
Wir werden oft gefragt, welche Art von Beratung wir bei Fast Data Science leisten. Wenn wir NLP sagen, lautet die nächste Frage normalerweise: „Was ist NLP?“, und wir müssen etwas genauer erklären, wofür NLP steht und was es bedeutet.
NLP steht für Natural Language Processing (Verarbeitung natürlicher Sprache)… aber nach 12 Jahren in diesem Bereich hat Google nichts aus meinem Suchverlauf gelernt. Screenshot von Google.
Die kurze Antwort lautet: NLP steht für Natural Language Processing (Verarbeitung natürlicher Sprache) . Das „Natural“ in Natural Language Processing bezieht sich auf menschliche Sprachen wie Englisch, im Gegensatz zu Programmiersprachen. „Processing“ bezieht sich darauf, was wir damit machen: Wir versuchen, Computer dazu zu bringen, menschliche Sprachen zu verstehen. Kurz gesagt bedeutet NLP Computerprogramme, die Sprache oder Text verstehen oder generieren. NLP ist ein Teilgebiet der künstlichen Intelligenz und verwendet regelmäßig Techniken des maschinellen Lernens.
Hier sind einige gängige Anwendungen von NLP in unserem normalen Leben:
Predictive Text ist ein NLP-Modell, das das wahrscheinlichste nächste Wort in Ihrem Satz vorhersagen kann. Es ist ein „Sprachmodell“, das ein allgemeines englisches Sprachmodell, das anhand der SMS-Verläufe vieler Benutzer trainiert wurde, mit personalisierten Mustern kombiniert, die es aus Ihrem eigenen Tippverlauf auf Ihrem Telefon gelernt hat.
Für ostasiatische Sprachen wie Chinesisch sind NLP-Algorithmen wie die Texterkennung für die effektive Nutzung eines Mobiltelefons unerlässlich. Bei einer der in China am häufigsten verwendeten Eingabemethoden gibt ein Benutzer Wörter in Pinyin (der phonetischen Darstellung) ein, und das Sprachmodell kann angesichts des Kontexts des restlichen Satzes das wahrscheinlichste Zeichen für diese Aussprache auswählen.
Demonstration des standardmäßigen Textvorhersagealgorithmus in Englisch und Chinesisch auf dem Samsung Galaxy S7.
Rechtschreibprüfungen sind Anwendungen, die Rechtschreibung und Grammatik prüfen, orthographische, stilistische und grammatikalische Fehler finden und hilfreiche Vorschläge zu deren Behebung liefern. Ich habe diesen Artikel beispielsweise mithilfe des Browser-Plug-ins Grammarly geschrieben, das NLP verwendet, um Ihren Schreibstil zu verbessern.
Screenshot der NLP-Software Grammarly, die meine Grammatik korrigiert, während ich diesen Artikel schrieb.

Screenshot des Dialogübersetzungsmodus des Samsung Galaxy S7, der ein gesprochenes Gespräch zwischen zwei Personen interpretiert.
Die maschinelle Übersetzung ist eine der bekanntesten Anwendungen der NLP. Die traditionelle maschinelle Übersetzung erfolgte mit regelbasierten Techniken, bei denen NLP-Forscher versuchten, die gesamte Grammatik der Ausgangs- und Zielsprache manuell in ihre Computerprogramme zu kodieren, als würden sie ein Grammatikbuch schreiben. Die regelbasierten Techniken scheiterten kläglich.
Es gibt eine bekannte, aber vermutlich apokryphe Geschichte über ein maschinelles Übersetzungssystem aus der Zeit des Kalten Krieges, das die Aussage „Der Geist war willig, aber das Fleisch war schwach“ ins Russische und zurück ins Englische übersetzte, sodass es „der Wodka war gut, aber das Fleisch war verdorben“ hieß.
Natürlich hat heutzutage fast jeder ein viel leistungsfähigeres Übersetzungstool in der Tasche … obwohl das eigentlich eine Illusion ist, da die Übersetzung selbst auf Ihrem Mobiltelefon wahrscheinlich auf den Servern von Google und nicht auf dem Gerät selbst stattfindet.
