
Ein Überblick über die Herausforderungen, denen Sie bei der Verarbeitung natürlicher Sprache auf mehrsprachige Daten begegnen.
Die meisten Projekte, die ich übernehme, beinhalten unstrukturierte Textdaten nur in englischer Sprache, aber in letzter Zeit habe ich immer mehr Projekte gesehen, die Text in verschiedenen Sprachen beinhalten, oft auch alle miteinander vermischt. Das ist eine lustige Herausforderung.
Vor kurzem hatte ich ein Projekt, bei dem es um Texte in 12 Sprachen ging, von denen jede ihre eigenen Probleme mit sich brachte. Ich möchte einige der seltsamen und wunderbaren Dinge durchgehen, auf die man stößt, wenn man versucht, ein System zur mehrsprachigen Verarbeitung natürlicher Sprache zu erstellen.
In einigen Bereichen der NLP sind alle verfügbaren Texte in einer einzigen Sprache. Ein Beispiel wäre ein Projekt zur Bearbeitung wissenschaftlicher Arbeiten, die im 21. Jahrhundert ausschließlich auf Englisch verfasst werden.
Projekte, die informelle Kommunikation zwischen Ländern beinhalten, enthalten jedoch oft Texte in mehreren Sprachen. Ein Data-Science-Projekt in der Marktforschung, das transkribierte Interviews mit Kunden aus verschiedenen Märkten umfasst, enthält wahrscheinlich unstrukturierten Text in verschiedenen Sprachen. Multinationale Marketingagenturen verfügen über Datensätze mit Fragen wie „ Wie gut passt die Verpackung Ihrer Meinung nach zum Produkt?“, die in mindestens zwei Varianten von Englisch, Spanisch und Portugiesisch gestellt werden.
Wenn unser Projekt wahrscheinlich Text in verschiedenen Sprachen enthält, müssen wir vorsichtig sein, welche NLP- Techniken wir verwenden. Wenn wir uns an Modelle und Toolkits halten, die auf Englisch gut funktionieren, könnten wir überrascht sein, wenn Dinge nicht mehr funktionieren.
Eine der einfachsten Möglichkeiten zum Erstellen eines Modells zur Verarbeitung natürlicher Sprache ist der Bag-of-Words-Ansatz . Dabei reduzieren wir einen Text auf die darin enthaltenen Wörter und können so sehr schnell und einfach eine Ähnlichkeitsmetrik zweier Dokumente ermitteln, indem wir die gemeinsamen Wörter zählen.
Wenn Sie sehr kurze Texte und nur wenige Trainingsdaten haben (und Ihr Text auf Englisch ist!), ist der Bag-of-Words- Ansatz großartig! Er ist nicht so gut bei Synonymen oder Beugungen (denken Sie an „drive“ -> „driving “), aber er funktioniert. Wenn wir beispielsweise zwei englische Sätze mit einem Bag-of-Words-Ansatz auf Ähnlichkeit vergleichen möchten, können wir Folgendes tun:
Bag-of-Words für zwei englische Sätze
Allerdings verfügen viele Sprachen über eine große Anzahl von Suffixen, die den Bag-of-Words-Ansatz erschweren.
Wenn wir ähnliche Texte auf Türkisch vergleichen möchten ( Sinirli, kaygılı, endişeli misiniz = fühlen Sie sich nervös, ängstlich oder gereizt, Endişeleniyorum = ich bin nervös), stehen wir sofort vor einer Herausforderung, da keine Wörter gemeinsam sind. Endişeleniyorum bedeutet „ich bin nervös/sorgenvoll“ und endişeleniyoruz bedeutet „wir sind nervös/sorgenvoll“. Um einen Bag-of-Words-Text zu verwenden, bräuchten wir sofort einen türkischen Stemmer oder Lemmatisierer , der die Wurzel jedes Wortes findet – aber indem wir jedes Wort durch seine Wurzel ersetzen, gehen wichtige Informationen wie Verneinung, Zeitformen oder Pronomen verloren.
Das bedeutet, dass Sie, wenn Sie ein System für Vergleiche auf Wortebene (wie etwa ein Informationsabrufsystem oder eine Suchmaschine) entwickeln, darüber nachdenken müssen, wie Sie mit Sprachen wie Türkisch umgehen und sich vom einfachen Wortabgleich entfernen. Ich habe die obigen türkischen Wörter in einem türkischen Stemmer in Python ausprobiert, um zu sehen, ob endişeleniyoruz und endişeli auf dieselbe Wurzel abgebildet werden, aber das war immer noch nicht der Fall (siehe Codeausschnitt unten) – selbst wenn Sie dieses Problem in einer stark flektierenden Sprache wie Türkisch vorhersehen, ist es möglicherweise nicht leicht zu lösen.
> pip installieren TurkishStemmer
Sammeln von TurkishStemmer
TurkishStemmer-1.3-py3-none-any.whl wird heruntergeladen (20 kB)
Gesammelte Pakete installieren: TurkishStemmer
TurkishStemmer-1.3 erfolgreich installiert
> [Python](https://www.python.org)
> > > von TurkishStemmer importieren TurkishStemmer
> > > [stemmer](https://tartarus.org/martin/PorterStemmer) = TürkischStemmer()
> > > stemmer.stem("endişeleniyoruz") # wir machen uns Sorgen
'Ende des Lebens'
> > > stemmer.stem("Ende") # ängstlich
'Ende'
> > > stemmer.stem("sürüyorum") # Ich fahre
'sürüyor'
> > > stemmer.stem("sürdüm") # Ich fuhr
'sürt'
Deutsch, Schwedisch und Niederländisch sind bekannt für ihre langen Wörter, die aus aneinandergefügten Wörtern bestehen. Diese können jedoch NLP- Systeme, die nur für Englisch entwickelt wurden, beschädigen.
