
We have been taking on data science engagements for a number of years. Our main focus has always been textual data, so we have an arsenal of traditional natural language processing techniques to tackle any problem a client could throw at us.
In our consulting engagements, a company typically has a large amount of data and needs to bring in outside expertise to make sense of it all. For example, a pharmaceutical company may have a large number of plain text reports or PDFs containing sensitive data, or a clinical trial results set in PDF printout form, and they need somebody to generate insights from them. An insurance company may have a large volume of incoming claims and needs to have a triaging system developed (e.g. “does this claim have all supporting documentation?”), or a local council may want an email redirection system (emails about bins go to a person responsible for that area, while emails about tax go to a different department).
For non-text-based projects, this has sometimes been things like predicting conversion rates for offline marketing campaigns. For example, we have been asked to develop a model to output the optimal latitude and longitude and time to station a brand ambassador to hand out flyers.
Despite the hype around generative AI, a lot of our work has no need for it. The question is, what does the job well and to the client’s satisfaction. The simplest machine learning models have just one or two numbers in and can be calculated with a pen and paper. For example, we trained a machine learning model to predict a student’s academic outcome and this could be worked out by summing a few numbers to make a score between 0 and 100. The idea that you should always take the simplest model which does the job is often called Occam’s Razor.
I’ve put some examples below of the kinds of projects which other consultants, or sometimes the clients, are often keen to approach with generative AI, but where it would be overkill.
| Client | Task | Technical solution |
|---|---|---|
| Pharmaceutical company | Find all drugs mentioned in a clinical trial report | Use a dictionary approach with fuzzy matching such as the Drug Named Entity Recognition Python library. |
| Insurance company, or a company’s sales department | Triage insurance claims into high, medium and low priority. Or triage incoming leads into high probability of conversion (needing a sales rep’s immediate attention) versus low probability | Train a Naive Bayes text classifier to categorise documents into three groups |
| Local government | Triage incoming emails | Train a Naive Bayes text classifier to categorise messages according to which department they should go to |
| Offline marketer | Predict optimal locations and times to station brand ambassadors | Queries on database of past campaigns and conversions as well as a dataset of foot traffic gathered from mobile phone masts, and generalise to recommend new locations and times for future campaigns |
Recently, we have seen an increasing demand for generative AI consulting. This often involves leveraging traditional machine learning and combining it with generative AI to benefit from the strengths of both technologies.
Generative AI is famously very good at some things and very bad at others. For example, it often gets basic arithmetic questions wrong, and it’s capable of embarrassing hallucinations, such as when an English High Court judge recently admonished a solicitor for their over-zealous use of generative AI that resulted in fictional citations.
Generative AI can be expensive, often unpredictable, and it has a huge environmental impact. It provides little transparency as to how it reaches its decisions and it’s infamously obsequious, it’s verbose, and it never admits it doesn’t know something (at least at the time that I’m writing this - with the caveat that these technologies progress rapidly!). Its strengths lie in its ability to make sense of unstructured text and generate human-like output.
We have found that generative AI is great at making simple front ends where the application logic is in the back end. Small standalones and prototypes are great. However, AI generated computer code often contains extra bits of boilerplate that isn’t used at all, and is unnecessarily verbose. There are also serious issues around the potential that AI code tools have plagiarised projects where the licence does not permit this.
Here’s a brief summary of some of the main advantages and disadvantages of using generative AI rather than traditional machine learning and data science techniques.
