
Many companies and organisations have large datasets that are stored in a very unstructured format. For example, you could work for a US based healthcare provider or insurer and have patient records stored in a free text format such as HL7 files or PDFs. A building regulator, land registry, or mortgage provider may have texts and accompanying diagrams from thousands of building inspections or land title deeds. A patent attorney’s office may have records of patent applications in PDF format.
These text and image documents often contain a wealth of information which can be useful for analysis, identifying topics, and predictive modelling (e.g. predicting the likelihood of an insurance claim being accepted). However, in many organisations, large document collections sit unused, because it’s simply too hard to turn them into useful numbers and categories that we can handle.
A company’s analytics team is likely to be used to handling data and running reports on data with a nice structure, such as SQL databases, and using tools like PowerBI and Tableau they can make effective graphs and executive summaries for management. Your analytics team’s toolbox is great for structured data but won’t be enough for unstructured data.
You may have a raw text document which looks like this:
Pt presented on 26 may following recent complaints of lethargy and increased thirst over past three weeks. BP: 142/91
From context, we know that BP means “blood pressure”. So you might want to convert this to a table where all blood pressure measurements are in a tabular format.
| NHS Number | Date | bp_systolic | bp_diastolic |
|---|---|---|---|
| 4926348264 | 2026-05-26 | 142 | 91 |
Or you may want to code all symptoms and medications according to a system such as MeSH or ICD-O, e.g.:
| MeSH code | MeSH Heading | Value |
|---|---|---|
| D001794 | Blood Pressure | 142/91 |
| D053609 | Lethargy | - |
| D013894 | Thirst | - |
Or you may want a more complicated structured representation such as an XML or JSON format that incorporates the codes and values in a more hierarchical way rather than a flat tabular structure.
This depends what you are trying to achieve with your structured representation of the information.
In an ideal world, the data would have already been collected in a structured format, with input validation. If a doctor tried to enter a blood pressure of 14/91 instead of 142/91, it would be rejected at the point of entry because it doesn’t make sense (the first number must be larger than the second number).
However, the reality is that the most informative data is very often captured in free text fields and resides in systems long-term in unstructured formats. If doctors are entering medical notes without validation, this can result in noisy or corrupted data and so we may have to perform corrections or even reject text documents entirely if their content is entirely invalid.
There are two approaches that you can take if you want to use your unstructured data effectively:
Natural language processing
If you keep the unstructured data in its original form, you can work with it, safely assured that no information has been lost. You might work with the unprocessed raw unstructured data if:
You want to triage incoming emails to your company as “sales approaches” vs “potential leads” vs “jobseekers” vs “spam”. In this case, you can train a Naive Bayes classifier or other type of classifier on the text, and deploy it to your company’s servers. Now unseen emails can be correctly classified.
You want to identify if an insurance claim will be approved. You can connect up the texts of your past claims and train a predictive model to learn patterns typical of successful claims.
However, there are many cases where you would want to convert your data to a structured form before working with it further. For example,
The easiest way to convert unstructured data into a structured format is to use generative AI with a structured output format, such as OpenAI’s JSON format.
This means that you can use tools like ChatGPT, Gemini, or Claude, but instead of receiving a text response in plain English, which is the default behaviour of a generative AI chatbot, the large language model responds with a JSON schema, such as,
{
"variables_identified": [
{
"mesh_code": "D001794",
"mesh_heading": "Blood Pressure",
"value": {
"systolic": 142,
"diastolic": 91
}
},
{
"mesh_code": "D053609",
"mesh_heading": "Lethargy",
"value": null
}
]
}
A structured output is incredibly useful when you want to pass the data in your text document into a system that requires a fixed schema.
An example of when you might need to do this is, if you are making an AI agent for booking a flight, which needs to understand sentences like:
I want to fly from London to Athens on Monday at 5pm
Your AI agent must identify the origin airport, destination airport, date, and time from the user’s input, in order to send this to a booking system API. You could just do a simple string search, but the only way that a journey origin and destination are marked is by the context within a sentence.
To do this with OpenAI, you would define the properties of a Flight like this:
class Flight(BaseModel):
origin_iata: str
destination_iata: str
date_yyyymmdd_utc: str
time_hhmm_utc: str
from openai import OpenAI
from pydantic import BaseModel
client = OpenAI()
class Flight(BaseModel):
origin_iata: str
destination_iata: str
date_yyyymmdd_utc: str
time_hhmm_utc: str
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=[
{"role": "system", "content": "Extract the flight information."},
{
"role": "user",
"content": "I want to fly from London to Athens on Monday at 5pm",
},
],
text_format=Flight,
)
event = response.output_parsed
print (event.json())
The above code creates this structured output, which is stable enough to be parsed as JSON and could then be sent to an API, or converted into an Excel or CSV format, according to your needs.
Using the OpenAI structured outputs API, the sentence “I want to fly from London to Athens on Monday at 5pm” would be converted to:
{"origin_iata":"LON","destination_iata":"ATH","date_yyyymmdd_utc":"2023-10-16","time_hhmm_utc":"1600"}
You don’t have to use OpenAI exclusively for this approach. I have demonstrated how we can solve the problem with OpenAI, but other generative AI providers have an equivalent solution.
Below you can see a demo of this functionality for an economics modelling use case:
Analyse plain-text descriptions of economic scenarios and identify variables mentioned.