Kürzlich musste ich dieses Problem bei einem Projekt zur Textanalyse für eine Sprachlern-App lösen. Für Deutsch verwende ich eine Bibliothek namens German Compound Splitter . Sobald Deutsch zum Projekt hinzugefügt wurde, musste ich ein separates Paket installieren, um die Komposita aufzuteilen, und außerdem ein deutsches Wörterbuch einbinden (dessen Lizenzbedingungen ich überprüfen musste). Das Aufteilen von zusammengesetzten Wörtern ist ein überraschend schwieriges Problem, da es mehrere gültige Aufteilungen geben kann.
Das Wort „ Kernkraftwerk “ ist ein interessanter Fall, da es aus drei zusammengefügten Substantiven besteht:
der Kern
die Kraft = power
das Werk = Fabrik / Arbeit
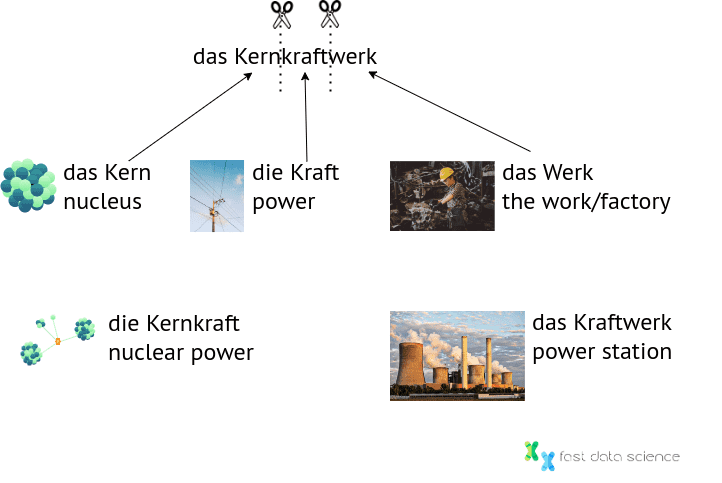
Möchten Sie es in die Kernkraft + das Werk oder das Kern + das Kraftwerk oder sogar das Kern + die Kraft + das Werk aufteilen? Grammatikalisch wäre alles gültig, aber es hängt davon ab, wofür Sie es verwenden möchten. Ich würde mich wohl für Kern + Kraftwerk entscheiden, da ein Kernkraftwerk eine Art Kraftwerk ist und dies für die meisten Zwecke wahrscheinlich die aufschlussreichste Aufteilung wäre - wenn Sie beispielsweise in einer Datenbank nach Informationen zu einem Kraftwerk suchen und ein Artikel zu einem Kernkraftwerk gefunden wird, könnte dieser dennoch von Interesse sein - obwohl das Gegenteil nicht unbedingt der Fall sein müsste! Eine Möglichkeit wäre, alle Aufteilungen zu generieren, um keine falsche Entscheidung zu treffen.
Im Englischen ist es ziemlich einfach, einen Text in Wörter zu zerlegen. Wie wir jedoch anhand der türkischen und deutschen Beispiele oben gesehen haben, sind die in einem Wort enthaltenen Informationen in verschiedenen Sprachen nicht immer gleich. In manchen Sprachen kann es sogar schwierig sein, einen Satz in Wörter zu zerlegen.
Im Hebräischen und Arabischen werden Artikel und Präpositionen zusammen geschrieben. „Der Computer“ wird also als الكمبيوتر „alkumbyutar“ geschrieben und „Mit dem Auto“ als بالسيارة „bissayaara“, wobei die drei Wörter „bi “ (mit), „ al “ (das) und „sayaara “ (Auto) aneinandergereiht werden.
Bei den ostasiatischen Sprachen geht dies jedoch noch auf eine andere Ebene. Chinesisch, Japanisch und Thailändisch werden völlig ohne Leerzeichen geschrieben, sodass die erste Stufe einer NLP- Pipeline für diese Sprachen ein Tokenisierer ist, der maschinelles Lernen verwendet, um zu erkennen, wann ein Wort endet und das nächste beginnt.
Bei englischen Texten kommt es häufig zu Texten in britischen und US-Varianten. Wenn Sie beispielsweise Umfrageantworten sowohl in britischem als auch in amerikanischem Englisch haben und beliebte Begriffe hervorheben möchten, wird der Popularitätswert dieses Worts fälschlicherweise reduziert, wenn die Hälfte Ihrer Benutzer „sanitize“ und die andere Hälfte „ sanitize“ geschrieben hat und das System es als einzelnes Wort behandelt.
Ich bin bei mehreren Projekten auf dieses Problem gestoßen und habe angefangen, eine Reihe von Regeln zu sammeln, um alle Texte entweder ins Britische oder Amerikanische zu normalisieren. Diese habe ich in einer Bibliothek namens localspelling als Open Source zur Verfügung gestellt. Sie verwendet einige allgemeine Regeln (wie das Suffix -ise/ize) in Kombination mit einem wörterbuchbasierten Ansatz, aber Wörter wie program/programme bleiben unberührt, da sie zu viel Mehrdeutigkeit aufweisen (da in Großbritannien beide Varianten existieren).
