Fast Data Science is a specialist NLP and data science consultancy based in London. We are a small company and we take on consulting engagements from clients around the world in many industries. We also have a flagship product, the Clinical Trial Risk Tool, which is a software-as-a-service (SaaS) product which analyses clinical trials.
We help companies extract structured information from unstructured datasets. These are often PDFs or other documents in natural languages but could be a client database.
Clients hire us to take on difficult NLP, AI, or data science tasks which they may not have the in-house capacity or specialism to handle.

For example, if your business has a problem with customer or employee attrition, Fast Data Science can analyse your CRM and identify factors which can help us to predict which customers or employees are about to churn - before it happens!
Another example is in the pharmaceutical space. Drug trials generate large amounts of unstructured text documents, such as PDFs. A lot of this documentation needs to be made public by law (e.g. for the regulatory body in the country in question). The problem is that the PDFs contain personal healthcare information (PHI) as well as commercially sensitive data. It is time consuming to manually redact all of this data from the documents. For one client we have developed a machine learning model which identifies the data that needs to be redacted and sanitises the PDF.

You can try some of the products we’ve developed:
The easiest way is on our contact form or by phoning us on +44 20 3488 5740.
Sorry, we don’t have any vacancies at the moment. Please follow our page on LinkedIn or X in case something comes up in future:
Unfortunately we don’t have any capacity for internships, but if you would like to get involved in data science we have the Harmony project https://harmonydata.ac.uk/ which is open source and we’re always happy to have more people involved in developing it.
Feel free to send us a resume/CV. Unfortunately we’re not hiring right now. Please follow us in case something comes up in future:
We would be glad to help with your academic project. We have favourable rates for clients in academia. Please get in touch and we can discuss. You can check out all of our publications under https://fastdatascience.com/ai-in-research/publications-and-patents/
Recent publications include:
McElroy, E., Wood, T., Bond, R. et al. Using natural language processing to facilitate the harmonisation of mental health questionnaires: a validation study using real-world data. BMC Psychiatry 24, 530 (2024). https://doi.org/10.1186/s12888-024-05954-2
Marton Ribary, Thomas Wood, Miklos Orban, Eugenio Vaccari, Paul Krause, A generative AI-based legal advice tool for small businesses in distress. Journal of International and Comparative Law, Vol 12.2, 2025.
McElroy, E., Moltrecht, B., Scopel Hoffmann, M., Wood, T. A., & Ploubidis, G. (2023, January 6). Harmony – A global platform for contextual harmonisation, translation and cooperation in mental health research. Retrieved from osf.io/bct6k (submitted for publication)
Ribary, M., Krause, P., Orban, M., Vaccari, E., Wood, T.A., Prompt Engineering and Provision of Context in Domain Specific Use of GPT, Frontiers in Artificial Intelligence and Applications 379: Legal Knowledge and Information Systems, 2023. https://doi.org/10.3233/FAIA230979
Moltrecht, B., Wood, TA., Scopel Hoffmann, M., McElroy, E., Harmony: a web-tool for retrospective, multilingual harmonisation of questionnaire items using natural language processing. Retrieved from https://psyarxiv.com/zvqbf/ (submitted for publication)
Wood, TA., McNair, D., Clinical Trial Risk Tool: software application using natural language processing to identify the risk of trial uninformativeness [version 1; peer review: awaiting peer review], Gates Open Research 2023, 7:56.
We use Google Analytics but do not hold any identifying information if you have visited the website. You can read more on our Privacy Policy page.
We use Python, Scikit-Learn, Plotly Dash, TensorFlow, spaCy, NLTK, and other AI, machine learning and NLP libraries primarily in the Python ecosystem, however we can work with whichever software our clients need. We can use large language models via APIs such as OpenAI and Gemini, and we have also fine-tuned our own models. We are not tied to any particular cloud provider and we work with all major cloud computing platforms as well as on-premises servers. We work preferentially in Microsoft Azure and we are in the Microsoft Partner Network but we can also work in AWS, Google Cloud, or any other platform.
We would like to hear from you. We work for all sectors - commercial, non-profit, and public, as well as a number of academic engagements. If you are in a non-profit or in academia, we understand that commercial fees may be unworkable and we are prepared to work at a discount. We also appreciate any opportunities to publish in academic journals.
