
Bedeutet der Schutz sensibler Daten, dass Sie auch bei der Leistung Ihres Machine-Learning -Modells Kompromisse eingehen müssen?
Wenn Sie an einer Universität maschinelles Lernen studieren oder einen Onlinekurs belegen, arbeiten Sie normalerweise mit einer Reihe öffentlich verfügbarer Datensätze wie dem Titanic-Datensatz , dem Fisher- Iris-Blumen-Datensatz oder dem Labelled Faces in the Wild- Datensatz. Sie können beispielsweise ein Gesichtserkennungsmodell anhand einer Reihe von Prominentengesichtern trainieren, die bereits öffentlich zugänglich sind, anstatt anhand privater oder vertraulicher Daten wie Überwachungsbildern. Diese öffentlichen Datensätze gibt es oft schon sehr lange und sie dienen als nützliche Benchmarks, über die sich alle einig sind.
 models](https://fastdatascience.com/images/machine_learning_sensitive_data_titanic_dataset_table-min.png)
Der Titanic-Datensatz
Der Titanic-Datensatz ist ein bekannter Datensatz für maschinelles Lernen. Da die Titanic vor so langer Zeit gesunken ist, können wir sensible persönliche Daten über die Passagiere verwenden.
In einem kommerziellen Umfeld müssen wir Machine-Learning-Modelle jedoch häufig anhand privater oder vertraulicher Daten trainieren. Mit Ausnahme neuer Startups verfügen große Unternehmen möglicherweise über Datenbanken mit äußerst persönlichen Daten, wie beispielsweise Adressen, Sozialversicherungsnummern, Finanzinformationen, Krankengeschichten und mehr von Millionen von Personen. Unternehmen sind äußerst zurückhaltend, wenn es darum geht, Zugriff auf diese Art von Daten zu gewähren, wenn dies nicht unbedingt erforderlich ist. Dies stellt ein Problem für einen Datenwissenschaftler dar, der ein Modell anhand vertraulicher Informationen trainieren muss. Einige Machine-Learning-Projekte sind technisch gesehen einfach, werden jedoch durch Datenschutzverpflichtungen enorm kompliziert.
Lassen Sie mich ein Beispiel aus unserem eigenen Portfolio vorstellen. Wir haben kürzlich ein NLP- Modell für einen großen Kunden in Großbritannien entwickelt, der täglich Tausende von Kunden-E-Mails erhält. Der Kunde wollte ein E-Mail- Triage- System, damit Kunden mit einigen der häufigsten Anfragen (wie z. B. einer Änderung der Privatadresse) automatisch zu einem Webformular weitergeleitet werden können, das ihre Anfrage beantwortet. Der Plan bestand darin, die Arbeitsbelastung des Kundendienstpersonals zu verringern und seine Kapazitäten für nicht routinemäßige Anfragen freizugeben.
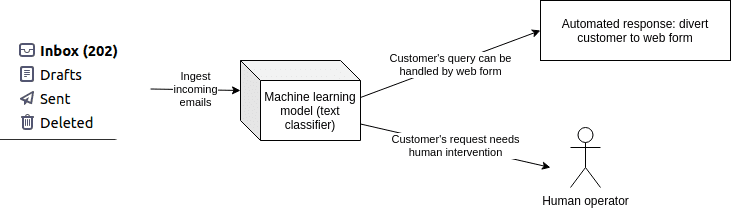
So funktioniert ein KI-basiertes E-Mail-Triage-System: Eingehende E-Mails werden nach Kundenabsicht klassifiziert und Kunden, die ihr Problem mit einem einfachen Webformular lösen können, werden an das richtige Formular weitergeleitet. Dies erfordert die Erkennung sensibler Daten und ist zwar technisch einfach zu erstellen, aber aufgrund der sensiblen Daten, die zum Trainieren des Modells benötigt werden, knifflig.
Auf den ersten Blick ist dieses Problem technisch recht einfach: Sie müssen eine Auswahl von E-Mails nehmen, diese manuell kommentieren und dann einen Textklassifizierer trainieren und bereitstellen. Aus Datenschutzgründen mussten wir jedoch Folgendes berücksichtigen:
Die Benutzer haben der Speicherung ihrer E-Mails nicht zugestimmt. Wenn ich einen Trainingsdatensatz manuell annotiere (ein zeitaufwändiger Prozess), kann ich ihn nicht unbegrenzt speichern. Er muss gelöscht werden.
