Bereit für den nächsten Schritt in Ihrer NLP-Reise? Vernetzen Sie sich mit Top-Arbeitgebern, die Talente in der natürlichen Sprachverarbeitung suchen. Entdecken Sie Ihren Traumjob!
Finden Sie Ihren TraumjobWir haben ein Tool entwickelt, das die Verarbeitung natürlicher Sprache nutzt und Forschern in den Sozialwissenschaften dabei helfen soll, Datensätze aus verschiedenen Kontexten zu harmonisieren . Dies ist Teil eines umfassenderen Projekts namens Harmony , das Teil eines Beitrags ist, den wir gemeinsam mit dem Center for Longitudinal Studies an der UCL , der Universität Ulster und der Universidade Federal de Santa Maria in Brasilien für den Wellcome Mental Health Data Prize einreichen.
Das Harmony-Projekt konzentriert sich auf eine Forschungsfrage:
Wie wirken sich soziale Kontakte auf Angstzustände und Depressionen bei jungen Menschen in verschiedenen Ländern aus?
Wir haben uns auf zwei sehr unterschiedliche Kontexte konzentriert: Großbritannien und Brasilien. Wir haben numerische Maße der sozialen Verbundenheit untersucht, die in Umfragen und Fragebögen gemessen werden können.
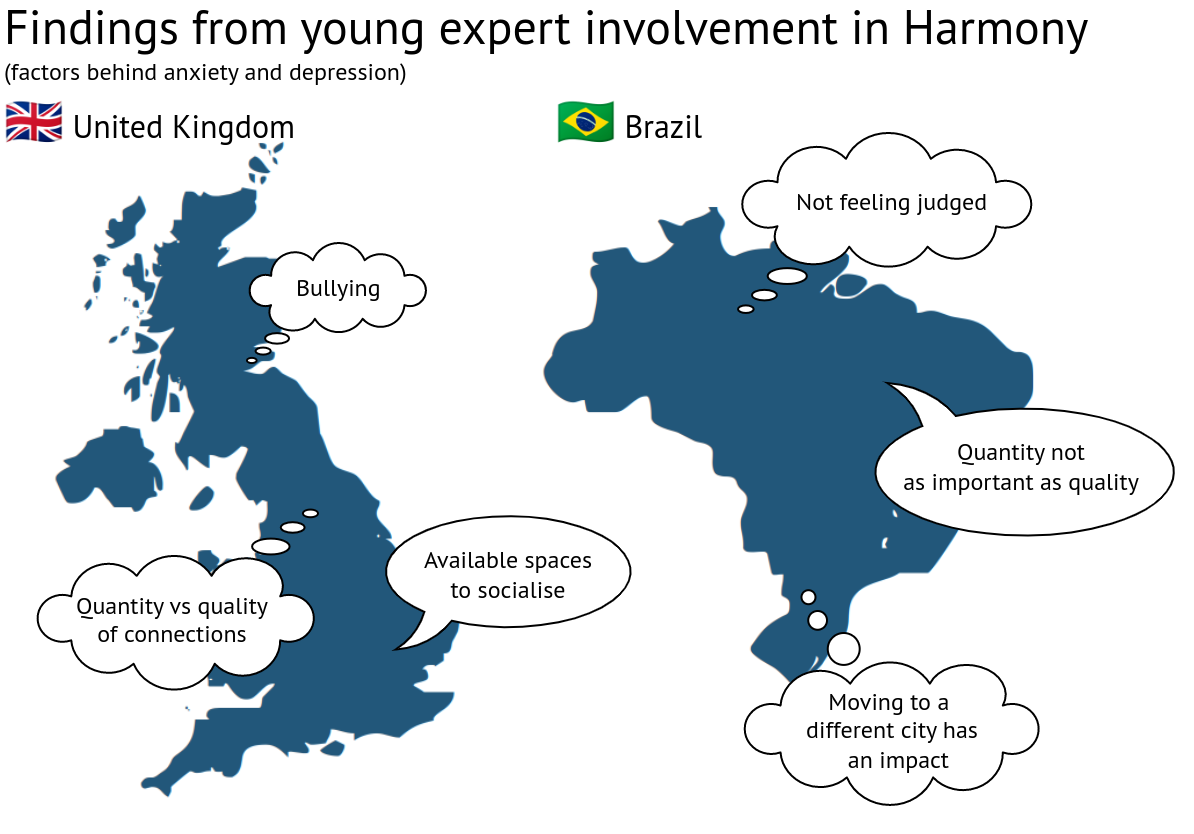
Die Harmony-Forscher führten eine Reihe von Sitzungen mit jungen Menschen in beiden Ländern durch, um qualitative Daten zu individuellen Erfahrungen zu sammeln.
