
How NLP document similarity algorithms can be used to find similar documents and build document recommendation systems.
Let us imagine that you are reading a document, and would like to find which other documents in a database are most similar to it. This is called the document similarity problem, or the semantic similarity problem.
 and [machine learning](/data-science-consulting/machine-learning-consulting-businesses-benefit/) be used to find similar documents?](https://fastdatascience.com/images/nlp_machine_learning_finding_similar_documents-min.png)
We can imagine a few real-world examples where you might encounter this:
There are a number of ways to approach this problem using natural language processing.
However before looking at the technologies available, I would start by defining the problem.
One question that needs to be asked before building an NLP model to calculate document similarity is, what is it expected to do?
In the company that you are building it for, there is unlikely to be a dataset indicating which documents are similar to which other ones.
Before beginning any hands-on data science work, I would advise to try to build up at least some data (a ‘gold standard’, or ‘ground truth’) that can be used to test and evaluate a future model. This is the machine learning analogue of test-driven development.
When you start developing your models, you will instantly have a way to score them.
However, often it is not possible to build a dataset to evaluate a document similarity model. Sometimes, the document similarity is subjective and in the eyes of the client. In a case like this, I would advise to build a basic model and present a number of recommendations to the stakeholders, and ask them to evaluate which recommendations were good and which were less accurate.
The result of this exercise can be turned into a test-bed which can evaluate future iterations of the similarity model.
There are a number of metrics which could be used to evaluate a document similarity model. One of the best-known is Mean Average Precision. This is a number which can measure the quality of a search engine’s recommendations, and scores models highly which rank very relevant documents in first position, and penalises a model which puts relevant documents at the bottom of the list. There are a number of other metrics but I would recommend to start evaluating your models on your gold standard dataset using mean average precision initially.
The simplest way to compare two documents would be to simply take the words that are present in both, and calculate the degree of overlap. We can throw away the information about which word co-occurred with which other word in the sentence. Because this representation of a sentence is akin to putting a set of words into a bag and jumbling them up before comparing them, this technique is called a ‘bag-of-words’ model.
For example, if we have these two sentences from paper abstracts:
India is one of the epicentres of the global diabetes mellitus pandemic.
Diabetes mellitus occurs commonly in the older patient and is frequently undiagnosed.
then one very simple way to measure the similarity is to remove stopwords (the, and, etc), and then calculate the number of words in both documents, divided by the number of words in any document. This is number is called the Jaccard index and was developed over a century ago by the Swiss botanist Paul Jaccard:

Paul Jaccard, developer of the Jaccard index. Source: Wikimedia. Licence: CC4.0.
So the non-stopwords in document 1 are:
{'diabetes', 'epicentres', 'global', 'india', 'mellitus', 'one', 'pandemic'}
and the non-stopwords in document 2 are:
{'commonly', 'diabetes', 'frequently', 'mellitus', 'occurs', 'older', 'patient', 'undiagnosed'}
Natural language processing
There are two words in common (diabetes, mellitus), and 13 words altogether.
So the Jaccard similarity index of the two documents is 2/13 = 15%.
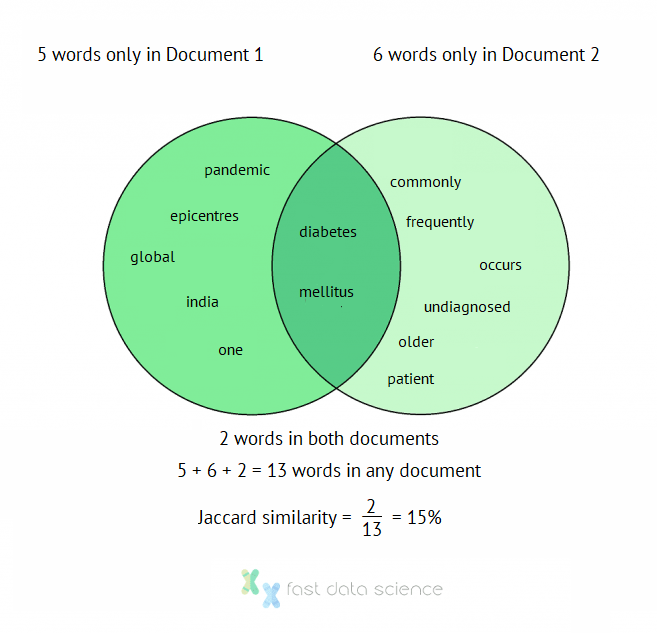
Illustration of the Jaccard document similarity index calculation as a Venn diagram
Despite its crudeness, bag-of-words models such as the Jaccard index and the similar cosine similarity are very powerful because they are so quick to implement and easy to understand.
I would recommend using a bag-of-words approach at the start of a model development cycle for two reasons: firstly, in case it does what you need, and secondly, in order to have a baseline and accurately assess whether a more sophisticated model, which does take context into account, is actually adding any value.
Bag-of-words is likely to be the best choice for very short document types, such as article titles, or search queries, where context is unlikely to matter. For example, if you have a job search board, and would like to recommend job titles to users who have searched for a similar term, then a bag-of-words approach would probably be the best model to try.
In the example above, we counted diabetes and mellitus as two separate words when calculating the Jaccard similarity index. In reality, they function as a single term (a multi-word expression, or MWE). A bag-of-words approach will not correctly handle multi-word expressions because it will break them up into separate words.
One way around this is to take all two-word sequences and calculate the similarity index using those. So the second document would generate the following two-word subsequences:
{'and is',
'commonly in',
'diabetes mellitus',
'frequently undiagnosed',
'in the',
'is frequently',
'mellitus occurs',
'occurs commonly',
'older patient',
'patient and',
'the older'}
The above terms are the bigrams of the document, and the technique of taking subsequences of length N is called the N-gram approach.
N-grams are still relatively easy to implement and have the advantage that some contextual information is retained. Diabetes mellitus is treated as a single term, for example. An N-gram based document similarity model is not as ‘dumb’ as the vanilla bag-of-words approach. I would usually combine the bigram model with the bag-of-words model in order to get the best of both worlds.
The bag-of-words and N-gram approaches detailed above all have a major disadvantage: if Document 1 has the word diabetic and Document 2 has the word diabetes, and Document 3 mentions T2DM (another abbreviation), how would we recognise a similarity?
In 2013 the Czech computer scientist Tomáš Mikolov had the idea of representing words in a ‘semantic space’, where every word has a set of coordinates in space, and words that are close together in meaning have a short distance between them. This algorithm is called word2vec and is derived from the idea that words that occur in similar contexts are similar semantically. Below you can explore a word2vec dataset that I trained on a set of clinical trial documents.
Note that words which are conceptually similar are close together in the graph. Often, the Euclidean distance is used as a measure of similarity.
Mikolov later extended word2vec to documents, creating an algorithm that can represent any document as e.g. a 500-dimensional vector. The similarity between two documents is indicated by the closeness of their vectors.
The above methods should be sufficient to measure document similarity for both use cases. However, if you want to squeeze some extra drops of performance, the cutting edge models are currently Transformers. The best-known transformer-based model is called BERT, but other models include ELMO, RoBERTa, DistilBERT, and XLNet.
Transformers also work by representing words and sentences as vectors, but with a crucial difference that the vector representation of a word is not fixed but is itself dependent on the context of the word. For example, the word it is represented differently in vector space according to what ‘it’ is referring to - a feature that comes in useful when using transformer models to translate from English to a gendered language where it could have different translations depending on what it refers to.
Transformers are very computationally intensive (they need GPUs and won’t run on a regular laptop), and are often limited to short sentences. In most commercial use cases they may be unwieldy due to the difficulty of implementing them. However, if you can train a transformer model on your data then it is likely to outperform the alternatives listed above.
The details of exactly how transformers work are very hard going to work through. In practice, to get started with transformers you can use a cloud provider such as Microsoft Azure ML, Google Cloud Platform, or AWS Sagemaker. The text classification examples on these platforms allow you to use pre-trained transformer models for document similarity calculations relatively quickly and without the need to go into the details of how transformers work.
Nowadays the best known LLMs such as OpenAI offer a sentence embedding API. So you don’t need to run a transformer on your machine. If you have an OpenAI API key, it’s possible to call OpenAI’s API from your code, to generate a sentence embedding for all your documents. You can then calculate the cosine similarity between the embeddings as a measure of similarity.
There are an increasing number of products on the market which manage a document collection in vector form and allow you to retrieve documents with vectors close to a query vector. For example, if you have documents containing the word “anxiety”, you would want to be able to search for “anxious” or “worried” and retrieve any document with that approximate theme.
A vector index, or vector database, such as Pinecone, Weaviate, OpenSearch or Elasticsearch, allows you to upload a collection of documents and index them in vector form. The software then allows you to query, as you would with a plain text search, and it will find documents which are closest to your query according to the cosine similarity, or dot product, or other metric.
| Solution | Description | Cloud or on prem |
|---|---|---|
| Elasticsearch | The most popular search solution. Very fast, and originally designed for word (token)-based search, but now supports vector search. | Cloud and on prem |
| Pinecone | A more modern alternative to Elasticsearch, designed with vector search out of the box. | Only on prem |
| Weaviate | Great alternative to Elasticsearch, performs well for large document collections. | Cloud and on prem |
| OpenSearch | Open source vector database with Apache 2.0-license | Cloud and on prem |
There are a number of document similarity models available. I would recommend approaching a document similarity problem by defining the task and a gold standard and choosing an evaluation metric, and then training a number of models from the simpler options to the more complex alternatives until you have found the model which best fits the use case.
Document similarity algorithms are also progressing fast, and the transformer-based methods are likely to become more prominent in the next few years.
P. Jaccard, Distribution de la flore alpine dans le bassin des Dranses et dans quelques régions voisines. Bulletin de la Société Vaudoise des Sciences Naturelles 37, 241-272 (1901)
T. Mikolov et al.. Efficient Estimation of Word Representations in Vector Space, arXiv:1301.3781 (2013)
Unleash the potential of your NLP projects with the right talent. Post your job with us and attract candidates who are as passionate about natural language processing.
Hire NLP Experts
This is an article based on my presentation on “The Role of Artificial Intelligence in Expert Investigations and the Preparation of reports” which I gave at the Expert Witness Conference on 20 May 2026.

Many companies and organisations have large datasets that are stored in a very unstructured format. For example, you could work for a US based healthcare provider or insurer and have patient records stored in a free text format such as HL7 files or PDFs. A building regulator, land registry, or mortgage provider may have texts and accompanying diagrams from thousands of building inspections or land title deeds. A patent attorney’s office may have records of patent applications in PDF format.

On 20 May, I attended the Expert Witness Conference in Dublin, Ireland, organised by La Touche Training. It was an eye opening event with a mixture of lawyers and expert witnesses in different fields from Ireland and abroad. The event was chaired by Mr Justice Michael Peart, with a keynote address by the Honourable Mr Justice David Barniville, President of the High Court of Ireland.
What we can do for you