Wenn ein Benutzer im Rahmen des in der DSGVO verankerten Rechts auf Vergessenwerden die Löschung aller seiner personenbezogenen Daten von der Organisation verlangen kann. Wenn ein Benutzer eine solche Anfrage stellt, wie kann ich dann alle Stellen aufspüren, an die die personenbezogenen Daten in der Pipeline des maschinellen Lernens gelangt sind? Es muss möglich sein, alle Kopien einer E-Mail in allen Datensätzen aufzuspüren.
Der Datensatz darf die Computersysteme des Kunden nicht verlassen. Ich kann keine Datei auf meinen Computer herunterladen und mit verschiedenen Modellen des maschinellen Lernens experimentieren. Die gesamte Modellentwicklung muss auf Servern stattfinden, die vom Kunden kontrolliert werden.
Können aus dem Modell sensible Daten reproduziert werden? Wenn beispielsweise die E-Mail-Adresse eines Kunden als Wort in seinem Vokabular in einem NLP- Modell gespeichert wurde, haben einige Kundendaten das Modell verunreinigt. Wir müssen sicherstellen, dass niemand sensible Informationen aus einem trainierten Modell rekonstruieren kann.
Die betroffene Person hat das Recht, von dem Verantwortlichen zu verlangen, dass sie betreffende personenbezogene Daten unverzüglich gelöscht werden.
Ein Risiko , das manchmal übersehen wird, besteht darin, dass ein maschinelles Lernmodell versehentlich sensible Teile seiner Trainingsdaten speichert. 2017 trainierte ein Team der Cornell University/Cornell Tech eine Reihe von Deep-Learning-Modellen zur Gesichtserkennung anhand von Prominentengesichtern. Anschließend konnten sie die ursprünglichen Gesichtsbilder aus dem neuronalen Netzwerk extrahieren, allerdings mit leicht schlechterer Qualität.
Mithilfe ihrer Technik könnte ein Angreifer, der Zugriff auf ein trainiertes maschinelles Lernmodell hat, das gelernt hat, sensible Daten zu erkennen und zu klassifizieren, möglicherweise einen Teil dieser Daten rekonstruieren. Ein maschinelles Lernmodell, das gelernt hat, Lebensläufe von Arbeitssuchenden zu klassifizieren, könnte beispielsweise Token gespeichert haben, die spezifisch auf die Namen der einzelnen Personen zugeschnitten sind, oder ungewöhnlich auf eine bestimmte Buchstabenkombination in einer Adresse reagieren, wodurch ein böswilliger Angreifer die Möglichkeit hätte, die Adresse abzuleiten, die in den Trainingsdaten enthalten war.
Es gibt eine Reihe von Strategien, die ein Datenwissenschaftler angesichts äußerst anspruchsvoller Datenschutzanforderungen verfolgen kann.

Während der Dauer des Projekts können annotierte Daten verwendet werden. Es darf nur eine Kopie des Datensatzes vorhanden sein. Sobald das maschinelle Lernmodell jedoch trainiert wurde, muss der Datenwissenschaftler den gesamten Datensatz löschen.
Das Löschen aller Ihrer Anmerkungen bedeutet, dass Sie die Form „wegwerfen“: Wenn das Projekt in Zukunft fortgesetzt werden soll, müssen Sie einen neuen Datensatz erneut annotieren. Wenn jedoch wirklich alle Daten gelöscht werden, besteht keine Möglichkeit, dass die Daten verloren gehen, und das „Recht auf Vergessenwerden“ ist kein Thema mehr.
Wir können versuchen, einen nicht sensiblen Datensatz zu erstellen. Beispielsweise verarbeiten wir alle E-Mails mit einem Datenanonymisierungsalgorithmus, um Namen, Adressen oder andere sensible Informationen zu entfernen. Das bedeutet, dass unser Datensatz zu einem bereinigten Satz von E-Mails wird, in dem keine personenbezogenen Informationen mehr enthalten sind.

Nachdem eine E-Mail anonymisiert und alle vertraulichen Daten entfernt wurden, reichen die verbleibenden Daten möglicherweise nicht aus, um ein genaues maschinelles Lernmodell zu trainieren.
Es gibt zahlreiche Produkte von Drittanbietern, mit denen Sie Texte anonymisieren können. Beispielsweise Anonymisation App oder Microsoft Azure Text Analytics .
Das Risiko bei diesem Ansatz besteht darin, dass die Anonymisierung von Texten schwierig und zeitaufwändig ist und die Möglichkeit besteht, dass versehentlich vertrauliche Informationen darin zurückbleiben. Darüber hinaus kann der anonymisierte Datensatz zu weit vom Original abweichen, um ein möglichst genaues Modell zu erstellen.
