
Can symbolic AI, or machine learning, or hybrid AI (a mixture of the two), be used for legal reasoning?
I have been looking into the problem of legal reasoning with AI. Legal reasoning is the process of coming to a legal decision using factual information and information about the law, and it is one of the difficult problems within legal AI. While ML models and other practical applications of data science are the eaiser parts of AI strategy consulting, legal reasoning is a lot more tricky.
A judge uses legal reasoning to reach a logical conclusion, such as deciding whether a defendant is guilty or not.
To apply legal reasoning, a judge must identify the facts of a case, the question, the relevant legislation and any precedents (in common law jurisdictions).
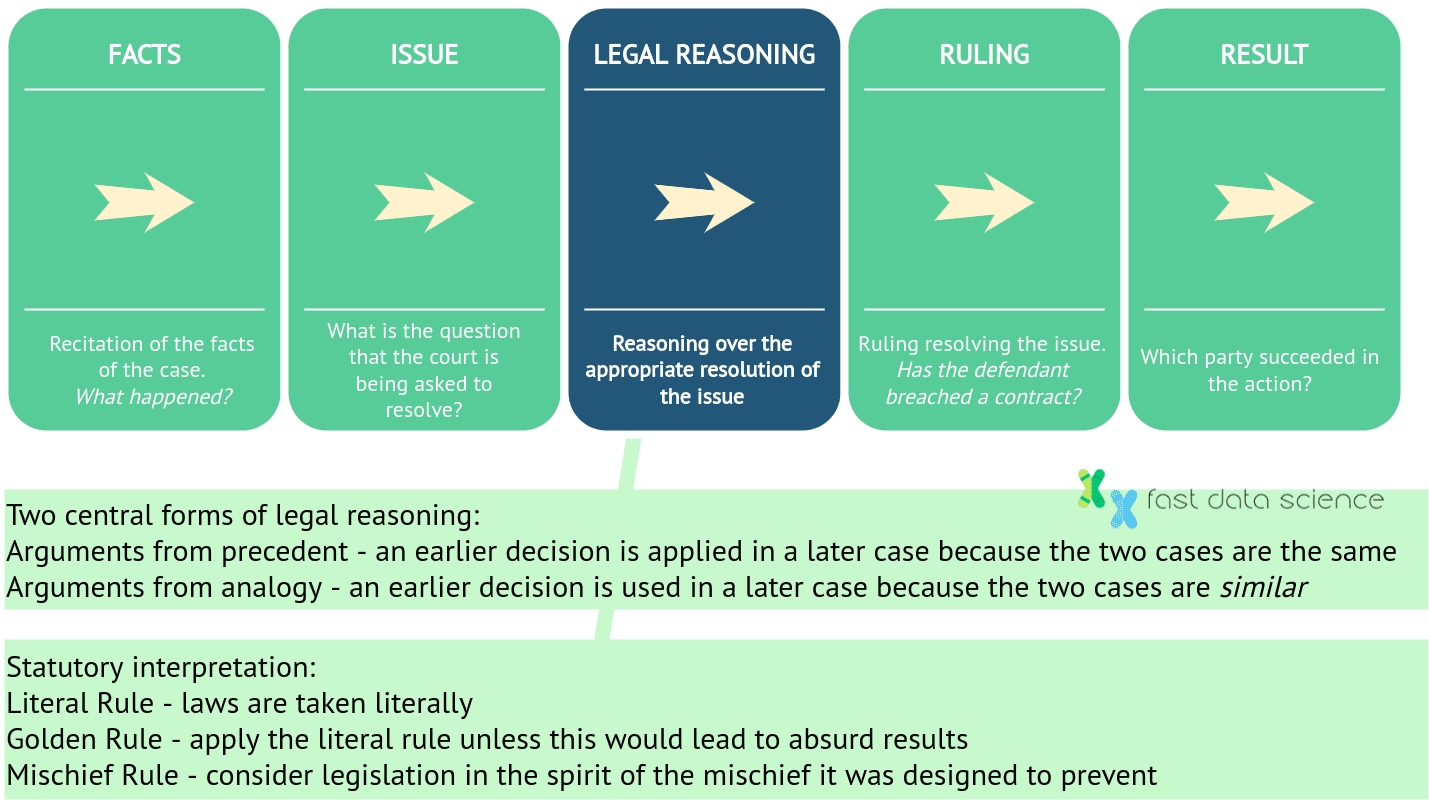
In common law systems like England and the US, a judgment has five steps: first the facts of the case must be established, the legal issue or question must be identified, and then legal reasoning is applied to the facts and question. Finally a ruling is given and the court decides on an outcome. Legal reasoning involves looking at previous cases as well as statute law. The question is, is either symbolic AI, machine learning, or hybrid AI (a mixture of the two) capable of legal reasoning?
