
Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdeckenTechnologien wie maschinelles Lernen (ML), künstliche Intelligenz (KI) und die Verarbeitung natürlicher Sprache (NLP) haben die Art und Weise revolutioniert Unternehmen sammeln Daten, interpretieren sie und nutzen die Erkenntnisse zur Verbesserung Prozesse, ROI, Kundenzufriedenheit und andere Aspekte ihrer Geschäft.
Es ist jetzt wichtiger denn je, Ihr Unternehmen richtig zu strukturieren Bemühungen in Bezug auf ML und KI, und dafür müssen Sie Verstehen Sie, wie der Workflow für maschinelles Lernen/künstliche Intelligenz funktioniert Der Workflow funktioniert im Allgemeinen.
Arbeitsabläufe für maschinelles Lernen beschreiben die Phasen, die implementiert werden während eines typischen ML-Projekts. Diese Phasen umfassen normalerweise Daten Sammlung und Datenvorverarbeitung, Aufbau von Datensätzen, Modelltraining und Verbesserungen, Evaluierung und schließlich Bereitstellung und Produktion.
Wir können zwar zustimmen, dass die oben genannten Schritte – die wir in besprechen werden große Tiefe – kann als Standard akzeptiert werden, es gibt immer Platz dafür Verbesserung. Denn wenn Sie zum ersten Mal mit maschinellem Lernen aufwarten Workflow müssen Sie das Projekt vor allem anderen definieren und dann Verwenden Sie einen Ansatz, der in Bezug auf die Geschäftsanwendung am besten funktioniert Sie zielen darauf ab.
Wir müssen also von Anfang an lernen, uns nicht mit Gewalt anzupassen Modell in einen starren Workflow umwandeln. Es ist immer gut, ein flexibles System aufzubauen Workflow, der es Ihnen ermöglicht, ganz einfach klein anzufangen und dann auf einen zu skalieren Lösung auf Produktionsebene.
Lassen Sie uns kurz die Schritte durchgehen, die in Arbeitsabläufen für maschinelles Lernen erforderlich sind – die von Projekt zu Projekt unterschiedlich sein können, obwohl die fünf Schritte Die von uns unten hervorgehobenen Elemente sind in der Regel enthalten:
Das Sammeln von Daten für Ihren maschinellen Lernworkflow ist eine der wichtigsten Aufgaben entscheidende Phasen. Während der Datenerfassungsphase definieren Sie die potenzielle Genauigkeit und Nützlichkeit Ihres Projekts oder Anwendungsfalls durch die Qualität der von Ihnen erfassten Daten.
Um Daten optimal zu sammeln, müssen Sie Ihre Quellen identifizieren und Fassen Sie die Daten dann in einem einzigen Datensatz zusammen.
Nach der Datenerfassung müssen Sie diese vorab verarbeiten. Das stellt sicher, dass die Daten bereinigt, überprüft und in eine verwendbare Form gebracht werden Datensatz. Dies kann ein relativ einfacher Vorgang sein, wenn die Daten vorhanden sind werden aus einer Hand gesammelt.
Aber wenn Sie die Daten aus mehreren Quellen aggregieren (was normalerweise der Fall ist). In diesem Fall müssen Sie sicherstellen, dass alle Datenformate übereinstimmen Jede Datenquelle ist gleichermaßen zuverlässig und es gibt kein Potenzial Duplikate.
Wir müssen nun unsere verarbeiteten Daten in drei Hauptdatensätze aufteilen:
Trainingsset: Wir werden dies zunächst verwenden, um den ML-Algorithmus zu trainieren. ihm beibringen, wie Informationen verarbeitet werden müssen. Das Set definiert das Modell Klassifizierungen durch Festlegen von Parametern.
Validierungssatz: Wir werden diesen verwenden, um abzuschätzen, wie genau das Modell ist besteht darin, den Datensatz zur Feinabstimmung aller unserer Modellparameter zu verwenden.
Testsatz: Wie der Name schon sagt, werden wir diesen verwenden, um zu bestimmen, wie wie genau die Modelle sind und wie gut sie funktionieren. Das ist eine großartige Möglichkeit um mögliche Probleme oder „schlechte“ Schulungen im Modell aufzudecken.
