
Named Entity Recognition (NER) ist die Aufgabe, Eigennamen und Wörter einer speziellen Klasse in einem Dokument zu erkennen, wie etwa Produktnamen, Orte, Personen oder Krankheiten . Dies lässt sich mit der verwandten Aufgabe des Named Entity Linking vergleichen, bei dem die Produkte mit einer eindeutigen ID verknüpft werden.
Stellen Sie sich vor, Sie haben einen großen Textdatensatz in einem bestimmten Bereich erhalten und möchten im Text Firmen- oder Produktnamen identifizieren. Dies könnte nützlich sein, wenn Sie Trends wie negative Stimmungen gegenüber einem Produkt in einem bestimmten Kontext identifizieren müssen. Beispiel: „Es gibt einen wachsenden Trend negativer Stimmungen zum Thema iPhone.“
Ein Branchenbeispiel, in dem Sie NER benötigen könnten, ist die Pharmaindustrie, in der die Vertriebsmitarbeiter von Pharmaunternehmen riesige Mengen an Transkripten und Notizen von Besprechungen und Telefonaten mit medizinischem Fachpersonal erstellen. Pharmaunternehmen sind an Erkenntnissen wie „x % der Erwähnungen eines bestimmten Medikaments durch Ärzte sind mit einer bestimmten Nebenwirkung verbunden“ interessiert, die nur aus einer detaillierten Analyse von Tausenden von Textdokumenten gewonnen werden können.
Die erste Phase einer solchen Analyse wäre die Erkennung und Verknüpfung benannter Entitäten, wobei ein System die betreffenden Entitäten erkennt. Medikamente würden identifiziert und mit einer ID verknüpft, und Krankheiten sollten mit einem bestimmten Krankheitswörterbuch wie MeSH-Begriffen verknüpft werden.

Beispiel für ein System zur Erkennung benannter Entitäten, Produkterkennung oder Verknüpfung benannter Entitäten. Die Eingabe ist Rohtext und die Ausgabe ist eine Markierung aller relevanten Entitäten. Ein Named-Entity-Erkenner würde markieren, dass das 14. Token eine benannte Entität ist, und ein Named-Entity-Linker würde es auch mit einer ID in einer Datenbank abgleichen.
Es gibt eine Reihe von gebrauchsfertigen Bibliotheken zur Erkennung benannter Entitäten, wie SpaCy und die wissenschaftliche Domäne ScispaCy, die für die Erkennung benannter Entitäten verwendet werden können. Sie werden jedoch häufig übersteuert, da sie mit Texten aus mehreren Domänen trainiert werden, und das System kann unbrauchbar werden. CT ist beispielsweise sowohl ein medizinischer Begriff als auch der Bundesstaat Connecticut, und Texte, die Adressen enthalten, können viele falsche Positivergebnisse liefern.
Der Vorteil der Verwendung einer vorgefertigten Bibliothek liegt natürlich in der Benutzerfreundlichkeit. Sie können loslegen, ohne ein Modell trainieren zu müssen.
Viele Standardbibliotheken für die Erkennung benannter Entitäten, wie Microsoft Azure Cognitive Services Text Analytics oder AWS Comprehend Medical , sind Cloud-basiert. Dies kann eine Überlegung wert sein, wenn Ihre Daten sensibel und vertraulich sind, da Sie Daten regelmäßig über das Internet an die Server des Cloud-Anbieters senden müssen.
Je nach Anwendungsfall und Budget kann es für Sie lohnend sein, einen benutzerdefinierten Named Entity Recognizer zu erstellen.
In den letzten Jahren wurde viel über die Verwendung von Deep Learning für jedes KI-Problem gesagt und geschrieben, von der Verarbeitung natürlicher Sprache bis hin zur Computervision.
Für das oben genannte Beispiel aus der Pharmaindustrie würde ich mich allerdings gegen die vorherrschende Meinung stellen und Ihnen vorschlagen, eher einen wissensbasierten Ansatz als einen reinen Ansatz des maschinellen Lernens in Betracht zu ziehen.
Es ist relativ einfach, eine recht umfassende Liste mit gängigen Medikamentennamen, Abkürzungen und Markennamen zu erhalten. Beispielsweise verfügen sowohl Medlineplus als auch die FDA über aktuelle Listen, die Sie abrufen oder herunterladen können.
Fast Data Science - London

Eine sortierte Liste von Medikamentennamen, die in einem wörterbuchbasierten Ansatz zur Produkt- oder benannten Entitätserkennung verwendet werden könnte.
Sie können dies verwenden und mit einem Wörterbuch gebräuchlicher englischer Wörter abgleichen. Jeder Medikamentenname wie Minocyclin, der nicht mit dem englischen Wörterbuch übereinstimmt, kann als eindeutige Übereinstimmung in Ihr Wörterbuch eingetragen werden. Insbesondere Wörter oder Abkürzungen, die mit gebräuchlichen englischen Wörtern übereinstimmen, können als Übereinstimmung mit geringer Konfidenz in das Wörterbuch eingetragen werden.