Since the 1970s, AI researchers have been experimenting with symbolic AI for legal problems. Symbolic AI traditionally involved coding a representation of the real world into a computer using a logic programming language such as Lisp or Prolog.
Logical programming languages are languages that are good at representing concepts such as a cat is a mammal, all mammals produce milk, and inferring that therefore, a cat produces milk.
The above example can be expressed in Prolog as follows:

An example logic program in Prolog.
Nowadays, symbolic AI seems to have some more fallen out of favour somewhat. I have not seen many companies using symbolic AI for commercial use. In academia, symbolic AI is still a hot topic of interest. Data scientists in industry are usually using machine learning and predictive modelling techniques, which are powerful in areas where huge amounts of data are available, and data-driven approaches such as neural networks have come to dominate the field. On the other hand, symbolic AI often requires a huge manual effort to code the real world into a knowledge base, and can be hard to scale.
I will discuss some of the approaches that have been taken to legal AI over the years. For some tasks, hand-coded symbolic AI in Prolog has been popular, whereas where the task is simpler and the appropriate data has been available, researchers have trained machine learning models. When symbolic AI is combined with machine learning, this is often called hybrid AI. I will provide an overview of the two approaches in the next sections.
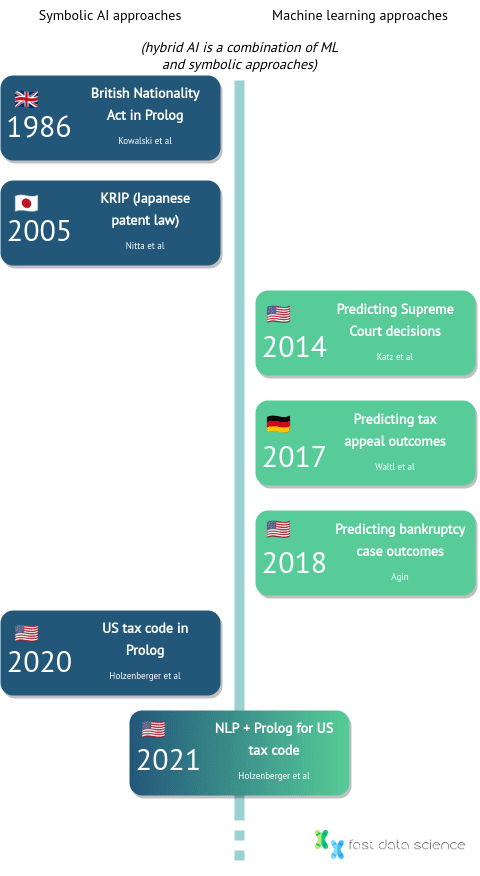
A timeline of the development of some key legal AI systems, from Kowalski’s British Nationality Act in 1986 through to the present day.
A number of researchers have been exploring the possibility of symbolic AI in law. One approach taken by some computer scientists is to represent a statute, such as an Act of Parliament, as a logic program, and convert the facts of a case into the same logic representation, and perform legal reasoning as a query in that logic language.
This seems to me to be simpler than attempting to model case law and simulate arguments from precedent or analogy computationally.
English law presents some particular challenges for legal NLP and legal AI models, when compared to civil law systems such as French law. Legal reasoning in English law involves intepretations of both statutes and past rulings, and identifying when to apply principles such as stare decisis (a past ruling is taken as authoritative). This is incredibly complex to code with symbolic AI.
English contracts tend to be extremely verbose. Despite this, English law is probably one of the most attractive legal systems to model with AI, since contracting parties often use England and Wales as their jurisdiction of choice, and disputes are regularly settled in London’s Commercial Court where neither litigant is based in the UK.