| Pros of generative AI | Cons of generative AI |
|---|---|
| Generative AI models don’t need to be trained (since they have already been trained), so the development cycle is short | Gen AI cannot handle certain types of task well, such as basic arithmetic |
| Very robust with unexpected inputs or wordings, or when incoming document has an unusual structure | Generative AI can expensive to deploy at scale |
| Generative AI can create human-like output | Generative AI is much slower than simple arithmetic operations which would be used in a more traditional machine learning application |
| Generative AI is good at creative tasks, although it is debatable what counts as “creative”! | Generative AI often needs a third party service so it may rely on having a reliable internet connection. That third party’s server may be down, or the third party could change their API or suddenly increase prices. |
| It can be hard to interpret the decisions made by generative AI | |
| Generative AI is prone to hallucinations, such as inventing fake legal citations | |
| Generative AI has a large carbon footprint. A single query to a generative AI provider is estimated to emit between 2 and 3 grams of CO2 | |
| There are unresolved ethical questions about whether tech companies should be allowed to train generative AI models on the creative work of others, such as artists and content creators. |
| Pros of traditional machine learning | Cons of traditional machine learning |
|---|---|
| You can have very small model files. For example, a Naive Bayes text classifier, which can assign documents to categories, may be a few kilobytes | Development time is long, because you need training data which may not always be available. In the worst case, you would need to hand-tag training data |
| Simple machine learning models are very quick to run. The simplest machine learning models can run in a web browser or even be worked out on pen and paper or with a spreadsheet. | Training a machine learning model needs some software development and data science skills |
| Simple machine learning models are cheap to deploy. Very small language models can run on a serverless app such as Microsoft Azure Functions or AWS Lambda, which cost pennies even for relatively heavy use. | You will need to have a data science and data engineering team in order to get anywhere with machine learning in your business. This may be out of reach for smaller organisations and non-profits. |
| A simple machine learning model can run in an environment without an internet connection | |
| Simple machine learning models are often explainabe - you can work out why a decision was made, and even modify the model accordingly. | |
| We can make a machine learning model which is designed specifically for the task at hand, as opposed to taking very generalist models like a generative AI model and trying to use it for a very specialist task. |
Drag the features below onto the corresponding scale pan to see which technology 'outweighs' the other. Pros add weight, Cons subtract weight.
There is a middle way, which is to use both generative AI / LLMs and traditional machine learning models together in the same project, benefiting from the strengths of both of these. At Fast Data Science we regularly combine generative AI and simpler ML models in our generative AI consulting projects. In my experience, it’s quite rare that a generative AI consulting engagement would require a system to be developed and deployed using only generative AI and no other machine learning technologies or rule based system.
There are a number of ways that a generative AI consulting project could combine generative AI with traditional machine learning or rule based systems.
Above: an overview of how an LLM can be combined with a simpler machine learning model. The simplest way is to do it sequentially with the traditional model processing the input first, and the generative AI processing the output of the traditional machine learning model.
Gen AI consulting
For handling plain text, the main pre-generative AI approaches involve looking for keywords, or training machine learning models to categorise documents.
For example, if you want to find out if a clinical trial includes chemotherapy, a simple quick and dirty solution is to assemble a word list such as “chemotherapy”, “chemo”, and drug names such as “Paclitaxel”, and look for these in a document. This approach is very quick to implement but you may wish to validate it - for example, take a set of 10 randomly selected unseen documents, send them through your program, and check that your handwritten rule is not over-triggering. Assembling a word list often results in false positives. The keyword “chemotherapy” would be triggered by the sentence “This trial does not involve chemotherapy”, or by any mentions of the topic in the preface or references of a document.
The next most sophisticated approach to this problem would be to hand tag a number of documents, perhaps as few as 10 or 20, and mark them as 1 (trial includes chemotherapy) or 2 (trial does not include chemotherapy), and send them to a machine learning algorithm such as a Naive Bayes classifier, which will learn the most informative words and assign weights to them according to how strongly they indicate that the document falls in once class or the other.
Finally, we have neural networks which will learn to take the entire context of a sentence into account when categorising a document.
Finding information such as locating all dates in a document can usually be done with a series of patterns for all possible date formats. Finding things like drug-drug interactions (“Clinically significant drug interactions have been reported to occur when paclitaxel is administered with doxorubicin, cisplatin, or anticonvulsants (phenytoin, carbamazepine, and phenobarbital”[1], could be discovered by a dictionary based stage to identify drug names, combined with word matching on terms such as “interaction”. However this kind of approach is already pushing the limit of what we can do with rule based methods. Machine learning algorithms such as neural networks can be trained to pick out the interactions mentioned, but this now requires a huge amount of training data.
So, what if we used some of the approaches listed above in conjunction with generative AI? This is generally what I end up doing in most of our generative AI consulting engagements.
For example, we can use a rule based system to find key words in text, and if a key phrase is not found, generative AI can be called as a fallback.


