifteten Bilder einem KI-Algorithmus übergeben, der versucht, die Schlüsselmerkmale von Tulpen und Gänseblümchen zu lernen.
Fast Data Science - London
Andererseits könnten Sie versuchen, alle diese Bilder einfach in ein Modell einzuspeisen, das versucht, zwei große Arten von Blumen im Datensatz explizit zu identifizieren, ohne sie zu kennzeichnen.
Das erste (beschriftete) Beispiel ist überwachtes Lernen. Das zweite (unbeschriftete) Beispiel ist unüberwachtes Lernen.
Die Verwendung unbeschrifteter gegenüber beschrifteten Daten bietet mehrere Vorteile. Erstens erfordert die Kennzeichnung von Daten viele Ressourcen, und Sie haben möglicherweise nicht die nötige Zeit oder das nötige Team. Zweitens kann der Prozess der Datenkennzeichnung aufgrund der Fehler oder impliziten Vorurteile derjenigen, die die Daten kennzeichnen, fehleranfällig und „verrauscht“ sein (wir sind schließlich nur Menschen). Schließlich sind Beschriftungen dann sinnvoll, wenn Sie genau wissen, was Sie vorhersagen möchten. In vielen Fällen möchten Sie jedoch möglicherweise tatsächlich neue Muster in Ihren Daten entdecken, Schlussfolgerungen, die über die menschliche Fähigkeit hinausgehen, sie herauszufinden (zumindest nicht ohne enormen Zeit- und Ressourcenaufwand). Aufwand), liegen aber durch unüberwachtes Lernen durchaus im Rahmen der Möglichkeiten der KI.
Nehmen wir an, Sie betreiben einen Floristen, in dem Ihre Blumen derzeit nach Farben sortiert sind. Jetzt möchten Sie jedoch Ihre Präsentation ändern und Ihre Blumen anders organisieren. In diesem Fall möchten Sie Gruppen von Blumen entdecken, die sich auf eine Weise ähneln, an die Sie vorher nicht gedacht haben. Unüberwachtes Lernen zur Rettung!
Es gibt verschiedene Möglichkeiten, wie unüberwachte Lernalgorithmen ihre Daten analysieren, die häufigste Art ist jedoch das Clustering . Dabei wird eine Datentrennung basierend auf der zwischen Dateninstanzen gefundenen Ähnlichkeit verwendet. Für unseren Zweck werden zugrunde liegende Merkmale in den Blumen ermittelt, die dann in verschiedene Gruppen eingeteilt werden können, die Sie selbst noch nie zuvor gesehen haben.
Ein weiteres häufiges Beispiel sind werkseitige Fehlerberichte. Stellen Sie sich vor, ein großes Produktionsunternehmen verfügt über ein Fehlerprotokollierungssystem. Jede Art von Unfall oder Zwischenfall wird von den Mitarbeitern im Klartext in einer Datenbank protokolliert. Einige sind einfach, wie zum Beispiel „Förderband blockiert“, andere können komplexer sein, wie zum Beispiel „Die Verpackung war während des Transports aufgrund schlechter Handhabung gerissen“. Wenn Sie als Datenwissenschaftler vor Ort sind und der Fabrikbesitzer Sie bittet, die zehn häufigsten Fehler in der Fabrik zu identifizieren, wie würden Sie vorgehen?
Es besteht die mühsame manuelle Vorgehensweise, alle Berichte durchzulesen und zu versuchen, sie einem willkürlichen Satz von Kategorien zuzuordnen. Alternativ können Sie die Verarbeitung natürlicher Sprache und unbeaufsichtigte Lerntechniken wie Clustering nutzen, um Themen und Cluster zu identifizieren.