One of the seminal attempts to apply statutory reasoning is the American-British logician Robert Kowalski and others’ modelling of the British Nationality Act as a logic program, which was published in 1986. The team chose to focus on statute law because statutory law is “definitional in nature” and can be more easily translated into logic. They chose the British Nationality Act 1981 in particular, because it was laid out as a precise series of rules and was relatively self-contained - although it did contain some vague phrasings such as being a good character, having reasonable excuse, and having sufficient knowledge of English.
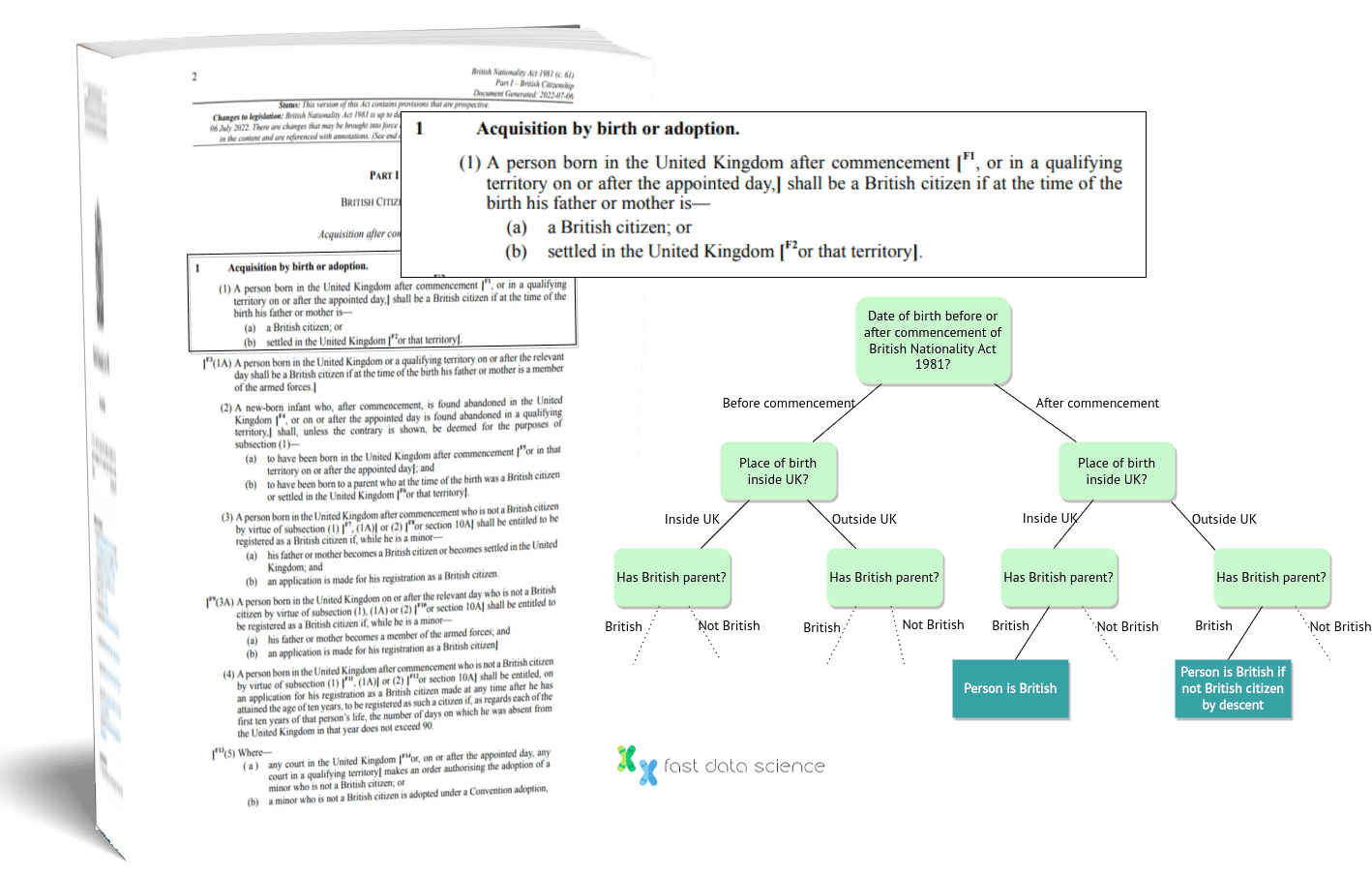
Schematic view of part of Robert Kowalski’s logical representation of the British Nationality Act.