The Director of the company, Thomas Wood, does most of the consulting work, but other experts work with us on a per-project basis. Check out the team info page for more information.
The Director of Fast Data Science is Thomas Wood, who does most of the consulting work, but other experts work with us on a per-project basis.

You can reach Thomas on LinkedIn here: https://www.linkedin.com/in/woodthom/
We can definitely help with a predictive modelling project. We have built a number of predictive models of this kind for companies based on their internal data, which could be contained in a CRM or incident list. We worked for the Office of Rail and Road (UK rail regulator) on predictive modelling on datasets of all rail incidents (e.g. vehicle striking bridge, flooding, etc), and we also worked for Tarion, the Canadian housing regulator on a similar predictive model for housing defects, e.g. electrical, drywall, etc. We’ve also done a number of customer and employee churn projects, e.g. for the National Health Service. You may also be interested in this tool which de-risks a clinical trial: https://clinicaltrialrisk.org/
For example, we could put together a simple score on a scale 0-100 which you could work out with pencil and paper, which would predict the likelihood of an incident occurring in the next month. The machine learning models that we develop can be made completely explainable. It’s a positive that you have several years of data in your CRM, which should be enough to work with.
We think there is huge value in developing very simple machine learning models, even scoring models which can be worked out with pen and paper. Check out our blog post on formulas vs intuition for more details.
We work on a fixed fee basis, as this is usually what our clients prefer. We can also work on a daily rate, but in practice clients have only wanted this once we have done some work for them initially and we are moving to a retainer engagement.
We recommend checking your data science consultant has the following:
Deep domain expertise - are they familiar with your industry? Do they know the difference between a “clinical trial phase” and a “marketing phase”? Or a “protocol” and a “prototype”? A generalist will treat all text data the same while a specialist knows that medical text requires specific Named Entity Recognition (NER) such as the tools and libraries developed by Fast Data Science.
Proven MLOps capabilities. The consultancy should be able to demonstrate that they have successfully brought projects through to deployment. Inexperienced consultants will often deliver a “notebook” (a static analysis) that gathers dust. They may make models that will run only on their laptop and then consider the job done. Or they might evaluate a model in an entirely inappropriate setting, which doesn’t correspond to real-life usage, and then give you inflated accuracy figures. Fast Data Science has deployed a number of data science projects which are publicly visible (https://harmonydata.ac.uk/search, https://clinicaltrialrisk.org/).
Transparency and explainability. Look for a consultant who can explain the models that they develop. Explainable models are less prone to bias. The consultant should be familiar with techniques like SHAP or LIME for explaining model outputs. The consultant should have a formal process for checking datasets for demographic or historical bias. The consultant should start with very similar linear models, such as a score between 0 and 100 which can be worked out on pen and paper, before trying to hard sell you neural networks. We have seen far too many projects where the in-house data science team, or a previous consultancy, built a ridiculously complicated neural network which nobody understands, and left the client no better off than before they started.
Understanding of your business problem, before trying to talk about tools. Lots of consultancies may try to sell you a “Generative AI” solution before they’ve even seen your data or understood what your business needs. A good consultant should start by talking to all relevant stakeholders, which could be the VPs of every division, to understand what the AI needs to do and how it will impact your business’s bottom line and KPIs. Consultants are business people first, and technologists second. Sometimes the best solution isn’t to throw generative AI at everything. You might be fine with a simple yet intuitive regression formula. A trustworthy data science consultant will tell you when you don’t need expensive AI.
Proven IP and case studies. Check out the consultant’s past engagements and look for case studies that mention ROI. (e.g., “Reduced document processing time by 40%” or “Increased clinical trial failure prediction by 15%”). Also check their GitHub account (https://github.com/fastdatascience/). Consultancies that contribute to the community (like Fast Data Science does with clinical tools) usually have a much deeper grasp of the underlying technology as well as the needs of people in your field.
Reasonable scoping of costs and timelines. Your consultant should be able to give you a quote after a couple of meetings and having a cursory look at your data. If they can’t commit to a fixed cost or time scale, how do you know the costs won’t run out of control? At Fast Data Science, we always give a few options of fixed costs, which also works better with many organisations’ accounting processes such as purchase orders (POs). This means we’re incentivised to work efficiently and deliver something useful. We have a lot of repeat customers and long term retainer agreements as well, as we like to keep a long term relationship with our clients.