Das Positive daran ist, dass sich das Modell des maschinellen Lernens nichts merken kann, was es nicht sollte, wenn keine vertraulichen Daten in die Nähe des Modells gelangen. Außerdem ist es einem Angreifer nicht möglich, die vertraulichen Informationen durch Manipulation des Modells zu rekonstruieren. Dies erleichtert die Erkennung vertraulicher Daten.
Möglicherweise können Sie die Daten kommentieren und dann löschen, wobei nur ein Hash oder eine ID der Originalinformationen gespeichert wird, sodass die Trainingsdaten leicht rekonstruiert werden können, aber nicht in Ihrem maschinellen Lernsystem gespeichert werden. Sie können beispielsweise die ID und das Label jeder E-Mail speichern, sodass die Trainingsdaten neu erstellt werden können, sofern die E-Mails nicht vom E-Mail-Server gelöscht wurden. Dies bedeutet, dass das maschinelle Lernprojekt nicht auf zusätzliche Datenkopien angewiesen ist.
Wenn Sie Hashes von E-Mail-Adressen speichern, müssen Sie vorsichtig sein. Denn wenn ein Hacker Zugriff auf Ihre gehashte Datenbank und eine Datenbank mit E-Mail-Adressen eines anderen Unternehmens erhält, kann er alle diese E-Mail-Adressen hashen, sie mit Ihrer Datenbank abgleichen und so die ursprünglichen E-Mail-Adressen rekonstruieren .

So können E-Mails gehasht werden. Die E-Mail-Adresse jefod50602@yncyjs.com wird durch einen Hash-Algorithmus in die Zeichenfolge c379bd7a05f1af4522d5ad28af10d623 umgewandelt. Dies lässt sich nicht einfach rückgängig machen, aber ein Hacker, der an eine andere Liste von E-Mails gelangt (wie etwa beim Ashley Madison-Datendiebstahl ), könnte dieselbe Hash-Funktion auf diese Liste anwenden und die ursprüngliche E-Mail im Datensatz identifizieren.
Ein anderer Ansatz besteht darin, die Erlaubnis einzuholen, Kundendaten länger aufzubewahren und sie zum Trainieren einer KI zu verwenden. Dies ist möglicherweise nicht immer eine Option, aber wenn genügend Kunden zustimmen, können wir möglicherweise einen Trainingsdatensatz nur aus den zustimmenden Kunden erstellen. Wir müssen jedoch vorsichtig sein, da zustimmende Kunden möglicherweise nicht repräsentativ für die gesamte Kundenbasis sind (sie geben möglicherweise mehr aus, können besser buchstabieren, gehören einer anderen demografischen Gruppe an usw.), und dies könnte zu einer Verzerrung unseres trainierten Modells führen. Darüber hinaus würde diese Strategie normalerweise nur bei Neukunden funktionieren, aber ein Unternehmen möchte möglicherweise die gesamte bestehende Kundenbasis zum Trainieren seines maschinellen Lernmodells verwenden.
 left index fingerprint showing some minutiae](https://fastdatascience.com/images/Thomas-Wood-left-index-fingerprint-showing-some-minutiae-min.jpg)
Mein Fingerabdruck des linken Zeigefingers zeigt einige Minutien (Merkmale wie Kreuzungen oder Sackgassen). Die Minutienkoordinaten könnten dann gemäß einem Einwegprozess verschlüsselt oder transformiert werden, was maschinelles Lernen auf verschleierten Daten ermöglicht.
Manchmal ist es möglich, einen sensiblen Datensatz so zu verschleiern, dass die sensiblen Daten nicht rekonstruiert werden können, maschinelles Lernen aber trotzdem daraus lernen kann. Dies nennt man homomorphe Verschlüsselung . Ein biometrischer Fingerabdruckdatensatz könnte beispielsweise in einen Satz von Minutien (Merkmalspunkten) umgewandelt werden, die dann durch eine nicht umkehrbare Operation transformiert werden könnten. Die Operation hätte die Eigenschaft, dass Fingerabdrücke, die im wirklichen Leben ähnlich sind, nach der Verschlüsselung ähnlich bleiben, die Verschlüsselung aber trotzdem nicht rückgängig gemacht werden kann.
