
Natural Language Processing oder NLP ist der Bereich der künstlichen Intelligenz, der sich mit der Analyse der menschlichen Sprache beschäftigt. Natural Language Processing ist ein aufstrebendes Feld mit einer großen Anzahl von Geschäftsanwendungen. Große Unternehmen, die über ein eigenes Data Science-Team verfügen, haben oft keine NLP-Spezialisten im Haus und müssen möglicherweise NLP-Experten als Berater hinzuziehen.
Wir benötigen die Verarbeitung natürlicher Sprache, wenn wir mit unstrukturierten Textdokumenten konfrontiert sind. Ein unstrukturiertes Dokument könnte etwa so aussehen:
Laut Dr. S lassen sich Patienten mit Komorbiditäten mit der Kombinationsbehandlung besser behandeln, allerdings hat sie bei älteren Patienten eine gewisse Resistenz festgestellt. Behandlungsnaive Patienten reagierten positiv.
(ein Beispieldokument aus der Pharmaindustrie)
oder
Insbesondere die Sicherheitswarnungen wurden von der Besatzung ignoriert. Aufgrund eines elektronischen Defekts funktionierte der akustische Alarm nicht. Die Leistung des Ersten Offiziers war durch die langen Arbeitszeiten auf dem Schiff beeinträchtigt. Außerdem war der wachhabende Offizier eingeschlafen. Die Untersuchung ergab, dass alle oben genannten Faktoren zum Untergang des Schiffes beitrugen.
(ein Bericht zur Untersuchung eines Seeunfalls)
Sie können sich vorstellen, dass ein solcher Absatz für einen Laien schwer verständlich ist, Branchenexperten in den entsprechenden Bereichen (in diesem Fall Pharma und Schifffahrt) dürften jedoch keine Probleme haben, den Text zu verstehen.
Hier kommt die Verarbeitung natürlicher Sprache ins Spiel.
Wenn beispielsweise eine Schifffahrtsversicherung eine Datenbank zu Vorfällen und deren Ursachen aufbauen oder ein Pharmaunternehmen Muster in den Rückmeldungen von Gesundheitsdienstleistern analysieren möchte, müssen wir zunächst die im Text enthaltenen Informationen in ein für den Computer verarbeitbares Format umwandeln.
Dies könnte die Form einer XML- oder JSON-Datei wie der folgenden annehmen:
{
...
"Ursachen": {
“PRIMARY”: [
“ELECTRONIC”,
“WORKING_HOURS”
],
“SECONDARY”: [
“EQUIPMENT_MALFUNCTION”
]
},
...
}
Ein Zweck der Verarbeitung natürlicher Sprache besteht darin, zwischen der unstrukturierten, benutzerfreundlichen Darstellung der Informationen und dem strukturierten Format zu übersetzen.
Wir können NLP also als eine Komponente betrachten, die zwischen diesen beiden Darstellungen sitzt. Die Aufgabe, einen für Menschen lesbaren Text in ein strukturiertes Format zu übersetzen, wird als Natural Language Understanding oder NLU bezeichnet, während die entgegengesetzte Aufgabe, eine strukturierte Liste in einen für Menschen lesbaren Text umzuwandeln, als Natural Language Generation oder NLG bezeichnet wird. Aufgrund der großen Vielfalt möglicher Formulierungen, die Menschen in Texten verwenden, ist Natural Language Understanding die schwierigere der beiden Aufgaben.
