
Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdeckenKönnen wir die KI-Voreingenommenheit beseitigen?
Voreingenommenheit ist eine der vielen Unvollkommenheiten der Menschheit, die dazu führt, dass wir Fehler machen und uns davon abhalten, zu wachsen und Innovationen voranzutreiben. Voreingenommenheit ist jedoch nicht nur eine menschliche Realität, sondern auch eine Realität für künstliche Intelligenz . KI-Bias ist ein gut dokumentiertes Phänomen, das bei maschinellen Lerntools aus verschiedenen Bereichen weit verbreitet ist und bekanntermaßen schwer zu beseitigen ist.
Im Jahr 2020 berichtete der Guardian , dass mehr als die Hälfte der Kommunen in England Algorithmen verwenden, um Entscheidungen über Leistungen (Wohlfahrt) zu treffen, ohne die Öffentlichkeit über diesen Einsatz der Technologie konsultiert zu haben. Wenn sie irgendeine Art von voreingenommener KI verwenden, könnte dies schwerwiegende Folgen für die Entrechteten in der Gesellschaft haben.
Künstliche Intelligenz soll uns von unseren menschlichen Grenzen befreien. Die Fähigkeit einer Maschine, innerhalb weniger Minuten riesige Datenmengen zu scannen und Trends und Muster zu erkennen, ist ein unschätzbares Werkzeug, das uns hilft, Zeit zu sparen und die Effizienz zu steigern. Denn Maschinen können nicht nur Daten viel schneller analysieren als Menschen, sondern auch Muster erkennen, die ein Mensch alleine nicht erkennen könnte. Wenn die künstliche Intelligenz, die wir verwenden, jedoch voreingenommen ist, werden die Extrapolationen, die wir von der KI erhalten, fehlerhaft sein. Lassen Sie uns einige der häufigsten Vorurteile in der KI durchgehen.
KI-Bias entsteht, wenn falsche Annahmen im maschinellen Lernprozess zu systematisch voreingenommenen Ergebnissen führen. Diese Verzerrung beim maschinellen Lernen kann auf menschliche Voreingenommenheit seitens der Personen zurückzuführen sein, die das System entwerfen oder trainieren, oder sie kann auf unvollständige oder fehlerhafte Datensätze zurückzuführen sein, die zum Trainieren des Systems verwendet wurden.
Wenn Sie beispielsweise einen Algorithmus darauf trainieren, bestimmte Hauterkrankungen anhand verschiedener Bilder von Hauterkrankungen zu erkennen, und die von Ihnen verwendeten Bilder hauptsächlich hellhäutige Menschen zeigen, kann sich dies negativ auf die Fähigkeit der KI auswirken, dieselben Hauterkrankungen zu erkennen dunklere Haut. Unabhängig von der Ursache wirkt sich KI-Voreingenommenheit negativ auf die Gesellschaft aus, von den Algorithmen, die wir bei Einstellungspraktiken verwenden, bis hin zur KI, die zur Ermittlung von Hochrisiko- Straftätern eingesetzt wird.

KI-Voreingenommenheit hat eine lange und komplizierte Geschichte, die bis in die Anfänge von Computern und maschinellem Lernen zurückreicht. Hier ist ein Beispiel für eine frühe KI-Voreingenommenheit: 1988 stellte die britische Kommission für Rassengleichheit fest, dass sich eine britische medizinische Fakultät aufgrund der KI-Voreingenommenheit in ihrer Computerprogrammierung der Diskriminierung schuldig gemacht hatte. Es wurde festgestellt, dass ihr Computerprogramm Frauen und Personen mit nicht europäisch klingenden Namen bei der Auswahl von Kandidaten für das Vorstellungsgespräch zu Unrecht diskriminierte .