Da auf viele Medikamente mit Abkürzungen verwiesen wird, können Sie den Wörterbuchansatz in Kombination mit einigen Regeln verwenden. Beispielsweise können Sie die letzten Buchstaben eines Medikamentennamens weglassen, wenn das Ergebnis eindeutig ist.
Ebenso können Sie eine vollständige Liste der MeSH-Begriffe aus der NIH Library of Medicine als XML-Datei herunterladen und die Begriffe entfernen, die mit dem englischen Wörterbuch übereinstimmen.
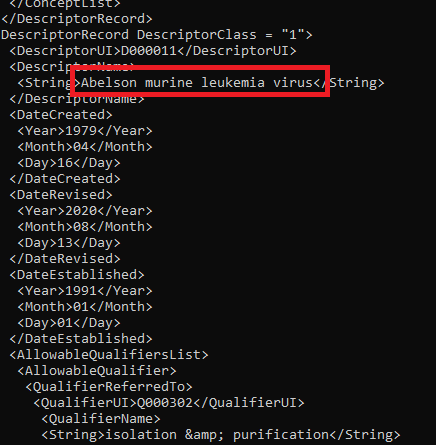
Screenshot der MeSH-Begriffsliste im XML-Format. Ein Krankheitsname ist hervorgehoben.
Der oben beschriebene wörterbuchbasierte Ansatz kann für Ihren Anwendungsfall eine Abdeckung von 95 % erreichen, und Sie müssen möglicherweise überhaupt kein maschinelles Lernen einsetzen!
Wir haben diesen Ansatz ausprobiert und eine wörterbuchbasierte Bibliothek zur Erkennung benannter Entitäten für Medikamente als Open Source auf Github bereitgestellt: https://github.com/fastdatascience/drug_named_entity_recognition . Sie kann von Pypi mit dem Befehl installiert werden
pip installieren Arzneimittel-Named-Entity-Erkennung
Ein besonders leistungsfähiger Ansatz zur Produkterkennung besteht darin, den oben aufgeführten wörterbuchbasierten Ansatz mit einem maschinellen Lernansatz zu kombinieren, um alle Elemente aufzuspüren, die nicht im Wörterbuch erfasst wurden (Rechtschreibfehler, Medikamente, die nicht in der Liste enthalten waren usw.).
Ich würde eine Reihe von Schritten empfehlen, die wie folgt in einer NLP-Pipeline kombiniert werden:
Teilen Sie den Eingabetext in Wörter und Leerzeichen auf (tokenisieren Sie ihn). Ich empfehle die Verwendung eines auf regulären Ausdrücken basierenden Tokenisierers, der an Wortgrenzen aufteilt.
Wenden Sie den Wörterbucherkenner auf alle Wörter an und markieren Sie Wörter im Wörterbuch als Entitäten.
(Optional) Wenden Sie die Wortartmarkierung an (markieren Sie jedes Wort als Substantiv, Verb oder Adjektiv).
Identifizieren Sie eine Reihe von Merkmalen jedes Wortes, z. B. „ist komplett groß geschrieben“, „mit Komma davor“ usw.
Markieren Sie einige dieser Wörter auf der Grundlage eines Entscheidungsbaums oder eines trainierten maschinellen Lernmodells oder sogar einiger handcodierter Regeln als Entitäten mit geringer Vertrauenswürdigkeit. Beispielsweise kann in der Eingabe ein Wort vorkommen, das aufgrund seines umgebenden Kontexts höchstwahrscheinlich ein Medikamentenname ist („Ich verschreibe meinen Patienten routinemäßig X“), aber nicht im Wörterbuch steht. Es könnte sich um einen Rechtschreibfehler, eine unbekannte Abkürzung oder ein neues Medikament handeln. In diesen Fällen sollte das Modell es erkennen und den Benutzer darauf aufmerksam machen.
Ein Standardansatz für das Problem der Bezeichnung von Entitäten ist die Verwendung einer Notation namens IOB (Inside-Outside-Beginning). Dabei wird jedes Token als Inside, Outside oder Beginning markiert. Stellen wir uns also vor, wir verarbeiten den Satz:
…Behandlung mit Dihydroartemisinin-Piperaquin und Primaquin zur Abtötung von Malariaparasiten.
dann würden wir Token mit B-DRUG (Anfang eines Medikamentennamens), I-DRUG (innerhalb eines Medikamentennamens) usw. markieren.
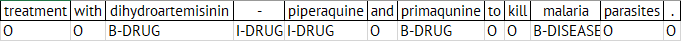
Dann können Sie entweder fest codierte Regeln einrichten (eine Behandlung mit“ geht wahrscheinlich B-DRUG voraus) oder ein maschinelles Lernmodell kann einige Regeln erlernen, die auf unbekannte Texte angewendet werden.