In Brasilien befragte unser Psychologe sechs Menschen im Alter zwischen 13 und 18 Jahren, die wegen Angstzuständen und Depressionen in Behandlung waren, und befragte sie zu ihrem Konzept von sozialer Bindung und deren Zusammenhang mit Angstzuständen und Depressionen.
Fast Data Science - London
Aus diesen Initiativen gingen einige Unterschiede hervor. Britische Jugendliche nannten beispielsweise Mobbing als Hauptfaktor, während brasilianische Teilnehmer angaben, sich nicht beurteilt zu fühlen.
Für Großbritannien und Brasilien stehen Datensätze zur Verfügung, mit denen wir arbeiten konnten:
UK Millennium Cohort Study , auch bekannt als „Kind des neuen Jahrhunderts“. Hierbei handelt es sich um eine Studie des Centre for Longitudinal Studies der UCL, die das Leben von rund 19.000 jungen Menschen verfolgt, die zwischen 2000 und 2002 im Vereinigten Königreich geboren wurden.
Bei der brasilianischen Hochrisiko-Kohortenstudie für psychiatrische Störungen im Kindesalter (BHRC) handelt es sich um eine Studie, die seit 2010 2.511 brasilianische Kinder beobachtet und dabei psychologische, genetische und bildgebende Daten umfasst. Ziel der Studie ist es, typische und atypische Verläufe von Psychopathologie und Kognition im Verlauf der Entwicklung zu untersuchen.
Diese Datensätze enthalten Variablen und Datenpunkte, die auf unterschiedliche Weise dargestellt werden können. Wenn wir eine Metaanalyse durchführen möchten (den Zusammenhang zwischen sozialer Verbindung, Angstzuständen und Depression in beiden Ländern vergleichen), müssen wir zunächst ermitteln, welche Variablen in beiden Datensätzen verfügbar sind, welche Variablen sie gemeinsam haben und wie wir dies tun können Vergleichen Sie die Informationen in diesen Variablen.
Wenn beispielsweise in einer Studie die Angst mithilfe des GAD-7 gemessen wurde und in einer anderen Studie Becks Anxiety Inventory verwendet wurde, würde in der Regel ein manueller Harmonisierungsprozess zur Identifizierung äquivalenter Fragebogenelemente stattfinden.

Wir hatten die Idee, jedes Fragebogenelement als Vektor auf der Oberfläche einer mehrdimensionalen Kugel darzustellen. Elemente, die semantisch ähnlich sind, liegen nahe beieinander und haben eine Kosinusähnlichkeit nahe 1, während Elemente, die völlig unterschiedlich sind, tendenziell eine Ähnlichkeit nahe 0 haben.
Wir haben das Deep-Learning -Modell GPT-2 verwendet, um Texte in verschiedenen Sprachen in ihre Vektordarstellungen umzuwandeln. Wir haben dies in ein Web-Frontend verpackt, um ein webbasiertes Tool namens Harmony zu erstellen. Sie können es online unter https://harmonydata.ac.uk/app ausprobieren.