Interessanterweise wurde dieses Computerprogramm so konzipiert, dass es die Entscheidungen der menschlichen Zulassungsbeamten widerspiegelt, was ihm mit einer Genauigkeit von 90–95 % gelang. Da die KI-Technologie entwickelt wurde, um menschliche Entscheidungen nachzuahmen, hat sie unbeabsichtigt menschliche Vorurteile in die KI-Voreingenommenheit einbezogen und häufig Interviews mit Frauen und ethnischen Minderheiten verweigert.

Fast Data Science - London
Künstliche Intelligenz wird im Strafrechtssystem häufig eingesetzt, um Bürger zu kennzeichnen, die eher als „hochriskant“ eingestuft werden. Da viele dieser Tools für maschinelles Lernen anhand bestehender Polizeiakten trainiert werden, können diese Tools menschliche Vorurteile in ihre Algorithmen integrieren.
Einige Polizeibeamte haben beispielsweise Bedenken geäußert , dass die Wahrscheinlichkeit, dass junge schwarze Männer auf der Straße angehalten und durchsucht werden als junge weiße Männer, dies Auswirkungen auf die Datensätze hat, die dann für die Vorhersage von KI-Verbrechen verwendet werden, was dann die rassistische Voreingenommenheit verstärkt. Es wurden auch Bedenken geäußert, dass Menschen aus benachteiligten Verhältnissen häufiger öffentliche Dienstleistungen in Anspruch nehmen und dadurch ihre Darstellung in den Daten verzerrt wird, wodurch die Wahrscheinlichkeit steigt, dass sie als Risiko eingestuft werden.
Programme mit künstlicher Intelligenz werden auch häufig zur Überprüfung der Lebensläufe von Bewerbern eingesetzt, um Top-Talente zu rekrutieren. Es ist jedoch bekannt, dass diese Algorithmen KI-Voreingenommenheit aufweisen, was dazu führt, dass qualifizierte Kandidaten ausschließlich aufgrund ihrer Rasse oder ihres Geschlechts ausgeschlossen werden. Amazon hat im Jahr 2018 den Einsatz seines KI-Rekrutierungstools eingestellt, nachdem festgestellt wurde, dass das Programm voreingenommen gegen Frauen ausgerichtet war.
Das künstliche Intelligenztool von Amazon wurde darauf trainiert, Muster in Lebensläufen zu erkennen, und es stellte fest, dass die Mehrheit der Bewerber Männer waren, was dazu führte, dass das Programm unbeabsichtigt männliche Bewerber bevorzugte. Dies geschah durch die Herabstufung von Bewerbungen, die das Wort „Frauen“ enthielten, beispielsweise Bewerber, die eine Frauenhochschule besuchten oder einer Frauengruppe oder -organisation beitraten. Obwohl Amazon versuchte, diese Voreingenommenheit in seinem Programm herauszufiltern, hat es sie letztendlich vollständig verworfen.

Es stellt sich heraus, dass die Überprüfung, ob ein Bewerber ein Manga-Forum besucht, eine sexistische Art der Mitarbeiterauswahl ist.
Eine Online-Plattform für die Einstellung von Technikern namens Gild ging sogar so weit, die Social-Media-Präsenz der Bewerber zu analysieren, um einen Einstellungsscore zu erstellen. Dabei wurden Aktivitäten auf Tech-Seiten wie Github berücksichtigt, der Algorithmus vergab aber auch zusätzliche Punkte an Bewerber, die in einem bestimmten japanischen Manga-Forum aktiv waren, das eine hohe männliche Nutzerbasis hatte. Die Begründung lautete, dass das Interesse an Manga ein starker Prädiktor für die Programmierfähigkeit sei, die Entwickler dieses Algorithmus es jedoch versäumten, die implizite geschlechtsspezifische Voreingenommenheit zu berücksichtigen, die sie in die Einstellungspraktiken einführten – diese Voreingenommenheit in der KI führte ebenfalls zu verzerrten Ergebnissen.
Viele Modelle zur Verarbeitung natürlicher Sprache werden anhand realer Daten trainiert. Da Nachrichtenartikel und Literatur typischerweise auf Männer ausgerichtet sind, führt dies zu einer Voreingenommenheit.
