Mit dem Aufkommen künstlicher Intelligenz wird Automatisierung zu einem Teil des Alltags. Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) hat sich als Schlüssel zu diesem Durchbruch erwiesen. Die Verarbeitung natürlicher Sprache schließt die Lücke zwischen Computern, KI und Computerlinguistik. Erfahren Sie mehr über NLP-Ansätze in diesem Leitfaden zur statistischen und symbolischen NLP.
Ein einfacher Satz, den Menschen sprechen, besteht aus verschiedenen Tönen, Wörtern, Bedeutungen und Werten. Experten-KI-Systeme können diese verborgenen Strukturen und Bedeutungen nutzen, um menschliches Verhalten zu verstehen. Allerdings benötigen wir oft eine sehr genaue und detaillierte Bewertung, um zu entscheiden, welche Bedeutung richtig sein könnte und welche nicht. Wenn wir über eine große Menge an Textdaten verfügen, kann es unmöglich werden, diese schnell zu lesen.
Rohtextdaten in Englisch oder anderen Sprachen sind ein Beispiel für unstrukturierte Daten . Diese Art von Daten passt nicht in eine relationale Datenbank und ist mit Computerprogrammen schwer zu interpretieren. Die Verarbeitung natürlicher Sprache ist ein Teilgebiet der KI, das sich damit beschäftigt, wie Computer menschliche Sprache interpretieren, verstehen und manipulieren.

Wie würden Sie einen NLP-Algorithmus trainieren, um mit langen dänischen zusammengesetzten Wörtern wie „Håndværkergården“ („der Handwerkerhof“) umzugehen? Würden Sie ein Wörterbuch aller möglichen zusammengesetzten Wörter erstellen oder versuchen, Wörter in ihre Bestandteile zu zerlegen?
NLP ist viel mehr als Sprach- und Textanalyse. Je nachdem, was getan werden muss, kann es unterschiedliche Ansätze geben. Es gibt drei Hauptansätze:
Statistischer Ansatz: Der statistische Ansatz zur Verarbeitung natürlicher Sprache beruht auf der Erkennung von Mustern in großen Textmengen. Durch das Erkennen dieser Trends kann das System sein eigenes Verständnis der menschlichen Sprache entwickeln. Zu den modernsten Beispielen für statistische NLP zählen Deep Learning und neuronale Netzwerke.
Symbolischer Ansatz: Beim symbolischen Ansatz der NLP geht es mehr um vom Menschen entwickelte Regeln. Ein Programmierer schreibt eine Reihe von Grammatikregeln, um zu definieren, wie sich das System verhalten soll.
Konnektionistischer Ansatz oder „ Hybrider “ Ansatz: Der dritte Ansatz ist eine Kombination aus statistischen und symbolischen Ansätzen. Wir beginnen mit einem symbolischen Ansatz und verstärken ihn mit statistischen Regeln.
Sehen wir uns nun an, wie diese NLP-Ansätze von Maschinen zur Interpretation von Sprache verwendet werden.
Die Sprachinterpretation kann in mehrere Ebenen unterteilt werden. Jede Ebene ermöglicht es der Maschine, Informationen auf einem höheren Komplexitätsniveau zu extrahieren.
Morphologische Ebene : Innerhalb eines Wortes ist eine Struktur namens Morphem die kleinste Bedeutungseinheit. Das Wort „unlockable“ besteht aus drei Morphemen: un+lock+able. Ähnlich besteht „happily“ aus zwei: happy+ly. Bei der morphologischen Analyse geht es darum, die Morpheme innerhalb eines Wortes zu identifizieren, um die Bedeutung herauszufinden.
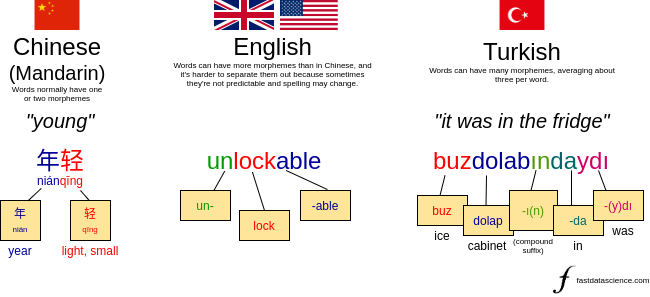
Ein chinesisches Wort, ein englisches Wort und ein türkisches Wort. Einige Sprachen, wie Mandarin, haben ein oder zwei Morpheme pro Wort, und andere, wie Türkisch, können viele Morpheme pro Wort haben. Englisch liegt irgendwo dazwischen. Das gezeigte Beispiel von „unlockable“ kann entweder als „un+lockable“ oder als „unlock+able“ analysiert werden, was die inhärente Mehrdeutigkeit vieler Analysen veranschaulicht, die wir in NLP durchführen.