Seit ich an einigen Projekten mit brasilianischem Portugiesisch arbeite, habe ich festgestellt, dass es im Portugiesischen in Portugal und Brasilien ähnliche Unterschiede in der Rechtschreibung gibt. Ich kann mir vorstellen, dass der gleiche Ansatz hier nützlich sein könnte.
Einige Sprachen haben mehrere Schriftsysteme. Serbisch kann beispielsweise in Latein oder Kyrillisch geschrieben werden, und es besteht meist eine 1:1-Übereinstimmung zwischen beiden, aber nicht immer (das kyrillische System enthält etwas mehr Informationen, sodass man eindeutig von Kyrillisch zu Latein wechseln kann, aber nicht umgekehrt).
Im Chinesischen gibt es die vereinfachte (Festlandchina) oder traditionelle Variante (Taiwan und Hongkong), und im Japanischen gibt es die Kana- und Kanji-Darstellung von Wörtern.
Für jede Sprache, in der Ihr NLP- System wahrscheinlich auf Text in verschiedenen Alphabeten oder Schriftsystemen stößt, müssen Sie auf eine kanonische Form normalisieren. Jede Sprache mit diesem Problem verfügt über einen bestimmten Satz von Online-Tools, die von Muttersprachlern verwendet werden (z. B. wenn ein Chinesischsprecher Text von traditionell in vereinfacht konvertieren möchte), und es gibt auch eine Reihe von APIs und Bibliotheken, die die Ersetzung durchführen.
In den meisten Fällen erfolgt der Wechsel zwischen Schriftsystemen durch Buchstaben-für-Buchstaben-Ersetzung, wobei entweder handschriftliche Regeln oder statistische oder maschinelle Lernmodelle zur Behandlung der Randfälle verwendet werden. Die meisten vereinfachten chinesischen Schriftzeichen haben in der traditionellen Schrift nur eine einzige Darstellung, manche jedoch mehr als eine. Zum Beispiel:
Im vereinfachten Chinesisch bedeutet das Zeichen 发 entweder „Haar“ oder „senden“ .
In traditionellen Schriftzeichen wird 发 發 geschrieben, wenn es „senden“ bedeutet, und 髮, wenn es „Haar“ bedeutet.
Glücklicherweise gibt es mehrere Websites, Python-Bibliotheken und Nachschlagetabellen, die die Konvertierung in beide Richtungen durchführen können. Das Zeichen 发 kommt nie allein vor, sondern ist normalerweise Teil eines zweistelligen Wortes wie 发送/發送fāsòng (senden) oder 頭髮/头发tóufà (Haar) – das bedeutet, dass die Begriffsklärung einfacher ist, als es klingt, da sie durch ein wenig Zahlenrechnen gelöst werden kann.
Allerdings verfügen manche Sprachen über ein Schriftsystem, das für NLP so schwierig ist, dass allein für die Transkription ein ganzes neuronales Netzwerk erforderlich ist …
Multilingual NLP
Die schwierigste NLP-Herausforderung, die ich bisher gefunden habe, ist Hebräisch. Um die Aussprache (z. B. die Romanisierung) eines hebräischen Wortes zu verstehen, müssen Sie den gesamten Satz lesen. Sie können nicht ein einzelnes Wort einzeln romanisieren.
Beispielsweise wird das Verb „wollen“ bei einem männlichen Subjekt als „rotzeh“ ausgesprochen, bei einem weiblichen Subjekt als „rotzah“, beide werden aber gleich geschrieben: רוצה . Vokale werden normalerweise nicht ausgeschrieben und um die Sache noch schwieriger zu machen, ergeben mehrere Konsonantenbuchstaben den gleichen Laut, manche ergeben zwei Laute und manche sind stumm.
Ein Satz wie תומס רוצה (Thomas will) wird also Thomas rotzeh ausgesprochen.
Aber חנה רוצה (Hannah will) wird Hannah rotzah ausgesprochen.
Bewegen Sie den Schieberegler im Bild unten, um zu sehen, wie viele Informationen in den Vokalen verborgen sind!


Die Laute b und v werden mit demselben Buchstaben gebildet und unterscheiden sich nur durch einen optionalen Punkt, der „Dagesh“ genannt wird.
Weil dieses System so viele Mehrdeutigkeiten schafft, gibt es im Hebräischen zwei optionale Systeme zur Angabe der Aussprache: die klassische Methode, bei der Punkte und Markierungen, sogenannte Nikkud, innerhalb, über und unter den Buchstaben hinzugefügt werden, und eine modernere Methode namens Kivt Maleh , bei der zusätzliche Buchstaben (Vav und Yod) eingefügt werden.
Ich konnte keinen einfachen Python-Import finden, um Hebräisch zu romanisieren. Was ich finden konnte, war ein neuronales Netzwerk namens Nakdimon , das als Docker-Container läuft und Hebräisch ohne Vokale in Hebräisch mit Nikkud und Dagesh umwandeln kann. Ich musste dann meine eigenen Regeln schreiben, um das Hebräisch mit vollem Vokal in lateinische Buchstaben umzuwandeln. In meiner bereitgestellten Anwendung läuft Nakdimon also auf einem eigenen Server. Das bedeutet, dass Hebräisch die einzige Sprache ist, die einen zusätzlichen Server benötigt (Kosten bis zu 50 $/Monat), nur um das Alphabet zu interpretieren!