Although Kowalski’s representation of the British Nationality Act was groundbreaking, it was not intended to be a fully functional system, and its limitations are obvious.
In 2005, Katsumi Nitta developed a system called KRIP which was an expert system for Japanese patent law. He used symbolic AI (predicate logic) to codify a limited section of law for a narrow domain (patent law) where the rules are relatively straightforward to put in a knowledge base.
In 2021, Nils Holzenberger at Johns Hopkins University, together with a larger research group, coded a section of the US tax code into Prolog. They created a system where where the user can ask questions like, if Mary was married in 2018 and earned $40,000 last year, how much tax should she pay?
Tax law is an interesting case because most problems have a simple unambiguous answer (how much tax must be paid?), and the rules are mostly laid down in statute (although lawyers can argue about the meanings of words).
Natural language processing
How the team approached the problem was first to manually translate statutes, and the facts of a case, into a logical representation in Prolog. You can move the slider below to see what a paragraph of the tax code looks like after it’s been translated into Prolog:

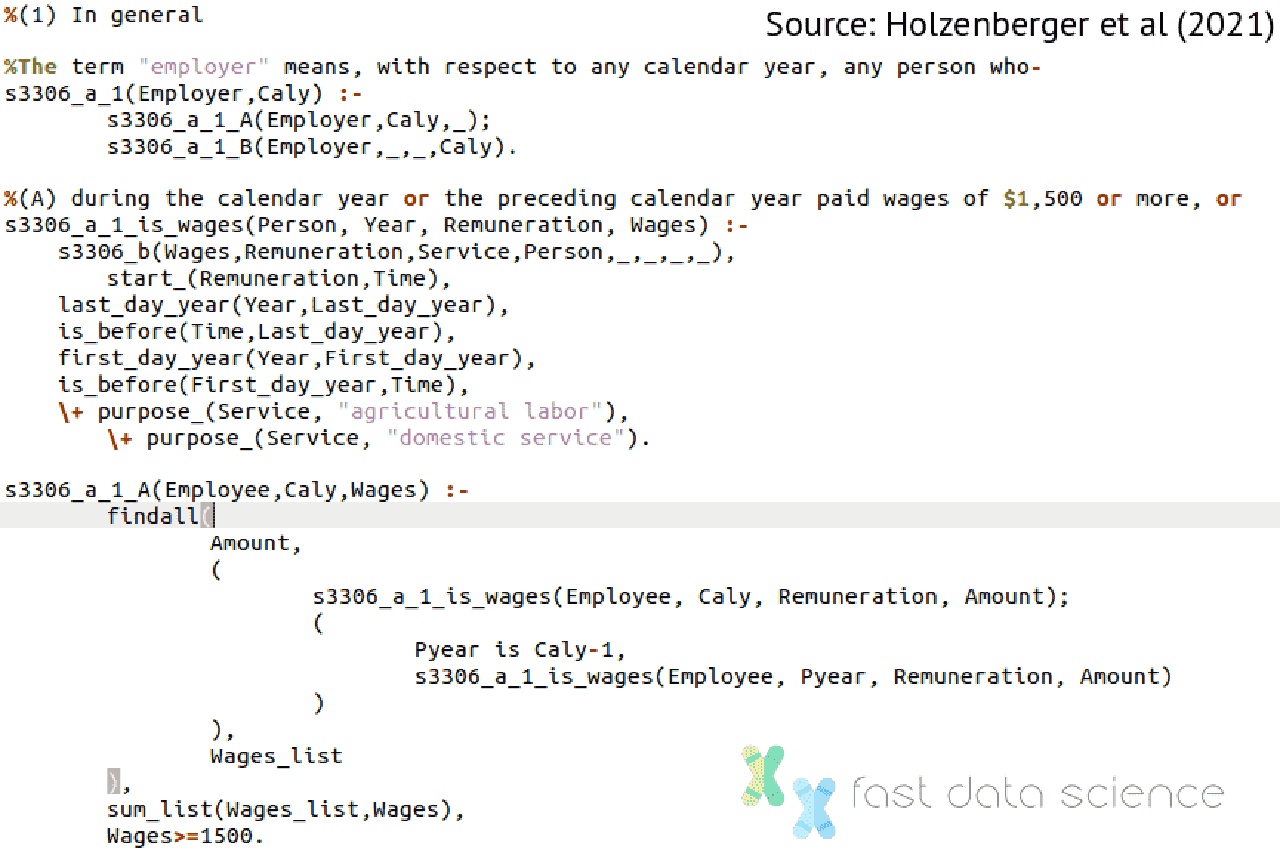
In this case, since the Prolog code was manually generated, the model had by definition 100% accuracy - provided of course that there are no bugs in the Prolog code.
