
Natural Language Processing ( NLP ) ist die Wissenschaft, die Computer dazu bringt, in menschlicher Sprache zu sprechen oder mit Menschen zu interagieren. Beispiele für Natural Language Processing sind Spracherkennung, Rechtschreibprüfung, Autovervollständigung, Chatbots und Suchmaschinen.
Die Verarbeitung natürlicher Sprache gibt es schon seit Jahren, wird aber oft als selbstverständlich angesehen. Hier sind acht Anwendungsbeispiele für die Verarbeitung natürlicher Sprache , die Sie vielleicht noch nicht kennen. Wenn Sie über eine große Menge an Textdaten verfügen, zögern Sie nicht, einen NLP-Berater wie Fast Data Science zu engagieren.
Wenn Unternehmen über große Mengen an Textdokumenten verfügen (denken Sie an die Fallbelastung einer Anwaltskanzlei oder an behördliche Dokumente eines Pharmaunternehmens), kann es schwierig sein, daraus Erkenntnisse zu gewinnen.
Beispielsweise möchte der Manager einer Pharmafirma wissen, wie viele von den Tausenden von klinischen Studien sein Unternehmen durchgeführt hat und wie viele davon eine bestimmte Nebenwirkung hervorgerufen haben. Allerdings sind diese Informationen in einem Stapel von Dokumenten gespeichert und niemand hat die Zeit, sie alle zu lesen.
Die Verarbeitung natürlicher Sprache bietet uns eine Reihe von Tools zur Automatisierung dieser Art von Aufgaben.
Mit herkömmlichen Business Intelligence (BI)-Tools wie Power BI und Tableau können Analysten Erkenntnisse aus strukturierten Datenbanken gewinnen. So können sie beispielsweise auf einen Blick erkennen, welches Team in einem bestimmten Quartal den höchsten Umsatz erzielt hat. Viele der in Unternehmen kursierenden Daten liegen jedoch in einem unstrukturierten Format wie PDF-Dokumenten vor, und hier kann Power BI nicht so einfach helfen.
Ein Experte für natürliche Sprachverarbeitung kann Muster in unstrukturierten Daten erkennen. So kann beispielsweise die Themenmodellierung (Clustering) verwendet werden, um Schlüsselthemen in einem Dokumentsatz zu finden, und die Erkennung benannter Entitäten kann Produktnamen, Personennamen oder Schlüsselorte identifizieren. Die Dokumentenklassifizierung kann verwendet werden, um Dokumente automatisch in Kategorien einzuteilen.
Die Verarbeitung natürlicher Sprache kann für die Themenmodellierung verwendet werden, bei der ein Korpus unstrukturierten Textes in eine Reihe von Themen umgewandelt werden kann. Zu den wichtigsten Algorithmen für die Themenmodellierung gehören K-Means und Latent Dirichlet Allocation . Weitere Informationen zu K-Means und Latent Dirichlet Allocation finden Sie in meiner Übersicht über die 26 wichtigsten Konzepte der Datenwissenschaft .
Ich arbeite häufig mit einer Open-Source- Bibliothek wie Apache Tika , die PDF-Dokumente in Klartext umwandeln und dann Modelle zur Verarbeitung natürlicher Sprache anhand des Klartexts trainieren kann. Doch selbst nach der PDF-zu-Text-Konvertierung ist der Text oft unübersichtlich, Seitenzahlen und Überschriften sind in das Dokument eingearbeitet und Formatierungsinformationen gehen verloren.
Rechtschreib- und Grammatikprüfungen sind heute alltäglich und helfen uns, Webformulare richtig auszufüllen und Tippfehler zu vermeiden. Tatsächlich stelle ich fest, dass die Rechtschreibprüfung beim Tippen auf einem Handy-Bildschirm wahrscheinlich die meisten Wörter korrigiert!