Einer der am häufigsten verwendeten Algorithmen zur Erkennung benannter Entitäten, der die IOB-Notation verwendet, sind Conditional Random Fields (CRFs). Weitere Informationen zu CRFs und zum Trainieren eines Modells zur Erkennung benannter Entitäten auf diese Weise finden Sie auf der Scikit-Learn-Website, auf der ein Tutorial verfügbar ist.
Der Vorteil des regelbasierten Ansatzes oder auch einiger der einfacheren Ansätze auf Basis maschinellen Lernens besteht darin, dass sie für Menschen relativ leicht verständlich sind. Insbesondere kann ein auf Wissen basierendes Wörterbuch bei Bedarf von nichttechnischem Personal bearbeitet werden, sodass das Management nachvollziehen kann, warum bestimmte Wörter markiert oder übersehen wurden.
Manchmal kann durch den Einsatz hochmoderner Deep-Learning-Modelle eine höhere Leistung erzielt werden.
Screenshot der ScispaCy-Ausgabe für einen Satz im biomedizinischen Bereich.
Es gibt eine Reihe ausgefeilterer Modelle zur Erkennung benannter Entitäten. Ein häufig verwendetes Paket in Python ist spaCy , das ein tiefes Convolutional Neural Network verwendet, um Entitäten, normalerweise Personen, Organisationen und Orte, zu erkennen. Ein wissenschaftlich trainiertes Modell namens ScispaCy ist ebenfalls verfügbar.
Modelle wie CRFs sind darauf beschränkt, kleine Textfenster um eine Kandidatenentität herum zu betrachten, und Faltungsnetzwerke iterieren ebenfalls ein Fenster über das Dokument. Etwas leistungsstärkere Modelle sind Long Short Term Memory (LSTM), das den gesamten vorhergehenden Kontext eines Dokuments berücksichtigen kann.
Der aktuelle Stand der Technik ist die Familie der transformerbasierten neuronalen Netzwerke wie BERT , die über einen „Aufmerksamkeitsmechanismus“ die Aufmerksamkeit auf bestimmte Wörter im Satz lenken, die für das jeweilige Wort besonders relevant sind.
Die Deep-Learning-Techniken zur Erkennung benannter Entitäten erfordern große Rechenleistung, sodass Sie möglicherweise einen Cloud-Anbieter wie Azure , AWS oder Google Cloud Services verwenden müssen und außerdem viele getaggte Daten benötigen. Wenn Sie also beispielsweise eine große Liste von Medikamenten oder Molekülen als XML-Datei haben, die Sie auswählen möchten, sind Sie in den meisten Fällen mit einem wörterbuchbasierten Ansatz besser bedient, als sich gleich in Deep Learning zu stürzen.
Für viele Kunden oder Entwickler ist dies möglicherweise eine Entweder-oder-Frage: Nutzen wir reine Wissenstechnik oder entscheiden wir uns für das modernste Deep-Learning-Modell für unsere Produkterkennungsaufgabe?
Tatsächlich eignen sich viele NLP-Probleme für einen hybriden Ansatz, bei dem unabhängige Modelle zusammengefügt werden können, um das Beste aus beiden Welten zu nutzen.
Warum nicht einen Wörterbuchansatz für eindeutige Medikamentennamen, Produktnamen oder Standorte mit hoher Zuverlässigkeit verwenden, kombiniert mit einem probabilistischen Ansatz auf Basis maschinellen Lernens für potenzielle Mehrdeutigkeiten?
Wir empfehlen dies unseren Kunden häufig und stellen fest, dass es in der Praxis sehr gut funktioniert.
Die Wahl eines Algorithmus zur Erkennung benannter Entitäten hängt daher ab von
ob eine Named-Entity-Erkennung oder ein vollständiges Named-Entity-Verknüpfungssystem erforderlich ist,
die Verfügbarkeit einer Liste von Entitäten,
die Verfügbarkeit eines getaggten Textdatensatzes,
das Bedürfnis der Wirtschaft nach einem transparenten und nachvollziehbaren Algorithmus – oder kommen wir mit einem Black-Box-Algorithmus durch?
das Bedürfnis nach Privatsphäre (können Cloud-Dienste genutzt werden),
Ist die Anzahl der Varianten jeder Entität bekannt? Kommt es bei Entitäten wahrscheinlich zu Rechtschreibfehlern?
die relativen Kosten der vom Erkenner zurückgegebenen falsch positiven und falsch negativen Ergebnisse.
Wenn Sie einen großen Datensatz von Produkten, Medikamenten, Molekülen oder Ähnlichem erkennen müssen, wenden Sie sich bitte an unser Team bei Fast Data Science. Wir verfügen über eine nachweisliche Erfolgsbilanz bei der Bereitstellung von Lösungen zur Erkennung benannter Entitäten und können Ihnen dabei helfen, zu entscheiden, welcher der oben genannten Ansätze für Ihr Unternehmen der richtige ist, um Produktnamen in Dokumenten zu erkennen.
Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdecken
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you