Hier ist ein Beispiel für eine NLP- KI-Voreingenommenheit.
In der Vergangenheit gab Google Translate den geschlechtsneutralen türkischen Ausdruck „o bir hemşire “ mit „sie ist eine Krankenschwester“ wieder, während „o bir doktor“ mit „er ist eine Krankenschwester“ übersetzt wurde. Das Pronomen o ist geschlechtsneutral und kann gleichermaßen mit „er“ oder „sie“ übersetzt werden.
Glücklicherweise wurde Google Translate, als ich 2023 nachschaute, so geändert, dass nun sowohl männliche als auch weibliche Übersetzungen angeboten werden.
Google Translate bietet jetzt korrekt beide Optionen für Übersetzungen aus geschlechtsneutraler Sprache an, anstatt standardmäßig weibliche oder männliche Pronomen zu verwenden. Bildquelle: Google
Was war also die Ursache für die ursprünglichen voreingenommenen Übersetzungen?
Nun, maschinelle Übersetzungsalgorithmen werden auf Korpora trainiert, bei denen es sich um große Textmengen handelt, die aus Nachrichtenartikeln, Literatur und anderen Inhalten bestehen. Die maschinellen Übersetzungsmodelle basieren auf Statistiken, das heißt, sie basieren auf der Wahrscheinlichkeit, dass bestimmte Sätze in einer Sprache vorkommen. Ein Satz wie „sie ist Krankenschwester“ wäre wahrscheinlicher gewesen als „er ist Krankenschwester“ – vielleicht tauchte die weibliche Version häufiger auf als die männliche Version im Korpus, auf dem Google Translate trainiert wurde.
Schauen wir uns als Beispiel das British National Corpus an, eines der bekanntesten Korpora für britisches Englisch.
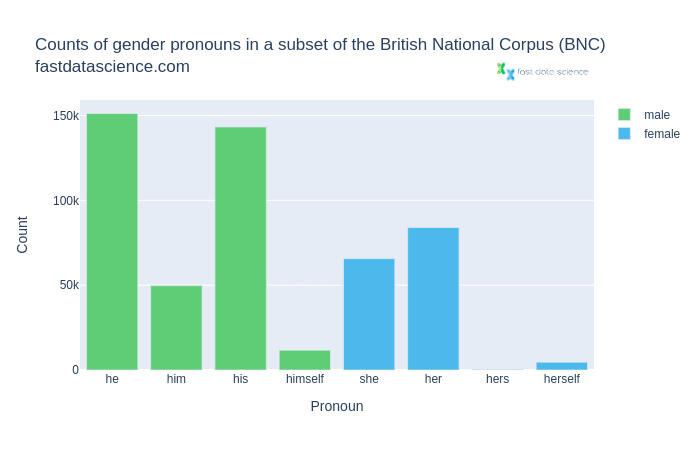
Zählungen der geschlechtsspezifischen Pronomen im British National Corpus. Männliche Pronomen wie er, ihn, sein und sich selbst sind viel häufiger als weibliche Pronomen.
Wir können sehen, dass die männlichen Pronomen im Allgemeinen viel häufiger vorkommen als ihre weiblichen Gegenstücke.
Angesichts dieses Ungleichgewichts ist es kein Wunder, dass maschinelle Übersetzungsalgorithmen eine geschlechtsspezifische Voreingenommenheit in übersetzten Texten absorbieren und weiter verbreiten.
Obwohl KI-Voreingenommenheit ein ernstes Problem darstellt, das die Genauigkeit vieler maschineller Lernprogramme beeinträchtigt, ist sie in mancher Hinsicht möglicherweise auch einfacher zu bewältigen als menschliche Voreingenommenheit. Im Gegensatz zu menschlicher Voreingenommenheit, die oft unbewusst und unbemerkt ist, ist die KI-Voreingenommenheit viel leichter zu erkennen. Algorithmen können viel einfacher auf Bias durchsucht werden, was häufig unbemerkte menschliche Bias in den in das System eingegebenen Datensätzen aufdecken kann. Dies kann uns helfen, systemische Verzerrungen zu erkennen, unseren Ansatz zur Datenerhebung zu ändern und Verzerrungen in KI-Modellen zu reduzieren.