Sie können unten meinen hebräischen Vokalisierer und Romanisierer (basierend auf Nakdimon) ausprobieren. Die Zeitverzögerung beim Hinzufügen von Vokalen zu einem einfachen hebräischen Satz zeigt uns, wie viel Kopfzerbrechen die hebräischen Vokale bereiten.
Geben Sie eine Textpassage in Hebräisch ohne Vokale ein (versuchen Sie es für beste Ergebnisse mit ein paar Wörtern): Beispieltexte: Böker tov (Guten Morgen) Thomas möchte eine heiße Schokolade bestellen. Sara möchte einen Kaffee.
[Geben Sie einen Text auf Hebräisch ein. Das Hebräische mit allen Vokalen wird hier angezeigt.]
[Geben Sie einen Text ein und der romanisierte Text wird hier angezeigt]
Ich werde auf einige der Probleme eingehen, die auftreten, wenn Sie einem Benutzer Text in einer Wortwolke , einem Diagramm oder einer Grafik anzeigen möchten, und wie Sie diese Probleme beheben können.
Wenn Sie Anfang der 2000er Jahre jemals eine nicht-englische Website besucht haben, waren Sie mit der Kodierung von verstümmeltem Text vertraut. Wenn eine Datei nach einem bestimmten Regelsatz erstellt wurde, um Ziffern in Buchstaben zu übersetzen (eine sogenannte Kodierung), und von einem anderen Benutzer mit einer anderen Kodierung gelesen wurde, war das Ergebnis eine Buchstabensuppe. Heutzutage ist dies weniger üblich, kann aber immer noch vorkommen.
Beispielsweise kodiert die Zeichenkodierung UTF-8 den deutschen Buchstaben Ü als zwei Zahlen: 195, 156. Wenn Sie die Folge 195, 156 mit der UTF-8-Kodierung interpretieren, erhalten Sie (korrekterweise) Ü. Wenn Sie sie jedoch mit einer anderen Kodierung namens Latin-1 (ISO-8859-1) lesen, erhalten Sie Ã\x9c, was Kauderwelsch ist.
Ein Programm, das Text in der falschen Kodierung liest, würde das deutsche Wort „Übersetzen“ also folgendermaßen anzeigen:
Ã\\x9cbersetzen
was bereits schwer verständlich ist, und das türkische Wort görüşürüz würde wie folgt angezeigt:
görüÅ\\x9fürüz
1991 gründete eine Gruppe von Technologieunternehmen das Unicode-Konsortium mit dem Ziel, dass Texte in jeder Sprache weltweit korrekt dargestellt werden können. Unicode ist im Grunde eine Liste aller Buchstaben oder Zeichen aus jeder Sprache der Welt, wobei jedem eine Nummer zugewiesen ist. Ein kleines a hat also die Zeichennummer 97 und der hebräische Buchstabe א (Aleph) die Nummer 1488, unabhängig von der verwendeten Schriftart.
Der Unicode-Standard hat das Problem der Buchstabensuppe gelöst, allerdings nicht ohne Kontroversen. Arbeitsgruppen aus China, Taiwan und Japan debattierten hitzig, welche Versionen der einzelnen Zeichen in der Unicode-Kodierung Vorrang erhalten würden . Das Ergebnis ist, dass Zeichen, die sich von Land zu Land stark unterscheiden, separate Unicode-Kodierungen haben, wie z. B. 囯 (22269) und 國 (22283) (beide bedeuten Land), während Varianten mit geringfügigen Unterschieden eine einzelne Nummer zugewiesen bekommen und die Wahl der Schriftart bestimmt, wie sie angezeigt wird.

„Schnee“ (Zeichen 38634) in der Schriftart Noto Sans Traditional Chinese. Hier ist das Zeichen in der Schriftart, die Ihr Computer verwendet: 雪

„Schnee“ (Zeichen 38634) in der Schriftart Noto Sans Simplified Chinese. Hier ist das gleiche Zeichen in der Schriftart, die Ihr Computer verwendet: 雪
Obwohl die größte Errungenschaft des Unicode-Konsortiums darin besteht, die Schriftsysteme der Welt zu indizieren und beide Seiten der Taiwanstraße dazu zu bewegen, sich darauf zu einigen, scheint Unicode seltsamerweise nur dann das Interesse der Medien zu wecken, wenn neue Emojis zur Liste hinzugefügt werden! Dank Unicode wird ein Emoji, das Sie jemandem per WhatsApp schicken, auch dann korrekt angezeigt, wenn der Empfänger ein Telefon eines anderen Herstellers hat.
