Ich stelle eine von mir geschriebene Python -Bibliothek namens faststylometrie vor, mit der Sie Autoren von Texten anhand ihres Schreibstils vergleichen können. Die Wissenschaft, die Fingerabdrücke von Autoren auf diese Weise zu vergleichen, wird forensische Stilometrie genannt.
Um dieses Tutorial ausführen zu können, benötigen Sie Grundkenntnisse in Python.
Die Faststylometrie -Bibliothek verwendet den Burrows-Delta-Algorithmus, eine bekannte stilometrische Technik. Die Bibliothek kann auch die Wahrscheinlichkeit berechnen, dass zwei Bücher vom selben Autor stammen.
Ich habe diese Bibliothek geschrieben, um mein Verständnis zu verbessern, und auch, weil die vorhandenen Bibliotheken, die ich finden konnte, sich auf das Erstellen von Diagrammen konzentrierten, aber nicht so weit gingen, Wahrscheinlichkeiten zu berechnen.
Hier gebe ich eine Schritt-für-Schritt-Anleitung, wie man mit der Faststylometrie- Bibliothek eine grundlegende Stilometrieanalyse durchführt. Wir werden den Burrows-Delta-Code an zwei „unbekannten“ Texten testen: „Sinn und Sinnlichkeit “ von Jane Austen und „Villette“ von Charlotte Brontë. Beide Autoren sind in unserem Trainingskorpus enthalten.
Das Burrows-Delta ist eine Statistik, die den Unterschied zwischen den Schreibstilen zweier Autoren ausdrückt. Eine hohe Zahl wie 3 bedeutet, dass die beiden Autoren sehr unterschiedlich sind, während eine niedrige Zahl wie 0,2 bedeutet, dass zwei Bücher sehr wahrscheinlich vom selben Autor stammen. Hier ist ein Link zu einer nützlichen Erklärung der Mathematik und des Denkens hinter Burrows-Delta und wie es funktioniert .
Das Burrows-Delta wird berechnet, indem die relativen Häufigkeiten von Funktionswörtern wie „innen“, „und“ usw. in den beiden Texten verglichen werden, wobei ihre natürliche Variation zwischen den Autoren berücksichtigt wird.
Wenn Sie Python verwenden, können Sie die Bibliothek mit dem folgenden Befehl installieren:
pip installiere Faststylometrie
Das Jupyter-Notebook für diese exemplarische Vorgehensweise finden Sie hier .
Burrows Delta-Komplettlösung im Jupyter Notebook
Zuerst starten wir Python. Zuerst müssen wir die Stilometrie-Bibliothek importieren:
aus Faststylometrie importieren Corpus
von Faststylometrie importiere load\_corpus\_from\_folder
von Faststylometrie importiere tokenise\_remove\_pronouns\_en
von Faststylometrie importiere berechne\_burrows\_delta
von Faststylometrie importiere Predict\_proba, kalibriere
Die Bibliothek ist von NLTK (Natural Language Toolkit) abhängig. Wenn Sie sie also zum ersten Mal verwenden, müssen Sie möglicherweise die folgenden Befehle in Ihrer Python- Umgebung ausführen, wenn Sie den integrierten Tokeniser verwenden möchten:
NLTK importieren
nltk.download("punkt")
Ich habe einige Testdaten bereitgestellt, damit Sie mit der Bibliothek spielen können. Sie können diese hier vom Projekt Github herunterladen. Es handelt sich um eine Auswahl klassischer Literatur aus dem Projekt Gutenberg , beispielsweise von Jane Austen und Charles Dickens. Aus urheberrechtlichen Gründen kann ich keine moderneren Bücher bereitstellen, aber Sie können diese jederzeit woanders erhalten.