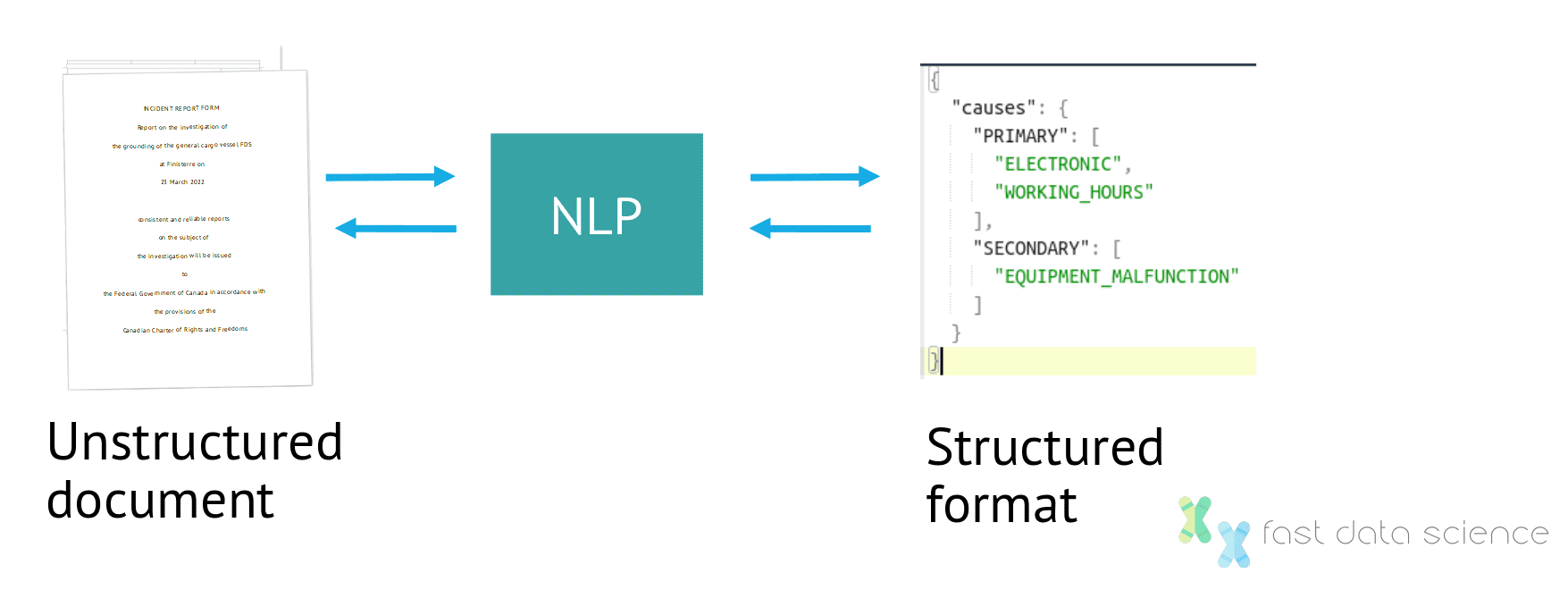
Die Verarbeitung natürlicher Sprache übersetzt zwischen einem unstrukturierten und einem strukturierten Datenformat, beispielsweise einer PDF-Datei eines Unfallberichts, und einer computerlesbaren Darstellung der relevanten Informationen.
Sobald die Informationen in das strukturierte Format konvertiert wurden, können sie in Datenbanken gespeichert und einfach und schnell abgefragt, abgerufen, aggregiert und verglichen werden. Stellen Sie sich vor, Sie versuchen, 100 Unfallberichte oder Zusammenfassungen klinischer Studien zu vergleichen, wenn sie alle im PDF-Format auf Ihrem Computer vorliegen! Dies zeigt, wie wertvoll NLP in einigen Bereichen sein kann.
Fast Data Science - London
Es gibt eine große Bandbreite an Anwendungen für die Verarbeitung natürlicher Sprache. Einige davon werden Ihnen offensichtlich sein, andere weniger.
Beispielsweise sind Google Translate und andere maschinelle Übersetzungssoftware eine klare Anwendung der Verarbeitung natürlicher Sprache. Informatiker arbeiten seit mehr als 50 Jahren an Algorithmen für maschinelle Übersetzung. In der Vergangenheit wurden hierfür regelbasierte Systeme verwendet, während heute datengesteuerte Ansätze wie neuronale Netzwerke bevorzugt werden.
Smartphone-Nutzer kennen auch die virtuellen Assistenten, die heute mit jedem Smartphone ausgeliefert werden. Die virtuellen Assistenten kombinieren zwei leistungsstarke Bereiche der natürlichen Sprachverarbeitung: Spracherkennung und -synthese (auch als Sprache-zu-Text und Text-zu-Sprache bekannt) sowie natürliche Sprachdialogsysteme zur Steuerung der Konversation.