Heutzutage können wir Buchstabensalat vermeiden, indem wir uns an die UTF-8-Kodierung halten, die alle Alphabete verarbeitet. Sie müssen jedoch darauf achten, Dateien immer mit der UTF-8-Kodierung zu lesen und zu schreiben. Beispielsweise ist die folgende Python-Codezeile zum Lesen einer Datei gefährlich, da sie abstürzen kann, wenn die Datei nicht-englischen Text enthält.
f = öffnen("demofile.txt", " [r](https://en.wikipedia.org/wiki/R_%28programming_language%29) ")
und die korrekte Art, eine Datei in Python zu lesen, besteht darin, immer die angegebene Kodierung zu verwenden:
f = öffnen("demofile.txt", " [r](https://www.r-project.org) ", Kodierung="utf-8")
Ich musste kürzlich eine Bibliothek zur Anzeige mehrsprachiger Wortwolken entwickeln und stieß dabei auf das Problem, dass es keine Schriftart gibt, die alle Sprachen abdeckt. Selbst wenn Ihr Text in der richtigen Sprache ist, müssen Sie auch eine Schriftart mit Glyphen für diese Sprache haben. Einige Sprachen haben Regeln, wie sich das Erscheinungsbild eines Buchstabens je nach Umgebung ändern soll. Diese werden von den Schriftartdateien behandelt. Beispielsweise wird der arabische Buchstabe ة als ـة angezeigt, wenn er mit einem Buchstaben rechts von ihm verbunden ist. Aber egal, wie er angezeigt wird, er hat immer dieselbe Kodierung: 1577 (dies entspricht dem Unicode-Prinzip, dass jedes Zeichen nur eine Kodierung hat, auch wenn es in einem Text als mehrere Glyphen dargestellt werden kann).
Ich habe ein paar nützliche Schriftfamilien gefunden, die alle Sprachen abdecken. Beispielsweise ist Google Noto eine Schriftfamilie, die viele Sprachen abdeckt, und Sie können je nach gewünschter Sprache die richtige Variante von Google Noto (oft „Google Noto [SPRACHNAME]“ genannt) anwenden.
Ich habe einen Entscheidungsbaum zusammengestellt, der bei der Entscheidung helfen soll, welche Schriftart zum Anzeigen von Text in einer bestimmten Sprache verwendet werden soll:
| Sprache Name | Gibt es eine Schriftart für diese Sprache? | Schriftart wählen |
|---|---|---|
| Englisch | Noto Sans Englisch -> existiert nicht | Noto Sans |
| Russisch | Noto Sans Russisch -> existiert nicht | Noto Sans (diese hat neben römischen auch kyrillische Zeichen) |
| Arabisch | Noto Sans Arabic -> existiert | Noto Sans Arabisch |
| Chinesisch (Festland) | Sonderregel: Noto Sans vereinfachtes Chinesisch | Noto Sans Vereinfachtes Chinesisch |
| Griechisch | Noto Sans Gujarati -> existiert | Noto Sans Gujarati |
Zur Veranschaulichung ist Folgendes passiert, wenn ich versuche, arabischen Text in einer Python-Wortwolke anzuzeigen, ohne explizit eine arabische Schriftart zu laden:

Dies ist derselbe Text mit geladener Schriftart, aber wenn die Rechts-nach-links-Logik nicht richtig konfiguriert ist (sodass die Buchstaben neu geformt und zusammengefügt, aber in der falschen Reihenfolge angezeigt werden):

Und dies ist der Text mit korrekt geladener Schriftart:

Eines der häufigsten Probleme, das ich überall sehe, sind fehlende Zeichenkodierungen. Das liegt vermutlich daran, dass man keine Sprachkenntnisse braucht, um zu erkennen, wenn die Kodierung völlig kaputt ist: Der Text wird als Quadrate oder bedeutungslose Symbole statt als Buchstaben angezeigt.
Viel häufiger kommt es vor, dass Arabisch und Hebräisch in die falsche Richtung gelesen werden und die Buchstaben nicht umgeformt werden. Wenn ich arabischen Text auf einem Schild in einem Flughafen oder Geschäft sehe, ist der Text recht häufig in die falsche Richtung geschrieben, aber da er für einen Nicht-Sprecher gleich aussieht, wird er oft übersehen.
Glücklicherweise gibt es einen einfachen Hinweis, mit dem Sie überprüfen können, ob die bidirektionale Textanzeige richtig funktioniert. In beiden Sprachen gibt es Buchstabenformen, die nur am Ende eines Wortes zulässig sind. Wenn Sie also einen dieser letzten Buchstaben rechts sehen, wissen Sie, dass Ihr Text falsch herum ist.
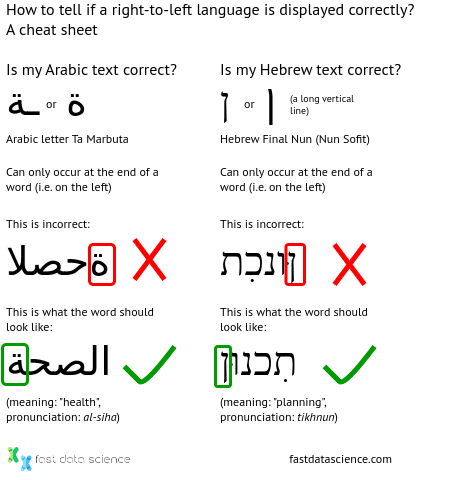
Ein Spickzettel zum Überprüfen Ihres Textes in einer von rechts nach links gelesenen Sprache wie Arabisch oder Hebräisch wird korrekt angezeigt.