Nachdem wir unsere Datensätze haben, können wir unser Modell trainieren. Hier sind wir wird unseren Trainingssatz unserem Algorithmus zuführen, damit dieser das lernen kann richtige Parameter und Merkmale, die für die Klassifizierung erforderlich sind.
Sobald das Training abgeschlossen ist, können wir unser Modell mithilfe von verfeinern Validierungsdatensatz. Dies kann die Änderung bestimmter Variablen erfordern oder sie ganz zu verwerfen. Dazu gehört auch der Prozess des Optimierens modellspezifische Einstellungen (sogenannte Hyperparameter), bis wir darauf ankommen ein akzeptables Genauigkeitsniveau.
Sobald wir einen akzeptablen Satz von Hyperparametern ermittelt haben und Nachdem wir die Genauigkeit unseres Modells optimiert haben, können wir mit dem Testen unseres Modells fortfahren. Testen wird natürlich den Testdatensatz verwenden, der Ihnen bei der Überprüfung hilft ob Ihre Modelle genaue Funktionen verwenden. Sobald Sie die erhalten haben Mithilfe des Feedbacks können Sie dann entscheiden, ob es am besten ist, das Modell dafür zu trainieren Sie können die Genauigkeit verbessern, die Ausgabeeinstellungen optimieren oder es ohne weiteres bereitstellen Ado.
Nachdem wir nun mit den oben genannten Schritten vertraut sind, wollen wir sie genauer untersuchen Details, um die in jeder Phase beteiligten Prozesse besser zu verstehen welche Ergebnisse zu erwarten sind.
Beginnen wir mit den Grundlagen:
Das ML-Modell ist einfach ein Stück Code, was bedeutet, dass ein Datenwissenschaftler oder Der Ingenieur kann es „intelligent“ machen, indem er es mit den richtigen Daten trainiert. Also, Was auch immer Sie dem Modell zuführen, das ist es, was es ausgibt. Du kannst Trainieren Sie es buchstäblich, um richtige oder falsche Vorhersagen zu treffen – im Falle von Letzteres, füttere es mit Müll, und Müll wird zurückkommen!
Das Sammeln von Daten hängt weitgehend von der Art des Projekts ab, an dem wir arbeiten An. Wenn wir beispielsweise an einem ML-Projekt arbeiten, bei dem Echtzeitdaten vorliegen genutzt werden muss, dann können wir uns ein schönes IoT (Internet of) aufbauen (Things)-System, das unterschiedliche sensorische Daten nutzt. Das können wir abholen Datensatz aus mehreren Quellen wie einer Datenbank, einer Datei, einem Sensor usw auch andere Quellen. Allerdings können wir die gesammelten Daten nicht verwenden Daten direkt zur Durchführung des Analyseteils – das liegt daran Möglicherweise fehlen Daten, „verrauschte“ Daten oder unorganisierter/unstrukturierter Text oder sehr große Werte.
Aus diesem Grund müssen wir unsere Daten einer „Vorverarbeitung“ unterziehen. Damit sagte, es gibt kostenlose Datensätze im Internet – z. B. Kaggle wird häufig zur Erstellung von ML-Modellen verwendet und ist zufällig auch die am häufigsten besuchte Methode Website für diejenigen, die ML-Algorithmen üben möchten.
Dies ist einer der wichtigsten Schritte beim maschinellen Lernen kommt zum Training von Modellen, da es Ihnen hilft, ein Modell zu erstellen, das funktioniert genau. Darüber hinaus gibt es beim maschinellen Lernen eine 80/20-Regel bedeutet: Datenwissenschaftler müssen 80 % ihrer Zeit für Daten aufwenden Vorverarbeitung und 20 % für die eigentliche Analyse.
Die Datenvorverarbeitung oder Datenaufbereitung ist ein Prozess zur Rohdatenbereinigung oder unstrukturierte Daten – die Daten werden also aus der realen Welt gesammelt Quellen erfasst und dann in einen „sauberen“ Datensatz konvertiert. Um es anders zu sagen, Wann immer Sie Daten aus verschiedenen Quellen sammeln, landen diese bei Ihnen ein völlig rohes Format, für das Sie, wie Sie sich vorstellen können, noch nicht bereit sind Analyse. Daher sind bestimmte Schritte erforderlich, um diese Daten in umzuwandeln ein kleiner und sauberer Datensatz, und daher nennen wir ihn Datenvorverarbeitung.