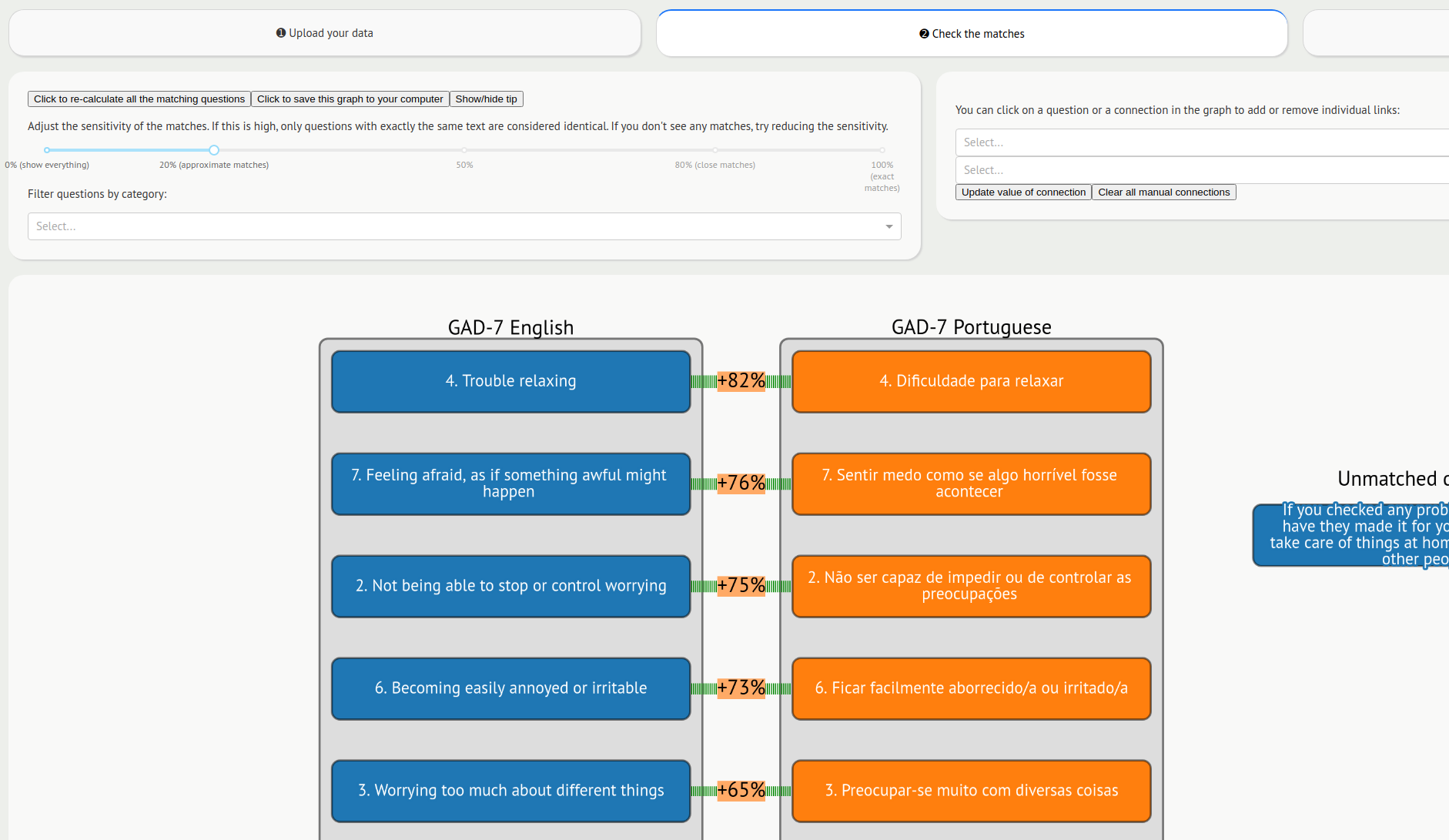
Wir haben Harmony auch in Zusammenarbeit mit DATAMIND und dem Catalogue of Mental Health Measures entwickelt, bei denen es sich um weit verbreitete Ressourcen in der Psychologieforschung handelt, und haben deren Feedback zur Verbesserung des Tools berücksichtigt.
Mehr über Harmony und seine Funktionsweise können Sie im Harmony-Blog lesen.
Radford, Alec, et al. “Language models are unsupervised multitask learners.” OpenAI blog 1.8 (2019): 9.
Salum, Giovanni Abrahão. “High Risk Cohort Study for Psychiatric Disorders in Childhood.”
Smith, Kate, and Heather Joshi. “The millennium cohort study.” POPULATION TRENDS-LONDON- (2002): 30-34.
Bereit für den nächsten Schritt in Ihrer NLP-Reise? Vernetzen Sie sich mit Top-Arbeitgebern, die Talente in der natürlichen Sprachverarbeitung suchen. Entdecken Sie Ihren Traumjob!