However, the problem is that legal texts are not available in Prolog form, and it is difficult to translate everything to Prolog.
The team then experimented with NLP tools, such as transformers, to parse statutes and facts, and predict the tax owed as a regression problem, bypassing the Prolog representation.
Holzenberger’s team then tried breaking down the problem into several steps of language understanding, followed by a slot filling stage where variables (such as salary, spouse, residence) are populated with information for the specific case. This performed slightly better than the previous approach. However, they found that it was very difficult to parse the structure of a sentence because the wording can be so variable.
Moving away from logic programming, other researchers are using machine learning approaches in law. In 2014, Daniel Katz and his team at Illinois Tech trained a machine learning model to predict the decisions of Supreme Court Justices.
In Germany in 2017, Bernhard Waltl and other researchers at the Technical University of Munich trained a machine learning classifier on 5990 tax law appeals to use 11 features to predict the outcome of a new tax appeal.
In 2018, Warren Agin trained a machine learning model to predict success or failure in Chapter 13 bankruptcy cases, using features such as District Success Ratio (the bankruptcy success rate by location), the total unsecured non-priority debt, income/expense gap, and others, which was able to predict the outcome of a bankruptcy application with 70% accuracy and 71% AUC.
I believe that machine learning can work in the legal field where there are many analogous cases, such as tax judgments, bankruptcy applications, and family law outcomes. However, more general legal work which can need a complex analysis of statute and precedent would be very hard to solve with machine learning.
Although the US tax code is incredibly complex, it is still a question of interpreting statute and it can be coded into Prolog if you have enough patience.
What can we do if we have a legal problem which involves both statute and precedent, as is common in common law jurisdictions such as England and the USA?
In English law, there are a number of principles which judges can use to interpret statute. There is a literal rule, which says that legislation must be interpreted literally in the usual sense of the words. Judges also have the golden rule, which means that the wording of legislation should be interpreted literally unless this would lead to absurd implications. Finally, there is the mischief rule, which means that a judge should take into account which mischief a law was designed to prevent. These were developed at different points in history, resulting in the reasonable level of discretion which judges have today.
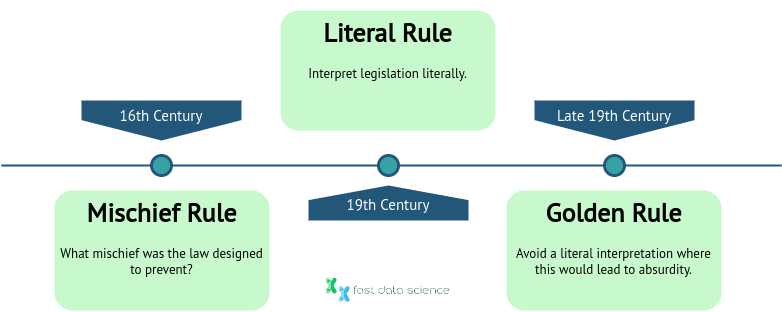
Timeline of the development of the three main rules of statutory interpretation: in the 16th Century, the original mischief rule gave judges a fair amount of freedom, and then in Victorian times the trend moved towards a literal interpretation of statute, and finally we have moved back towards a reasonable interpretation of the purpose of a statute with the golden rule.