Results will appear here once you run the analysis.
Depending on the complexity of the structure that you want to extract, it may be possible to use traditional rule-based approaches or machine learning approaches to turn an unstructured text into a structured format. This has the huge advantage that your process is accountable and explainable. If a particular entity is not recognised, you can add it to the dictionary.
For example, if you want to recognise country names or drug names mentioned in a text, then a simple pattern matching will suffice, possibly with fuzzy matching (spelling error tolerance).
However, once you want to do anything more sophisticated than simply picking up mentions of locations, products, drugs, or companies, then you are limited in what you can achieve without generative AI.
As an example, take this text:
Nitroglycerin (prescribed for chest pain/angina) and PDE5 inhibitors (e.g., sildenafil/Viagra, tadalafil/Cialis) are known to interact negatively. Both of these medications work by dilating blood vessels. Taking them together causes an additive effect that can trigger severe hypotension and deprive vital organs of oxygen, causing fainting, a heart attack, or a stroke.
If you use a dictionary lookup and you have access to a database of common drug names and synonyms, you can easily identify all drugs that are mentioned. In fact, we have implemented an open source library to do just that, the Drug Named Entity Recognition Python library. You can try it below:
However, imagine that you want to identify if a text is discussing drug-drug interactions and what the side effects of each interaction are, and potentially match them to patient IDs. Simply finding the drug names in the text isn’t enough. You also can’t realistically make a list of all potential English words and sentence constructions that describe a drug-drug interaction - there are simply too many and you will always miss some out.
This example is where a hybrid approach is very effective. You could use a dictionary lookup (e.g. the Drug Named Entity Recogniser) to identify drugs and match them to IDs, and a structured JSON call to OpenAI, Gemini, Claude, or an alternative, in order to relate them to the nature of the interaction, patient types, and known adverse events. This way you get the best of both worlds: the dictionary lookup can guarantee you are mapping product or item names precisely how you want, while OpenAI handles the English syntax to extract relationships between entities.
If you would like help turning your unstructured datasets into structured data, please contact Fast Data Science to discuss your requirements.
Ready to take the next step in your NLP journey? Connect with top employers seeking talent in natural language processing. Discover your dream job!
Find Your Dream Job
Fast Data Science Ltd’s flagship AI platform, the Clinical Trial Risk Tool, has been accepted as a supplier on the UK Government’s G-Cloud 15 framework.

We are pleased to announce that Thomas Wood, director of Fast Data Science, will be appearing as a panelist at the Bond Solon Expert Witness Conference on 6 November 2026 at Church House, Westminster in London. This follows Thomas’s recent appearance at the Ireland’s Expert Witness Conference on 20 May 2026.
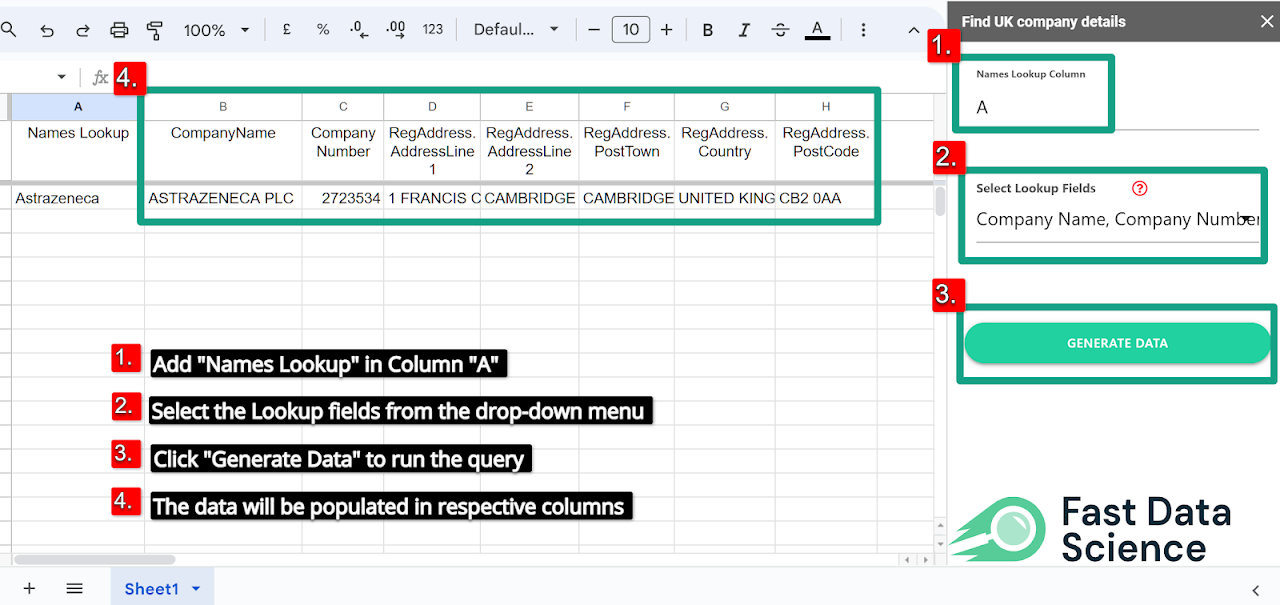
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.
What we can do for you