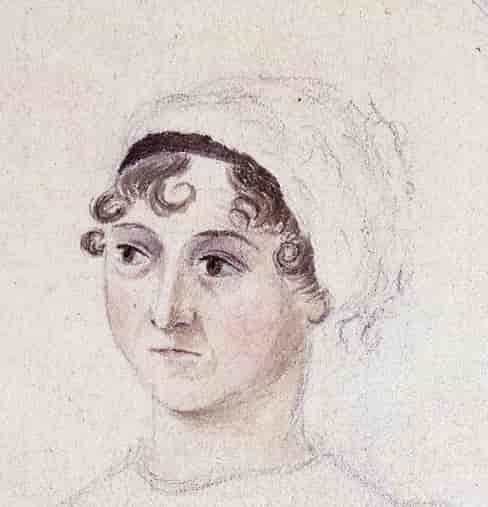
Fast Data Science has developed a unique forensic stylometry model and Python library which allows you to identify the author of a text by their unique stylistic and linguistic “fingerprint”. It needs a relatively long text, such as a few chapters of a book, to make an accurate identification.
For best results try entering at least two or three paragraphs of text. You can get some free writing samples by visiting Project Gutenberg, or the contemporary authors' websites (Pottermore, Dan Brown, Philip Pullman). JK Rowling wrote some books under the pseudonym Robert Galbraith. Try testing if the model can correctly identify the author. If the text has no resemblance to any of the known author’s works, the model will output some very small probabilities.
The model was trained on the following books. So, if you give it a book such as Villette by Charlotte Brontë, which is not on the list, it will hopefully identify Brontë as the correct author despite never having seen the book.
Jane Austen (1775-1817) was most famous for Pride and Prejudice but in fact wrote six novels. The forensic stylometry model has been trained on three of her novels. Can it recognise the others?
I have written a tutorial on using forensic stylometry with the Python library faststylometry here: Fast Stylometry Tutorial.
There is an excellent introduction to various stylometry techniques here: Introduction to Stylometry with Python.
I also recommend to read the paper Stylometry with R: A Package for Computational Text Analysis by Maciej Eder, Jan Rybicki and Mike Kestemont, which provides an overview on how to conduct scientifically valid stylometric analyses of texts using a graphical package stylo in R.
Using stylo and other scientific packages, researchers in linguistics and the humanities can analyse text in a variety of languages for cases of contested historical authorship. For instance, I had a query about a set of Latin texts where academics disagree on which historian is the true author! The technique is also used by forensic linguists for legal cases.
The probabilities output by this stylometry model are derived from a probability calibration process, which converts the Burrows Delta statistic to a probability value based on the distribution of Burrows Delta values in the training data. This means that if the text you input is unlike anything by any of the known authors, all authors will be assigned a probability close to zero. Conversely, the probabilities may sum to a number greater than 1, because each probability is calculated independently.
A lot of machine learning models you can try (for example, the iPhone apps you can download which tell you what breed your dog is, or how old your face looks) tend to output unreasonable probabilities, because they rely on a Softmax layer, which forces all output scores to sum to 1. A Softmax layer tends to spit out probabilities which are either very close to 0 or very close to 1.
I chose to use a probability calibration technique for this demo to avoid the odd effects associated with (mis)interpreting a Softmax output as a probability.
We can calculate the probability that a text was authored by a generative AI model such as BARD or ChatGPT, by calculating the model’s perplexity (how surprised it is by the document). Recently, many disputes are arising in higher education, where a student may be accused of using AI to write an assignment.
Try our generative AI detector.
If you are undertaking research in AI, NLP, or other areas, and are publishing your findings, I would be grateful if you could please cite the project.
Wood, T.A., Fast Stylometry [Computer software] (1.0.4). Data Science Ltd. DOI: 10.5281/zenodo.11096941, accessed at https://fastdatascience.com/fast-stylometry-python-library, Fast Data Science (2024)
![]()
A BibTeX entry for LaTeX users is:
@software{faststylometry,
author = {Wood, T.A.},
title = {Fast Stylometry (Computer software), Version 1.0.4},
year = {2024},
url = {https://fastdatascience.com/fast-stylometry-python-library/},
doi = {10.5281/zenodo.11096941},
}
What we can do for you