Man könnte meinen, dass das Schreiben eines Rechtschreibprüfprogramms so einfach ist wie das Zusammenstellen einer Liste aller zulässigen Wörter in einer Sprache, aber das Problem ist viel komplexer. Wie kann ein solches System zwischen their , there und they’re unterscheiden? Heutzutage verwenden die ausgefeilteren Rechtschreibprüfprogramme neuronale Netzwerke, um zu prüfen, ob das richtige Homonym verwendet wird. Außerdem kann die Rechtschreibprüfung bei Sprachen mit komplizierteren Morphologien als Englisch sehr rechenintensiv werden.
Ein Beispiel für ein nicht englischspezifisches Problem bei der Verarbeitung natürlicher Sprache ist die Kompositazerlegung , also die Aufteilung zusammengesetzter Wörter in ihre Bestandteile. Manchmal gibt es mehrere gültige Aufteilungen, obwohl nur eine für einen menschlichen Leser Sinn ergibt. Open-Source-Software wie LibreOffice kann diese Aufgabe mithilfe der Bibliothek Hunspell ausführen, die ursprünglich für Ungarisch entwickelt wurde, eine Sprache mit einer sehr komplexen Morphologie.
In letzter Zeit gab es viel Hype um Transformer -Modelle, die die neueste Generation neuronaler Netzwerke darstellen. Transformer können die Grammatik natürlicher Sprache auf äußerst tiefe und anspruchsvolle Weise darstellen und haben die Leistung von Dokumentenklassifizierungs-, Textgenerierungs- und Frage-Antwort-Systemen verbessert. Die bekanntesten dieser Tools sind BERT , GPT-2 und GPT-3 .
Fast Data Science - London
Der einfachste Weg, mit BERT zu beginnen, ist die Installation einer Bibliothek namens Hugging Face . Unten sehen Sie mein Experiment zum Abrufen der Fakten des Falls Donoghue v. Stevenson („Schnecke in der Flasche“), einer bahnbrechenden Entscheidung im englischen Deliktsrecht, die den Grundstein für die moderne Fahrlässigkeitsdoktrin legte. Sie sehen, dass BERT die Fakten recht einfach abrufen konnte ( Am 26. August 1928 trank der Berufungskläger eine Flasche Ingwerbier, das vom Berufungsbeklagten hergestellt worden war… ). Obwohl es beeindruckend ist, beschränkt sich die Komplexität von BERT derzeit auf das Auffinden der relevanten Textpassage.
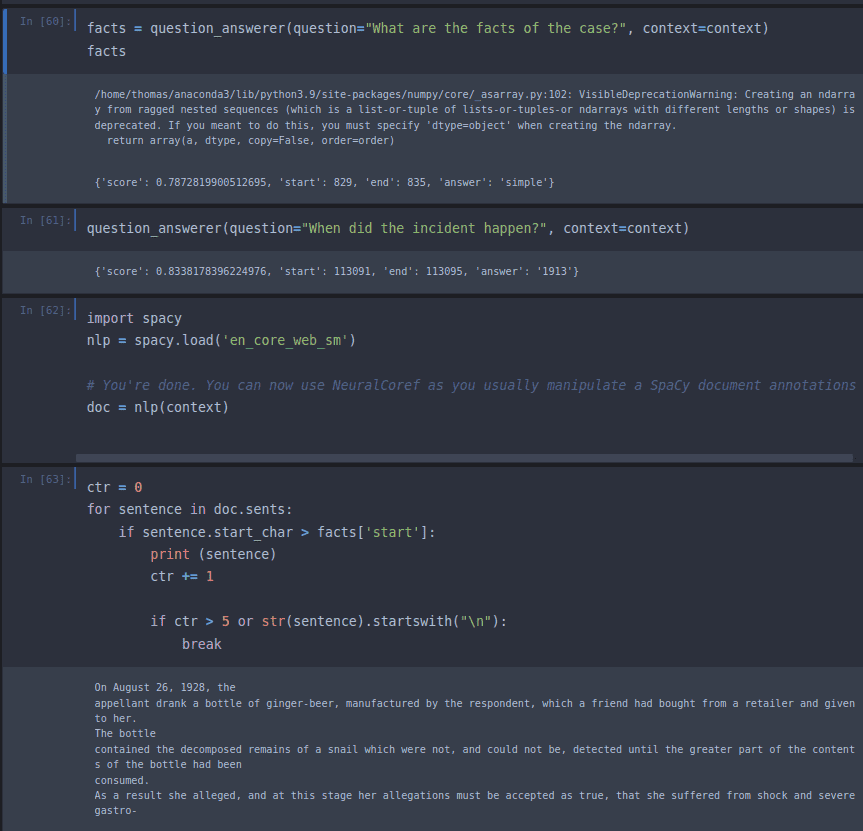