Homomorphe Verschlüsselung ist oft sehr schwierig durchzuführen. Eine einfache Möglichkeit, dasselbe Ergebnis zu erzielen, besteht darin, numerische Felder mithilfe der Hauptkomponentenanalyse zu transformieren. Ein transformierter Wert könnte beispielsweise 2 * Alter + 1,5 * Gehalt + 0,9 * Breitengrad sein, was aufgrund der Viele-zu-eins-Natur der Transformation sehr schwer auf eine Einzelperson zurückzuführen wäre.
Neben der Sicherstellung, dass keine Daten unnötig kopiert oder in Repositories eingecheckt werden, gibt es noch weitere routinemäßige Sicherheitsmaßnahmen, die bei sensiblen Trainingsdaten getroffen werden müssen. Beispielsweise müssen alle API-Endpunkte mit SSL und HTTPS gesichert werden, und Sie sollten keine Daten über Dienste von Drittanbietern wie Github oder Gmail teilen.
Möglicherweise stellen Sie fest, dass ein bestimmtes Feld, z. B. das Geburtsdatum, zwar hochsensibel ist, aber wenig zur Modellgenauigkeit beiträgt. In diesen Fällen muss zwischen Sicherheit und Leistung des maschinellen Lernmodells abgewogen werden, und möglicherweise wird eine geschäftliche Entscheidung getroffen, die Genauigkeit zu opfern, um eine gute Datenverwaltung aufrechtzuerhalten.
Daten können geändert oder vergröbert werden, sodass sie für maschinelles Lernen noch immer von Nutzen sind, das Potenzial zur Identifizierung sensibler Daten jedoch abnimmt. Beispielsweise können Längen- und Breitengrade gerundet oder mit Jitter versehen, Postleitzahlen (W9 3JP) auf die erste Hälfte (W9) reduziert und numerische Mengen in Bins eingeteilt werden. Die HIPAA-Verordnung der USA legt fest, dass Altersangaben unter bestimmten Umständen nur als Jahreszahlen und nicht als Datumsangaben gespeichert werden dürfen , es sei denn, das Alter liegt über 90 Jahren, in welchem Fall auch das Jahr ausgeblendet werden muss.

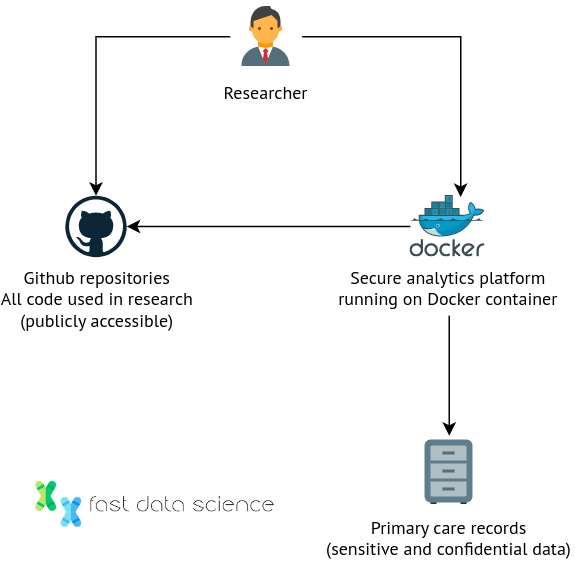
Es ist auch möglich, die sensiblen Daten in einem sicheren Archiv aufzubewahren, wo Forscher zwar nicht direkt darauf zugreifen können, aber Experimente und statistische Tests durchführen können. Der National Health Service ( NHS ) in England hat ein Pilotprogramm namens OpenSAFELY eingerichtet, das es Forschern ermöglicht, die Gesundheitsakten von 58 Millionen Menschen zu verwenden, ohne sie jemals zu sehen. Benutzer können Code schreiben und ihn auf der Plattform einreichen (herunterladbar als Github-Repository ), ohne jemals die Rohdaten sehen zu müssen. Alle Interaktionen mit den Daten werden protokolliert und genehmigte Projekte werden auf der Website von OpenSAFELY aufgeführt.
Wie funktioniert das in der Praxis? OpenSafely verwendet eine Reihe mehrstufiger Tabellen und Forscher haben keinen Zugriff, um einfache Datenbankabfragen auszuführen und die Rohdaten anzuzeigen. Die Architektur basiert auf einer sicheren Analyseplattform, auf der Code ausgeführt wird, der Code selbst jedoch von Forschern in öffentliche Github-Repositories übertragen wird.
OpenSAFELY verkörpert eine innovative Methode zur Erforschung sensibler Daten, die in den frühen Tagen der Pandemie aufkam. Dr. Ben Goldacre, Direktor des EBM Data Lab der Universität Oxford, beschrieb dies als eine Abkehr von Modellen, die auf Vertrauen basieren (Forschern wird vertraut, dass sie die Daten sicher aufbewahren), hin zu Modellen, die auf Beweisen basieren.