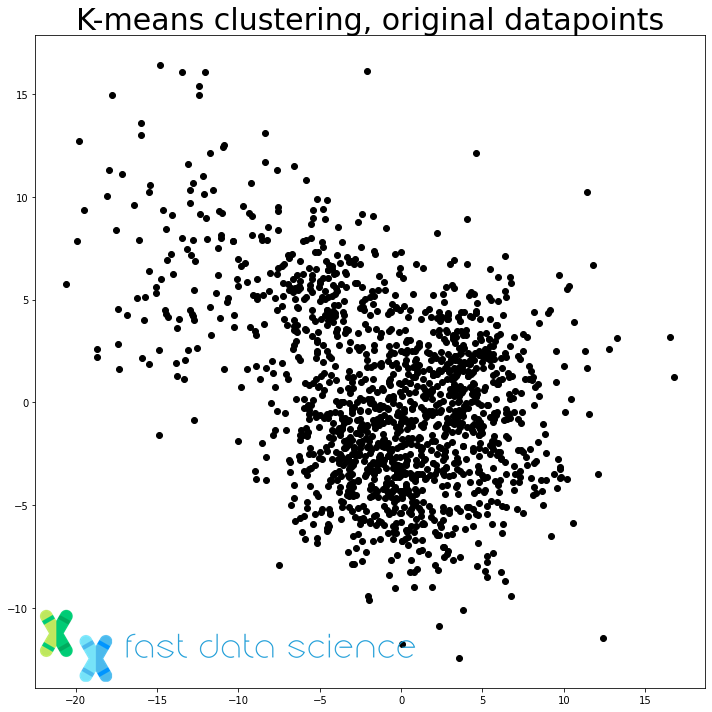
Clustering, eine der gebräuchlichsten unbeaufsichtigten Lerntechniken, beginnt mit einem Satz unbeschrifteter Daten und entdeckt Gruppen und Muster im Rauschen.
Die Clusteranalyse ist ein wichtiger Ansatz im Bereich des unüberwachten Lernens. Da unbeaufsichtigtes Lernen nicht mit Etiketten beginnt, wäre das Ergebnis eines Clustering-Algorithmus die Zuordnung jeder Blume zu einer Gruppe. Es stellt Gemeinsamkeiten und Gemeinsamkeiten in Gruppen dar. Diese Gruppen haben keine vordefinierte Bedeutung, sondern werden durch Clustering entdeckt. An diesem Punkt würden Sie die Elemente in jeder Gruppe durchgehen, um zu sehen, welche Gemeinsamkeiten die KI gefunden hat. Beispielsweise stellen Sie möglicherweise fest, dass die Gruppen Blumen mit unterschiedlicher Textur, Höhe, Blütenblattlänge oder Stielbreite entsprechen. Das Ergebnis ist eine Reihe von Mustern in Ihren Blumen, an die Sie vorher vielleicht nicht gedacht haben. Oder Sie können einfach nicht herausfinden, was in den Gruppen vor sich geht, die Ihr Algorithmus entdeckt hat.

Diagramm der Kelchblattlänge vs. Kelchblattbreite für drei Arten von Irisblüten (unter Verwendung des bekannten Iris-Datensatzes ). Diese Daten sind gekennzeichnet, aber wenn die Markierungen entfernt würden, wäre ein Clustering-Algorithmus wahrscheinlich in der Lage, Setosa von den beiden anderen Arten zu unterscheiden.
Die DVLA ist die Organisation im Vereinigten Königreich, die Fahrzeuge auf Verkehrssicherheit prüft, das Äquivalent der DMV in den Vereinigten Staaten. Es ist möglich, alle Fahrzeuginspektionsberichte im Land von der Website der DVLA herunterzuladen. Ein Inspektionsbericht enthält oft eine Beschreibung des Fehlers im Klartext.

Ein Beispiel für Fahrzeuginspektionsberichte, die von der DVLA-Website heruntergeladen wurden
Wenn wir jedoch nur diese Texte und keine anderen strukturierten Daten hätten, wäre es ziemlich schwierig, häufige Arten von Fahrzeugfehlern zu identifizieren.
Wenn wir in den Berichten schnell gemeinsame Themen entdecken wollen, können wir eine Wortwolke der Texte erstellen, in der häufig vorkommende Wörter in großer Schrift erscheinen. Dadurch können wir auf einen Blick die gebräuchlichsten Ausdrücke sehen, erhalten aber keine Themenliste .
Eine Wortwolke für die Kfz-Prüfberichte. Den Berichten sind keine Etiketten zugeordnet, daher können wir sie nur durch unbeaufsichtigtes Lernen verarbeiten.
Wir können einen unbeaufsichtigten Lernalgorithmus namens LDA oder Latent Dirichlet Allocation verwenden, um die Berichte in fünf Themen aufzuteilen:
Ausgabe des LDA-Algorithmus auf Fahrzeuginspektionsberichte. Sie sehen, dass die entdeckten Themen offenbar mit Bremsen, Licht, Fahrzeugheck, Achsen und Federung zu tun haben. LDA (Latent Dirichlet Allocation) ist eine gängige unbeaufsichtigte Lerntechnik, die für Textdaten verwendet wird.