Watch out for the following red flags:

We would be very glad to assist. The director, Thomas Wood, has spoken and presented at a number of academic and industry conferences, which you can find under https://fastdatascience.com/blog/events/. Please get in touch and let us know the details.
We recommend to find a consultancy which will charge you a fixed cost for the entire job. Many consultants will charge per hour, but at Fast Data Science we prefer to offer our clients a fixed cost. That means, we define the outcomes of the project and any milestones, and agree on a price. This incentivises us to work efficiently. Please read this blog post for more information about pricing. In general the lowest priced project that we would take on would be a proof of concept and this would be subject to a minimum charge. This could later lead to a full-scale deployed production system which would have a higher fee.
Yes, we can develop and deploy apps in Python, R, or any other technology that you need. Please check out the Harmony R library for an example of an open source R library for data science (exposing LLM functionality) which we have developed.
Certainly. This is a technical due diligence engagement. If a venture capital or private equity firm is looking to invest in or buy a startup, they need to know if the software is built on a solid foundation or if it’s held together by duct tape.
We have a tried and tested AI due diligence process and checklist and if you contact us, we will happily show you redacted and anonymised reports from past tech due diligence engagements which resulted in successful mergers and acquisitions.
This is a form of due diligence (see the answer above), since the models are already developed and we need to check them over. First we would need to understand why underwriting is needed. Is it for regulatory purposes, such as the FCA? In any case please get in touch and we will happily discuss your needs.
Certainly. Quite often, we come in on a project once the client has already attempted something in-house. In fact, this helps us to know what you have tried and what did and didn’t work. Please give us a call and we can discuss.
You can speak to a data scientist. For example, if you contact Thomas Wood at Fast Data Science you can discuss your article. Thomas Wood has been interviewed by the BBC and also some trade magazines such as Commercial Dispute Resolution.
There isn’t one single answer. Every blog post you find on our website generally has references at the bottom and links to external website. If something isn’t in a reference it could be from our own discovery work or experience or experimentation.
For example, let’s take this recent blog post as an example:
https://fastdatascience.com/ai-for-business/ai-generated-text/
It discusses the Wikipedia guide for identifying AI generated text (https://en.wikipedia.org/wiki/Wikipedia:Signs_of_AI_writing) and then goes into more detail about the experiments which we conducted.
So you could say some of this is opinion, some of it is original research and some is citing other people. We have tried to use as many reliable citations as possible.
Another thing that hopefully gives credibility is our list of publications, which have been published in peer-reviewed journals:
https://fastdatascience.com/ai-in-research/publications-and-patents/
Some of our articles got picked up by other publications. For example, the New York Times has quoted us: https://www.nytimes.com/2025/05/14/technology/ai-jobs-radiologists-mayo-clinic.html - they cited this article: https://fastdatascience.com/ai-in-healthcare/ai-replace-radiologists-doctors-lawyers-writers-engineers/.
Yes, we are prepared to enter into partnership agreements like this. Please get in touch with Fast Data Science (https://fastdatascience.com) to discuss the specifics.
This is a complex recommender system or predictive modelling task. Please get in touch to discuss.
Every project is so unique, so we would not be able to give a fixed cost on the website. However, if you can get in touch with specifics of your project, we can come back with a cost estimate.
Thank you. We are keen to submit a proposal. Please send us the RFP.
We are happy to help with grant writing and applications in public sector procurement. We have led or been co-grant writers on several successful grants such as Wellcome Trust, the Gates Foundation, and UKRI. We can work on the technical section of the application or be involved in whichever way improves the chances of success. Please get in touch.
We keep a test or validation dataset separate from any data that was used to train or develop our models. At the start of a project we will define a scoring metric, such as accuracy or AUC, which we can use to identify which models are performing well.
A model which is a binary classifier (e.g. put a document into two categories: HIV or TB) is best evaluated using a metric like AUC (Area under the ROC Curve) or plotting a ROC curve. Other metrics like accuracy, confusion matrices, and F1 score and precision and recall may be appropriate.