In der Praxis müssen wir beim englischen NLP, abgesehen vom Entfernen von Suffixen wie „ing“ aus Wörtern, normalerweise nicht auf die morphologische Ebene vordringen. Bei stark flektierenden Sprachen wie Shona kann die Behandlung von Unterwortmorphemen unvermeidlich sein. In meinem Beitrag zum mehrsprachigen NLP bin ich näher darauf eingegangen.
Lexikalische Ebene: Die nächste Analyseebene beinhaltet die Betrachtung von Wörtern als Ganzes.
Ein Beispiel für einen rein lexikalischen NLP-Ansatz ist ein Naive-Bayes-Klassifikator , der Texte anhand der Worthäufigkeit und unter Berücksichtigung der Satzstruktur als Sport oder Politik, Spam oder Ham kategorisieren kann.
Syntaktische Ebene : Die syntaktische Analyse geht einen Schritt weiter und konzentriert sich auf die Struktur eines Satzes: wie Wörter miteinander interagieren.
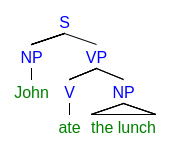
Ein Analysebaum ist eine Möglichkeit, die Syntax eines Satzes darzustellen.
Ein NLP-System, das auf syntaktischer Ebene arbeitet, könnte den Unterschied zwischen „Dieser Film war sehenswert“ und „Der Film ist definitiv nicht sehenswert“ erkennen. Diese Nuancen sind mit einer Bag-of-Word-Technik wie dem Naive Bayes Classifier schwer zu erkennen.
Semantische Ebene: Die semantische Analyse beschäftigt sich damit, wie wir die Satzstruktur in eine Bedeutungsinterpretation umwandeln können.
Ein semantischer NLP-Ansatz könnte möglicherweise Erkenntnisse wie „40 % der Ärzte dachten, es gäbe eine Wechselwirkung zwischen Medikament A und Medikament B“ hervorbringen.
Diskursebene: Hier geht es um die Verbindung zweier Sätze. Das ist unglaublich knifflig: Wenn jemand „er“ sagt, woher wissen wir dann aus einem früheren Satz, auf wen er sich bezieht, wenn mehrere Personen erwähnt wurden?
(2008 schrieb ich meine Masterarbeit über das Wort „it“ und beschäftigte mich dabei mit der Frage, wie wir das pleonastische „it“ wie in „it’s raining“ von dem „it“ unterscheiden können, das sich auf etwas in einem vorhergehenden Satz bezieht. Im Zeitalter der GPT ist das Problem immer noch ungelöst!)
Nachdem wir nun ein klares Verständnis der Verarbeitung natürlicher Sprache haben, sind hier einige gängige Beispiele für NLP:

Außer Kontrolle geratene soziale Medien können einer Marke schaden.
Eines der besten Beispiele für die Verarbeitung natürlicher Sprache ist die Überwachung sozialer Medien. Negative Publicity ist nicht gut für eine Marke und eine gute Möglichkeit, die Meinung Ihrer Kunden zu erfahren, besteht darin, die sozialen Medien im Auge zu behalten.
Plattformen wie Buffer und Hootsuite nutzen NLP-Technologie, um Kommentare und Posts zu einer Marke zu verfolgen. NLP hilft Unternehmen, benachrichtigt zu werden, wenn ein negativer Tweet oder eine negative Erwähnung online geht, damit sie ein Kundendienstproblem beheben können, bevor es zu einer Katastrophe wird.

Während sich das herkömmliche Social-Media-Monitoring mit geschriebenen Texten befasst, können wir mithilfe von Sentimentanalyse-Techniken einen tieferen Einblick in die Emotionen der Benutzer gewinnen.