Wenn Sie Git verwenden, können Sie die Beispieltexte mit diesem Befehl herunterladen:
Git-Klon https://github.com/fastdatascience/faststylometrie
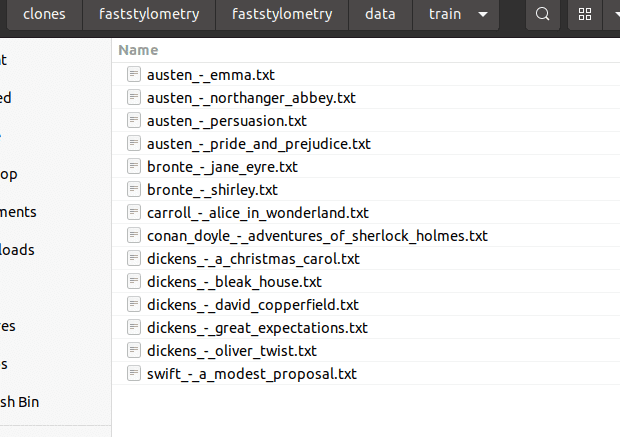
Stellen Sie sicher, dass sich die Buchtexte im Ordner faststylometrie/data/train auf Ihrem Computer befinden und jede Datei den Namen „Autorenname“_-_„Buchtitel“.txt trägt, zum Beispiel:
Sie können die Bücher jetzt in die Bibliothek laden und sie nach englischen Regeln tokenisieren:
train\_corpus = lade\_corpus\_aus\_Ordner("faststylometrie/daten/train")
train\_corpus.tokenise(tokenise\_remove\_pronouns\_en)
Alternativ können Sie Ihrem Korpus Bücher mit dem folgenden Verfahren hinzufügen:
Korpus = Korpus()
corpus.add\_book("Jane Austen", "Stolz und Vorurteil", [gesamter Buchtext])
Ich habe uns auch einige „unbekannte“ Bücher zur Verfügung gestellt, damit wir die Leistung des Algorithmus testen können. Stellen Sie sich vor, wir sind auf ein Werk gestoßen, dessen Autor unbekannt ist. Die Bücher, die ich aufgenommen habe, sind „Sinn und Sinnlichkeit“ von Jane Austen (aber als „janedoe“ gekennzeichnet) und „Villette “ von Charlotte Brontë, das ich als „currerbell“ gekennzeichnet habe, Brontës echtes Pseudonym. Sie befinden sich im Ordner faststylometrie/data/test .
 test texts](https://fastdatascience.com/images/forensic_stylometry_test_texts-min.png)
Hier ist der Code zum Laden der unbekannten Dokumente in ein neues Korpus und zum Tokenisieren, sodass es für die Analyse bereit ist:
Load Sense and Sensibility, geschrieben von Jane Austen (gekennzeichnet als „janedoe“)
======================================================================================
und Villette, geschrieben von Charlotte Brontë (gekennzeichnet als „currerbell“, Brontës wirkliches Pseudonym)
==============================================================================================================
test\_corpus = lade\_corpus\_aus\_Ordner("faststylometrie/daten/test", Muster=Keine)
Sie können das Muster auf einen Zeichenfolgenwert setzen, um nur eine Teilmenge des Korpus zu laden.
====================================================================================================
test\_corpus.tokenise(tokenise\_remove\_pronouns\_en)
Fast Data Science - London
Jetzt haben wir ein Trainingskorpus, das aus bekannten Autoren besteht, und ein Testkorpus, das zwei „unbekannte“ Autoren enthält. Die Bibliothek liefert uns die Burrows-Delta-Statistik als Matrix (Pandas-Datenrahmen) für beide unbekannten Texte (x-Achse) und alle bekannten Autoren (y-Achse):
berechne Burrows-Delta (Trainingskorpus, Testkorpus, Vokabelgröße = 50)
Wir können sehen, dass die niedrigsten Werte in jeder Spalte und damit die wahrscheinlichsten Kandidaten Brontë und Austen sind – die tatsächlich die wahren Autorinnen von Villette und Sinn und Sinnlichkeit sind.
| Autor | Currerbell – Villette | Janedoe – Sinn und Sinnlichkeit |
|---|---|---|
| austen | 0,997936 | 0,444582 |
| bronte | 0,521358 | 0,93316 |
| Carroll | 1,116466 | 1,433247 |
| conan_doyle | 0,867025 | 1,094766 |
| Dickens | 0,800223 | 1,050542 |
| schnell | 1,480868 | 1,565499 |
Es ist möglich, einen Blick darauf zu werfen und zu sehen, welche Token für die stilometrische Analyse verwendet werden:
Die obige Burrows-Delta-Statistik kann etwas schwierig zu interpretieren sein, und manchmal hätten wir gern einen Wahrscheinlichkeitswert. Wie wahrscheinlich ist es, dass Jane Austen die Autorin von „Verstand und Gefühl“ ist?