Und schließlich ist es möglich, die Themen in einem Diagrammbereich darzustellen. Anhand dieser Visualisierung können wir beispielsweise erkennen, dass die Themen 1 und 4 recht nahe beieinander liegen.
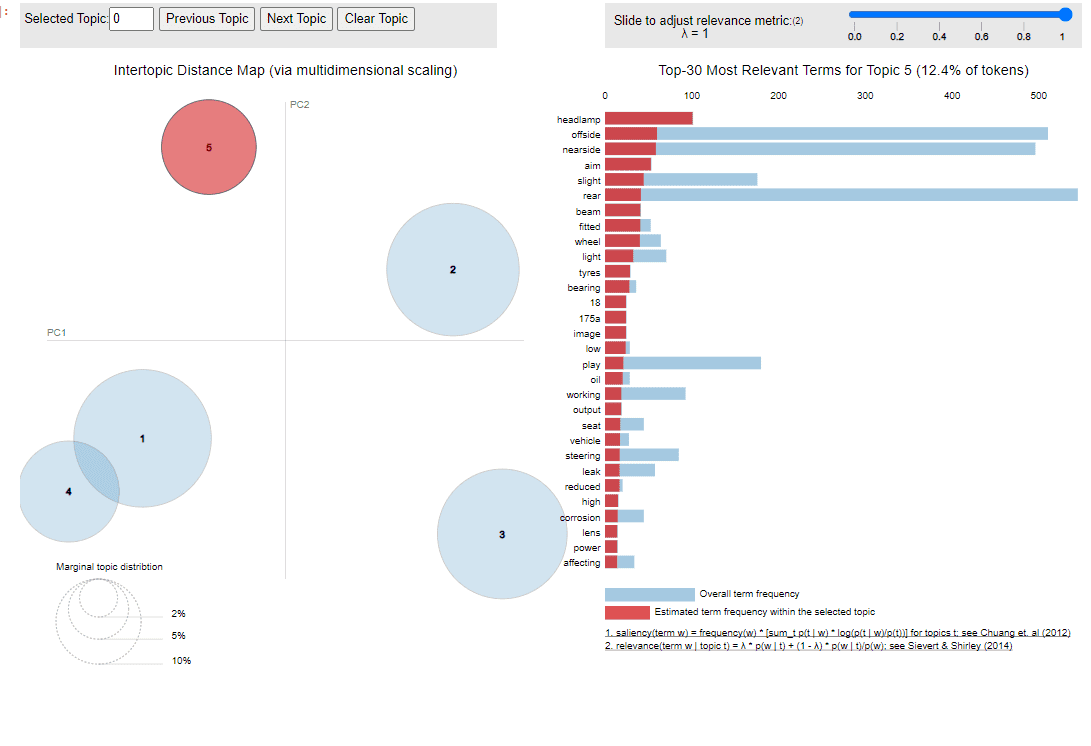
Visualisierung der LDA-Ausgabe auf Fahrzeuginspektionsberichten.
Die obige LDA-Analyse ist ein einfaches Beispiel, für das ich weniger als eine halbe Stunde gebraucht habe. Wir können uns nur vorstellen, wie leistungsstark es wäre, Themen in Fabrikfehlerberichten, Umfragedaten und anderen Arten unstrukturierter Textdaten zu entdecken.
Dies ist das zweischneidige Schwert des unbeaufsichtigten Lernens: Da Sie keine vordefinierten Etiketten haben, ist Ihr KI-Programm in der Lage, neuartige, innovative Entdeckungen und Muster in Ihren Daten zu finden. Da Ihre KI nicht aus Etiketten lernt, ist es gleichzeitig schwieriger vorherzusagen, was der Algorithmus lernen wird – Sie haben also keine Garantie dafür, dass die Ausgabe nützlich oder aussagekräftig ist. Yan LeCun, der Direktor von Facebook AI Research, sagte:
„Wenn Intelligenz ein Kinderspiel ist, besteht der Großteil des Kuchens aus unbeaufsichtigtem Lernen, das Tüpfelchen auf dem Kuchen ist überwachtes Lernen und das Sahnehäubchen auf dem Kuchen ist Reinforcement Learning (RL).“
Yann LeCun
Unüberwachtes Lernen ist nur ein, aber immer noch wichtiges Element des maschinellen Lernens, das dazu beitragen wird, die KI in eine zuverlässige und dynamische Zukunft zu führen.