Ebenso wichtig ist es zu verstehen, warum wir jede Datenvorverarbeitung benötigen Zeit wollen wir ML-Modelle trainieren. Wir tun dies einfach, um das Erwünschte zu erreichen oder machbare Ergebnisse aus dem angewandten Modell in unserem ML und DL (deep Lernen) und KI-Projekte.
Wenn reale Daten erfasst werden, sind sie normalerweise chaotisch. Das wird fast so sein kommen immer zu Ihnen in Form von:
Verrauschte Daten – Auch Outliner genannt, können verrauschte Daten entstehen menschliche Fehler (schließlich sind es Menschen, die die Daten sammeln) oder möglicherweise ein technisches Problem mit dem Gerät zu der Zeit, als es verwendet wurde Sammeln Sie die Daten.
Fehlende Daten – Sie können fehlende Daten haben, wenn diese vorhanden sind nicht kontinuierlich erstellt oder es liegen technische Probleme mit vor Anwendung (z. B. mit einem IoT-System).
Inkonsistente Daten – Dies ist normalerweise das Ergebnis menschlicher Fehler (z. B. Fehler bei Namen oder Werten) oder sogar Duplikate von Daten.
Bei den erfassten Daten handelt es sich in der Regel um drei Arten:
Numerische Daten (Alter, Einkommen usw.)
Kategoriale Daten (Nationalität, Geschlecht usw.)
Ordinaldaten (Werte, z. B. niedrig, mittel oder hoch)
Ganz gleich, wie streng der Standard ist, dem wir bei der Datenerfassung folgen, Sie Sie müssen verstehen, dass es Fehler, Inkonsistenzen usw. enthalten wird Mängel. Die Datenvorverarbeitung ist daher ein entscheidender Schritt sollte unter keinen Umständen umgangen werden, egal wie gut Sie sind Glauben Sie an die Qualität Ihrer ursprünglich gesammelten Daten!
Sie fragen sich vielleicht, wie die Datenvorverarbeitung erfolgt. Es ist fair unkompliziert, solange Sie diese Vorverarbeitungstechniken befolgen:
Datenkonvertierung – Da ML-Modelle nur Zahlen verstehen können Merkmale müssen wir die kategorialen und ordinalen Daten konvertieren numerische Merkmale.
Fehlende Werte übersehen – Jedes Mal, wenn wir auf fehlende Werte stoßen Daten im Datensatz, wir sollten die spezifische Zeile/Spalte der Daten entfernen, nach unserem Bedarf. Dies ist eine sehr effiziente Methode, obwohl dies nicht der Fall sein sollte durchgeführt werden, wenn in Ihrem Datensatz viele Werte fehlen – übersehen Sie sie nicht!
Auffüllen der fehlenden Werte – Wenn wir auf fehlende Daten stoßen Um unseren Datensatz zu erweitern, müssen wir die fehlenden Daten manuell ergänzen. Der Mittelwert, Normalerweise sollte der Medianwert oder der höchste Häufigkeitswert verwendet werden.
Maschinelles Lernen – Wenn wir auf fehlende Daten stoßen, sollten wir dies tun in der Lage, vorherzusagen, welche Daten an der leeren Position vorhanden sein müssen. Wir können unsere vorhandenen Daten nutzen, um dies festzustellen.
Erkennung von Ausreißern – Es besteht eine geringe Wahrscheinlichkeit, dass fehlerhafte Daten vorliegen Im Datensatz kann es vorkommen, dass dieser deutlich von anderen abweicht Beobachtungen darin. Beispielsweise wird das Gewicht einer Person eingegeben „800 kg“ aufgrund eines Tippfehlers, bei dem eine zusätzliche Null eingegeben wurde.