Virtuelle Assistenten oder Chatbots wie Alexa und Siri gehören zu einer Untergruppe der NLP, die als natürliche Sprachdialogsysteme bezeichnet wird. Sie ermöglichen es einem Benutzer, ein Mobilgerät, ein Auto, ein Soundsystem, einen intelligenten Kühlschrank oder Ähnliches per Sprachbefehl zu steuern, und sind in der Lage, innerhalb der engen Bereiche, für die sie entwickelt wurden, einen rudimentären Dialog mit einem Menschen zu führen.
Wir alle haben irgendwann einmal versucht, die Grenzen eines Chatbots auszutesten. Glücklicherweise sind Menschen genauso berechenbar wie Roboter. Als ich einige Jahre an der Entwicklung virtueller Unternehmensassistenten arbeitete, stellten wir fest, dass die häufigsten Fragen, die die Leute an die Bots stellten, waren: „Was trägst du gerade?“, „Hast du einen Freund?“ und so weiter. Es war ziemlich einfach, die Bots so zu programmieren, dass sie auf diese Eingaben eine witzige Antwort hatten.
Google und Bing führen NLP-Algorithmen sowohl für Ihre Suchanfragen als auch für die von ihnen gecrawlten Dokumente aus, um beides miteinander abzugleichen und die besten Dokumente zu ermitteln, die für die Abfrage eines bestimmten Benutzers zurückgegeben werden sollen.
In allen Bereichen, in denen große Textmengen an der Tagesordnung sind, kann NLP wahrscheinlich einen Mehrwert liefern. Einige der häufigsten Anwendungen sind:
Es ist ein häufiger Anwendungsfall, eingehende Dokumente in verschiedene Gruppen zu klassifizieren. Ein Standardproblem der NLP sind Dokumentklassifizierungssysteme, und im Laufe der Jahre wurden viele Algorithmen entwickelt, um dieses Problem zu lösen. Klassische Beispiele sind:
Es ist oft hilfreich zu wissen, ob ein Satz positive oder negative Emotionen enthält. Viele Unternehmen nutzen diese Technologie, um soziale Medien zu überwachen und schnell auf negative Erwähnungen ihres Produkts zu reagieren. Wenn beispielsweise ein Mobiltelefon zum Überhitzen neigt oder ein Elektroauto dazu neigt, zu stark zu beschleunigen, können Verbraucher ihrem Ärger auf Twitter Luft machen, bevor sie versuchen, das Unternehmen über seine offiziellen Kanäle zu kontaktieren.
Sentimentanalyse ist ein Bereich der NLP, in dem Texte automatisch auf emotionalen Inhalt analysiert werden. Manchmal werden die Gefühle auf die Ebene aller in einem Text erwähnten Entitäten (Unternehmen, Orte, Personen) heruntergebrochen. Sentimentanalyse ist nicht trivial zu lösen, da Sarkasmus, komplexe Satzkonstruktionen und Ton verwendet werden, die für Computer schwer zu verarbeiten sind.
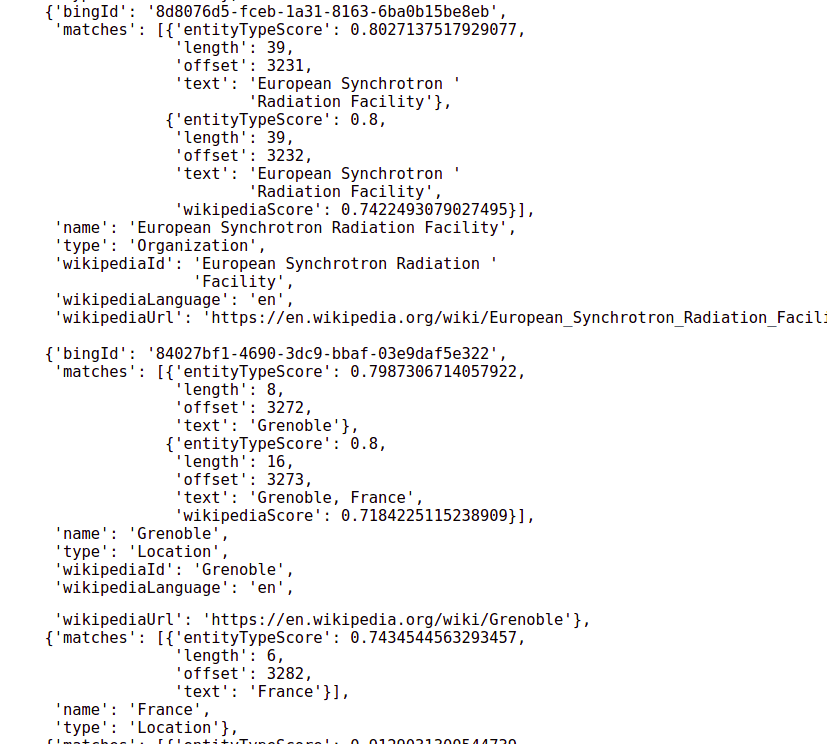
Ausgabe eines Algorithmus zur Erkennung benannter Entitäten. Dieser nimmt einen englischen Satz und identifiziert alle darin enthaltenen Wörter, die sich auf Entitäten beziehen, stellt ggf. Wikipedia-Links bereit und weist jedem einen Vertrauenswert zu.