Die Wortwahl des Benutzers gibt einen Hinweis darauf, wie sich der Benutzer gefühlt hat, als er den Beitrag geschrieben hat. Wenn er beispielsweise Wörter wie glücklich , gut und Lob verwendet, deutet dies auf ein positives Gefühl hin. Die Stimmungsanalyse ist jedoch alles andere als einfach: Sie kann durch Sarkasmus, Zweideutigkeiten und komplexe Satzstrukturen durcheinandergebracht werden, daher sollte ein guter Algorithmus zur Stimmungsanalyse die Satzstruktur berücksichtigen.
Unternehmen nutzen häufig Stimmungsanalysen, um die Reaktionen der Kunden auf ihre Marken zu beobachten, wenn etwas Neues eingeführt wird.
Einfache Texte können eine tiefere Bedeutung haben und auf mehrere Unterkategorien verweisen. Erwähnungen von Orten, Daten, Orten, Personen und Unternehmen können wertvolle Daten liefern. Die leistungsfähigsten Modelle sind oft sehr branchenspezifisch und werden von Unternehmen entwickelt, die in ihrem Bereich über große Datenmengen verfügen. Ein maschinelles Lernmodell kann trainiert werden, um das Gehalt eines Jobs anhand seiner Beschreibung oder das Risikoniveau eines Hauses oder eines Schiffes anhand eines Sicherheitsinspektionsberichts vorherzusagen.
Eine coole Anwendung ist die forensische Stilometrie , also die Wissenschaft, den Autor eines Dokuments anhand des Schreibstils zu bestimmen. Ich habe mit einer Online-Demo ein einfaches forensisches Stilometriemodell trainiert, um herauszufinden, welcher von drei berühmten Autoren einen Text wahrscheinlich geschrieben hat.

Forensische Stilometrie ist eine NLP-Technik, die es uns ermöglicht, Detektiv zu spielen, um den Autor eines Ghostwriter-Romans, eines anonymen Briefs oder einer Lösegeldforderung zu identifizieren. Das Bild von Sherlock Holmes ist gemeinfrei.
Die Verarbeitung natürlicher Sprache hilft auch bei der Diagnose von Krankheiten, der medizinischen Versorgung und der Senkung der Gesamtkosten des Gesundheitswesens. NLP kann Ärzten dabei helfen, elektronische Gesundheitsakten zu analysieren und anhand der großen Menge an Textdaten, die die Krankengeschichte einer Person detailliert beschreiben, sogar den Krankheitsverlauf vorherzusagen.
Um nur ein kommerzielles Angebot zu nennen: Amazon Comprehend Medical verwendet NLP, um Daten zu Krankheitszuständen, Medikamenten und Ergebnissen aus klinischen Studien zu sammeln. Solche Unternehmungen können bei der Früherkennung von Krankheiten helfen. Derzeit wird es für verschiedene Gesundheitszustände eingesetzt, darunter Herz-Kreislauf-Erkrankungen, Schizophrenie und Angstzustände.
IBM hat kürzlich einen kognitiven Assistenten entwickelt, der wie eine persönliche Suchmaschine funktioniert. Er kennt detaillierte Informationen über eine Person und stellt diese Informationen dann auf Nachfrage dem Benutzer zur Verfügung. Dies ist ein positiver Schritt, um Menschen mit Gedächtnisproblemen zu helfen.
Wir haben einige Beispiele für praktische Anwendungen der Verarbeitung natürlicher Sprache gesehen. Hier geben wir einen kurzen Einblick in die wichtigsten NLP-Techniken und die zugrunde liegenden Phasen einer NLP-Pipeline.
Das Bag-of-Words-Modell ist das einfachste Modell in der NLP. Wenn wir eine Bag-of-Words-Analyse durchführen, ignorieren wir die Wortreihenfolge, Grammatik und Semantik. Wir zählen einfach alle Wörter in einem Dokument und geben diese Zahlen in einen Algorithmus für maschinelles Lernen ein.
Wenn wir beispielsweise ein Modell erstellen, um Nachrichtenartikel in die Kategorien „ Sport“ oder „Finanzen“ zu klassifizieren, könnten wir den Bag-of-Words-Score für zwei Artikel wie folgt berechnen:
| Wort | Artikel A | Artikel B |
|---|---|---|
| Interesse | 3 | 1 |
| Ziel | 1 | 2 |
| Fußball | 0 | 2 |
| Bank | 2 | 0 |
Beispielhafter Bag-of-Words-Score für zwei Artikel, die wir dem Bereich Sport oder Finanzen zuordnen möchten.