In meiner Tätigkeit als Berater für natürliche Sprachverarbeitung werde ich in Projekte in praktisch allen Branchen eingebunden und viele der Aufgaben, mit denen ich konfrontiert werde, sind völlig neu, aber dennoch absolut faszinierend.
Nur so aus dem Stegreif: Die letzten paar Projekte, an denen ich gearbeitet habe, waren
Die traditionelle Herangehensweise an Probleme der natürlichen Sprachverarbeitung besteht darin, den Text durch eine Pipeline von Komponenten zu leiten, die jeweils unabhängig voneinander die Ausgabe der vorherigen Komponente verarbeiten.
Die erste Komponente in einer Pipeline ist normalerweise ein Tokenizer. Nachdem ein PDF- oder Word-Dokument in einfachen Text umgewandelt wurde, wird es in Einheiten von Wörtern und Satzzeichen, sogenannte Tokens, aufgeteilt. Bei englischem Text ist die Tokenisierung relativ unkompliziert, bei ostasiatischen Sprachen kann sie jedoch schwierig sein, da die Grenzen eines Wortes nicht immer klar definiert sind.
Die Token können dann an eine Reihe von Komponenten weitergegeben werden, die sie mit zusätzlichen Informationen versehen, wie zum Beispiel
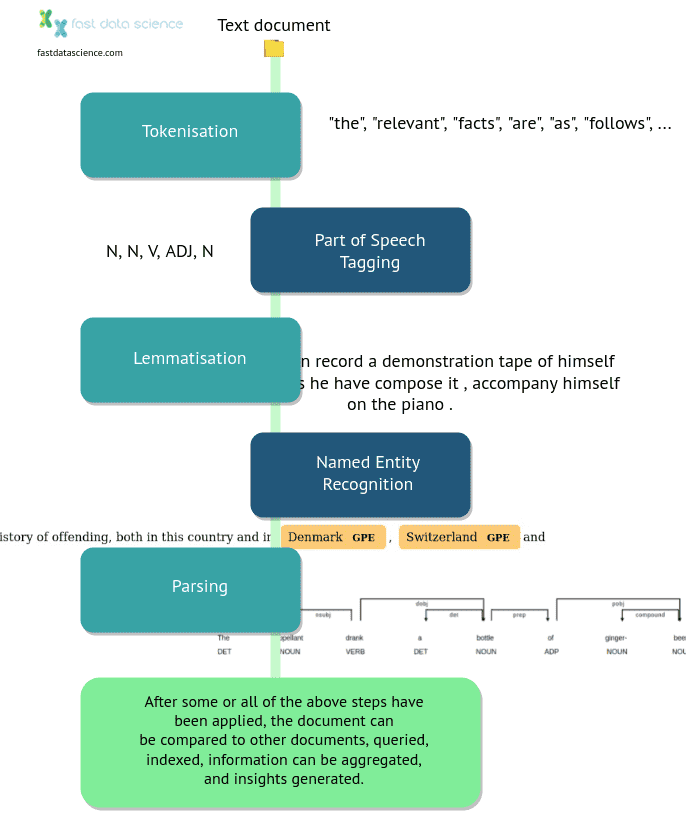
Das traditionelle Konzept einer NLP-Pipeline. Schritte wie Tokenisierung, Lemmatisierung usw. werden der Reihe nach angewendet, und ein unstrukturiertes Textdokument wird schrittweise in ein strukturiertes Format umgewandelt.
In den letzten Jahren wurden im Bereich der Verarbeitung natürlicher Sprache große Fortschritte gemacht, und für viele Anwendungen gehört die traditionelle NLP-Pipeline der Vergangenheit an. Eine wichtige Innovation ist die Erfindung des Transformers, dem neuesten auf neuronalen Netzwerken basierenden Ansatz zur Verarbeitung natürlicher Sprache.
Ein Transformer ist im Wesentlichen ein riesiges neuronales Netzwerk, das für die Verarbeitung von Sequenzen optimiert ist und sich daher ideal für die Verarbeitung von Text- oder Tonsignalen eignet. Im Kern wandelt ein Transformer eine Sequenz von Token in eine Sequenz von Vektoren in einem sehr hochdimensionalen Raum um. Diese Vektoren können für nahezu jede NLP-Aufgabe verwendet werden, von der grammatikalischen Satzanalyse bis hin zur Beantwortung von Fragen und dem Abrufen von Informationen.