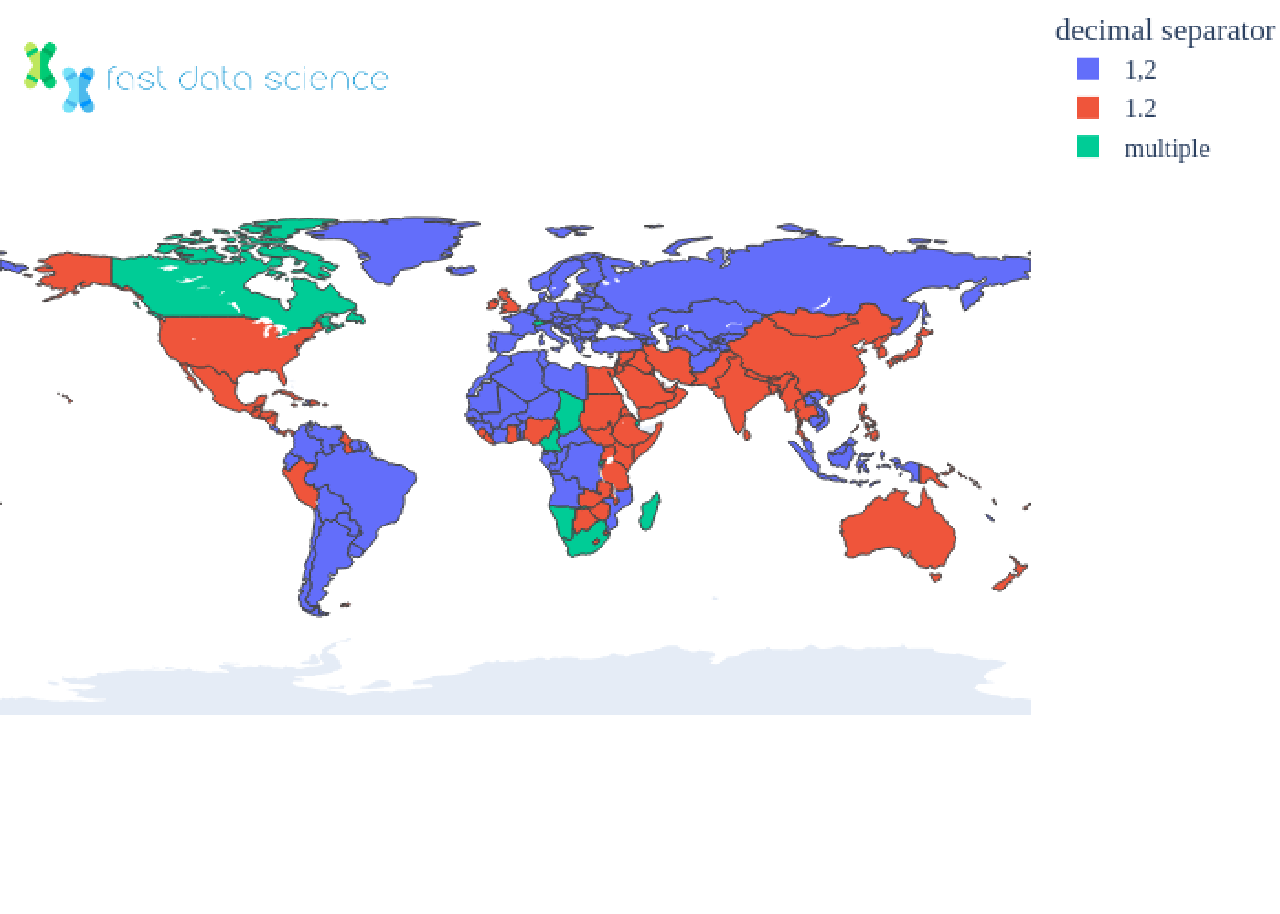
Wenn Sie beispielsweise schon einmal Tabellenkalkulationen und CSV-Dateien (Comma-Separated Value) zwischen englischen und deutschen Computern übertragen haben, ist Ihnen möglicherweise ein seltsames Verhalten aufgefallen, und manchmal werden CSV-Dateien nicht geladen. Wenn eine Tabellenkalkulation mit einer Zahl wie 54,2 als CSV aus einem englischsprachigen Excel gespeichert und in einen deutschen Computer mit derselben Excel-Version geladen wird, wird die Zahl möglicherweise falsch analysiert. Dies liegt daran, dass verschiedene Länder unterschiedliche Dezimal- und Tausendertrennzeichen haben und in Deutschland der „.“ ein Tausendertrennzeichen und das „“ das Dezimaltrennzeichen ist – das Gegenteil der englischen Konvention!
Die Zahl 12345,6 kann je nach Gebietsschema in den folgenden Varianten angezeigt werden:
| Länder | Wie die Nummer angezeigt werden könnte |
|---|---|
| Großbritannien, USA | 12.345,6 |
| Deutschland | 12.345,6 |
| Schweiz | 12'345,6 |
| Frankreich | 12 345,6 |
Tatsächlich gibt es in verschiedenen Ländern unterschiedliche Möglichkeiten, mit Dezimalzahlen und Tausendern umzugehen. Einige Länder verwenden völlig andere Symbole, wie beispielsweise das arabische Dezimaltrennzeichen ٫, und in Indien wird bei Tausend, Hunderttausend und Zehnmillionen ein Komma verwendet.
Zweisprachige Länder können für verschiedene Sprachen unterschiedliche Konventionen haben und dieselbe Sprache kann in jedem Land eine Variante haben. Aus diesem Grund werden Gebietsschemata normalerweise als zweistelliger Sprachcode und zweistelliger Ländercode ausgedrückt, z. B. bedeutet de_DE „Deutsch, wie es in Deutschland gesprochen wird“.