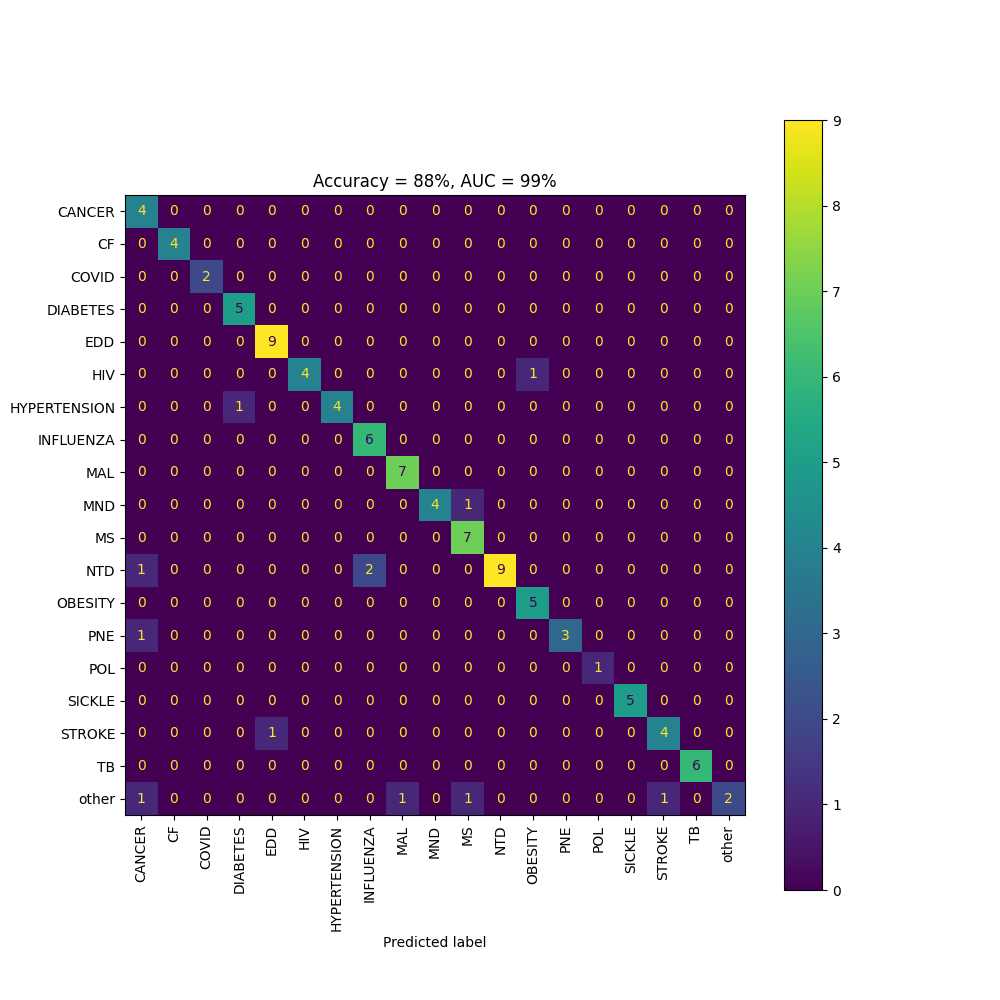
Above: a confusion matrix shows how many items in each class were correctly classified as the other class
At the start of a project we will use simple approaches such as rule based methods (expert systems) or small language models such as Naive Bayes, logistic regression, or linear regression. Before we go anywhere near neural networks, we need to set a baseline and understand what kind of score is acceptable. A neural network or large language model is only worth bothering with if it can beat the score of the simpler models.
We then progress and iteratively develop and train more and more sophisticated models, each time validating them against the same scoring metric.