Dies können wir erreichen, indem wir das Modell kalibrieren. Das Modell betrachtet die Burrows-Deltawerte zwischen bekannten Autoren und ermittelt, welche Werte am häufigsten auf dieselbe Urheberschaft hinweisen:
kalibrieren(train\_corpus)
Nachdem wir die Kalibrierungsmethode aufgerufen haben, können wir das Modell nun auffordern, uns die Wahrscheinlichkeiten zu liefern, die den Deltawerten in der obigen Tabelle entsprechen:
vorhersagen\_proba(Trainingskorpus, Testkorpus)
Sie sehen, dass wir nun eine 76-prozentige Wahrscheinlichkeit haben, dass Villette von Charlotte Brontë geschrieben wurde.
| Autor | Currerbell – Villette | Janedoe – Sinn und Sinnlichkeit |
|---|---|---|
| austen | 0,324233 | 0,808401 |
| bronte | 0,757315 | 0,382278 |
| 0,231463 | 0,079831 | |
| conan_doyle | 0,445207 | 0,246974 |
| Dickens | 0,510598 | 0,280685 |
| schnell | 0,067123 | 0,049068 |
Nebenbei bemerkt: Standardmäßig verwendet die Bibliothek die logistische Regression von Scikit Learn, um die Kalibrierungskurve des Modells zu berechnen. Alternativ können wir ihr mitteilen, welches Modell verwendet werden soll, indem wir der Kalibrierungsmethode ein Argument übergeben:

Wir können die Kalibrierungskurve für einen Bereich von Deltawerten darstellen:
importiere Numpy als np
importiere matplotlib.pyplot als plt
x\_Werte = np.arange(0, 3, 0,1)
plt.plot(x\_Werte, trainiere\_corpus.Wahrscheinlichkeitsmodell.predict\_proba(np.reshape(x\_Werte, (-1, 1)))[:,1])
plt.xlabel("Burrows-Delta")
plt.ylabel("Wahrscheinlichkeit des gleichen Autors")
plt.title("Kalibrierungskurve des Burrows Delta-Wahrscheinlichkeitsmodells\nUnter Verwendung einer logistischen Regression mit Korrektur für Klassenungleichgewicht")
Wir können sehen, dass ein Delta-Wert von 0 nahezu sicher ist, dass die beiden Bücher vom selben Autor stammen, während ein Wert von 2 nahezu sicher ist, dass sie von unterschiedlichen Autoren stammen.
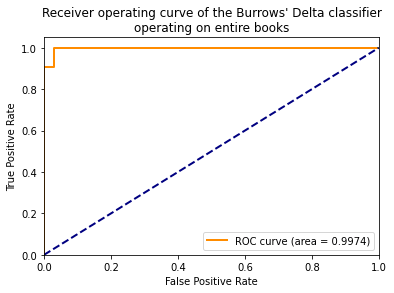
Die ROC- Kurve und die AUC-Metrik sind nützliche Methoden zum Messen der Leistung eines Klassifikators.
Die Burrows-Delta-Methode ist bei der Verwendung als Textklassifizierer mit zwei Klassen (verschiedener Autor vs. gleicher Autor) unglaublich einfach zu handhaben, da sie aus ganzen Büchern gelernt hat. Daher würden wir erwarten, dass der Klassifizierer sehr gut funktioniert.
Wir können die ROC- Auswertung mithilfe einer Kreuzvalidierung durchführen. Der obige Kalibrierungscode hat nacheinander jedes Buch aus dem Trainingskorpus herausgenommen, ein Burrows-Modell mit dem Rest trainiert und es gegen das zurückgehaltene Buch getestet. Wir nehmen die daraus resultierenden Wahrscheinlichkeitswerte und berechnen die ROC-Kurve.
Ein AUC-Wert von 0,5 bedeutet, dass ein Klassifikator schlecht funktioniert, und 1,0 ist ein perfekter Wert. Sehen wir uns an, wie gut unser Modell funktioniert.