Das Schwierige am Umgang mit Gebietsschemata ist, dass Computer das Gebietsschema normalerweise global, auf der Ebene des gesamten Systems, festlegen. Wenn Ihr Computer also auf Deutsch eingestellt ist, wird Excel normalerweise auf Deutsch ausgeführt. Wenn Sie ein Programm zum Parsen von Zahlen in mehreren Gebietsschemata schreiben möchten, beinhalten die meisten Beispiele, die ich online gefunden habe, das Festlegen des Systemgebietsschemas, das Parsen einer Zahl und das Zurücksetzen.
Nachfolgend sehen Sie eine Aufschlüsselung, wie in verschiedenen Ländern Dezimalstellen und Tausender getrennt werden:

Eine nützliche Lösung ist die Python-Bibliothek Babel , die speziell für diese Art von Internationalisierungsproblemen entwickelt wurde. Der folgende Codeausschnitt funktioniert beispielsweise und zeigt, wie Sie eine Zahl in verschiedenen Gebietsschemas drucken können, ohne das Systemgebietsschema zu ändern:
Gebietsschema importieren
von Babel Importnummern
drucken (Zahlen.Format\_Dezimal(12345.6, locale='de\_DE')) # Deutsch (Deutschland)
druckt 12.345,6
===============
drucken (Zahlen.Format\_Dezimal(12345.6, Gebietsschema='de\_CH')) # Deutsch (Schweiz)
12'345.6
========
drucken (Zahlen.Format\_Dezimal(12345.6, Gebietsschema='fr\_FR')) # Französisch (Frankreich)
druckt 12 345,6
===============
Anstatt separate Pakete und Codes für die Verarbeitung von Texten in verschiedenen Sprachen zu verwenden, setzt sich ein neuer Ansatz durch: Es gibt Modelle, die vollständig mehrsprachig sind und mit Texten in mehreren Sprachen trainiert wurden. Das Transformer- Modell BERT ist beispielsweise in sprachspezifischen Versionen und einer mehrsprachigen Variante, BERT-Base-Multilingual, verfügbar.
Diese mehrsprachigen Modelle verarbeiten Text sprachunabhängig. Wenn Sie zum Erstellen von Chatbots ein Paket wie Microsoft NLU verwenden, können Sie auch Trainingsdaten in einer Sprache hochladen und Ihren Chatbot in einer anderen ausführen – obwohl meiner Erfahrung nach die Leistung leicht nachlässt, wenn Sie einen Chatbot in einer Sprache verwenden, in der er nicht trainiert wurde.
Ich habe einige Experimente mit Microsoft Language Studio gemacht. Microsoft behauptet, dass
„Wenn Sie mehrere Sprachen in einem Projekt aktivieren, können Sie das Projekt primär in einer Sprache trainieren und sofort Vorhersagen in anderen erhalten.“
Dokumentation zu Microsoft Azure Cognitive Services
Ich habe das auf die Probe gestellt. Ich habe versucht, ausschließlich englischsprachige Trainingsdaten in meinen Chatbot hochzuladen und sie mit spanischem Text zu testen. Dann habe ich versucht, einen Chatbot mit ausschließlich spanischsprachigem Text und mit einer Mischung aus spanischem und englischem Text zu trainieren, um zu sehen, was am besten ist. Ich habe festgestellt, dass das auf Spanisch trainierte Modell die beste Leistung erbrachte, dicht gefolgt vom englischen Modell.
Ich habe festgestellt, dass bei Sprachen mit weniger Ressourcen, wie etwa Swahili, die Leistung noch viel stärker nachließ. Ein Modell, das ausschließlich mit englischen Daten trainiert wurde, wäre also für die Kategorisierung von Swahili-Eingaben überhaupt nicht von großem Nutzen.
Ich habe auch eine Reihe von Experimenten durchgeführt, bei denen ich englische und portugiesische Datensätze zum Thema psychische Gesundheit für das Harmony-Projekt verglichen habe, das eine Zusammenarbeit mit mehreren Universitäten ist. Ich habe festgestellt, dass Transformer- Modelle wie die auf HuggingFace Hub verfügbaren am besten mit Daten in einer einzigen Sprache funktionieren, aber in der Lage sind, Stimmungen über Sprachen hinweg abzugleichen. Mehr dazu können Sie hier lesen.
