Fine tuning a large language model refers to taking a model that has already been developed, and training it on more data. It’s a way of leveraging the work that has already gone into developing the original model. Fine tuning is often used to adapt a generalist model for a more specific domain, such as mental health, legal, or healthcare, and in this case it’s also referred to as “transfer learning”.
Would you like to fine tune your own large language model (LLM) and help mental health research at the same time? Are you interested in generative AI, AI in mental health, and free and open source software? Are you interested in competing for a £500 voucher if you can train the most accurate LLM?
We are building a free online tool called Harmony to help researchers find similar questions across different psychology questionnaires. Harmony currently uses off-the-shelf LLMs from HuggingFace and OpenAI, but we would like to improve the tool with a custom-built (“fine-tuned”) LLM trained on psychology and mental health data.
The Harmony LLM training challenge is on DOXA AI’s platform and anyone can participate. You don’t need previous experience in LLMs. The goal is to train a large language model that can identify how similar different psychology questionnaire items are. The winner will be whoever trains the LLM with the lowest mean absolute error (MAE). Your challenge is to develop an improved algorithm for matching psychology survey questions that produces similarity ratings more closely aligned with those given by humans psychologists working in the field and that can be integrated into the Harmony tool. This competition will last approximately two months and finish early January.
Researchers are using Harmony to match questionnaire items and variables in datasets. For example, if social scientists in different studies have measured household income, and reported it in different ways (given their variable a different name), it can be hard to match them together. Harmony is a tool for item and data harmonisation and it will also help researchers discover datasets (e.g. “I want to find datasets measuring anxiety”). Matching variables in datasets has previously been a time consuming and fastidious process that may take a harmonisation committee several days. Large language models and vector embeddings are very good at handling semantic information, and Harmony will match sentences such as “I feel worried” and “Child often feels anxious” even where there are no key words in common, so a simple word matching approach (or Ctrl+F) would not match items correctly.
The mainstream large language models are generalist models which have been trained on text across domains (news, social media, books, etc). They perform well as a “jack of all trades” but often underperform in particular domains. Users of Harmony have often remarked that distinct mental health or psychology-specific concepts are often mistakenly grouped together by Harmony (false positives), and conversely, items which a human would consider to be equivalent are mistakenly separated by Harmony (false negatives).
As an example, see the below comment from a researcher on Harmony’s Discord channel:

We have found that items such as “child bullies others” and “child is often bullied”, or “I have trouble sleeping” and “I sleep very deeply” are mistakenly grouped together by Harmony, whereas to a human these are clearly distinct items and should not be conflated.
Of course, why would we expect a standard “vanilla” LLM to get this right?
A lawyer’s understanding of the word “consideration” is different from a layperson’s, and you often hear “bankruptcy” being used as a synonym for “insolvency” in everyday speech when they are most definitely not [1]! Because language has strong nuances in different domains, you can find domain-specific large language models on open source hubs such as HuggingFace and from commercial providers for domains as diverse as medical, legal, and finance. The popularity of fine tuning also extends to entire languages: groups such as the grassroots African NLP community Masakhane have taken the initiative to fine tune versions of LLMs for underrepresented languages such as Shona, Xhosa, or Nigerian Pidgin English.