An example application of the mischief rule is Corkery v Carpenter (1951), where the defendant rode his bicycle while drunk and was arrested under a Victorian-era law (Licensing Act 1872) which mentioned ‘carriages’. The judge decided that the mischief in question is the same whether a person is riding a bicycle or a horse-drawn carriage.

The introductory paragraph of the judgment of R v Bentham (2005), laying out the facts of the case.
An interesting case where AI might have trouble due to varying statutory interpretations is R v Bentham, which was an appeal which went to the House of Lords in England in 2005.
The defendant, Peter Bentham, committed a robbery and used his outstretched finger hidden under the folds of his jacket so as to deliberately give the impression that he had a gun. His victim, believing he had a gun, handed over valuables.
In the Court of Appeal, Bentham was convicted under the Firearms Act 1968, which has provision for “imitation firearms”.

Can a finger be considered an imitation firearm?
Bentham later appealed, and the case went to the House of Lords, which allowed his appeal, because, according to the judges, a human finger cannot be considered to be an imitation firearm because it is is a part of the body.
The lower Court (the Court of Appeal) applied the mischief rule, but the House of Lords interpreted the Firearms Act more literally and overturned the conviction on a technicality.
Given the huge progress made in transformers in the last couple of years, my first instinct was that a transformer model such as BERT or GPT-2 should be able to to answer questions about the case.
I tried ingesting the facts of the case into BERT and asking questions such as who is the appellant?, what is the appellant accused of?, and when did the crime occur? Although BERT was sometimes able to locate the answers in the text and locate substrings of the text, this is far from actually understanding and retrieving information. In essence, I found that that was a very sophisticated information retrieval system but did not come close to the complexity needed to model the real world.
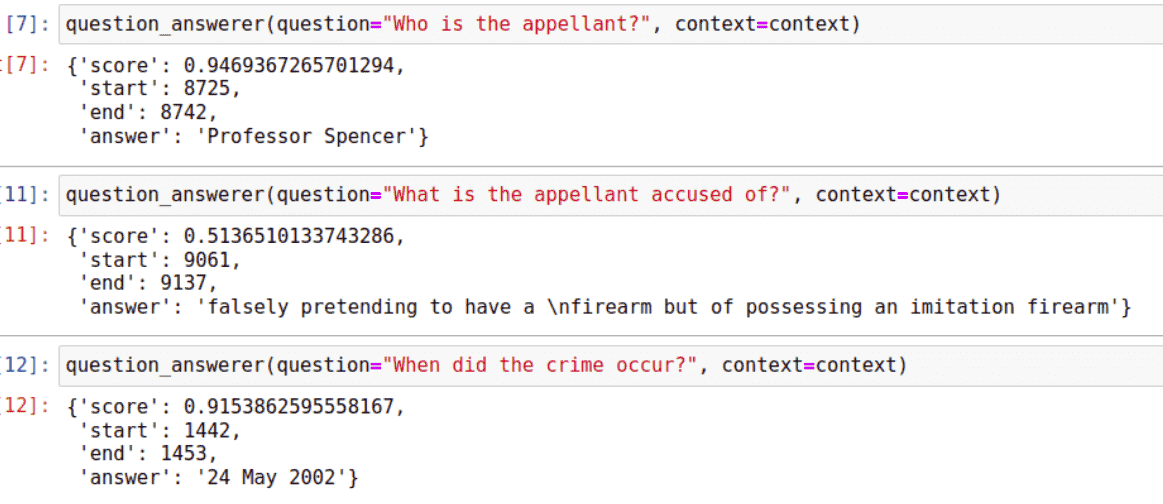
How BERT responded to questions about R v Bentham
There are a number of ways of representing real-world events and their effects in logical languages such as Prolog, such as the Event Calculus, which is a logical way of representing events and their effects developed by Robert Kowalski and Marek Sergot in 1986.
I chose a relatively simple way of modelling natural language texts, where all verbs or prepositions are translated into a Prolog expression of the form:
action(subject, object, time)
So the sentences the defendant burgled the house in 9th July 2001, or the house was burgled by the defendant on 9th July 2001 would both become:
burgle(defendant, house, date_20010709)
When all information in a text is translated into this format, it is easier to query, although it does have some shortcomings, such as representation of subclauses.