Generative AI can be slow but it may not need to see the whole document that you’re processing. For example, a clinical trial protocol may run to 200 or 300 pages, which would put it over the limit of many generative AI systems, or even make generative AI prohibitively expensive.
For the Clinical Trial Risk Tool, we have been developing a system to find the schedule of events in a clinical trial protocol. The schedule of events is a table which tells you what procedures (e.g. blood test, MRI, chemotherapy) will take place on which dates (day 1, day 7, etc). It’s standard practice to put time (date) on the x axis in the table and the procedure names are on the y axis. Whenever an event takes place, it’s usually marked with an X in a cell in the table. Despite this standardisation, the schedule of events can be formatted in different ways in different companies. You can see an example below:
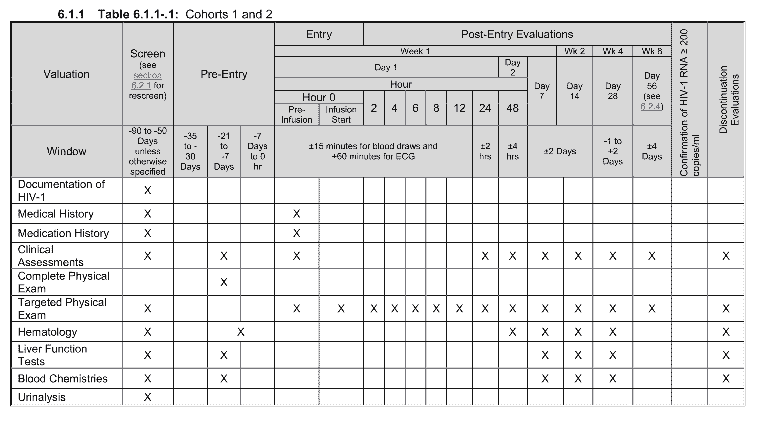
Above: an example schedule of events table. Source: https://clinicaltrials.gov/study/NCT01933594
The schedule of events is very information dense and for doing something like estimating the cost of running a clinical trial, you would need to get the information out and turn it into something structured.
It is not practical to send the entire 200-page PDF to OpenAI or another generative AI provider - processing speeds may be too long, the file may be over the limit, and above all it’s just a very inefficient use of the tool.
So we are using a Naive Bayes classifier to identify which pages contain the schedule of events. I hand-tagged 100 protocol PDFs and marked each page as 1 (contains the schedule of events) or 0 (does not contain the schedule of events). This is a very simple classifier, since it only has to make a two-way decision on each page, and it had a high degree of accuracy.
Then I set up a system so that the 20 pages with the highest score are taken from the PDF and reconstituted into a smaller 20-page PDF. This can now be sent to OpenAI with a smart prompt, and processed much faster, without incurring too much cost. Furthermore, since OpenAI is only receiving the most relevant pages to its task, it’s less likely to hallucinate.
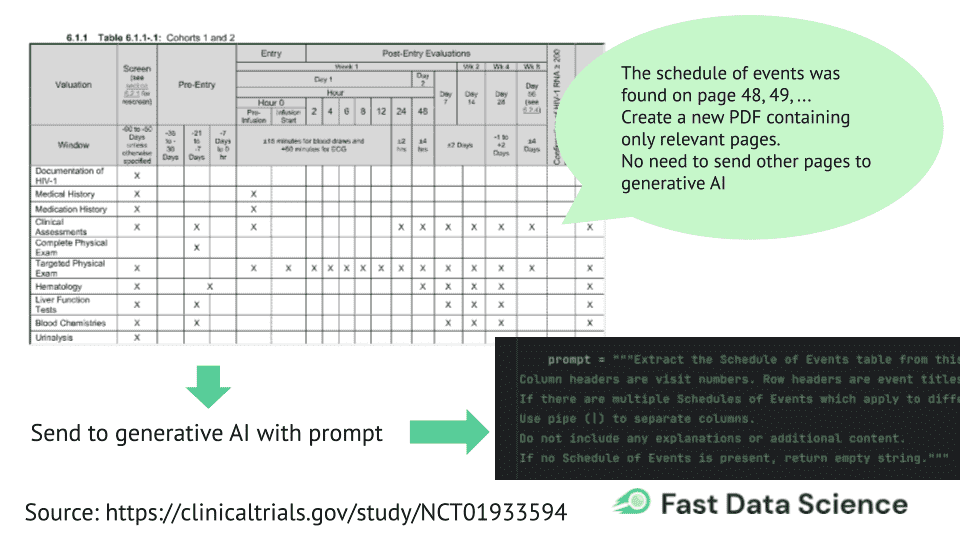
The end result is a system which is faster, cheaper and more reliable than sending a huge PDF to OpenAI.