We would expect to see the AUC and ROC curve (or whichever metric we chose) improving with time:
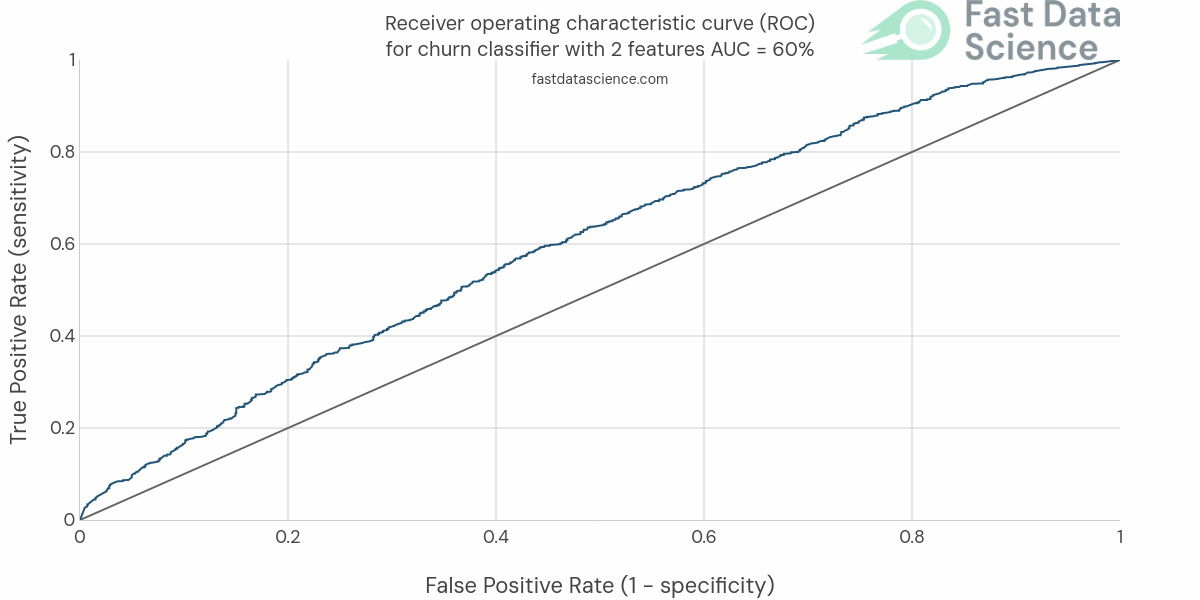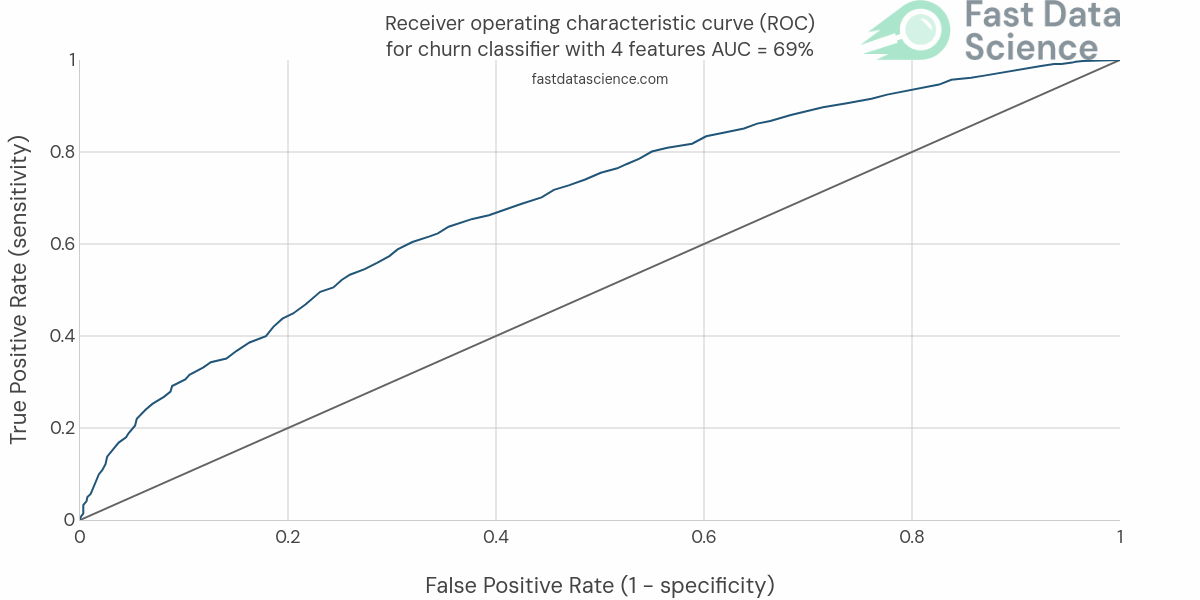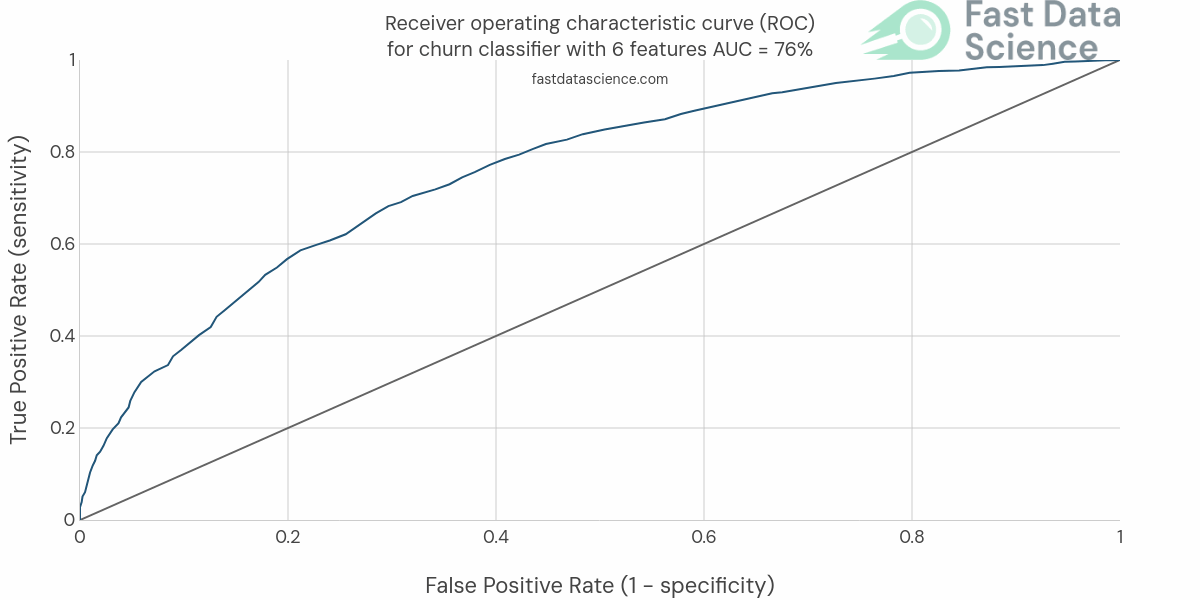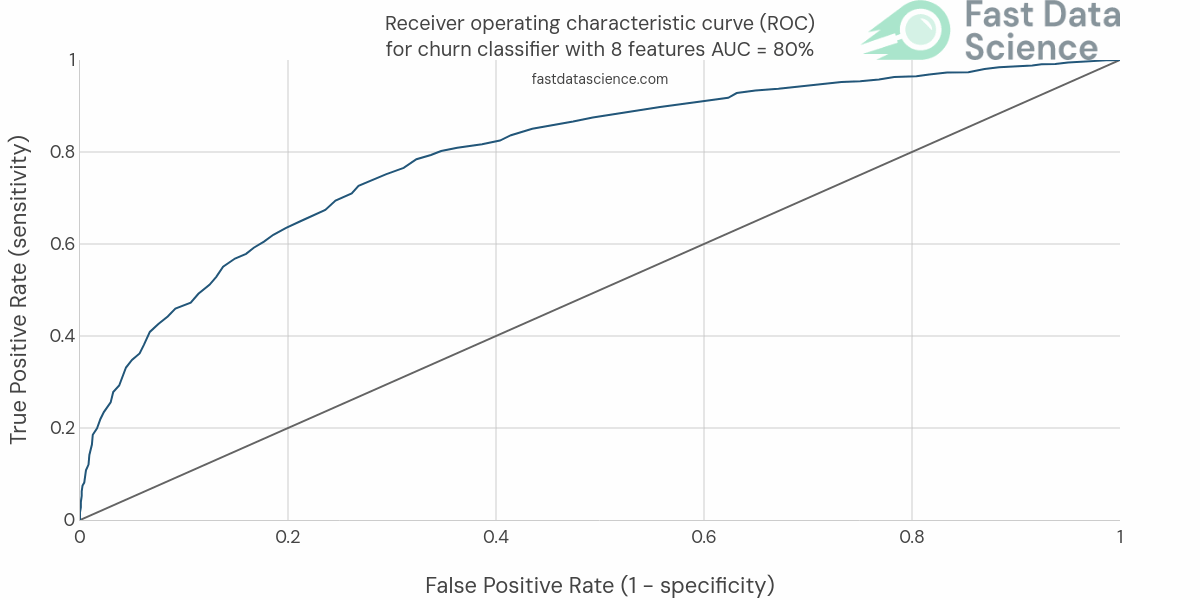
Check out this page which defines in detail how the accuracy is measured of all the models inside the Clinical Trial Risk Tool: https://clinicaltrialrisk.org/accuracy/
For generative AI models, we have devised a “mark scheme” which can be used to evaluate generated text: https://fastdatascience.com/generative-ai/how-can-we-evaluate-generative-language-models/
All our business operations comply with modern slavery and trafficking laws. Employees, subcontractors, freelancers and suppliers are paid a fair wage. We use low carbon footprint technologies where possible, and avoid LLMs unless there is no alternative. Business meetings are conducted remotely and all travel is by train if possible. Please check out our modern slavery statement and sustainability policy.