Wir werden nun unsere vorverarbeiteten Daten verwenden, um die Leistungsstärksten zu trainieren Machine-Learning-Modell möglich. In dieser Phase Ihres maschinellen Lernens Workflow oder Workflow mit künstlicher Intelligenz, Sie müssen zwei verstehen Konzepte:
Überwachtes Lernen – In einer überwachten Lernumgebung ist die Dem KI-System werden beschriftete Daten angezeigt, d. h. jedes Stück davon Die Daten werden mit der entsprechenden Bezeichnung versehen. Überwachtes Lernen selbst ist unterteilt in zwei Unterkategorien:
Klassifizierung – Die Zielvariable ist kategorischer Natur; dh die Die Ausgabe kann in Klassen eingeteilt werden, entweder Klasse A, B oder was auch immer Du willst, dass es so ist. Bei einem Klassifizierungsproblem also die Ausgabe Variable ist immer eine Kategorie („rot“ oder „blau“, „Spam“ oder „kein Spam“, „Krankheit“ oder „keine Krankheit“ usw.).
Zu den am häufigsten verwendeten Klassifizierungsalgorithmen gehört Naive Bayes, logistische Regression, Support Vector Machine und Random Forest.
Regression – Die andere Unterkategorie ist Regression. Hier ist die Zielvariable ist kontinuierlicher Natur; dh es verfügt über eine numerische Ausgabe.
Stellen Sie sich vor, Sie sehen sich ein Diagramm an, in dem auf der X-Achse „Test“ steht „Scores“ und die Y-Achse zeigt „IQ“ an. Wir werden also versuchen, das zu erstellen „Best-Fit-Linie“ und nutzt sie, um jeden durchschnittlichen IQ-Wert vorherzusagen, der das nicht ist in den angegebenen Daten vorhanden.
Zu den am häufigsten verwendeten Regressionsalgorithmen gehört Support Vektorregression, Random Forest, Ensemble-Methoden und linear Rückschritt.
Unbeaufsichtigtes Lernen – In einer unbeaufsichtigten Lernumgebung Dem KI-System werden unbeschriftete und nicht kategorisierte Daten präsentiert Die Algorithmen des Systems verarbeiten die Daten ohne vorheriges Training. Natürlich hängt die Ausgabe von der Codierung des Algorithmus ab. Also, Eine weitere Möglichkeit besteht darin, Ihr System unbeaufsichtigtem Lernen zu unterziehen Testen Sie Ihre KI.
Wie beim überwachten Lernen kann auch das unbeaufsichtigte Lernen unterteilt werden weiter in eine Unterkategorie:
Clustering – Hierbei unterteilen wir eine Reihe von Eingaben in Gruppen. Im Gegensatz zur Klassifizierung sind die Gruppen nicht im Voraus bekannt, also die Aufgabe selbst ist unbeaufsichtigt, wie Sie sich vorstellen können.
Zu den gängigen Methoden zur Verwendung von Clustering gehören: Boosting, Hierarchisch Clustering, Spectral Clustering, K-Means Clustering und mehr.
Um Ihnen einen schnellen Überblick über die Modelle und ihre Kategorien zu geben:
Maschinelles Lernen verzweigt sich in überwachtes und unbeaufsichtigtes Lernen Lernen; Überwachtes Lernen hat zwei Unterkategorien (Klassifizierung und Regression), während unüberwachtes Lernen eine Unterkategorie hat (Clusterbildung).
Um unser ML-Modell richtig zu trainieren, müssen wir es zunächst in drei Teile aufteilen Abschnitte:
Datenschulung
Datenvalidierung
Datentests
Wir werden unseren Klassifikator mithilfe des Trainingsdatensatzes trainieren und ihn optimieren Parameter durch den Validierungsdatensatz und testen Sie dann unsere Leistung des Klassifikators für den unsichtbaren Testdatensatz .
Beachten Sie Folgendes: Nur während Sie den Klassifikator trainieren Das Trainings- und Validierungsset ist verfügbar – wir werden es bewusst tun Legen Sie den Testdatensatz beiseite, während Sie den Klassifikator trainieren. Das Testset, Daher steht es zur Nutzung zur Verfügung, sobald wir mit dem Testen beginnen Klassifikator.
Es ist wichtig zu verstehen, wie diese drei Sets funktionieren:
Training – Der Trainingsdatensatz ist das eigentliche Material, durch das Das System oder der Computer lernt die Verarbeitung von Informationen. Das Training Ein Teil wird durch ML-Algorithmen durchgeführt. Ein bestimmter Datensatz zum Lernen verwendet werden, die auch zum Klassifikator passen müssen Parameter.