We often want to use generative AI in a system but not get the generic ChatGPT response to a query, but rather to apply that query to a set of documents.
For example, in the Insolvency Bot project, we made a dataset of English and Welsh insolvency law (citations for statutes, cases and forms on HMRC’s website).[2] An incoming user query is matched to the most relevant sections of law, and an augmented query is made which combines the user’s question with extra information from the dataset. The end result is a significant improvement on the original (non-augmented) LLM, with fewer hallucinations and more relevant responses.

In theory, we could also use machine learning or a rule based system on the output from the generative AI. However, I have not yet seen this done in practice. The closest we come to this is using regular expressions to clean up the output of the generative AI, mainly for things like formatting (e.g. if we are prompting the LLM to output in JSON format, we may want to clean that output and ensure that the JSON format is correct). I would not usually do it this way round because the generative AI is the most unpredictable part of the entire pipeline, so it feels better from a development perspective to use any rule based or machine learning system before data goes to generative AI, rather than afterwards.
One huge advantage of using just generative AI in a consulting engagement is the speed of development and deployment. We can very quickly set up proofs of concept which can do amazing things with unstructured input such as PDFs. This is a useful approach if you just want to test if something is possible, and how it works as a user experience.
However, if a task or subtask could be done with something simpler than a large language model, I would recommend to replace the generative AI with the simpler alternative for that task. If your system must categorise documents daily into five categories, this can easily be done with a Naive Bayes model.
A number of people have asked me, can we use generative AI to do the tedious donkey work of data annotation? I have tried this a few times and generally I have been disappointed and I have not found it to be effective. The generative AI output is so unpredictable and messy, and it may fail to have the domain specific knowledge. Most of my text annotation tasks are not as simple as “classify this article into politics or sport”, but are much more complex and domain specific, such as “mark up all biopharmaceutical content in this page”. A generative AI may give an answer for this kind of problem but it is not always the right answer. Furthermore, I find that the process of hand tagging my data gives me huge insights into the problem and shapes my ideas around the machine learning model that I will use. So I think that for the moment, we don’t have a viable alternative to an expert human annotator.
Generative AI is a powerful tool, but it has not put us out of a job yet. Expert-built machine learning systems are often more reliable and accountable, as well as faster and cheaper. However, the combination of traditional machine learning or information retrieval with generative AI can deliver results for a client that combine the best of both worlds.
Baker, A. F., and R. T. Dorr. Drug interactions with the taxanes: clinical implications. Cancer treatment reviews 27.4 (2001): 221-233.
Ribary, Marton, et al. Prompt Engineering and Provision of Context in Domain Specific Use of GPT. Legal Knowledge and Information Systems. IOS Press, 2023. 305-310.
Dive into the world of Natural Language Processing! Explore cutting-edge NLP roles that match your skills and passions.
Explore NLP Jobs
Financial advisors, like lawyers, are regulated in the UK. All financial advisors should be registered with the Financial Conduct Authority (FCA) and must have certain qualifications and have signed up to a code of ethics. UK financial advisors must also complete professional training every year.

Which is the best AI for legal questions in 2026? We tested 16 Large Language Models (AIs) from the last two years on a law exam.

The effects of AI companies training on creative works When AI companies train models on text, video and images from creative industries, the end product is an AI model which can create near-human quality visual designs or copywriting. Many artists have argued the AI companies are exploiting creatives by profiting from their work, while the original creators do not receive any compensation. By flooding the market with low-cost content, AI has driven down rates for human artists, which is threatening creative careers.
What we can do for you