Es ist oft wünschenswert, sogenannte „benannte Entitäten“ in einem Dokument zu identifizieren und eindeutig zu machen. Einige Beispiele:
Der anonymisierte Lebenslauf eines Arbeitssuchenden. Personalvermittler nutzen häufig Anonymisierungstools, um die Daten von Bewerbern an Arbeitgeber weiterzugeben, ohne das Risiko einzugehen, dass der Arbeitgeber die Personalvermittlungsagentur umgeht.
Mit dem Aufkommen von Big Data ist das Bewusstsein für die Bedeutung des Datenschutzes gewachsen, was zu Vorschriften wie der DSGVO in Europa geführt hat. Dies hat auch neue Möglichkeiten für NLP eröffnet, da viele Organisationen nun alle Dokumente anonymisieren müssen, bevor sie sie an Dritte weitergeben. NLP kann verwendet werden, um alle Personennamen, Telefonnummern, Adressen oder Ähnliches in einem Dokument zu entfernen oder durch Platzhalter zu ersetzen. Die Techniken dahinter ähneln denen der Named Entity Recognition, aber das Ziel ist das Gegenteil: Daten zu verschleiern, anstatt sie zu extrahieren.

Ein anonymisierter technischer Due-Diligence -Bericht von Fast Data Science. Die Verarbeitung natürlicher Sprache ist nützlich, um vertrauliche Unternehmensdaten zu bereinigen.
Traditionell entwickelte sich NLP aus dem Bereich der Linguistik, wo Informatiker versuchten, Computer mit immer ausgefeilteren Darstellungen der menschlichen Sprache zu programmieren. Im Laufe der Zeit hat sich NLP von regelbasierten Ansätzen zu Ansätzen auf der Basis maschinellen Lernens entwickelt und wird heute unter KI oder künstliche Intelligenz zusammengefasst.
KI ist ein sehr weit gefasster Begriff, der eine Vielzahl von Bereichen umfasst, von der Bildverarbeitung und Gesichtserkennung bis hin zur Audiotranskription, Kundenabwanderungsprognose und Betrugserkennung. In seiner weitesten Definition umfasst KI alle Techniken, die verwendet werden, um Computer dazu zu bringen, menschliches Denken nachzuahmen, was die gesamte NLP einschließt.
NLP-Techniken können in drei Gruppen unterteilt werden:
Regelbasierte Systeme sind am einfachsten zu erklären. Ein Mensch würde beispielsweise ein Computerprogramm schreiben, das Anweisungen wie „Wenn das Wort mit einem Großbuchstaben beginnt und nicht am Satzanfang steht und das folgende Wort ebenfalls mit einem Großbuchstaben beginnt und das folgende Wort ein Verb ist, dann ist es ein Personenname“ befolgt. Regelbasierte NLP-Systeme sind zwar leicht verständlich und hochgradig transparent, aber schwer zu warten und zu skalieren und weisen keine sehr gute Leistung auf. Der einzige Bereich, in dem ich regelbasierte Systeme in der Industrie im Einsatz gesehen habe, sind Chatbots, aber selbst Chatbots entfernen sich von regelbasierten Ansätzen und bewegen sich in Richtung maschineller Lerntechniken.