Finden Sie Ihren Traumjob
Mittlerweile sind es Organisationen aller Größenordnungen und fast aller Sektoren werden zunehmend datengesteuert, insbesondere als größere Datenspeicher Systeme und schnellere Computer treiben die Leistungsgrenzen immer weiter voran.

Aufgrund des umfangreichen Einsatzes von Technologie und der Arbeitsteilung hat die Arbeit des durchschnittlichen Gig-Economy-Arbeiters jeden individuellen Charakter und damit auch jeden Charme für den Arbeitnehmer verloren.
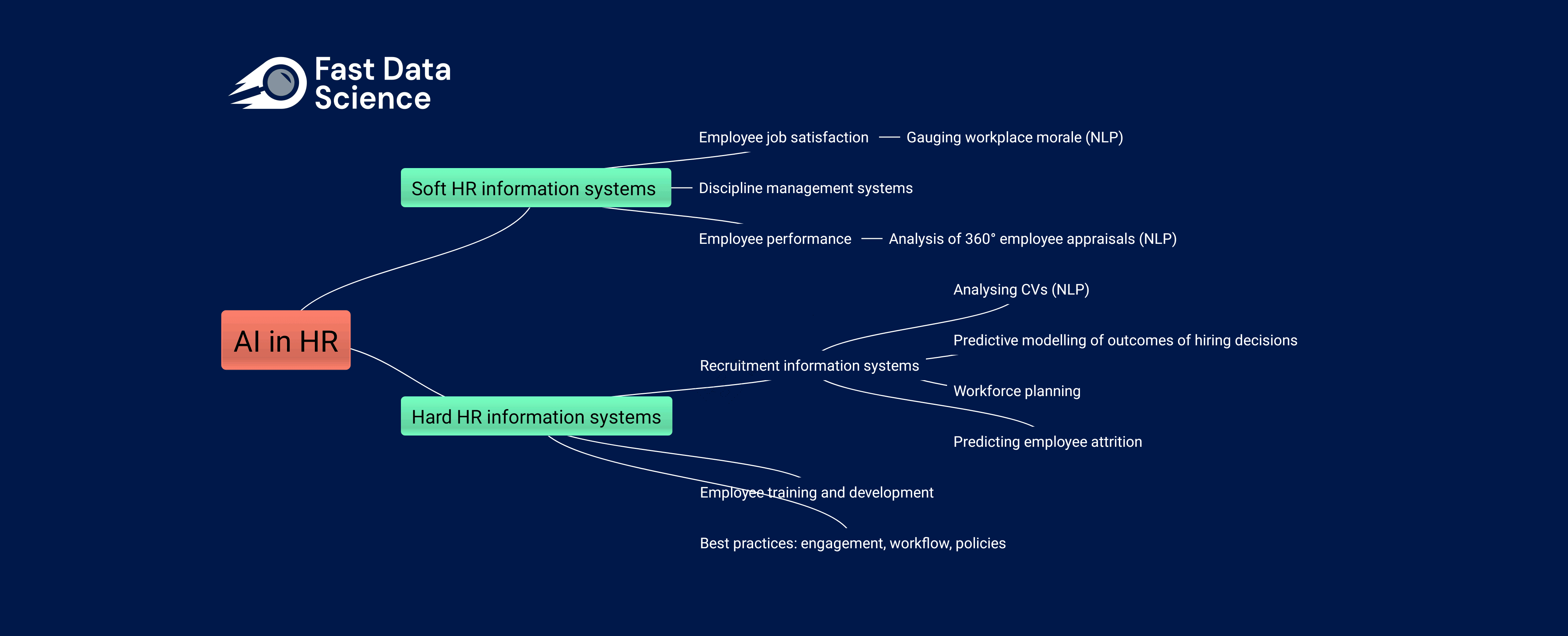
Die Auswirkungen von KI auf die Humanressourcen Die Arbeitswelt verändert sich rasant, sowohl aufgrund der Einführung traditioneller Data-Science-Praktiken in immer mehr Unternehmen als auch aufgrund der zunehmenden Beliebtheit generativer KI-Tools wie ChatGPT und Googles BARD bei nicht-technischen Arbeitnehmern.
What we can do for you