Obwohl es schwierig ist, KI-Verzerrungen zu beheben, gibt es Möglichkeiten, Verzerrungen in KI-Modellen und -Algorithmen zu reduzieren . Durch das Testen von Algorithmen in Umgebungen, die denen ähneln, in denen sie in der realen Welt verwendet werden, können wir die KI effektiv trainieren, geeignete Muster zu erkennen, ohne unbewusste Vorurteile einzubeziehen. Entwickler müssen außerdem darauf achten, dass die Datensysteme, die sie zum Trainieren des maschinellen Lernens verwenden, frei von Vorurteilen sind und alle Rassen und Geschlechter genau repräsentieren.
Forscher haben versucht, „Fairness“ in KI-Algorithmen zu definieren, indem sie entweder verlangten, dass KI-Modelle über alle Gruppen hinweg den gleichen Vorhersagewert haben, oder indem sie verlangten, dass sie gleiche Falsch-Positiv- und Falsch-Negativ-Raten aufweisen. Sie sind sogar so weit gegangen, kontrafaktische Fairness in ihre KI-Modelle zu integrieren, indem sie testen, ob die Ergebnisse in einer Welt, in der allgemein sensible Attribute wie Rasse oder Geschlecht geändert wurden, die gleichen sind.
In einem früheren Blogbeitrag habe ich die Einführung eines Standards für Penetrationstests befürwortet, bei dem KI-Algorithmen einem Stresstest auf Voreingenommenheit unterzogen werden und ein Tester versucht, geschützte Merkmale zu rekonstruieren, die aus Trainingsdaten entfernt wurden.
Letztendlich lässt sich Verzerrung in KI-Modellen am besten reduzieren, wenn sowohl die Personen, die die künstliche Intelligenz trainieren, als auch die Personen, die sie testen, auf mögliche Verzerrungen achten und natürlich die Vielfalt in den Entwicklerteams, die an dem Algorithmus arbeiten, aufrechterhalten. Indem Entwickler auf beiden Seiten nach unbewussten Vorurteilen Ausschau halten, können sie Ungenauigkeiten schnell erkennen und die notwendigen Änderungen vornehmen.
Cathy O’Neil, How algorithms rule our working lives, The Guardian (2016)
Caroline Criado Perez, Invisible Women (2019)
The British National Corpus, version 3 (BNC XML Edition). 2007. Distributed by Bodleian Libraries, University of Oxford, on behalf of the BNC Consortium. URL: http://www.natcorp.ox.ac.uk/
Marsh and McIntyre, Nearly half of councils in Great Britain use algorithms to help make claims decisions, The Guardian, 2020
Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdecken
Mittlerweile sind es Organisationen aller Größenordnungen und fast aller Sektoren werden zunehmend datengesteuert, insbesondere als größere Datenspeicher Systeme und schnellere Computer treiben die Leistungsgrenzen immer weiter voran.

Aufgrund des umfangreichen Einsatzes von Technologie und der Arbeitsteilung hat die Arbeit des durchschnittlichen Gig-Economy-Arbeiters jeden individuellen Charakter und damit auch jeden Charme für den Arbeitnehmer verloren.
Die Auswirkungen von KI auf die Humanressourcen Die Arbeitswelt verändert sich rasant, sowohl aufgrund der Einführung traditioneller Data-Science-Praktiken in immer mehr Unternehmen als auch aufgrund der zunehmenden Beliebtheit generativer KI-Tools wie ChatGPT und Googles BARD bei nicht-technischen Arbeitnehmern.
What we can do for you