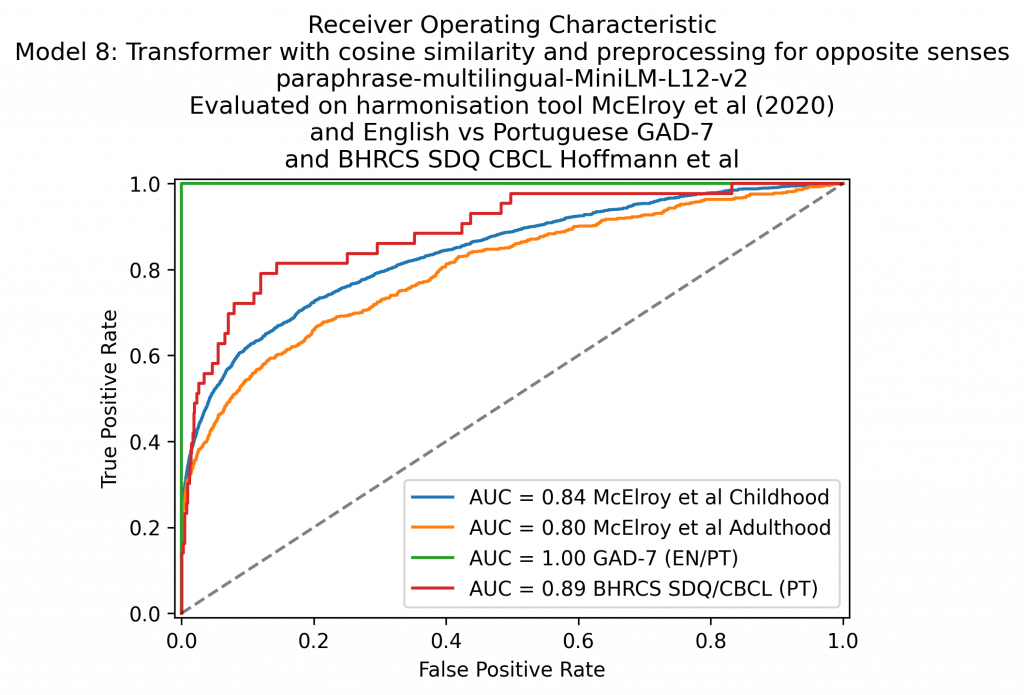
Beim Experimentieren mit Transformer -Modellen fand ich auf dem HuggingFace- Hub eine Reihe von Modellen für unterrepräsentierte Sprachen und konnte mit dem Shona-Konzept (Simbabwe) von kufungisisa („zu viel denken“) experimentieren. Forscher der Grassroots-NLP-Gruppe Masakhane haben NLP-Modelle für eine Reihe afrikanischer Sprachen entwickelt, darunter auch Shona. Weitere Informationen zu meinen Experimenten mit Shona-Texten finden Sie in diesem Blogbeitrag .
Dies sind die Bibliotheken, die ich als nützlich empfunden habe und die ich in meinen Projekten verwende. Es gibt noch viele weitere Ressourcen , die ich jedoch nicht verwendet habe. Ich arbeite mit Python. Wenn Sie also eine andere Programmiersprache verwenden, müssen Sie möglicherweise ein Äquivalent in Ihrem Stack finden.
Langdetect - das funktioniert am besten, wenn Sie ihm ein paar Sätze geben, und es neigt dazu, falsche Antworten zu geben, wenn Ihr Text sehr kurz oder chaotisch ist (wie z. B. Text aus dem Internet mit vielen Tippfehlern ). Ich würde empfehlen, dass Sie dies auch mit einer kurzen Liste der Sprachen kombinieren, die Sie erwarten.
Unicodeblock – diese Python-Bibliothek verrät Ihnen den Unicode-Block eines Zeichens. Wenn Sie also in einem Dokument auf ein Zeichen aus dem KATAKANA-Block stoßen, ist Ihr Text wahrscheinlich japanisch. Dies ist robuster als der statistische Ansatz von Langdetect.
Chinesische Pinyin-Bibliothek xpinyin
Konvertierung von vereinfachtem/traditionellem Chinesisch (HanziConv)
Hebräisches Nikkud-Werkzeug Nakdimon
Russisch, Ukrainisch, Griechisch: Transliteration
Koreanisch: Koreanischer Romanisierer
Japanische Romaji-Konvertierung: Cutlet
Englische UK/US-Rechtschreibung: Localspelling
Wenn Sie nichts dagegen haben, einen API-Aufruf zu verwenden, gibt es Azure Transliterate , das viele Sprachen abdeckt
Arabischen/hebräischen Text von rechts nach links anzeigen (falls das System dies nicht bereits unterstützt: https://packages.ubuntu.com/focal/libfribidi0
Arabische Buchstaben in Verbindungsformen umwandeln: Arabic Reshaper (Python-Paket)
Schriftart zur Anzeige aller Sprachen: Noto oder eine andere Google-Schriftart , die das von Ihnen benötigte Skript unterstützt.
Diese Bibliotheken sind nützlich, wenn Sie die Struktur eines Satzes analysieren, Verben in die Gegenwartsform umwandeln, Objekt und Subjekt eines Verbs finden usw. möchten.
Der altmodische Ansatz zur mehrsprachigen Verarbeitung natürlicher Sprache umfasste handcodierte Regeln, die auf die jeweiligen Sprachen zugeschnitten waren, während modernere Ansätze auf der Verwendung von Transformer-Neuralnetzen in der Lage sind, Texte in einer Vielzahl unterschiedlicher Sprachen nahtlos zu verarbeiten.
Die nahtlosen sprachagnostischen Ansätze erbringen jedoch häufig eine schlechtere Leistung, wenn sie in einer Sprache trainiert und in einer anderen getestet werden. Wenn also eine bestimmte Sprache Priorität hat (beispielsweise die Sprache eines Schlüsselmarkts für Ihr Unternehmen), ist es immer am besten, ein dediziertes Modell zur natürlichen Sprachverarbeitung für diese Sprache zu haben.
Weitere Informationen zu geschäftlichen Einsatzmöglichkeiten der Verarbeitung natürlicher Sprache finden Sie in unserem begleitenden Blogbeitrag .
Devlin, Jacob, et al. „ BERT: Vortraining tiefer bidirektionaler Transformatoren zum Sprachverständnis. “ arXiv-Vorabdruck arXiv:1810.04805 (2018).
Tsu, Jing. Kingdom of Characters: Eine Geschichte über Sprache, Obsession und Genie im modernen China . Penguin UK, 2022.
Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdecken
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you