Anhand des obigen Beispiels sollte es einfach sein, zu erkennen, welcher Artikel zu welcher Kategorie gehört.
Der Hauptnachteil der Bag-of-Words-Methode besteht darin, dass wir viele nützliche Informationen wegwerfen, die in der Wortreihenfolge enthalten sind. Aus diesem Grund wird Bag-of-Words in Produktionssystemen in der Praxis nicht häufig verwendet.
Die Tokenisierung ist häufig die erste Phase eines NLP-Modells. Ein Dokument wird in Teile aufgeteilt, um die Handhabung zu erleichtern. Oft ist jedes Wort ein Token, aber das ist nicht immer der Fall, und bei der Tokenisierung muss man wissen, dass Telefonnummern, E-Mail-Adressen usw. nicht getrennt werden dürfen.
Nachfolgend finden Sie beispielsweise die Token für den Beispielsatz „Wann fährst du nach England?“
| Wann | Wille | Du | verlassen | für | England | ? |
|---|
Dieses Beispiel für die Tokenisierung scheint einfach, da der Satz durch Leerzeichen getrennt werden könnte. Allerdings gelten nicht in allen Sprachen dieselben Regeln zur Worttrennung. Bei vielen ostasiatischen Sprachen wie Chinesisch ist die Tokenisierung sehr schwierig, da zwischen Wörtern keine Leerzeichen verwendet werden und es schwer ist, herauszufinden, wo ein Wort endet und das nächste beginnt. Auch im Deutschen kann die Tokenisierung schwierig sein, da zusammengesetzte Wörter je nach ihrer Funktion in einem Satz getrennt oder zusammen geschrieben werden können.
Auch bei manchen Wörtern wie „New York“ ist die Tokenisierung nicht effektiv. Sowohl „New“ als auch „York“ können unterschiedliche Bedeutungen haben, daher kann die Verwendung eines Tokens verwirrend sein. Aus diesem Grund folgt auf die Tokenisierung oft ein Schritt namens „ Chunking“ , in dem wir mehrteilige Ausdrücke, die durch einen Tokenisierer aufgeteilt wurden, wieder zusammenfügen.
Die Tokenisierung kann für die Verarbeitung von Textdomänen, die Klammern, Bindestriche und andere Satzzeichen enthalten, ungeeignet sein. Das Entfernen dieser Details bringt die Begriffe durcheinander. Um diese Probleme zu lösen, werden die folgenden Methoden in Kombination mit der Tokenisierung verwendet.
Nach der Tokenisierung werden Stoppwörter , also Pronomen, Präpositionen und allgemeine Artikel wie „zu“ und „das“, häufig verworfen. Dies liegt daran, dass sie für unsere Zwecke oft keine nützlichen Informationen enthalten und problemlos entfernt werden können. Stoppwortlisten sollten jedoch sorgfältig ausgewählt werden, da eine Liste, die für einen Zweck oder eine Branche funktioniert, für einen anderen möglicherweise nicht richtig ist.
Um sicherzustellen, dass dabei keine wichtigen Informationen ausgeschlossen werden, erstellt im Normalfall ein menschlicher Bediener die Liste mit Stoppwörtern.
Beim Stemming werden Affixe entfernt. Dies umfasst sowohl Präfixe als auch Suffixe aus den Wörtern.
Suffixe stehen am Ende des Wortes. Beispiele für Suffixe sind „-able“, „-acy“, „-en“, „-ful“. Wörter wie „wonderfully“ werden in „wonderful“ umgewandelt.
Präfixe stehen vor einem Wort. Einige der häufigsten Beispiele für Präfixe sind „hyper-“, „anti-“, „dis-“, „tri-“, „re-“ und „uni-“.
Um Stemming durchzuführen, wird eine allgemeine Liste von Affixen erstellt und diese werden programmgesteuert aus den Wörtern in der Eingabe entfernt. Stemming sollte mit Vorsicht verwendet werden, da es die Bedeutung des eigentlichen Wortes verändern kann. Stemmer sind jedoch einfach zu verwenden und können sehr schnell bearbeitet werden. Ein häufig verwendeter Stemmer im Englischen und in anderen Sprachen ist der Porter Stemmer .