Ein Problem, auf das ich immer wieder stoße, ist die Anwendung von Algorithmen zur Verarbeitung natürlicher Sprache auf Dokumentenkorpora oder Listen mit Umfrageantworten, die eine Mischung aus amerikanischer und britischer Schreibweise aufweisen oder voller häufiger Rechtschreibfehler sind. Eine der ärgerlichen Folgen einer fehlenden Normalisierung der Rechtschreibung ist, dass Wörter wie normalising/normalizing nicht als häufig vorkommende Wörter erkannt werden, wenn sie in verschiedene Varianten aufgeteilt sind. Aus diesem Grund müssen wir häufig Tools zur Normalisierung von Rechtschreibung und Grammatik verwenden.
Nachdem dieses Problem in so vielen meiner Projekte auftrat, schrieb ich mein eigenes Python- Paket namens „localpelling“ , mit dem ein Benutzer den gesamten Text in einem Dokument ins Britische oder Amerikanische konvertieren oder erkennen kann, welche Variante im Dokument verwendet wird.
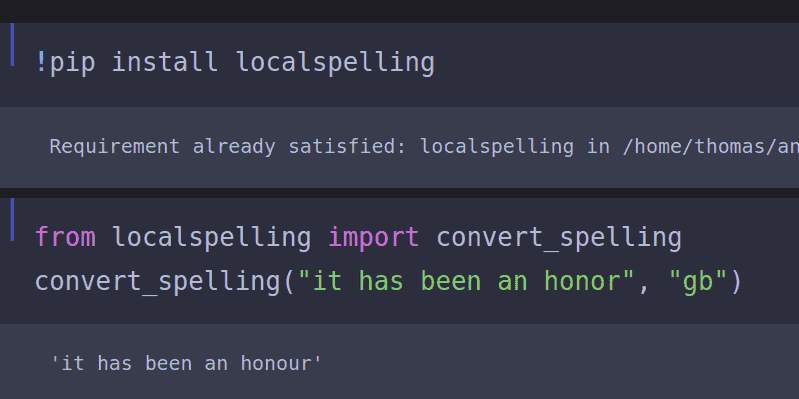
Obwohl die Normalisierung der Rechtschreibung unwichtig erscheinen mag, berichtete die BBC im Jahr 2022, dass Rechtschreibfehler Großbritannien Millionen Pfund an entgangenen Einnahmen kosten und dass ein einziger Rechtschreibfehler auf einer Website die Conversion-Rate halbieren kann. Unglaublich!
Bei einem Text in einer unbekannten Sprache ist es für die natürliche Sprachverarbeitung überraschend einfach, die Sprache zu identifizieren. Es gibt zwei Hauptansätze zur Sprachidentifizierung:
Ein NLP- System kann in einem Text nach Stoppwörtern (kleinen Funktionswörtern wie „the“ , „ at “, „in “) suchen und diese mit einer Liste bekannter Stoppwörter für viele Sprachen vergleichen. Die Sprache mit den meisten Stoppwörtern im unbekannten Text wird als Sprache identifiziert. Ein Dokument mit vielen Vorkommen von „le“ und „la“ ist also wahrscheinlich Französisch.
Eine etwas ausgefeiltere Technik zur Sprachenerkennung besteht darin, eine Liste von N-Grammen zusammenzustellen. Dabei handelt es sich um Zeichenfolgen, die in jeder Sprache eine charakteristische Häufigkeit aufweisen. Die Kombination „ch“ ist beispielsweise im Englischen, Niederländischen, Spanischen, Deutschen, Französischen und anderen Sprachen üblich.