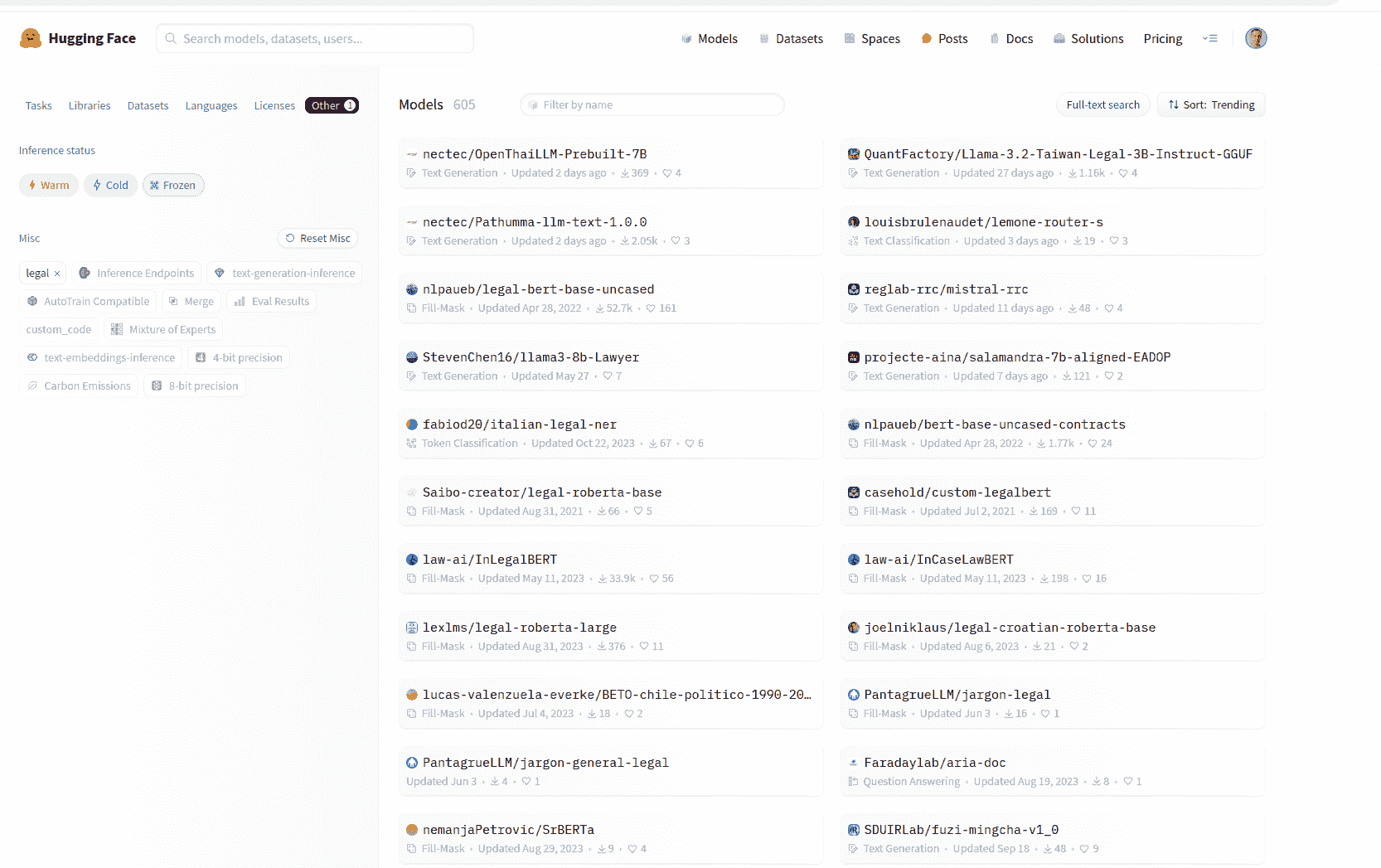
Above: HuggingFace Hub had 605 legal models at the time of writing this post
| Domain | Number of large language models fine tuned for this domain on HuggingFace (October 2024) |
|---|---|
| Medical | 1379 |
| Legal | 605 |
| Finance | 478 |
| Education | 50 |
| Psychology+Mental health | 27 |
You could conjecture that the mental health domain LLMs are far behind the other domains I tested, and it wouldn’t do any harm to have a purpose-built mental health/psychology LLM on HuggingFace Hub. In fact, if you win the challenge, yours could be the next fine-tuned LLM to appear on HuggingFace and increase the total to 28!
Fine tune your own model
You can get some traction by using the traditional “bag of words” method of comparing items. In fact I have evaluated this approach head-to-head against LLMs in this blog post. Unfortunately, matching similar words misses synonyms such as “sad” vs “depressed”, and completely falls over if the texts to be compared are in different languages.
You may have read about the colossal carbon emissions that ChatGPT and the like are responsible for. Big tech companies burn through the electricity needs of a small country to train a state-of-the-art generative AI model, and the future rollout of AI-powered search engines could consume 6.9–8.9 Wh per request[2], or enough electricity to run a 1W LED light bulb for nearly an hour, and 24 AI-powered Google queries could come close to lighting a room for a day.