Validierung – Der Validierungsdatensatz bezieht sich auf die Kreuzvalidierung Dies wird hauptsächlich beim angewandten maschinellen Lernen zur Schätzung der Fertigkeit verwendet Ebene eines ML-Modells auf unsichtbaren Daten. Es wird ein Satz unsichtbarer Daten verwendet aus den Trainingsdaten, um die Parameter des Klassifikators zu optimieren.
Test – Der Testdatensatz ist ein Satz unsichtbarer Daten, die lediglich dazu verwendet werden Bewerten Sie die Leistung eines vollständig bewerteten Klassifikators.
Sobald unsere Daten in diese drei Segmente (Training, Validierung, Test) können wir mit dem Trainingsprozess beginnen.
In Ihrem Datensatz wird der Trainingssatz zum Aufbau des ML-Modells verwendet. während der Validierungssatz zur Validierung des von Ihnen erstellten ML-Modells verwendet wird. Datenpunkte in diesem Trainingssatz sind nicht im Validierungssatz enthalten. Sie werden feststellen, dass in den meisten Fällen ein Datensatz in ein Training unterteilt wird Set und Validierungsset (oder ein Testset, wie manche Leute es bevorzugen). stattdessen) in jeder Iteration des Modells – oder in einen Trainingssatz, Validierungssatz und Testsatz für jede Iteration.
Das ML-Modell kann jede der in Schritt 3 beschriebenen Methoden verwenden. Einmal Nachdem das Modell trainiert wurde, können wir in der Reihenfolge dasselbe trainierte Modell verwenden um die unsichtbaren Daten vorherzusagen. Danach kann es zu einer Verwirrung kommen Matrix, die uns sagen würde, wie gut wir unser Modell trainiert haben.
Eine Verwirrungsmatrix weist vier Parameter auf:
Wirklich positiv
Echte Negative
Fehlalarm
Falsche Negative
Hier finden Sie jeweils eine kurze Beschreibung:
Echte Positive – Fälle, in denen wir das Wahre und das Vorhergesagte vorhergesagt haben Die Ausgabe ist korrekt.
Echte Negative – Fälle, in denen wir falsch und das vorhergesagte vorhergesagt haben Die Ausgabe ist korrekt.
Falsch positive Ergebnisse – Fälle, in denen unsere Vorhersage wahr war, die Vorhersage aber stimmte Die Ausgabe ist falsch.
Falsch-negative Ergebnisse – Fälle, in denen wir falsch vorhergesagt haben, aber das Vorhergesagte Die Ausgabe ist wahr.
Unser Ziel sollte es sein, möglichst viele Werte als echte Positive zu erhalten und echte Negative , um ein möglichst genaues Modell zu erhalten. Die Größe Ihrer Verwirrungsmatrix hängt von der Gesamtsumme ab wie viele Klassen es gibt.
Die Genauigkeit Ihres Modells kann auch durch die Verwirrungsmatrix bestimmt werden bestimmt durch diese Formel:
Echte Positive + Wahre Negative dividiert durch die Gesamtzahl der Klassen = Genauigkeit (Prozent)
Die Modellbewertung ist ein entscheidender Teil des maschinellen Lernworkflows Prozess, da er Ihnen dabei hilft, das beste Modell zu finden, das Sie repräsentiert Daten und wie gut das von Ihnen gewählte Modell in Zukunft funktionieren wird.
Um unser Modell zu verbessern, sollten wir die Hyperparameter optimieren und verbessern Genauigkeit. Zusätzlich sollten wir die Verwirrungsmatrix nutzen, um zu erhöhen die gesamten wahren Positiven und wahren Negativen .
Beim Trainieren Ihres ML-Modells und beim Verbessern Ihres maschinellen Lernworkflows oder Workflow mit künstlicher Intelligenz sollten Sie ebenfalls kennen wie die NLP-Pipeline (Natural Language Processing) funktioniert.
Eine Pipeline zur Verarbeitung natürlicher Sprache umfasst eine Reihe von Schritten, die Hilfe bei der Umwandlung von Rohdaten in eine ausgewählte Ausgabe – z. B. eine Antwort, Zusammenfassung oder Etikett.