Aber die Kombination „sch“ ist nur im Deutschen und Niederländischen üblich, und „eau“ ist als Dreibuchstabenfolge im Französischen üblich. Auch wenn ostasiatische Schriften für das ungeübte Auge ähnlich aussehen mögen, ist das häufigste Zeichen im Japanischen の und das häufigste Zeichen im Chinesischen 的, beide entsprechen dem englischen Suffix „s“ .
Durch Zählen der Ein-, Zwei- und Dreibuchstabenfolgen in einem Text (Unigramme, Bigrame und Trigramme) kann eine Sprache anhand einer kurzen Abfolge von nur wenigen Sätzen identifiziert werden.
Als Erweiterung des oben genannten Problems erscheint manchmal ein Text mit einem unbekannten Autor und wir möchten wissen, wer ihn geschrieben hat.
Beispiele hierfür sind Romane, die unter einem Pseudonym geschrieben wurden, etwa die Krimiserie von J. K. Rowling, die unter dem Pseudonym Robert Galbraith entstand, oder die der italienischen Autorin Elena Ferrante, die unter einem Pseudonym schrieb. In der Politik haben wir den anonymen Leitartikel „ Ich bin Teil des Widerstands innerhalb der Trump-Administration“ in der New York Times, der eine Hexenjagd auf seinen Autor auslöste, und die offene Frage, wer Dominic Cummings‘ Rosengarten-Erklärung verfasst hat .
Der hervorragende Linguistik-YouTuber Joshua R hat eine qualitative Analyse einer französischen Botschaft durchgeführt, die von einem der Bataclan-Terroristen im Jahr 2015 geschrieben wurde . Dabei hat er wichtige demografische Informationen über den Autor ermittelt (Bildungsniveau, kulturelle Erziehung usw.).
Die Wissenschaft der Autorschaftsbestimmung anhand unbekannter Texte nennt sich forensische Stilometrie . Jeder Autor besitzt einen charakteristischen Fingerabdruck seines Schreibstils – selbst wenn es sich um Textverarbeitungsdokumente handelt und keine Handschrift vorliegt.
Weitere Informationen zur forensischen Stilometrie finden Sie in meinem früheren Blogbeitrag zu diesem Thema . Auf der Site können Sie außerdem eine Live-Demo eines Autorenidentifizierungssystems ausprobieren.
Obwohl die forensische Stilometrie als qualitative Disziplin betrachtet werden kann und von Akademikern in den Geisteswissenschaften bei Problemen wie unbekannten lateinischen oder griechischen Texten eingesetzt wird, ist sie auch ein interessantes Anwendungsbeispiel für die Verarbeitung natürlicher Sprache.
Die Zeiten, in denen maschinelle Übersetzungssysteme dafür berüchtigt waren, Texte wie „Der Geist ist willig, aber das Fleisch ist schwach“ in „Der Wodka ist gut, aber das Fleisch ist verdorben“ zu verwandeln, sind vorbei. ( Der Economist teilt mir allerdings mit, dass diese Geschichte nicht stimmt.)
Heute deckt Google Translate eine erstaunliche Anzahl von Sprachen ab und verarbeitet die meisten davon mit statistischen Modellen, die auf riesigen Textkorpora trainiert wurden, die möglicherweise nicht einmal im jeweiligen Sprachenpaar verfügbar sind. Transformer-Modelle haben es Technologiegiganten ermöglicht, Übersetzungssysteme zu entwickeln, die ausschließlich auf einsprachigen Text trainiert wurden.
Im Jahr 2022 kündigte der Mischkonzern Meta, dem Facebook gehört, die Entwicklung eines einzigen KI-Modells an, das in der Lage ist, in 200 verschiedene Sprachen zu übersetzen. Dadurch wird der Zugang zur natürlichen Sprachverarbeitung für weniger gesprochene Sprachen wie Twi (Ghana) demokratisiert, die bisher von NLP- Tools nicht unterstützt wurden.