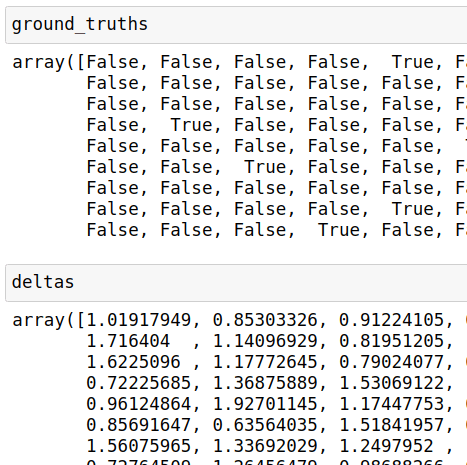
Lassen Sie uns zunächst die Grundwahrheiten ( Falsch = anderer Autor, Wahr = gleicher Autor) und Burrows-Deltawerte für alle Vergleiche ermitteln, die innerhalb des Trainingskorpus durchgeführt werden können:
Grundwahrheiten, Deltas = Kalibrierungskurve abrufen (Trainkorpus)
Wir erhalten die Wahrscheinlichkeiten für jeden Vergleich, den das Modell durchgeführt hat, indem wir die Burrows-Deltawerte wieder durch das trainierte Scikit-Learn- Modell laufen lassen:
Wahrscheinlichkeiten = Korpus trainieren.Wahrscheinlichkeitsmodell.Proba\_vorhersagen(np.reshape(deltas, (-1, 1)))[:,1]
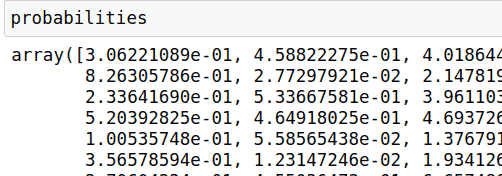
Wir können die Wahrscheinlichkeiten und Grundwahrheiten in Scikit-Learn eingeben, um die ROC-Kurve zu berechnen:
von sklearn.metrics importiere roc\_curve, auc
fpr, tpr, Schwellenwerte = roc\_curve(Grundwahrheiten, Wahrscheinlichkeiten)
Wir können nun den AUC-Score berechnen. Wenn unser Modell die Urheberschaft gut erkennt, sollte eine Zahl nahe 1,0 angezeigt werden.
roc\_auc = auc(fpr, tpr)
Schließlich können wir die ROC-Kurve zeichnen:
plt.figure()
plt.plot(fpr, tpr, Farbe='dunkelorange',
lw=lw, label='ROC curve (area = %0.4f)' % roc_auc)
plt.plot([0, 1], [0, 1], Farbe='marineblau', lw=2, Linienstil='--')
plt.xlim([0.0, 1.0])
plt.ylim([0,0, 1,05])
plt.xlabel('Falsch-Positiv-Rate')
plt.ylabel('Wahre Positive-Rate')
plt.title('Receiver-Operating-Kurve des Burrows-Delta-Klassifikators, der auf ganzen Büchern operiert')
plt.legend(loc="unten rechts")
plt.anzeigen()
Wir können auch die stilistischen Ähnlichkeiten zwischen den Büchern im Trainingskorpus visualisieren, indem wir ihre Unterschiede berechnen und sie mithilfe der Hauptkomponentenanalyse (PCA) im 2D-Raum anzeigen.
Dazu müssen wir die Python-Bibliothek für maschinelles Lernen Scikit-Learn verwenden.
von sklearn.decomposition importiere PCA
erneut importieren
Pandas als pd importieren
Wir können das Trainingskorpus erneut laden und Segmente mit 80.000 Wörtern entnehmen, sodass wir unterschiedliche Abschnitte jedes Buches in unsere Analyse einbeziehen können.