The hand over at the end of the project includes full documentation, code bases, and training and handover sessions to ensure that your internal team can manage whatever has been built longer term.
Fast Data Science is infrastructure agnostic. Whether you require a secure on-premise deployment for sensitive medical data or a scalable AWS/Azure/Google Cloud solution, we tailor the architecture to your security needs. We are not tied to any particular cloud provider.
Healthcare and pharma contain lots of opportunities for natural language processing, as large amounts of data, such as clinical trial reports or electronic health records are stored partly in text format. A lot of our projects involve PDFs so we have become adept at pulling structured information out of PDFs. A common ask is anonymisation: for some of our clients we are developing software to identify and automatically redact personally identifiable healthcare information (PHI) in clinical trial narrative reports. For another client, we are analysing electronic health records in HL7 format to identify if a patient can be included in a clinical trial (matches the inclusion criteria), or if a cancer should be reported to a registry. We have made open source libraries such as Drug Named Entity Recognition: https://github.com/fastdatascience/drug_named_entity_recognition which are used by research teams and commercial entities around the world.
If you have a project in healthcare that needs looking at, for example, a large amount of unstructured text in PDF format, please get in touch with Fast Data Science.
We take on consulting engagements where, e.g. there is a dispute over the authorship of a document. We would analyse all documents in question using forensic stylometry, which generates a ‘fingerprint’ of an author’s writing style. We could produce an expert witness report or expert advisor report according to what you require. Please contact us for a quote.
Certainly. We can set up a bespoke agentic chatbot which can answer questions and perform tasks for your business. Please check out the Insolvency Bot and peer-reviewed publications on dialogue systems, as well as our recent evaluation of 16 commercial LLMs. Please get in touch.
There may not be an exact off-the-shelf solution for this kind of problem. We have developed an NLP dashboard which lets you upload survey responses and visualise them, however in our experience, projects often need a bespoke analysis. We can use traditional NLP tools combined with the most up to date LLM solutions to find the information you are looking for in your meeting recordings. Check the above answer for more details.
Yes, in fact this is quite a common ask. The Clinical Trial Risk Tool reads a clinical trial document and identifies about 50 dichotomous variables, such as “does the trial involve an overnight stay”. In many ways dichotomous variables are simpler to work with, because it’s quite easy to get a high classifier performance.
A common need for this, is to identify e.g. if a new piece of legislation is related to your subject of interest and then classify its content. We have had queries about doing this on Acts in the UK, bills in the US, or even reports from the World Bank or World Health Organization.
In either case it would boil down to training a text classifier and evaluating its accuracy and ROC, then deploying it in a system where new documents are ingested and triaged as soon as they are produced.
It is possible to fine-tune your own large language model. We have provided a tutorial on how to fine tune a model for document similarity: https://fastdatascience.com/generative-ai/train-ai-fine-tune-ai/
However, in most cases, we would not recommend fine-tuning your own LLM. It is time consuming, and requires a lot of data. You are unlikely to have the resources to manually tag enough data for your LLM, so ideally you already possess that data.
Furthermore, the big tech offerings such as ChatGPT, DeepSeek, and Gemini, are improving so rapidly, that you’re unlikely to get an improvement in accuracy over the big players. Even if you do manage to improve this, your edge may disappear in a few months with the next release of an LLM.
If data privacy and sensitive data are your concern, we suggest you try self-hosting a large language model, or using Azure or AWS’s secure environments. You can even deploy models on Azure or AWS and remain GDPR and HIPAA compliant.
Some cases where it’s still worthwhile to train your own LLM are:
What we can do for you