Jeder Schritt in der NLP-Pipeline führt eine hochspezifische Funktion aus, z B. Lemmatisierung, Erkennung benannter Entitäten, semantische Analyse oder Tokenisierung.
Der Workflow zur Verarbeitung natürlicher Sprache beschreibt den Satz von Regeln und Prozesse, die zur Ausführung, Verwaltung und Überwachung verwendet werden Pipeline in Bezug auf eine der oben genannten Funktionen.
Daher ist es künstlich, wenn Sie mit ML-Modelltraining arbeiten Intelligence-Workflows und Machine-Learning-Workflows, dann sollten Sie das tun Machen Sie sich mit den Pipelines für die Verarbeitung natürlicher Sprache vertraut Arbeitsabläufe sind. Befolgen Sie einen klaren und konsistenten Arbeitsablauf und Pipeline, und Sie können darauf wetten, dass Ihre Daten vollständig standardisiert werden, sauber und bereit für die Analyse.
Als erfahrene NLP-Berater können wir Sie in allen Belangen unterstützen Pipelines und Workflows für die Verarbeitung natürlicher Sprache, egal was beabsichtigte Verwendung oder Anwendung.
Je besser Sie Ihren Workflow für maschinelles Lernen definieren können, desto besser Für den Workflow mit künstlicher Intelligenz gibt es viele Best Practices, die Sie anwenden können Befolgen Sie die folgenden Schritte, um sicherzustellen, dass Sie das gewünschte Ergebnis erzielen:
Das Definieren von Projektzielen ist wichtig, da es sicherstellt, dass Ihre ML-Modelle einen Mehrwert bieten Wert für einen Prozess und nicht Redundanz. Versuchen Sie, Ihre Rollen zu verstehen Möchten Sie, dass Ihr Modell die möglicherweise bestehenden Einschränkungen erfüllt? Umsetzung und die Kriterien, die sie erfüllen oder übertreffen muss.
Bewerten Sie die Prozesse, auf denen Ihre Daten basieren, wie sie erfasst werden und welche Umfang der Daten. Dies wird Ihnen helfen, die spezifischen Datentypen zu bestimmen und Datenpunkte, die Sie benötigen, um Vorhersagen zu treffen.
Forschen und experimentieren Sie!
Die gesamte Prämisse der Implementierung künstlicher Intelligenz-Workflows, Arbeitsabläufe für maschinelles Lernen und das Verstehen natürlicher Sprache Verarbeitungspipelines – soll die Genauigkeit und Effizienz verbessern Ihr aktueller Modelltrainingsprozess.
Bevor Sie also einen Ansatz umsetzen, sollten Sie sich vielleicht damit befassen, wie andere Teams vorgehen ähnliche Projekte umgesetzt. Experimentieren Sie auf jeden Fall mit dem Vorhandenen oder einen neuen Ansatz, und trainieren und testen Sie dann Ihr Modell ausgiebig.
Während Sie Ihren Ansatz entwickeln, wird Ihr Endergebnis ein „Proof of“ sein Konzept', mehr oder weniger. Aber dieser Beweis muss in a übersetzt werden funktionelles Produkt, das durch die Schaffung einer Maschine erreicht werden kann Lern-API, A/B-Tests und benutzerfreundliche Dokumentation enthalten den Code, die Methoden und die Art und Weise, wie das Modell verwendet wird.
Benötigen Sie weitere Anleitungen zu den Schritten, die wir auf der Maschine besprochen haben? Lernabläufe? Unsere Datenanalysten stehen Ihnen jederzeit zur Verfügung Einblicke und Beratung entsprechend Ihren Geschäftszielen.
Stichworte
Arbeitsablauf für maschinelles Lernen
Workflow für künstliche Intelligenz
Pipeline zur Verarbeitung natürlicher Sprache
Wir besprechen alle Schritte eines effizienten maschinellen Lernens Workflow zusammen mit dem Verständnis der Bedeutung Ihrer natürlichen Sprachverarbeitungspipeline.
Tauchen Sie ein in die Welt der Natürlichen Sprachverarbeitung! Entdecken Sie modernste NLP-Rollen, die zu Ihren Fähigkeiten und Leidenschaften passen.