Ich war neugierig, ob ich mithilfe der Plattform von OpenSAFELY auch mit dem Textinhalt von Gesundheitsakten experimentieren könnte. Von den 151 Projekten, die auf der Website von OpenSAFELY aufgelistet sind, hat keines etwas mit Text zu tun (die meisten scheinen Studien mit strukturierteren Daten zu sein, wie etwa „Die Auswirkungen von COVID-19 auf Behandlungspfade und -ergebnisse während der Schwangerschaft“). Ich kontaktierte OpenSAFELY und fragte, ob es möglich sei, Experimente mit Textdaten durchzuführen, und sie antworteten, dass sie derzeit keine Textprojekte durchführen. Ich wäre gespannt, mir vorzustellen, wie das OpenSAFELY-Modell erweitert werden könnte, um Experimente mit Textdaten zu ermöglichen.
Eine recht drastische Möglichkeit zum Schutz sensibler Daten, die meines Wissens in der Gesundheits- und Medizintechnik eingesetzt wird, besteht darin, einen leeren Laptop zu nehmen, die gesamte Analysesoftware darauf zu installieren, die sensiblen Daten darauf zu übertragen und anschließend physisch sämtliche Internetverbindungen zu trennen. Jetzt können nur noch die Analyseergebnisse bzw. die Modelle des maschinellen Lernens den Laptop verlassen und der Laptop verlässt nicht die Räumlichkeiten der Einrichtung, beispielsweise eines Krankenhauses, in dem das Modell trainiert wird. Forscher verwenden diesen Ansatz manchmal bei der Entwicklung von Modellen für elektronische Gesundheitsakten (EHRs). Wenn es beispielsweise keine sichere Möglichkeit gibt, eine EHR zu anonymisieren, wenn sie im Klartext vorliegt, können wir den Ansatz der vertrauenswürdigen Ressourcenumgebung verwenden.
Wenn ein Datenwissenschaftler mit sensiblen Daten jeglicher Art arbeitet, wäre es ratsam , Rechtsberatung einzuholen oder den Datenschutzbeauftragten der Organisation (in Großbritannien/der EU) zu kontaktieren , um sich beraten zu lassen und eine Governance-Richtlinie und eine Dokumentation der besten Vorgehensweisen zu erstellen. Dazu gehört die Einrichtung eines sicheren Speicherorts, die Dokumentation aller Quellen sensibler Daten und aller angefertigten Kopien sowie die Einrichtung eines Prozesses zum Scannen nach sensiblen Daten. Gemäß der DSGVO müssen alle Kopien einer Dateninstanz nachverfolgt werden, damit die betroffene Person eine vollständige Löschung verlangen kann. Außerdem müssen Prozesse eingerichtet werden, die es Mitarbeitern ermöglichen, Zugriff auf Daten anzufordern, und die nachverfolgen, wer zu einem bestimmten Zeitpunkt Zugriff hat.
Der Umgang mit äußerst wertvollen, aber sensiblen Daten kann ein Minenfeld sein. Datenwissenschaftler müssen sehr vorsichtig sein, um die Datenschutzbedenken der Kunden nicht zu ignorieren, und müssen versuchen, den richtigen Mittelweg zwischen Kompromissen bei der Privatsphäre und Kompromissen bei der Modellleistung zu finden. Oft werden einige der kommerziell erfolgreichsten Modelle mit hochsensiblen Daten trainiert.
Google, Überlegungen zu sensiblen Daten in Machine-Learning-Datensätzen (2020)
Quintanilla et al., Was ist verantwortungsvolles maschinelles Lernen?, Microsoft (2021)
DSGVO, Recht auf Vergessenwerden , EU-Gesetz (2016)
Song et al., Maschinelle Lernmodelle, die sich zu viel merken , Cornell University (2017)
Die OpenSAFELY-Zusammenarbeit., Williamson, EJ, Tazare, J. et al. Vergleich von Methoden zur Vorhersage von COVID-19-bedingten Todesfällen in der Allgemeinbevölkerung mithilfe der OpenSAFELY-Plattform. Diagn Progn Res 6, 6 (2022). https://doi.org/10.1186/s41512-022-00120-2
Jo Best, Dieses Open-Source-Projekt verwendet Python, SQL und Docker, um Gesundheitsdaten zum Coronavirus zu verstehen , Zdnet (2020), abgerufen am 6. April 2023
Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdecken
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you