Bereit für den nächsten Schritt in Ihrer NLP-Reise? Vernetzen Sie sich mit Top-Arbeitgebern, die Talente in der natürlichen Sprachverarbeitung suchen. Entdecken Sie Ihren Traumjob!
Finden Sie Ihren Traumjob
Mittlerweile sind es Organisationen aller Größenordnungen und fast aller Sektoren werden zunehmend datengesteuert, insbesondere als größere Datenspeicher Systeme und schnellere Computer treiben die Leistungsgrenzen immer weiter voran.

Aufgrund des umfangreichen Einsatzes von Technologie und der Arbeitsteilung hat die Arbeit des durchschnittlichen Gig-Economy-Arbeiters jeden individuellen Charakter und damit auch jeden Charme für den Arbeitnehmer verloren.
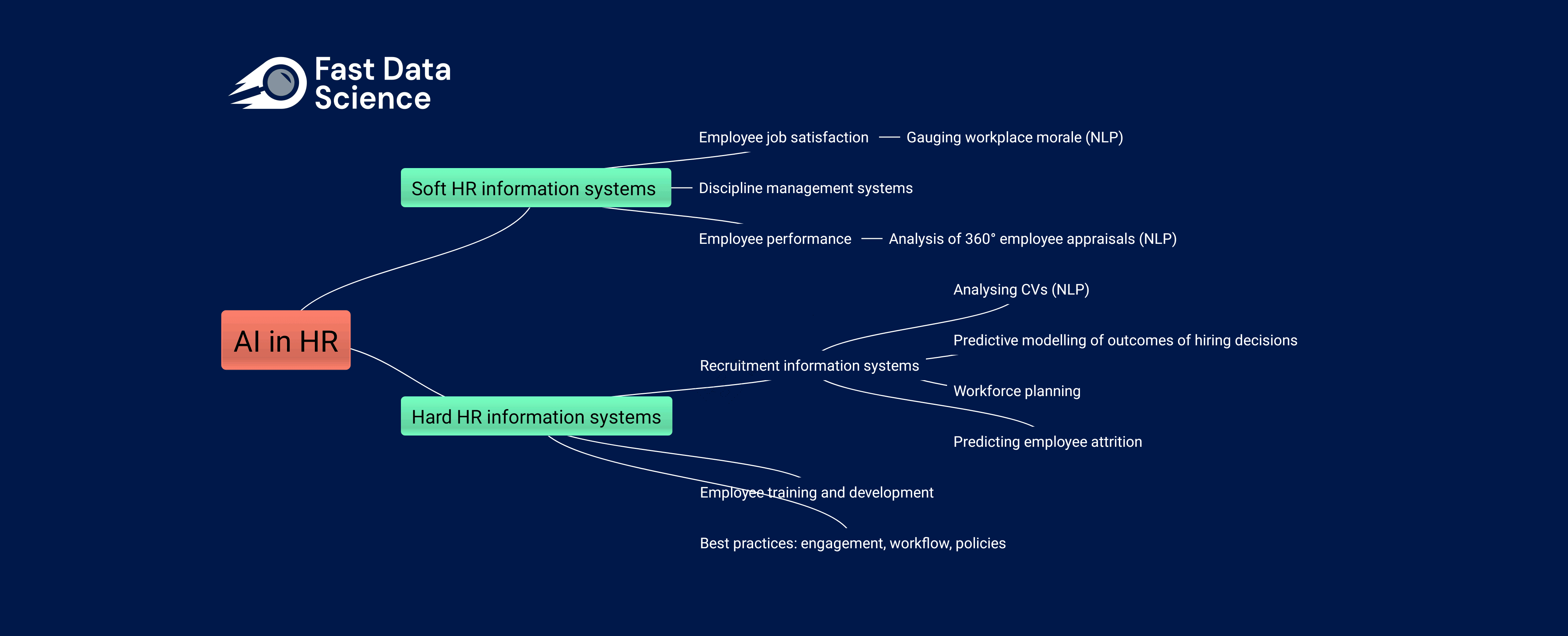
Die Auswirkungen von KI auf die Humanressourcen Die Arbeitswelt verändert sich rasant, sowohl aufgrund der Einführung traditioneller Data-Science-Praktiken in immer mehr Unternehmen als auch aufgrund der zunehmenden Beliebtheit generativer KI-Tools wie ChatGPT und Googles BARD bei nicht-technischen Arbeitnehmern.
What we can do for you