NLP-Jobs entdecken
Mittlerweile sind es Organisationen aller Größenordnungen und fast aller Sektoren werden zunehmend datengesteuert, insbesondere als größere Datenspeicher Systeme und schnellere Computer treiben die Leistungsgrenzen immer weiter voran.

Aufgrund des umfangreichen Einsatzes von Technologie und der Arbeitsteilung hat die Arbeit des durchschnittlichen Gig-Economy-Arbeiters jeden individuellen Charakter und damit auch jeden Charme für den Arbeitnehmer verloren.
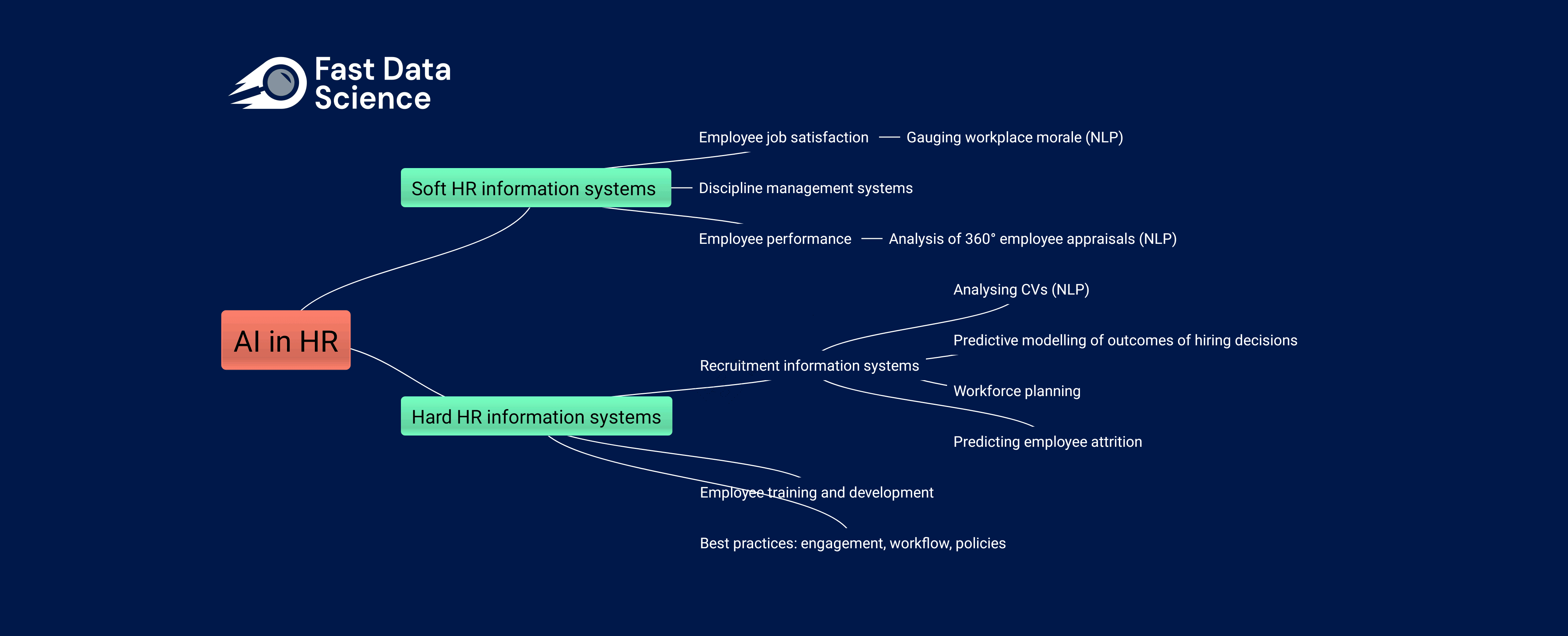
Die Auswirkungen von KI auf die Humanressourcen Die Arbeitswelt verändert sich rasant, sowohl aufgrund der Einführung traditioneller Data-Science-Praktiken in immer mehr Unternehmen als auch aufgrund der zunehmenden Beliebtheit generativer KI-Tools wie ChatGPT und Googles BARD bei nicht-technischen Arbeitnehmern.
What we can do for you