Das bekannteste Transformatormodell ist BERT, das neueste und größte Transformatormodell ist jedoch GPT-3 .
Transformer sind so komplex und schwer zu trainieren, dass der durchschnittliche Benutzer nicht mehr in der Lage ist, seine eigenen Transformer im Handumdrehen individuell zu erstellen und zu trainieren, wie dies mit einer NLP-Pipeline, wie ich sie oben beschrieben habe, möglich wäre. Der einfachste Ansatz besteht darin, eine vorgefertigte Bibliothek wie Hugging Face oder Open AI zu verwenden und die sofort einsatzbereiten Transformermodelle zu nutzen.
Für die meisten Beratungsprojekte zur Verarbeitung natürlicher Sprache , an denen ich gearbeitet habe, waren Transformatoren jedoch nicht relevant. In vielen Fällen waren Fachkenntnisse und die Bereitschaft, etwas über die Branche zu lernen, wichtiger als ein riesiges neuronales Deep-Learning-Netzwerk oder Gigabyte an Daten.
Ich habe beispielsweise an einem Projekt zur Quantifizierung des Risikos einer klinischen Studie gearbeitet, und die enorme Datenmenge, die ein Transformator benötigt hätte, war einfach nicht verfügbar. Meine einzige Möglichkeit bestand darin, Fachwissen zu sammeln, mit Experten auf dem Gebiet zu sprechen und zu versuchen, ein einfaches maschinelles Lernmodell zu erstellen, das mit Tokens operierte.
Wenn Sie sich für den Einstieg in die Verarbeitung natürlicher Sprache interessieren oder bereits etwas über diesen Bereich wissen, aber ein Experte werden möchten, gibt es eine Reihe von Quellen, die ich Ihnen empfehlen kann.
Ich hoffe, dass Sie die Informationen in diesem Artikel verarbeiten konnten und nun besser verstehen, was natürliche Sprachverarbeitung ist und wofür NLP verwendet wird. Wenn Sie in irgendeiner Branche über eine große Menge unstrukturierter Daten verfügen (Branchen wie die Pharma-, Rechts- oder Versicherungsbranche verfügen über große Mengen an Textdaten) und einen NLP-Experten oder NLP-Berater beauftragen müssen, der Ihnen hilft, die Daten zu verstehen, zögern Sie bitte nicht, uns zu kontaktieren .
Bereit für den nächsten Schritt in Ihrer NLP-Reise? Vernetzen Sie sich mit Top-Arbeitgebern, die Talente in der natürlichen Sprachverarbeitung suchen. Entdecken Sie Ihren Traumjob!
Finden Sie Ihren Traumjob
Generative KI Einführung Generative KI , ein Teilbereich der KI, verändert Branchen grundlegend und gestaltet die Zukunft. Durch die Nutzung fortschrittlicher Algorithmen kann generative KI Inhalte, Designs und Lösungen erstellen, die zuvor undenkbar waren. Durch die Verwendung von Modellen des maschinellen Lernens wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) können generative KI-Systeme neue Daten erstellen, die die Muster und Strukturen der Trainingsdaten nachahmen.

Große Daten Das Aufkommen von Big Data hat ganze Branchen revolutioniert und traditionelle Geschäftsmodelle und Entscheidungsprozesse verändert. In dieser umfassenden Untersuchung gehen wir der Frage nach, was Big Data ist, welche erheblichen Auswirkungen es auf die Geschäftsstrategie hat und wie Unternehmen riesige Datenmengen nutzen können, um Innovationen voranzutreiben und sich einen Wettbewerbsvorteil zu verschaffen.
KI im Finanzwesen Die Integration künstlicher Intelligenz (KI) in den Finanzsektor hat die Arbeitsweise von Institutionen revolutioniert, von der Automatisierung von Abläufen bis hin zur Verbesserung der Kundenbindung und des Risikomanagements. Diese umfassende Untersuchung wird mehrere Schlüsselbereiche untersuchen, in denen KI in der Branche erhebliche Fortschritte macht.
What we can do for you