Laden Sie das Trainingskorpus als „Testkorpus“ neu, tokenisieren Sie es erneut und segmentieren Sie es dieses Mal
=================================================================================================================
test\_corpus = lade\_corpus\_aus\_Ordner("faststylometrie/daten/train")
test\_corpus.tokenise(tokenise\_remove\_pronouns\_en)
split\_test\_corpus = test\_corpus.split(80000)
Nun berechnen wir die Burrows-Delta-Statistik für die Buchsegmente:
df\_delta = berechne Burrows\_Delta (Trainingskorpus, Testkorpus aufteilen)
Wir sind an der Reihe der Z-Scores interessiert
df\_z\_scores = split\_test\_corpus.df\_author\_z\_scores

Das obige Array ist zu groß, um es direkt anzuzeigen. Daher müssen wir es auf den zweidimensionalen Raum reduzieren, um es in einem Diagramm anzeigen zu können. Dies können wir mithilfe des Hauptkomponentenanalysemodells von Scikit-Learn tun, indem wir es auf zwei Dimensionen einstellen:
pca\_modell = PCA(n\_Komponenten=2)
pca\_matrix = pca\_model.fit\_transform(df\_z\_scores)
Es wäre schön, die Buchabschnitte in einem Diagramm darzustellen und dabei für jedes Buch desselben Autors dieselbe Farbe zu verwenden. Da die Z-Score-Matrix nach Autor und Buchname indiziert ist, können wir einen regulären Ausdruck verwenden, um alles vor dem ersten Bindestrich zu übernehmen. Dadurch erhalten wir den einfachen Autorennamen ohne den Buchtitel:
Autoren = df\_z\_scores.index.map( [lambda](https://aws.amazon.com/lambda) x: re.sub(" - .+", "", x))
Wir können die von der PCA abgeleiteten Koordinaten und die Autorennamen in einem Datenrahmen zusammenführen:
df\_pca\_by\_author = pd.DataFrame(pca\_matrix)
df\_pca\_by\_author["author"] = Autoren
Jetzt können wir die einzelnen Bücher in einem einzigen Diagramm darstellen:
plt.figure(Figurgröße=(15,15))
für Autor, pca\_coordinates in df\_pca\_by\_author.groupby("Autor"):
plt.scatter(*zip(*pca_coordinates.drop(“author”, axis=1).to_numpy()), label=author)
für i im Bereich (Länge (pca\_matrix)):
plt.text(pca_matrix[i][0], pca_matrix[i][1]," " + df_z_scores.index[i], alpha=0.5)
plt.legend()
plt.title("Darstellung mittels PCA von Werken im Trainingskorpus")

Der Code für ROC/AUC bedeutet, dass wir verschiedene Parameter ausprobieren können, indem wir die Vokabulargröße, die Dokumentlänge oder die Vorverarbeitungsschritte ändern, um zu sehen, wie sich dies auf die Leistung der Burrows-Delta-Methode auswirkt.
Mich würde interessieren, wie das Delta bei anderen Sprachen funktioniert und ob es bei flektierenden Sprachen von Vorteil wäre, eine morphologische Analyse als Vorverarbeitungsschritt durchzuführen. Sollte beispielsweise das türkische Wort „teyzemle“ (mit meiner Tante) als teyze+m+le behandelt werden, wobei die beiden Suffixe separat eingegeben werden?
Sie können diese Art von Experiment ausprobieren, indem Sie die Funktion tokenise_remove_pronouns_en durch eine Tokenisierungsfunktion Ihrer Wahl ersetzen. Die einzige Einschränkung besteht darin, dass eine Zeichenfolge in eine Liste von Zeichenfolgen konvertiert werden muss.
Wenn Sie in den Bereichen KI, NLP oder anderen Bereichen forschen und Ihre Ergebnisse veröffentlichen, wäre ich Ihnen dankbar, wenn Sie das Projekt zitieren könnten.
Wood, TA, Fast Stylometrie [Computersoftware] (1.0.4). Data Science Ltd. DOI: 10.5281/zenodo.11096941, abgerufen unter https://fastdatascience.com/natural-language-processing/fast-stylometry-python-library/ , Fast Data Science (2024)
![]()
Ein BibTeX-Eintrag für LaTeX-Benutzer lautet:
@software{faststylometrie,
author = {Wood, T.A.},
title = {Fast Stylometry (Computer software), Version 1.0.4},
year = {2024},
url = {https://fastdatascience.com/natural-language-processing/fast-stylometry-python-library/},
doi = {10.5281/zenodo.11096941},
}
Glücklicherweise nutzen zahlreiche Personen und Organisationen auf der ganzen Welt die Fast Stylometry-Bibliothek und haben uns zitiert.
Yong-Bin Kang vom Exzellenzzentrum für automatisierte Entscheidungsfindung und Gesellschaft des Australian Research Council (ARC) verwendete das Tool zur Analyse von Inhalten in Foren zur psychischen Gesundheit:
Rebecca Hicke und David Mimno von der Cornell University verwendeten die Fast Stylometrie zur Autorenzuordnung im frühneuzeitlichen englischen Drama:
Entfesseln Sie das Potenzial Ihrer NLP-Projekte mit dem richtigen Talent. Veröffentlichen Sie Ihre Stelle bei uns und ziehen Sie Kandidaten an, die genauso leidenschaftlich über natürliche Sprachverarbeitung sind.
NLP-Experten einstellen
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you