Traditionelle Systeme auf Basis maschinellen Lernens sind leistungsfähiger als regelbasierte Systeme und erfordern, dass der NLP-Datenwissenschaftler ein Modell auswählt und einen Satz Trainings- und Validierungsdaten bereitstellt. Beispiele für diesen Ansatz sind der Naive-Bayes-Algorithmus zur Spam-Erkennung. Sie können einen passablen Spam-Detektor mit nur 100 Beispielen für Spam-E-Mails und 100 für Ham-E-Mails sowie den einfachen Regeln des Naive-Bayes-Algorithmus erstellen.
Der Stand der Technik für alle NLP-Anwendungen sind heute Deep-Learning-basierte Systeme. Deep-Learning-basierte Systeme basieren auf neuronalen Netzwerken. Sie benötigen eine Möglichkeit, ein Textdokument in Zahlen umzuwandeln, die in ein neuronales Netzwerk eingespeist werden können, das dann lernen kann, die anstehende Aufgabe auszuführen.
Deep-Learning-NLP-Methoden erfordern in der Regel sehr große Mengen an Trainingsdaten, was zu großen Modellgrößen führt und mehr Rechenleistung für Training und Ausführung erfordert. Oft benötigt ein NLP-Datenwissenschaftler Millionen von Dokumenten, bevor das Training eines auf Deep Learning basierenden Systems praktikabel wird. Deep Learning ist für viele NLP-Projekte keine Option, da die Menge der verfügbaren Trainingsdaten zu gering ist.
Der Hauptvorteil von Deep-Learning-basierten Systemen besteht darin, dass Datenwissenschaftler nicht viel Zeit mit dem Entwerfen und Optimieren von Algorithmen für maschinelles Lernen verbringen müssen. Sie können normalerweise ein vorhandenes neuronales Netzwerkdesign direkt verwenden. Wenn sie Glück haben, können sie ein vorab trainiertes Netzwerk wie BERT verwenden, das bereits mit Texten in der betreffenden Sprache trainiert wurde, und sie müssen nur minimale Nachschulungen durchführen, um das Modell an ihren Anwendungsfall anzupassen. Diese Technik wird als Transferlernen bezeichnet.
Der zweite Hauptvorteil von Systemen auf Basis von Deep Learning besteht darin, dass sie ein erstaunliches Maß an Genauigkeit liefern können, da sie sich an die äußerst komplexe Struktur der menschlichen Sprache anpassen können.
Beispielsweise konnten neuronale Netzwerke auf der Basis von LSTM und Transformer Pronomen über mehrere Sätze hinweg auflösen. Neuronale Netzwerkmodelle konnten auch Sätze wie „Ich sah den Mond. Er war wunderschön“ korrekt ins Spanische oder Deutsche übersetzen, wobei die Übersetzung von „er“ vom Geschlecht von „Mond“ abhängt (so wird der letzte Satz im Spanischen als „sie war wunderschön“ und im Deutschen als „er war wunderschön“ wiedergegeben).
Bei der Textklassifizierung stellen Transformer-basierte Modelle derzeit den neuesten Stand der Technik dar. Allerdings entwickelt sich dieses Feld rasch weiter und jedes Jahr wird ein neuer Entwurf für ein neuronales Netzwerk veröffentlicht, der das vorherige Spitzenmodell übertrifft.
Ich hoffe, dieser Artikel hat Ihnen geholfen, die wichtigsten Punkte von NLP besser zu verstehen.
Wenn Ihre Organisation über eine große Menge an Textdokumenten verfügt und Sie Unterstützung bei der Nutzbarmachung dieser Dokumente benötigen, nehmen Sie bitte Kontakt mit uns auf .
Suchen Sie Experten in Natürlicher Sprachverarbeitung? Veröffentlichen Sie Ihre Stellenangebote bei uns und finden Sie heute Ihren idealen Kandidaten!
Veröffentlichen Sie einen Job
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you