So is the competition to fine tune Harmony going to burn through colossal amounts of energy?
Fortunately, there’s another way to do it, which is fine tuning. Most of the work has already been done in developing a large language model. LLMs, like other neural networks, consist of a series of layers which turn a messy unstructured input into something more manageable.
When we fine tune a large language model, we keep the main parts of it constant, and we adjust the weights of one or two layers at the end of the neural network to better fit our domain. There are a number of tutorials on HuggingFace showing how you can fine tune a text classifier starting from an existing model. In fact, you can fine tune an LLM on the Harmony DOXA AI challenge data in under half an hour on a Google Colab instance. I recommend reading this post on Datacamp for an explanation of the ins and outs of fine-tuning.
As mentioned above, the mass-market LLMs are very generalist tools. Fine tuning is a useful way that you can steer an LLM more towards a particular domain, such as the abovementioned medical, legal, finance, or psychology. Fine tuning is also referred to as “transfer learning”. In particular, the term “transfer learning” is used when a model that has been trained on one domain is re-purposed for a different domain with data from the new domain.
Alternatives to fine-tuning your LLM include:
To get started, visit the competition on DOXA AI’s website and try the tutorial notebook. An example is provided for a submission with an off-the-shelf LLM, and another notebook is provided as an example of fine-tuning of an LLM.
We have provided a training dataset, consisting of pairs of English-language sentences (sentence_1 and sentence_2), as well as a similarity rating between zero and one hundred (human_similarity) that is based on responses to a survey of human psychologists run by the Harmony project. The training data comes from a large number of human annotators who have marked their perception of which question items are equivalent.
You can follow the instructions on DOXA AI to submit your model and accompanying inference code. DOXA AI’s servers will execute your model and calculate the mean absolute error that your model scored, both on the training set and the unseen test data.
The contestant who submits the most accurate LLM according to our evaluation metric (MAE, or mean absolute error) on the unseen test data will win £500 in vouchers and there’s also a second prize of £250.
We hope that the result of this competition will be that Harmony will be more robust and better suited to mental health data, allowing researchers to harmonise and discover datasets more efficiently.
Harmony is a project where we are developing a free open-source online tool that uses Natural Language Processing to help researchers make better use of existing data from different studies by supporting them with the harmonisation of various measures and items used in different studies, as well as data discovery. Harmony is run as a collaboration between Ulster University, University College London, the Universidade Federal de Santa Maria, and Fast Data Science. Harmony has been funded by the Economic and Social Research Council (ESRC) and by Wellcome as part of the Wellcome Data Prize in Mental Health.
Ribary, Marton, et al. Prompt Engineering and Provision of Context in Domain Specific Use of GPT. Legal Knowledge and Information Systems. IOS Press, 2023. 305-310.
de Vries, Alex. The growing energy footprint of artificial intelligence. Joule 7.10 (2023): 2191-2194.
McElroy, Wood, Bond, Mulvenna, Shevlin, Ploubidis, Scopel Hoffmann, Moltrecht, Using natural language processing to facilitate the harmonisation of mental health questionnaires: a validation study using real-world data. BMC Psychiatry 24, 530 (2024), https://doi.org/10.1186/s12888-024-05954-2
Ravindran, Sandeep, Frustrated that AI tools rarely understand their native languages, thousands of African volunteers are taking action, Science, 2023 https://doi.org/10.1126/science.adj8519
Ready to take the next step in your NLP journey? Connect with top employers seeking talent in natural language processing. Discover your dream job!
Find Your Dream Job
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.

This is an article based on my presentation on “The Role of Artificial Intelligence in Expert Investigations and the Preparation of reports” which I gave at the Expert Witness Conference on 20 May 2026.

Many companies and organisations have large datasets that are stored in a very unstructured format. For example, you could work for a US based healthcare provider or insurer and have patient records stored in a free text format such as HL7 files or PDFs. A building regulator, land registry, or mortgage provider may have texts and accompanying diagrams from thousands of building inspections or land title deeds. A patent attorney’s office may have records of patent applications in PDF format.
What we can do for you