Der einsprachige Ansatz ist zudem viel skalierbarer, da Facebooks Modelle genauso einfach von Thailändisch nach Laotisch oder von Nepalesisch nach Assamesisch übersetzen können wie zwischen diesen Sprachen und Englisch. Mit der steigenden Zahl unterstützter Sprachen würde die Zahl der Sprachpaare unüberschaubar werden, wenn jedes Sprachpaar neu entwickelt und gepflegt werden müsste. Frühere Iterationen maschineller Übersetzungsmodelle zeigten tendenziell eine schlechtere Leistung, wenn sie nicht ins oder aus dem Englischen übersetzten.
Es bleibt jedoch noch viel zu tun, um die Abdeckung aller Weltsprachen zu verbessern. Facebook schätzt, dass derzeit mehr als 20 % der Weltbevölkerung noch nicht durch kommerzielle Übersetzungstechnologie abgedeckt sind. Generell ist die Abdeckung für die wichtigsten Weltsprachen sehr gut, mit einigen Ausreißern (insbesondere Yue- und Wu-Chinesisch, auch Kantonesisch und Shanghai-Chinesisch genannt).
Top 91 Sprachen mit Google Translate-Abdeckung. Datenquelle: Ethnologue (2022, 25. Ausgabe), Google Translate-Homepage.
Bei vielen der nicht unterstützten Sprachen handelt es sich um Sprachen mit vielen Sprechern, aber keinem offiziellen Status, wie etwa die zahlreichen gesprochenen Varianten des Arabischen.
Interessanterweise wurde die Bibel in über 6.000 Sprachen übersetzt und ist oft das erste Buch, das in einer neuen Sprache veröffentlicht wird.
Die Sentimentanalyse ist ein Beispiel dafür, wie die Verarbeitung natürlicher Sprache verwendet werden kann, um den subjektiven Inhalt eines Textes zu identifizieren. Dies ist natürlich sehr nützlich für Unternehmen, die den Social-Media-Verkehr in Bezug auf ihre Marken und Konkurrenzmarken oder wichtige Themen überwachen möchten, und auch um die Stimmung des Dialogs zwischen Benutzern und Chatbots oder Kundendienstmitarbeitern zu überwachen. Die Sentimentanalyse wird im Finanzwesen verwendet, um aufkommende Trends zu identifizieren, die auf profitable Geschäfte hinweisen können.
Weitere Beispiele für die Anwendung dieses Bereichs der natürlichen Sprachverarbeitung in Ihrem Unternehmen finden Sie in meinem Blogbeitrag zu Trends in der Stimmungsanalyse. Dieser enthält eine interaktive Demo eines Stimmungsanalysetools und zeigt die Entwicklung der Stimmungsanalysetechnologie von den 1970er-Jahren bis heute.
Die Verarbeitung natürlicher Sprache kann ein Unternehmen schnell verändern. Unternehmen in Branchen wie Pharmazie , Recht , Versicherungen und wissenschaftlicher Forschung können die riesigen Datenmengen, die sie in Silos gespeichert haben, nutzen, um die Konkurrenz zu überholen.
Die Verarbeitung natürlicher Sprache kann in Form von Chatbots und Systemen zur Priorisierung eingehender Verkaufsanfragen und Kundensupportanfragen zur Verbesserung des Kundenerlebnisses eingesetzt werden.
Weitere Beispiele, wie Sie die Verarbeitung natürlicher Sprache zur Steigerung der Effizienz und Rentabilität Ihres Unternehmens nutzen können , erhalten Sie von Fast Data Science .
SIL International, Ethnologue: Sprachen der Welt (2022, 25. Ausgabe)
The Economist, Eine Gabe der Zungen (2009)
Entfesseln Sie das Potenzial Ihrer NLP-Projekte mit dem richtigen Talent. Veröffentlichen Sie Ihre Stelle bei uns und ziehen Sie Kandidaten an, die genauso leidenschaftlich über natürliche Sprachverarbeitung sind.
NLP-Experten einstellen
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you
{kind=link}