In this way, a sequence of events can be by broken down into a series of independent predicates. The huge advantage of Prolog is that is tolerant of errors and usually ignores mistakes on one line and proceeds to the next line.
Judgments from the House of Lords can be downloaded in PDF form from the UK Parliament’s web portal.
I developed a simple web interface which can process a PDF of a judgment, identify the facts of the case, and apply the relevant statutory reasoning - within a very narrow scope.
The process works as follows:
To test the Prolog legal reasoning model on R v Bentham, I manually translated the relevant sections of the Firearms Act 1968 into Prolog. The relevant section of the Firearms Act simply states that a person is guilty if they commit an offence such as robbery and are in possession of a firearm or imitation firearm - but does not state explicitly whether a finger could count as an imitation firearm.
I included an option in my Prolog code to apply or ignore the mischief rule, allowing for a strict or loose interpretation of the Act.
I joined together the Prolog code for the legislation and the Prolog code describing the facts of the R v Bentham case, and was able to query to ask if anybody was guilty under the Firearms Act 1968.
With the ability to turn the mischief rule on and off, this allows a user to see both interpretations of a judgement.
With this flexibility, my Prolog code could reproduce the rulings of both the original Court of Appeal which had convicted Bentham and the House of Lords which acquitted him.
In the video below you can see how the Prolog code can be quickly generated from the raw facts of the case, and how legal reasoning can be performed on the Prolog:
The conversion of the facts of a case and relevant legislation into Prolog is an interesting problem, because it involves an interpretation of real world events which have to be included into Prolog. In order for an AI to be aware that a human finger is not an imitation firearm because it is part of the body, a huge amount of real-world knowledge must be encoded into that AI and I do not believe that statistical AI or machine learning is capable of this level of understanding.
What would also be extremely difficult for an AI to do would be to apply precedent. An AI would need real-world knowledge in order to decide that a certain firearms case is analogous or similar enough to another case.
In 2023, we presented our Insolvency Bot at the JURIX conference at Maastricht University in the Netherlands. The insolvency bot which we developed was a proof of concept of how LLMs can be leveraged to improve access to justice to those facing insolvency procedures, who are unlikely to be able to pay for timely legal advice in their circumstances (you can read our submitted paper in the proceedings of the conference here: Prompt Engineering and Provision of Context in Domain Specific Use of GPT).
We were interested to note that there was a lot of interest in legal reasoning systems from the angle of widening access to justice. A number of papers presented on the topic. Many jurisdictions have a state-funded legal aid system, but these are often very restrictive, and low-income litigants have been left without access to legal advice.
My short experiments with Prolog show that it is possible to achieve some limited results in a limited domain with symbolic AI in law. The combination of a statistical based model such as a natural language parser, together with a symbolic AI, in the form of a hybrid AI system, is very powerful but has many limitations and is a long way from being able to perform the job the job of a lawyer or a judge.
However, AI in law is rapidly changing and a promising application is improving access to justice (AI for A2J). We have spoken to some larger law firms which are interested in the possibility of AI innovations in law actually trickling up from areas such as insolvency and A2J initiatives to the higher paid areas of law such as commercial and contract law, or mergers and acquisitions.
The reason for the Lords’ decision in R v Bentham hinged on the meaning of the word possess - harking back to a principle of Roman law that a person cannot possess a part of their body. This unfortunately is very difficult to model with AI, as judges and lawyers have knowledge of these common principles which are not always coded in statute.
It is possible that we will only reach the necessary level of understanding when artificial general intelligence (AGI) becomes a reality. While AGI remains science fiction, I do not see legal AI making major decisions, although it is currently in use to assist lawyers mainly in the area of information retrieval.
I enjoyed this excellent presentation by Nils Holzenberger on NLP and tax law in the US:
Dive into the world of Natural Language Processing! Explore cutting-edge NLP roles that match your skills and passions.
Explore NLP Jobs
Unlock your business potential with expert AI consulting services from Fast Data Science. Discover strategies to accelerate growth and outperform competitors.

Financial advisors, like lawyers, are regulated in the UK. All financial advisors should be registered with the Financial Conduct Authority (FCA) and must have certain qualifications and have signed up to a code of ethics. UK financial advisors must also complete professional training every year.
What we can do for you