Die Lemmatisierung verfolgt ein ähnliches Ziel wie die Wortstammbildung: Die verschiedenen Formen eines Wortes werden in eine einzige Grundform umgewandelt. Der Unterschied besteht darin, dass die Lemmatisierung auf einer Wörterbuchliste basiert. „ate“, „eating“ und „eaten“ werden also alle auf der Grundlage des Wörterbuchs in „eat“ abgebildet, während ein Algorithmus zur Wortstammbildung dieses Beispiel nicht verarbeiten könnte.
Lemmatisierungsalgorithmen müssen idealerweise den Kontext eines Wortes in einem Satz kennen, da die korrekte Grundform beispielsweise davon abhängen kann, ob das Wort als Substantiv oder Verb verwendet wurde. Darüber hinaus kann eine Wortbedeutungs-Disambiguierung erforderlich sein, um identische Wörter mit unterschiedlichen Grundformen zu unterscheiden.
Need a new NLP approach?

Viele Jahrzehnte lang versuchten Forscher, natürlichsprachliche Texte zu verarbeiten, indem sie immer kompliziertere Regelreihen schrieben. Das Problem bei diesem regelbasierten Ansatz besteht darin, dass die Grammatik des Englischen und anderer Sprachen eigentümlich ist und keinem festen Regelsatz folgt.
Als ich an unserem Clinical Trial Risk Tool arbeitete, musste ich eine Reihe von Schlüsselwerten aus technischen Dokumenten ermitteln. Einer der Werte, die ich brauchte, war die Anzahl der Teilnehmer an einer Studie. Ich versuchte, eine Reihe von Regeln zu schreiben, um die Anzahl der Teilnehmer aus einem klinischen Studienprotokoll (dem PDF-Dokument, das beschreibt, wie eine Studie durchgeführt werden soll) zu extrahieren. Ich fand Sätze wie die folgenden:
Wir haben 450 Teilnehmer rekrutiert
Die Teilnehmerzahl betrug N= 231
Ursprünglich war geplant, 45 Probanden zu rekrutieren. Aufgrund von Studienabbrüchen lag die endgültige Zahl jedoch bei 38.
Sie sehen, wie schwierig es wäre, einen robusten Satz von Anweisungen zu schreiben, sodass ein Computer die richtige Zahl zuverlässig identifizieren kann.
Bei dieser Art von Problem ist es daher oft sinnvoller, den Computer die schwere Arbeit machen zu lassen. Wenn Sie mehrere tausend Dokumente haben und die tatsächliche Anzahl der Teilnehmer in jedem dieser Dokumente kennen (vielleicht sind die Informationen in einer externen Datenbank verfügbar), kann ein neuronales Netzwerk lernen, die Muster selbst zu finden und die Anzahl der Beteiligten in einem neuen, noch nicht gesehenen Dokument zu erkennen.
Ich bin davon überzeugt, dass dies der Weg in die Zukunft ist und dass einige der traditionellen NLP-Techniken mit der zunehmenden Verfügbarkeit von Rechenleistung und den wissenschaftlichen Fortschritten immer weniger zum Einsatz kommen werden.
Zu den häufig für NLP verwendeten neuronalen Netzwerken gehören LSTM , Convolutional Neural Networks und Transformers .
Der Bereich der Verarbeitung natürlicher Sprache hat in den letzten Jahrzehnten Fortschritte gemacht und einige bedeutende Wege zu einer fortschrittlicheren und besseren Welt eröffnet. Obwohl die Entschlüsselung der weltweit verwendeten Sprachen und Dialekte noch immer eine Herausforderung darstellt, verbessert sich die Technologie weiterhin rasant.
NLP wird bereits bei der Entwicklung von Gesundheitslösungen eingesetzt und hilft Unternehmen, die Erwartungen ihrer Kunden zu erfüllen. Wir können davon ausgehen, dass die Verarbeitung natürlicher Sprache unser Leben in Zukunft auf viele weitere unerwartete Arten beeinflussen wird. Weitere Informationen zu geschäftlichen Einsatzmöglichkeiten der Verarbeitung natürlicher Sprache finden Sie in unserem begleitenden Blogbeitrag .
Entfesseln Sie das Potenzial Ihrer NLP-Projekte mit dem richtigen Talent. Veröffentlichen Sie Ihre Stelle bei uns und ziehen Sie Kandidaten an, die genauso leidenschaftlich über natürliche Sprachverarbeitung sind.
NLP-Experten einstellen
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you